我是从cBioPortal数据下载的临床数据,下载使用临床数据还是没问题的。RNAseq counts数据推荐用生信人TCGA小工具下载,这里放一个传送门:https://www.shengxin.ren/article/95。言归正传,讲cBioPortal。主页面是这样的:

cBioPortal主页面
选择我们需要的肿瘤类型和数据集,可以看到最新的TCGA数据库里面有头颈部肿瘤530例:

头颈部肿瘤数据集
我们可以点击download,切换到下载页面:
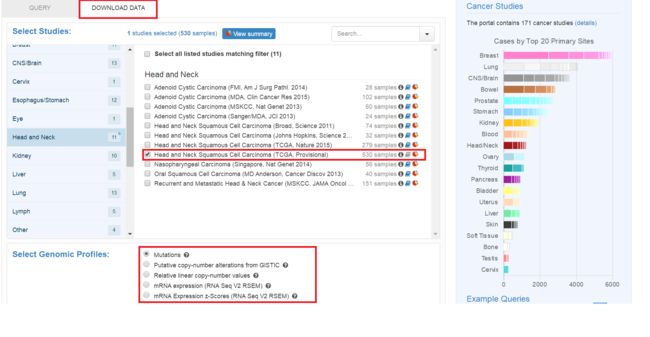
下载页面
点击绿色框内的图标进入概览页面:
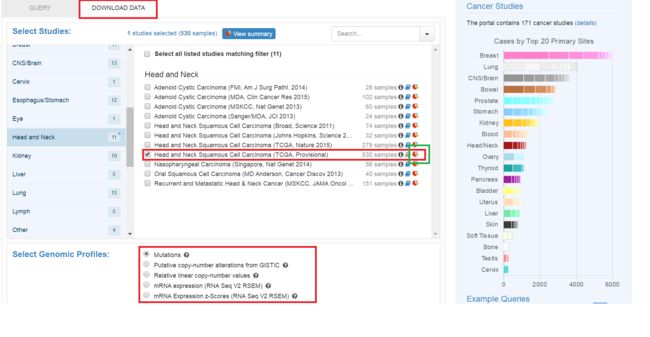
概览
点击Download,就可以在浏览器里面下载数据了。
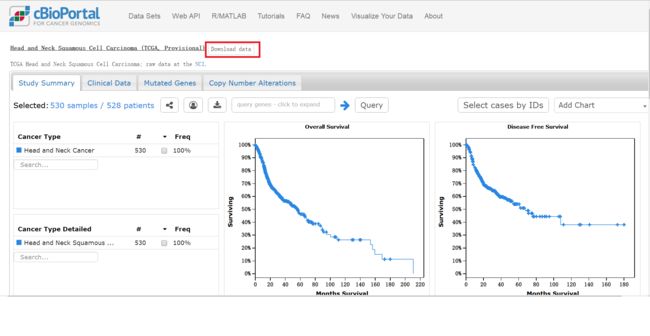
下载

下载文件
下载好之后解压就行了,里面有多个文件也有说明。这里不再赘述了。
以下就是代码,读取数据生成对象:
#================临床资料整理============
# 1.1 读入数据
patientMatch <- read.table("hnsc_tcga/hnsc_tcga/data_bcr_clinical_data_patient.txt",
header = T, row.names = 1, comment.char = '#', sep = '\t',
na.strings = '[Not Available]')
> colnames(patientMatch)
# [1] "PATIENT_ID" "FORM_COMPLETION_DATE"
# [3] "HISTOLOGICAL_DIAGNOSIS" "PRIMARY_SITE"
# [5] "LATERALITY" "PROSPECTIVE_COLLECTION"
# [7] "RETROSPECTIVE_COLLECTION" "SEX"
# [9] "DAYS_TO_BIRTH" "RACE"
# [11] "ETHNICITY" "HISTORY_OTHER_MALIGNANCY"
# [13] "HISTORY_NEOADJUVANT_TRTYN" "INITIAL_PATHOLOGIC_DX_YEAR"
# [15] "LYMPH_NODE_NECK_DISSECTION_INDICATOR" "LYMPH_NODE_DISSECTION_METHOD"
# [17] "LYMPH_NODES_EXAMINED" "LYMPH_NODE_EXAMINED_COUNT"
# [19] "LYMPH_NODES_EXAMINED_HE_COUNT" "LYMPH_NODES_EXAMINED_IHC_COUNT"
# [21] "PATH_MARGIN" "P53_GENE_ANALYSIS"
# [23] "AMPLIFICATION_STATUS" "VITAL_STATUS"
# [25] "DAYS_TO_LAST_FOLLOWUP" "DAYS_TO_DEATH"
# [27] "TUMOR_STATUS" "AJCC_STAGING_EDITION"
# [29] "AJCC_TUMOR_PATHOLOGIC_PT" "AJCC_NODES_PATHOLOGIC_PN"
# [31] "AJCC_METASTASIS_PATHOLOGIC_PM" "AJCC_PATHOLOGIC_TUMOR_STAGE"
# [33] "EXTRACAPSULAR_SPREAD_PATHOLOGIC" "GRADE"
# [35] "ANGIOLYMPHATIC_INVASION" "PERINEURAL_INVASION"
# [37] "HPV_STATUS_P16" "HPV_STATUS_ISH"
# [39] "TOBACCO_SMOKING_HISTORY_INDICATOR" "SMOKING_YEAR_STARTED"
# [41] "SMOKING_YEAR_STOPPED" "SMOKING_PACK_YEARS"
# [43] "ALCOHOL_HISTORY_DOCUMENTED" "ALCOHOL_CONSUMPTION_FREQUENCY"
# [45] "DAILY_ALCOHOL" "RADIATION_TREATMENT_ADJUVANT"
# [47] "PHARMACEUTICAL_TX_ADJUVANT" "TREATMENT_OUTCOME_FIRST_COURSE"
# [49] "NEW_TUMOR_EVENT_AFTER_INITIAL_TREATMENT" "AGE"
# [51] "CLIN_M_STAGE" "CLIN_N_STAGE"
# [53] "CLIN_T_STAGE" "CLINICAL_STAGE"
# [55] "DAYS_TO_INITIAL_PATHOLOGIC_DIAGNOSIS" "DISEASE_CODE"
# [57] "EXTRANODAL_INVOLVEMENT" "ICD_10"
# [59] "ICD_O_3_HISTOLOGY" "ICD_O_3_SITE"
# [61] "INFORMED_CONSENT_VERIFIED" "PROJECT_CODE"
# [63] "STAGE_OTHER" "TISSUE_SOURCE_SITE"
# [65] "TUMOR_TISSUE_SITE" "OS_STATUS"
# [67] "OS_MONTHS" "DFS_STATUS"
# [69] "DFS_MONTHS"
> dim(patientMatch)
# [1] 527 69
一共有69列,即69个变量,527个样本。这里我们需要的变量有:
"PATIENT_ID" ,做行名
rownames(patientMatch) <- patientMatch$PATIENT_ID
patientMatch <- patientMatch[,-1]
其它的变量,这里用了一个正则表达式:
"PRIMARY_SITE","LATERALITY"
"SEX"
"RACE"
"HISTORY_OTHER_MALIGNANCY"
"LYMPH_NODE_NECK_DISSECTION_INDICATOR"
"LYMPH_NODE_DISSECTION_METHOD"
"LYMPH_NODE_EXAMINED_COUNT","LYMPH_NODES_EXAMINED_HE_COUNT"
"LYMPH_NODES_EXAMINED_IHC_COUNT","PATH_MARGIN"
"VITAL_STATUS","DAYS_TO_LAST_FOLLOWUP"
"DAYS_TO_DEATH","TUMOR_STATUS"
"AJCC_TUMOR_PATHOLOGIC_PT"
"AJCC_NODES_PATHOLOGIC_PN","AJCC_METASTASIS_PATHOLOGIC_PM"
"AJCC_PATHOLOGIC_TUMOR_STAGE","EXTRACAPSULAR_SPREAD_PATHOLOGIC"
"GRADE","ANGIOLYMPHATIC_INVASION"
"PERINEURAL_INVASION","HPV_STATUS_P16"
"HPV_STATUS_ISH","TOBACCO_SMOKING_HISTORY_INDICATOR"
"ALCOHOL_HISTORY_DOCUMENTED"
"PHARMACEUTICAL_TX_ADJUVANT"
"TREATMENT_OUTCOME_FIRST_COURSE","NEW_TUMOR_EVENT_AFTER_INITIAL_TREATMENT"
"AGE","CLIN_M_STAGE"
"CLIN_N_STAGE","CLIN_T_STAGE"
"CLINICAL_STAGE"
"TISSUE_SOURCE_SITE","TUMOR_TISSUE_SITE"
"OS_STATUS","OS_MONTHS"
"DFS_STATUS"
原文本在这里,需要把换行符、回车符去掉,在两个中间没有字母数字的"中间插入一个,。用的正则替换式如下图:

在notepad++中完成替换
完成之后变成这样子:
"PRIMARY_SITE","LATERALITY","SEX","RACE","HISTORY_OTHER_MALIGNANCY","LYMPH_NODE_NECK_DISSECTION_INDICATOR","LYMPH_NODE_DISSECTION_METHOD","LYMPH_NODE_EXAMINED_COUNT","LYMPH_NODES_EXAMINED_HE_COUNT","LYMPH_NODES_EXAMINED_IHC_COUNT","PATH_MARGIN","VITAL_STATUS","DAYS_TO_LAST_FOLLOWUP","DAYS_TO_DEATH","TUMOR_STATUS","AJCC_TUMOR_PATHOLOGIC_PT","AJCC_NODES_PATHOLOGIC_PN","AJCC_METASTASIS_PATHOLOGIC_PM","AJCC_PATHOLOGIC_TUMOR_STAGE","EXTRACAPSULAR_SPREAD_PATHOLOGIC","GRADE","ANGIOLYMPHATIC_INVASION","PERINEURAL_INVASION","HPV_STATUS_P16","HPV_STATUS_ISH","TOBACCO_SMOKING_HISTORY_INDICATOR","ALCOHOL_HISTORY_DOCUMENTED","PHARMACEUTICAL_TX_ADJUVANT","TREATMENT_OUTCOME_FIRST_COURSE","NEW_TUMOR_EVENT_AFTER_INITIAL_TREATMENT"
"AGE","CLIN_M_STAGE","CLIN_N_STAGE","CLIN_T_STAGE","CLINICAL_STAGE","TISSUE_SOURCE_SITE","TUMOR_TISSUE_SITE","OS_STATUS","OS_MONTHS","DFS_STATUS"
这一步也可以在RStudio中完成。
我们选出这些列:
patientMatch <- patientMatch[, c( "PRIMARY_SITE","LATERALITY","SEX","RACE","HISTORY_OTHER_MALIGNANCY",
"LYMPH_NODE_NECK_DISSECTION_INDICATOR","LYMPH_NODE_DISSECTION_METHOD",
"LYMPH_NODE_EXAMINED_COUNT","LYMPH_NODES_EXAMINED_HE_COUNT",
"LYMPH_NODES_EXAMINED_IHC_COUNT","PATH_MARGIN","VITAL_STATUS",
"DAYS_TO_LAST_FOLLOWUP","DAYS_TO_DEATH","TUMOR_STATUS","AJCC_TUMOR_PATHOLOGIC_PT",
"AJCC_NODES_PATHOLOGIC_PN","AJCC_METASTASIS_PATHOLOGIC_PM",
"AJCC_PATHOLOGIC_TUMOR_STAGE","EXTRACAPSULAR_SPREAD_PATHOLOGIC",
"GRADE","ANGIOLYMPHATIC_INVASION","PERINEURAL_INVASION","HPV_STATUS_P16",
"HPV_STATUS_ISH","TOBACCO_SMOKING_HISTORY_INDICATOR","ALCOHOL_HISTORY_DOCUMENTED",
"PHARMACEUTICAL_TX_ADJUVANT","TREATMENT_OUTCOME_FIRST_COURSE",
"NEW_TUMOR_EVENT_AFTER_INITIAL_TREATMENT",
"AGE","CLIN_M_STAGE","CLIN_N_STAGE","CLIN_T_STAGE","CLINICAL_STAGE",
"TISSUE_SOURCE_SITE","TUMOR_TISSUE_SITE","OS_STATUS","OS_MONTHS","DFS_STATUS")]
> colnames(patientMatch)
# [1] "PRIMARY_SITE" "LATERALITY"
# [3] "SEX" "RACE"
# [5] "HISTORY_OTHER_MALIGNANCY" "LYMPH_NODE_NECK_DISSECTION_INDICATOR"
# [7] "LYMPH_NODE_DISSECTION_METHOD" "LYMPH_NODE_EXAMINED_COUNT"
# [9] "LYMPH_NODES_EXAMINED_HE_COUNT" "LYMPH_NODES_EXAMINED_IHC_COUNT"
# [11] "PATH_MARGIN" "VITAL_STATUS"
# [13] "DAYS_TO_LAST_FOLLOWUP" "DAYS_TO_DEATH"
# [15] "TUMOR_STATUS" "AJCC_TUMOR_PATHOLOGIC_PT"
# [17] "AJCC_NODES_PATHOLOGIC_PN" "AJCC_METASTASIS_PATHOLOGIC_PM"
# [19] "AJCC_PATHOLOGIC_TUMOR_STAGE" "EXTRACAPSULAR_SPREAD_PATHOLOGIC"
# [21] "GRADE" "ANGIOLYMPHATIC_INVASION"
# [23] "PERINEURAL_INVASION" "HPV_STATUS_P16"
# [25] "HPV_STATUS_ISH" "TOBACCO_SMOKING_HISTORY_INDICATOR"
# [27] "ALCOHOL_HISTORY_DOCUMENTED" "PHARMACEUTICAL_TX_ADJUVANT"
# [29] "TREATMENT_OUTCOME_FIRST_COURSE" "NEW_TUMOR_EVENT_AFTER_INITIAL_TREATMENT"
# [31] "AGE" "CLIN_M_STAGE"
# [33] "CLIN_N_STAGE" "CLIN_T_STAGE"
# [35] "CLINICAL_STAGE" "TISSUE_SOURCE_SITE"
# [37] "TUMOR_TISSUE_SITE" "OS_STATUS"
# [39] "OS_MONTHS" "DFS_STATUS"
> dim(patientMatch)
#[1] 527 40
下面我们生成一个新的变量来储存整理我们需要的变量和变量值:
baseLine <- patientMatch[, c(1:5)]
# baseLine$Race[baseLine$Race %in% c("Not Evaluated", "Unknown")] <- NA
# rownames(baseLine) <- patientMatch$patientID
# 1.5数据转换称因子变量分组并储存
#Freq <- lapply(patientMatch[,c(2:21)], table)
baseLine$Age <- ifelse(as.numeric(patientMatch$AGE) > 55,">55", "<=55")
baseLine$Smoke <- ifelse(patientMatch$TOBACCO_SMOKING_HISTORY_INDICATOR == "1", "NO", "YES")
baseLine$Acohol <- patientMatch$ALCOHOL_HISTORY_DOCUMENTED
baseLine$pMargin <- patientMatch$PATH_MARGIN
patientMatch$AJCC_PATHOLOGIC_TUMOR_STAGE[patientMatch$AJCC_PATHOLOGIC_TUMOR_STAGE == "[Discrepancy]"] <- NA
baseLine$pathoStage <- gsub("[a-cA-C]", "", patientMatch$AJCC_PATHOLOGIC_TUMOR_STAGE)
baseLine$PathoT <- gsub("[a-cA-C]", "", patientMatch$AJCC_TUMOR_PATHOLOGIC_PT)
baseLine$PathoN <- gsub("[a-cA-C]","",patientMatch$AJCC_NODES_PATHOLOGIC_PN)
baseLine$PathoM <- gsub("[a-cA-C]", "", patientMatch$AJCC_METASTASIS_PATHOLOGIC_PM)
baseLine$ClinStage <- gsub("[a-cA-C]", "", patientMatch$CLINICAL_STAGE)
baseLine$ClinT <- gsub("[a-cA-C]", "", patientMatch$CLIN_T_STAGE)
baseLine$ClinN <- gsub("[a-cA-C]", "", patientMatch$CLIN_N_STAGE)
baseLine$ClinM <- gsub("[a-cA-C]", "", patientMatch$CLIN_M_STAGE)
baseLine$HistoGrade <- patientMatch$GRADE
baseLine$LymphVasInvas <- patientMatch$ANGIOLYMPHATIC_INVASION
baseLine$PeriInvas <- patientMatch$PERINEURAL_INVASION
#baseLine$MarginStatus <- factor(patientMatch$MarginStatus,
# levels = c("Negative", "Close", "Positive"))
baseLine$NodeExtraCapsu <- patientMatch$EXTRACAPSULAR_SPREAD_PATHOLOGIC
后面HPV的感染有两个检测方法,我们选其中任意一个阳性的患者判定其HPV感染状态为阳性,通过创建一个函数来判定:
HPVlog <- function(x, y){if("Positive" %in% c(x, y)){hpv = "Positive"}
else if("Negative" %in% c(x, y)){hpv = "Negative"}
else {hpv = NA}
return(hpv)
}
baseLine$HPV <- mapply(HPVlog, patientMatch$HPV_STATUS_ISH, patientMatch$HPV_STATUS_P16)
后面是结局事件和时间:
# 1.6 生存时间和事件
baseLine$Mons2End <- patientMatch$Mons2End
baseLine$VitalStatus <- patientMatch$VitalStatus
baseLine$DisFreeStatus <- patientMatch$DFS_STATUS
baseLine$OSMonths <- patientMatch$OS_MONTHS
导出整理出来的临床资料:
# 1.7 结果导出
write.csv(baseLine, "baseLine.csv")
dim(baseLine)
#[1] 527 23
tableNA <- table(baseLine[, 2],useNA = "ifany")
Freq <- lapply(baseLine[, 1:22],function(x) table(x, useNA = "ifany"))
prop <- lapply(Freq[1:22], prop.table)
建立表格并导出:
# 1.8 建表
Char <- NULL
for(i in 1:22){
Character <- c(names(Freq[i]), names(Freq[[i]]))
Noc <- c(NA, paste0(Freq[[i]], "(", round(prop[[i]]*100, 2),")"))
patientChara <- data.frame("Characteristics" = Character, "Number of Case" = Noc)
Char <- rbind(Char, patientChara)
}
library(xlsx)
write.xlsx(Char, "BaseLineIntergarted.xls", row.names = F, showNA = F)
这是最终导出的表格:
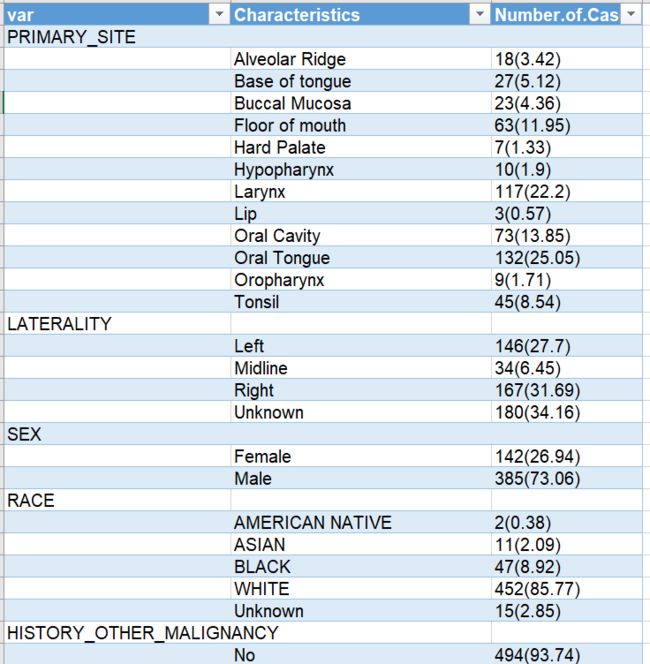
导出表格