Zookeeper的配置很简单,用自带的zkCli可以对ZNode进行操作,可以实现分布式锁和小文件分布式存储等功能,这些都是基础功能。在现实世界里,Zookeeper用来构建一些分布式应用会都会涉及到核心功能:数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁、分布式队列等等。
典型应用场景和实现
数据发布/订阅
就是配置中心,发布者将数据发布到Zookeeper的一个或多个节点,供订阅者进行数据订阅,实现配置信息的集中式管理和数据的动态更新。
Zookeeper采用的是推拉模型相结合的方式,客户端向服务端注册自己需要关注的节点,一旦节点数据发生变化,服务器会向客户端发送Watcher事件通知,客户端收到通知后主动到服务端获取最新数据。
在应用系统中,经常碰到这样的需求:系统中需要使用一些通用的配置信息,例如机器列表信息、运行时开关配置、数据库配置等等,这些全局配置信息具备以下三个特点:
1、数据量比较小
2、数据在运行时发生动态变化
3、集群中各机器共享,配置一致
用Zookeeper可以很容易实现,将配置放到一个ZNode中,集群机器初始化阶段会读取这个节点的配置,同时注册一个数据变化的Watcher监听,一旦配置变化,所有订阅的客户端都可以获得这个配置变化。
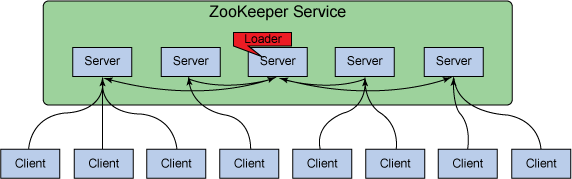
负载均衡
Zookeeper实现的是软负载均衡。
是指通过指定的名字来获取资源或者服务的地址,提供者的信息。利用Zookeeper很容易创建一个全局的路径,而这个路径就可以作为一个名字,它可以指向集群中的集群,提供的服务的地址,远程对象等。简单来说使用Zookeeper做命名服务就是用路径作为名字,路径上的数据就是其名字指向的实体。
阿里巴巴集团开源的分布式服务框架Dubbo中使用ZooKeeper来作为其命名服务,维护全局的服务地址列表。在Dubbo实现中:服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers目录下写入自己的URL地址,这个操作就完成了服务的发布。服务消费者启动的时候,订阅/dubbo/{serviceName}/providers目录下的提供者URL地址, 并向/dubbo/{serviceName} /consumers目录下写入自己的URL地址。注意,所有向ZK上注册的地址都是临时节点,这样就能够保证服务提供者和消费者能够自动感应资源的变化。另外,Dubbo还有针对服务粒度的监控,方法是订阅/dubbo/{serviceName}目录下所有提供者和消费者的信息。
分布式协调/通知
分布式协调/通知服务是分布式系统中不可缺少的一个环节,是讲不同的分布式组件有机结合在一起的关键。对于一个在多台机器上部署运行的应用,通常需要一个协调者coordinator来控制整个系统的运行。
Zookeeper中特有的Watcher注册与异步通知机制,能够很好的实现分布式环境下不同机器,甚至是不同系统之间的协调与通知,从而实现对数据变更的实时处理。
集群管理
传统集群管理需要在每个客户机安装Agent,这种方案不灵活而且Agent升级、功能都会有局限性。
监控系统在/clusterSevers节点上注册一个Watcher监听,但凡进行动态添加机器的操作,就会在/clusterSevers节点下创建一个临时节点:/clusterServers/[hostname]。这样监控系统就能实时监测到机器的变动情况。
Master选举
略
分布式锁
略
分布式队列
略
Zookeeper在大型分布式系统中的应用
Hadoop
在Hadoop中,Zookeeper用来实现HA,这部分逻辑在Hadoop Common HA模块中,HDFS的NameNode与YARN的ResourceManager都基于这个HA模块来实现自己的HA。在YARN中,Zookeeper也用来存储应用的运行状态。
HBase
在整个Hbase架构中,Zookeeper用来串起HBase集群和CLient。
Kafka
Kafka主要用来实现低延时的发送和收集大量的事件和日志数据,是一个吞吐量极高的分布式消息系统,其整体设计是典型的发布和订阅模式。Kafka使用Zookeeper的负载均衡策略来解决生产者和消费者的负载均衡问题。
Zookeeper在阿里巴巴
消息中间件Metamorphosis(用作负载均衡)、RPC框架Dubbo(用作服务注册)、基于MySQL数据库Binlog实现的增量订阅和消费组件Canal。在Canal中,Zookeeper用来实现主备切换HA。实时计算引擎JStrom使用Zookeeper负责协调Nimbus和Supervisor。