2017/3/14
RDBMS:关系型数据库管理系统
关系模型独立于语言
SQL有几种不同类型的语言:数据定义语言(DDL)、数据处理语言(DML)、数据控制语言(DCL)
DDL:用于处理数据对象的定义,包括的语句有CREATE、ALTER、DROP
DML:用于查询和修改数据,包括的语句有SELECT、INSERT、UPDATE、DELTE、MERGE
DCL:用于处理权限管理,包括的语句有GRANT、REVOKE
关系模型基于的两个分支:集合论和谓词逻辑
集合:一组对象、实体、
谓词:在关系模型中,谓词用于维护数据的逻辑完整性和定义它的结构;对数据进行过滤以定义其子集;在结合论中可以用谓词来定义集合
example:集合{0,1,2,3,4,5,6,7,8,9}可以定义为以下谓词为true的所有元素的集合==>"X是一个大于等于0,而小于等于9的整数"
关系模型的定义(Relational Model):表示数据的语义模型,理论基础是集合论和谓词逻辑
关系模型的目标:要用最少或者完全无冗余的支持完整数据的持久化表示,而且还要将数据完整性定义为数据的一部分
什么是关系(Relation)?
在集合论中关系是集合的一种表示,在关系模型中关系是相关信息的一个集合,在数据库的实现中就表现为(数据表)
关系模型的关键要点:一个关系代表一个集合ps:对关系进行操作的结果得到的还是一个关系
数据库中设计数据模型时,所有数据都是用关系来表示的
域或类型是最基础的关系型构建模块之一,一个域就是一个属性可能的(有效的)一组取值的集合
域是一种数据库中形式最简单的谓词,因为它限制属性允许的取值
关系模型最大的优点之一就是将数据完整性定义为模型的一部分,完整性是通过规则(或约束来实施的)
域完整性(Domain Integrity),约束的其他例子还包括提供实体完整性(entity Integrity)的候选键,以及提供引用完整性的外键(Referential Integrity)
候选键(candidate key):是指在关系中能够防止同一元组(数据行)多次出现的属性集(一个或多个属性),基于候选键的谓词能够唯一标识一行数据。在关系中可以定义多个候选键,可以任意选择一个候选键作为主键(Primary Key),换言之主键一定要在候选键中选择,主键以外的候选键成为备用候选键(alternate key)
外键(foreign key)用于实施引用完整性,外键只在关系(这里的关系在数据库中称之为表)中一个或多个属性上定义的,通过它引用另一个关系(数据库中即为表)中的候选键,这种约束要求引用关系中的外键属性值要与被引用关系(referenced relation)的候选键的属性值相一致
关系模型中的规范化规则(范式)
第一范式(1NF):要求表中的行必须是唯一的,属性应该是原子的,这个范式对关系的定义来说是冗余的(最低要求)
行的唯一性是通过在表中定义一个唯一的主键而实现的
第二范式(2NF):第二范式包括两条规则==>1)首页数据必须满足第一范式,其次要求非建属性和候选属性之间必须满足一定的条件,每个非建属性必须完全函数依赖于整个候选键ps:函数依赖指的是存在组合候选键中的某些字段决定非关键字段的情况
2017/3/15
第三范式(3NF):第三范式也有两条规则,首先数据必须满足第二范式,其次所有非建属性必须非传递依赖于候选键,这条规则意味着所有的非建属性都必须互相独立,换句话说,一个非建属性不能依赖于其他的非建属性
总的概括一下第二范式和第三范式:每个非键属性都依赖于键,全部键,除了键没有别的
联机事物处理(OLTP):数据首先进入联机事务处理系统,OLTP系统的重点是的数据的输入,而不是生成报表主要处理的事物包括插入、更新和删除数据,关系模型的目标主要定位于OLTP系统
数据仓库(Data WareHouses): 专为数据检索和生成报表而设计的环境,数据仓库最简单的设计就是所谓的星型模式,如果规范化一个维度表生成表示该维度的多个表,得到的就是雪花型维度,而包含雪花型 维度的模式成为雪花模式(相对于星型模式)
从原系统抽取数据,对数据进行处理,并将数据加载到数据仓库的工具成为ETL*(Extract Transform anf Load)。SQL Server提供一个称为Microsoft的SSIS(SQL Server Intergration Services)的工具来处理ETL需求
联机分析处理(OLAP):系统支持对聚合后的数据进行动态的在线分析,为OLAP需求而设计的特殊的产品--SSAS(这是一个独立于Sql Sever服务的一种服务或引擎)。用于管理和查询SSAS的数据方块的语言称为多为表达式(MDX,Multidimensional Expressions)
数据挖掘(DM,data mining),数据挖掘模型进行筛选数据;用于管理和查询数据挖掘模型的语言是数据挖掘扩展插件语句(DMX)
数据库:各种对象的容器,这些对象可以是表、视图、存储过程(stored procedure)等。
系统数据库:master、Resource、model、tempdb、msdb
数据库登录的账号可以关联到windows凭据,使用windows验证登陆不需要提供用户名和密码使用Sql server验证来连接SQL Server时就必须提供用户名和密码
数据库对象是将被授权访问的数据库对象的实体。每个数据库至少得有一个数据文件和一个事务日志文件。数据文件用于保存数据库对象数据,日志文件则保存SQL Server为了维护事物而需要的文件
表属于架构,而架构又属于数据库
在SQL Server环境中创建数据库代码如下:
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
ps:DB_ID('')接受一个数据库名称作为输入,返回它的内部数据库ID,如果输入名称的指定的数据库不存在这个函数将返回NULL
在例子中,使用的架构是dbo,在每个数据库中都会自动创建这个架构,,当用户没有将默认架构显示关联到其他架构时,就会将这个dbo作为默认架构。
以下代码是在数据库testdb中创建一个名为Employees的表:
USE testdb /**切换数据库**/
IF OBJECT_ID('dbo.Employees','U') IS NOT NULL /**OBJECT_ID('','')函数判断当前创建的表是否已经存在于testdb数据库中,该函数接受一个对象名称和类型作为它的参数 类型'U'代表用户表,如果该表在testdb数据库中存在,则删除它,然后再创建的新的表**/
DROP TABLE dbo.Employees;
CREATE TABLE dbo.Employees (
empid INT NOT NULL,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
hiredate DATE NOT NULL,
mgrid INT NULL,
ssn VARCHAR(20) NOT NULL,
salary MONEY NOT NULL
);
PS:上面的代码使用了前面推荐的两部分名称,如果省略架构名,SQL Server将使用与运行这段代码的数据库用户相关联的默认架构
数据的完整性:作为模型的一部分而实施的数据完整性(也就是说作为表定义的一部分)称为成为声明式数据完整性;用代码来实施的数据完整性称为过程式数据完整性
约束(主键约束、唯一约束、外键约束)
主键约束:以前面创建好的Employees表为例,在它的empid列上定义一个主键约束
ALTER TABLE dbo.Employees
ADD CONSTRAINT PK_Employees
PRIMARY KEY(empid);
唯一约束:唯一约束用来保证数据行的一个列(或一组列)数据的唯一,可以在数据库中实现关系模型的替换键的概念。
2017/3/16
SQL Server Management Studio中快捷键
Ctrl+k,Ctrl+c 注释选中行
以下代码在Employees表中定义了ssn列上的唯一约束:
ALTER TABLE dbo.Employees
ADD CONSTRAINT UNQ_Employees_ssn
UNIQUE(ssn);
外键约束:用于实施引用完整性。这种约束在引用表的一组属性上进行定义并指向被引用表中的一组候选键(主键或唯一约束)。注意引用表或被引用表可能是同一张表。外键的目的是为了将外键允许的值域限制为被引用列中现有的值。
以下代码创建了一个名为Orders的表,其主键定义在orderid列上:
--IF OBJECT_ID('dbo.Orders','U') IS NOT NULL
-- DROP TABLE dbo.Orders;
--CREATE TABLE dbo.Orders(
-- orderid INT NOT NULL,
-- empid INT NOT NULL,
-- custid VARCHAR(10) NOT NULL,
-- orderts DATETIME NOT NULL,
-- qty INT NOT NULL,
-- CONSTRAINT PK_Orders PRIMARY KEY(orderid)
--);
现在要在Orders表的empid列上添加一个外键约束,让它指向Employees表的主键的empid列,如下所示:
ALTER TABLE dbo.Orders
ADD CONSTRAINT FK_Orders_Employees
FOREIGN KEY(empid)
REFERENCES dbo.Employees(empid);
如果想限制Employees表中mgrid列支持的值域为同一张表中已经存在的那些empid列的值,可以增加以下约束:
ALTER TABLE dbo.Employees
ADD CONSTRAINT FK_Employees_Employees
FOREIGN KEY(mgrid)
REFERENCES dbo.Employees(empid);
禁止操作:当试图删除表被引用表中的行时,或更新被引用的候选键时,如果在引用表中存在相关的行,则此操作不能执行
CASCADE:操作将被级联到引用表中的相关行
ON DELETE CASCADE:意味着当从被引用表中删除一行时,RDBMS也将从引用表中删除相关的行
CHECK约束:定义在表中输入或修改一行数据之前必须满足的一个谓词
以下的检查约束能保证Employees表中的salary列只支持正数:
ALTER TABLE dbo.Employees
ADD CONSTRAINT CHK_Employees_salary
CHECK(salary>0);
默认约束:默认约束与特定的属性关联
以下代码为orderts属性定义了一个默认约束:
ALTER TABLE dbo.Orders
ADD CONSTRAINT DFT_Orders_orderts
DEFAULT(CURRENT_TIMESTAMP) FOR orderts;
第二章 单表查询
查询子句是查询语法的组成部分,当讨论逻辑查询处理中发生的某一部逻辑处理时,通常会使用阶段
FROM子句是逻辑处理阶段第一个要处理的查询子句,这个子句用于指定要查询的表名以及对这些表进行操作的表运算符
WHERE子句可以指定一个谓词或逻辑表达式,从而过滤由FROM阶段返回的行
SELECT firstname,lastname,ssn,salary
FROM dbo.Employees
WHERE empid=1;
TSQL使用的是三值谓词逻辑,返回结果为true和不为true是两个不同的概念,因为还有一个结果为unknown
GROUP BY子句:以指定的元素进行分组
SELECT empid,hiredate
FROM dbo.Employees
WHERE empid=2
GROUP BY empid,hiredate
--SELECT empid,YEAR(hiredate) as hiredate
-- FROM dbo.Employees
-- WHERE empid=2
-- GROUP BY empid,YEAR(hiredate);
因为聚合函数只为每个组返回一个值,所以一个元素如果不在GROUP BY列表中出现,就只能作为聚合函数(COUNT、SUM、AVG、MIN以及MAX)的输入
SELECT empid,firstname,lastname
FROM dbo.Employees
GROUP BY empid,firstname,lastname;
PS:如果试图引用不在GROUP BY列表中出现的属性(例如 ssn),而且也没有将其作为GROUP BY子句之后处理的任何子句中聚合函数的输入,SQL Server引擎就会报错
选择列表中的列 'dbo.Employees.ssn' 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。
注意所有的聚合函数都会忽略NULL值,只有一个例外-----COUNT(*)===>假设一个组有5行,其中qty列分别为 10,20,NULL,20,10。表达式COUNT(*)将返回5,因为这个组中有5行,而COUNT(qty)返回4,因为只有4行已知值,如果想处理不重复的已知值可以在聚合函数的圆括号中指定DISTINCT关键字
HAVING子句:用于指定对组进行过滤的谓词和表达式
记住SELECT子句是在FROM、WHERE、GROUP BY、HAVING子句后处理的
ORDER BY子句:用于展示数据时对输出结果中的行进行排序,从逻辑查询处理来看,ORDER BY是最后一个处理的子句。
SELECT empid,YEAR(orderts) AS orderyear,COUNT(*) AS numorders
FROM dbo.Orders
WHERE custid=1
GROUP BY empid,YEAR(orderts)
HAVING COUNT(*)>1
ORDER BY empid,orderyear;
表不保证是有序的,因为表是为了代表一个集合,而集合是无序的。
ORDER BY是唯一一个在SELEC阶段后被处理的阶段
排序出现的列不一定要出现在输出返回的类中,代码如下:
SELECT empid,firstname,lastname,salary
FROM dbo.Employees
ORDER BY hiredate;
当指定了DISTINCT以后,ORDER BY子句就被限制为只能选取在SELECT列表中出现的那些元素,以下的查询无效:
SELECT DISTINCT orderid
FROM dbo.Orders
ORDER BY empid;
消息 145,级别 15,状态 1,第 78 行
如果指定了 SELECT DISTINCT,那么 ORDER BY 子句中的项就必须出现在选择列表中。
TOP选项:用于限制查询返回的行数或百分比。如果要从Orders表中返回最近的5个订单可以采用如下的代码:
SELECT TOP(5) orderid,orderts,custid,empid
FROM dbo.Orders
ORDER BY orderts DESC;
当使用TOP时,同一ORDER BY 子句既担当了为TOP决定行的逻辑优先顺序的角色,同时也担当了它的常规角色(展示数据),只是最终生成的结果由表变成了具有固定顺序的游标。
PERCENT关键字:
SELECT TOP(50) PERCENT orderid,orderts,custid,empid
FROM dbo.Orders
ORDER BY orderts;
2017/03/17
OVER子句用于为行定义一个窗口,以便进行特定的运算:
SELECT empid,ssn,salary,
SUM(salary) OVER() AS totalvalue,
SUM(salary) OVER(PARTITION BY ssn ) AS custtotalValue
FROM dbo.Employees;
所有结果行的totalvalue列表示所有行的价格总数,custtotalValue列表示所有行中与当前行具有相同ssn值的那些行的价格总数
OVER子句的一个优点就是能够在返回基本列的同时 ,在同一行对他们进行聚合 。一下代码查询为Employees的每一行计算当前价格占总价格的百分比:
SELECT empid,ssn,salary,
100. *salary/ SUM(salary) OVER() AS totalvalue,
100. *salary/SUM(salary) OVER(PARTITION BY ssn ) AS custtotalValue
FROM dbo.Employees;
聚合函数和排名函数都是可以支持OVER子句的运算类型,由于OVER子句为这些函数提供了一个行的窗口,所以这些函数又称为开窗函数
OVER子句支持的四种排名函数:ROW_NUMBER(行号),RANK(排名),DENSE_RANK(密集排名),以及NTILE。以下代码演示了这些函数的用法:
SELECT empid,ssn,salary,
ROW_NUMBER() OVER(ORDER BY salary) AS rownum,
RANK() OVER(ORDER BY salary) AS rank,
DENSE_RANK() OVER(ORDER BY salary) AS dense_rank,
NTILE(10) OVER(ORDER BY salary) AS ntile
FROM dbo.Employees
ORDER BY salary;
RANK列为9表示前面有8行具有更小的排序值,DENSE_RANK列为9表示前面有8个更小的不同的排序值
表达式ROW_NUMBER() OVER(PARTITION BYcustidORDER BY oredrts)为各行中具有相同custid的子集独立的分配行号
SELECT orderid,empid,custid,orderts,
ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderts) AS rownum
FROM dbo.Orders
ORDER BY custid,orderts;
如果在SELECT处理阶段指定了开窗函数,开窗计算会在DISTINCT子句(如果存在)之前处理
总结点:作为目前为止已经讨论过的所有子句的总结,以下列出了他们的逻辑处理顺序:
FROM
WHERE
GROUP BY
HAVING
SELECT
1)OVER
2)DISTINCT
3)TOP
ORDER BY
谓词和运算符
T-SQL支持的谓词有IN、BETWEEN、LIKE等。
IN这个谓词用于检查一个值(标量表达式)是否与一组元素中的至少一个相等。以下代码查询返回订单orderid等于1、3、5的订单:
SELECT orderid,empid,custid,orderts
FROM dbo.Orders
WHERE orderid IN(1,3,5);
BETWEEN这个谓词用于检查一个值是否在指定的范围内,包括边界值,如下代码查询订单ID在2到5之间的订单:
SELECT orderid,empid,custid,orderts
FROM dbo.Orders
WHERE orderid BETWEEN 2 AND 5;
LIKE这个谓词用于检查一个字符串是否与指定的模式匹配,如下代码查询返回姓氏以'x'开头的所有雇员:
SELECT empid,firstname,lastname,salary
FROM dbo.Employees
WHERE lastname LIKE N'x%';
T-SQL中比较运算符的使用
以下查询返回订单日期在2017/03/05之后生成的所有订单:
SELECT orderid,empid,custid,orderts
FROM dbo.Orders
WHERE orderts>='2017/03/05';
以下的查询返回订单日期在2017/03/05之后并且orderid为1,3,5的所有订单:
SELECT orderid,empid,custid,orderts
FROM dbo.Orders
WHERE orderts>='2017/03/05'
AND orderid IN(1,3,5);
CASE表达式
case表达式是一个标量表达式,它基于条件逻辑来返回一个值。CASE表达式有两种:简单表达式和搜索表达式。
CASE简单格式将一个值(或一个标量)与一组可能的取值进行比较,并返回第一个匹配的结果。如果列表中没有值等于测试值,CASE表达式就返回其ELSE子句中列出的值。如果CASE表达式中没有ELSE子句,则默认将其视为ELSE NULL.以下代码用于描述categoryid列取值的信息:
SELECT orderid,empid,custid,
CASE custid
WHEN 1 THEN '顾客1'
WHEN 2 THEN '顾客2'
ELSE 'UNKNOWN CATEGORY'
END AS categoryName
FROM dbo.Orders;
CASE简单表达式只有一个测试值,而CASE搜索表达式不限于只进行相等性比较,代码如下:
SELECT empid,firstname,lastname,salary,
CASE
WHEN salary < 1500 THEN '工资较低'
WHEN salary BETWEEN 1500 AND 3000 THEN '工资一般'
WHEN salary > 3000 THEN '工资较高'
ELSE 'UNKNOWN SALARY'
END AS salaryDesc
FROM dbo.Employees;
NULL值
UNKNOWN和NOT(UNKNOWN)一样
如果想查找mgrid是NULL的所有行,不应该使用谓词mgrid=NULL,而应该使用mgrid IS NULL,以下代码是两种查询方式的对比:
SELECT empid,firstname,lastname
FROM dbo.Employees
WHERE mgrid=NULL;
返回空集
SELECT empid,firstname,lastname
FROM dbo.Employees
WHERE mgrid IS NULL;
1 dai xin
2 gu shiyi
3 li xueji
3行记录
2017/03/20
同时操作
SELECT子句中所有表达式的计算是没有顺序的,他们只是一组表达式。在逻辑上列表中的所有表达式都是在同一时刻进行计算的。以下代码是没有作用的:
SELECT orderid,YEAR(orderts) AS orderyear,orderyear +1 AS nextyear
FROM dbo.Orders;
SQL Server中的短路求值,代码示例如下:
SELECT col1,col2
FROM dbo.T1
WHERE col1 <> 0 AND col2 > 2*col1;
处理字符数据
SQL Server支持两种字符数据类型--普通字符和Unicode字符。普通字符数据类型包括CHAR和VARCHAR,Unicode字符类型包括NCHAR和NVARCHAR。
普通字符需要一个字节来保存每个字符,而Unicode字符需要两个字节来保存每个字符。
名称中不包含VAR元素的任何数据类型都是固定长度的(CHAR,NCHAR),SQL Server会按照列定义的大小,在行中为该列预留出固定的空间,所以该列的长度并不是字符的实际个数;名称中含有VAR元素的数据类型是可变长度(VARCHAR.NVARCHAR),SQL Sercver会在行中会字符串的实际长度来保存数据。
排序规则(collation)
得到系统中目前支持的所有排序规则及其描述,可以查询表函数fn_helpcollations(),代码如下所示:
SELECT name,description
FROM sys.fn_helpcollations();
当没有显示定义任何排序规则时,就默认使用字典排序(更确切的说排序规则名称中没有显示的出现BIN元素)。如果出现BIN元素,就表示要根据字符的二进制表示对字符数据进行排序和比较。
CI--数据不区分大小写
AS--数据区分重音
可以在4重不同的级别上定义排序规则:SQL Server实例,数据库,列,以及表达式。最低级的排序规则是比较有效的定义方式。
当创建用户数据库时,可以使用COLLATE子句指定数据库的排序规则,如果不指定则默认采用SQL Server实例的排序规则。
数据库的排序规则决定数据库中对象元数据的排序规则,同时也是用户表列的默认使用的排序规则。
以下查询是不区分大小写的:
SELECT empid,firstname,lastname
FROM dbo.Employees
WHERE lastname=N'XIN';
以下查询是区分大小写的:
SELECT empid,firstname,lastname
FROM dbo.Employees
WHERE lastname COLLATE Latin1_General_CS_AS =N'XIN';
单引号('')用于分割文字字符串,如果单引号是文字字符串的一部分,则需要由两个单引号表示('')
运算符和函数
字符串串联运算符
T-SQL提供加号运算符,可以将两个或多个字符串合并或串联成一个字符串。示例如下:
SELECT empid,firstname +N' '+lastname AS fullname
FROM dbo.Employees;
通过将一个CONCAT_NULL_YIELDS_NULL的会话选项设置为OFF,就可以改变SQL Server处理串联的方式。设置的代码如下:
SET CONCAT_NULL_YIELDS_NULL OFF;
如果想把NULL作为一个空字符串,则应该以编程的方式来实现。COALESCE()函数接受一列值,返回其中第一个不为NULL的值,COALESCE(region,N'')
SUBSTRING(string,start,length)---SELECT SUBSTRING('abcde',1,3),返回'abc'
LEFT、RIGHT函数。他们分别返回输入字符串从左边或右边开始指定字符的个数。SELECT RIGHT('abcde',3);
LEN和DATELENGTH函数,LEN函数返回字符串中的字符数,即字符长度,如果要得到字节数则选哟使用DATELENGTH函数
SELECT LEN(N'abcde');返回5
SELECT DATALENGTH(N'abcde');返回10;
PS:值得注意的是,字节数并不一定等于字符数,对于LEN()函数而言返回的是字符数。对于普通字符而言,这两个值相等;但是对于Unicode字符,这两个值不等,因为Unicode字符中每个字符需要两个字节来保存,所以对于Unicode字符而言,字节数等于2倍字符数。
CHARINDEX函数,返回字符串中某个子串第一次出现的起始位置。CHARINDEX(substring,string[,start_pos]),在String中没有找到SubString,则CHARINDEX返回0,示例代码如下:
SELECT CHARINDEX(' ','Dai Xin');
PATINDEX函数,PATINDEX(pattern,string)。 参数pattern使用的模式与T-SQL中LIKE谓词使用的模式类似,示例代码如下,返回结果为5:
SELECT PATINDEX('%[0-9]%','abcd123efgh');
REPLACE函数,将字符串中出现的所有某个子串替换为另一个字符串。REPLACE(string,substring1,substring2);该函数会将string中出现的所有substring1替换为substring2。示例代码如下:
SELECT REPLACE('1-A 2-B','-',':');
1:A 2:B
REPLACE函数也可以用来计算字符串中某个字符出现的次数。为此,先将先将字符串中所有的那个字符替换为空字符串(长度为0的字符串),再计算字符串的原始长度和新长度的差值。示例代码如下:
SELECT empid,lastname,LEN(lastname)-LEN(REPLACE(lastname,'i','')) AS numoccur
FROM dbo.Employees;
1 xin 1
2 shiyi 2
3 xueji 1
REPLICATE函数以指定的次数复制字符串的值。REPLICATE(string,n),示例代码如下:
SELECT REPLICATE('ABC',3);
ABCABCABC
整数类型的供应商ID的字符串表示是用CAST函数生成的,这个函数用于转换输入值的数据类型
STUFF函数可以先删除字符串中的一个字串,再插入一个新的字符串作为替换。STUFF(string,pos,delete_length,insertstring)。示例代码如下:
SELECT STUFF('xyz',2,1,'daixin');
xdaixinz
UPPER和LOWER函数将输入字符串中所有字符都转换为大写或小写。UPPER(string),LOWER(string)。
SELECT UPPER('daixin')
SELECT LOWER('DAIXIN');
RTRIM和LTRIM函数用于删除字符串中的尾随空格和前导空格。如果既想删除输入字符串的前导空格和尾随空格,则可以将一个函数的结果所谓另一个函数的输入来使用,示例代码如下:
SELECT RTRIM(LTRIM(' daixin '));
LIKE谓词
%通配符,%代表任意长度的字符串,包括空字符串,示例代码如下:
SELECT empid,lastname
FROM dbo.Employees
WHERE lastname LIKE N'x%';
_通配符,_代表任意单个字符,示例代码如下:
SELECT empid,lastname
FROM dbo.Employees
WHERE lastname LIKE N'_i%';
[<字符列>]通配符,方括号中包含一列字符,表示必须匹配列指定字符中的一个字符,示例代码如下:
SELECT empid,lastname
FROM dbo.Employees
WHERE lastname LIKE N'[xn]%';
[<字符>-<字符>]通配符,方括号中包含一个字符范围,表示必须匹配指定范围内的一个字符。示例代码如下:
SELECT empid,lastname
FROM dbo.Employees
WHERE lastname LIKE N'[a-z]%';
[^<字符列或范围>]通配符,表示不属于指定字符列或范围内的单个字符,示例代码如下:
SELECT empid,lastname
FROM dbo.Employees
WHERE lastname LIKE N'[^a-s]%';
ESCAPE转义字符
col1 LIKE '%!_%' ESCAPE '!';说明‘!’是转义字符的标识,那么后面的'_'就不是通配符
如果想指定字符串文字‘02/12/2017’的格式为mm/dd/yyyy,则可以使用样式号101
SELECT CONVERT(DATETIME,'02/12/2017',101);
2017-02-12 00:00:00.000
如果想指定字符串文字‘02/12/2017’的格式为dd/mm/yyyy,则可以使用样式号103
SELECT CONVERT(DATETIME,'02/12/2017',103);
2017-12-02 00:00:00.000
CURRENT_TIMESTAMP和GETDATE返回的内容相同,当时优先选用CURRENT_STAMP
以下代码为取得当前时间和时间函数的用法:
SELECT GETDATE() AS [GATEDATE],
CURRENT_TIMESTAMP AS [CURRENT_TIMESTAMP],
GETUTCDATE() AS [GETUTCDATE],
SYSDATETIME() AS [SYSDATETIME],
SYSUTCDATETIME() AS [SYSUTCDATETIME],
SYSDATETIMEOFFSET() AS [SYSDATETIMEOFFSET];
将CURRENT_TIMESTAMP或SYSDATETIME转换为DATE或TIME,代码如下所示:
SELECT CAST(SYSDATETIME() AS DATE) AS [CURRENT_DATE],
CAST(SYSDATETIME() AS TIME) AS [CURRENT_DATE];
CAST和CONVERT函数用于转换值的数据类型
语法:CAST(value AS datetype)
CONVERT(datetype,value[,style_number])
CAST是ANSI标准SQL ,CONVERT不是
以下代码是使用CAST和CONVERT处理时间和日期数据类型的例子:
SELECT CAST('20121225' AS DATE);
SELECT CAST(SYSDATETIME() AS DATE);
SELECT CAST(SYSDATETIME() AS TIME);
SELECT CONVERT(CHAR(8),CURRENT_TIMESTAMP,112);
SELECT CAST(CONVERT(CHAR(8),CURRENT_TIMESTAMP,112) AS DATETIME);
SELECT CONVERT(CHAR(12),CURRENT_TIMESTAMP,114);
SELECT CAST(CONVERT(CHAR(12),CURRENT_TIMESTAMP,114) AS DATETIME);
SWITCHOFFSET函数可以按指定的时区对输入的DATETIMEOFFSET值进行调整
SWITCHOFFSET(datetimeoffset_value,time_zone)
SELECT SWITCHOFFSET(SYSDATETIMEOFFSET(),'-05:00');//按时区-05:00调整
SELECT SWITCHOFFSET(SYSDATETIMEOFFSET(),'+00:00');//调整为UTC时间
TODATETIMEOFFSET函数
SELECT TODATETIMEOFFSET(SYSDATETIMEOFFSET(),'-05:00');
为当前日期增加一年DATEADD(part,n,dt_val)
SELECT DATEADD(year,1,'20170320');
DATEDIF返回两个日期和时间值之间相差的指定部分的计数:DATEDIFF(part,dt_val1,dt_val2)
SELECT DATEDIFF(day,'20121225','20170320');
DATEPART函数返回给定日期和时间值的指定部分的整数:
SELECT DATEPART(month,CURRENT_TIMESTAMP);
YEAR、MONTH、DAY函数是DATEPART的简略版本。
2017/03/21
以下代码返回给定日期的所在月份的最后一天,很重要:
SELECT DATEADD(month,DATEDIFF(month,'19991231','20170321'),'19991231');
所以解决一下问题就很容易了,以下代码返回订单日期是每个月最后一天的所有的订单:
SELECT orderid,empid,orderts,custid
FROM dbo.Orders
WHERE orderts=DATEADD(month,DATEDIFF(month,'19991231',orderts),'19991231');
可以用模式‘%a%a%'来表达字符'a'在字符串的任意位置至少出现了两次
在订单列表中返回总价格大于10000的订单,这个问题很容易被误解成返回价格大于10000的订单,注意这是两个不同的问题,分析该问题时,要知道首先这不是一行记录能解决的事情,我们得按orderid进行分组,分完组之后,我们再添加过滤条件,分析代码如下:
SELECT orderid,SUM(qty*unitprice) AS totalPrice
FROM dbo.Orders
GROUP BY orderid
HAVING SUM(qty*unitprice)>10000
ORDER BY totalPrice DESC;
以下代码返回平均运费最高的三个国家:

第三章 联接查询
JOIN表运算符对两个表进行操作,联接有三种基本类型:交叉联接、内链接、外联接。
交叉联接
ANSI SQL-92语法。示例代码如下:
SELECT e.empid,o.orderid
FROM dbo.Employees AS e
CROSS JOIN dbo.Orders AS o;
交叉联接的关键字 CROSS JOIN
ANSI SQL-89语法.示例代码如下:
SELECT e.empid,o.orderid
FROM dbo.Employees AS e,dbo.Orders AS o;
三种联接类型都支持自联接(self-join),在自联接中,必须为 表起别名,如果不为表指定别名,联接结果中的列名就会有歧义。
创建表Digits,并向其中插入数据
--IF OBJECT_ID('dbo.Digits','U') IS NOT NULL
-- DROP TABLE dbo.Digits;
--CREATE TABLE Digits(
-- digit INT NOT NULL PRIMARY KEY
--);
--INSERT INTO dbo.Digits(digit) VALUES (0),(1),(2),(3),(4),(5),(6),(7),(8),(9);
已下代码生成1-1000的整数序列:
SELECT D3.digit*100+D2.digit*10+D1.digit+1 AS n
FROM dbo.Digits AS D1
CROSS JOIN dbo.Digits AS D2
CROSS JOIN dbo.Digits AS D3
ORDER BY n;
内联接
ANSI SQL-92语法。须在两个表名之间指定INNER_JOIN关键字。INNER关键字是可选的,因为内联接是默认的联接方式,所以可以只单独指定JOIN关键字,联接条件的关键字是ON
以下代码是对数据库中的Employees表和Orders表进行内联接运算:
SELECT e.empid,e.firstname,e.lastname,o.orderid
FROM dbo.Employees AS e
JOIN dbo.Orders AS o
ON e.empid=o.orderid;
ANSI SQL-89语法.
SELECT e.empid,e.firstname,e.lastname,o.orderid
FROM dbo.Employees AS e,dbo.Orders AS o
WHERE e.empid=o.orderid;
特殊的联接实例:
组合联接(composite join)、不等联接(non-equi join)、多表联接(multi-table join)
组合联接:联接条件涉及联接两边的多个列的查询。
新建一个名为OrderDetailsAudit的客户审核表,代码如下:
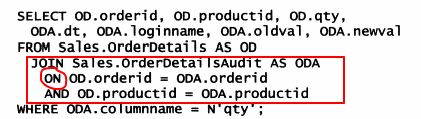
不等联接

多表联接

3.4外联接
外联接是在ANSI SQL-92中被引入的,因为它只有一种标准语法---在表名之间指定JOIN关键字,在ON子句中指明联接条件。
外联接会应用内联接的两个逻辑处理步骤,此外还多加一个外联接特有的第三步--添加外部行。
在外联接种要把一个表标记为‘保留表’
LEFT OUTER JOIN 、 RIGHT OUTER JOIN 、 FULL OUTER JOIN(OUTER 关键字可选)
LEFT关键字表示左边表的行是保留的
RIGHT关键字表示右边表的行是保留的
FULL关键字表示左右两边表的行都是保留的
新建并填充辅助表Nums的代码:
--SET NOCOUNT ON;
--IF OBJECT_ID('dbo.Nums','U') IS NOT NULL
-- DROP TABLE dbo.Employees;
--CREATE TABLE dbo.Nums(
-- n INT NOT NULL PRIMARY KEY
--);
--DECLARE @i AS INT =1;
--BEGIN TRAN
-- WHILE @i <=100000
-- BEGIN
-- INSERT INTO dbo.Nums VALUES (@i);
-- SET @i=@i+1;
-- END
-- COMMIT TRAN
-- SET NOCOUNT OFF;
这部分较难,过后再理解
1)写一条查询语句把所有雇员的记录复制5次。涉及的表:dbo.Employees和dbo.Nums
SELECT E.empid,E.firstname,E.lastname,Nums.n
FROM dbo.Employees AS E
CROSS JOIN dbo.Nums
WHERE Nums.n <= 5
ORDER BY n,empid;
2)写一个查询,为每个雇员和从2009/06/12至2009/06/16范围内的每天返回一行
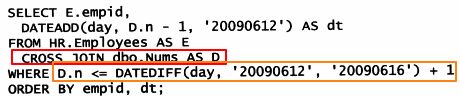
第4章 子查询
最外层查询结果集会返回给调用者,称为外部查询;内部查询结果是供外部查询使用的,也称为子查询。
子查询可以分为独立子查询和相关子查询。独立子查询不依赖于它所属的外部查询,而相关子查询必须依赖于它所属的外部查询。
子查询返回的结果可以是一个单独的值,多值或整个 表结果。本章重点讨论返回单个值的子查询(标量子查询)和多个值的子查询(多值子查询)
标量子查询是返回单个值的子查询,而不管它是不是独立子查询或是相关子查询,因为相关子查询也可以返回单个值。标量子查询可以出现在外部查询中使用单个值的任何地方(WHERE、 SELECT)
以下代码返回订单表中,订单ID最大的订单信息:
DECLARE @maxid AS INT =(SELECT MAX(orderid) FROM dbo.Orders);
SELECT orderid,orderts,empid,custid
FROM dbo.Orders
WHERE orderid=@maxid;
将变量转化成标量子查询,代码示例如下:
SELECT orderid,orderts,empid,custid
FROM dbo.Orders
WHERE orderid=(SELECT MAX(orderid) FROM dbo.Orders);
对于有效的标量子查询,它的返回值不能超过一个。如果标量子查询返回了多个值,在运行时可能会失效
SELECT orderid
FROM dbo.orders
WHERE empid=(SELECT E.empid FROM dbo.Employees AS E WHERE E.lastname LIKE N'x%');
消息 512,级别 16,状态 1,第 357 行
子查询返回的值不止一个。当子查询跟随在 =、!=、<、<=、>、>= 之后,或子查询用作表达式时,这种情况是不允许的。
多值子查询,它的返回值不只一个,谓词用IN,还是上面的例子:
SELECT orderid
FROM dbo.orders
WHERE empid IN (SELECT E.empid FROM dbo.Employees AS E WHERE E.lastname LIKE N'x%');
以下代码返回没有下过订单的客户:
SELECT empid,firstname,lastname
FROM dbo.Employees
WHERE empid NOT IN (SELECT O.empid FROM dbo.Orders O);
2017/03/22
新建一个名为Orders的表,并用TSQLFundamentals2008数据库中Orders表订单ID为偶数的订单来填充这个表

这里需要注意一下 SELECT INTO子句是用来创建一个目标表,并用查询出来的结果集填充这个表
借助辅助表Nums,筛选出介于Orders表中订单ID的最小值和最大值之间,而且没有在Orders表的订单ID集合中出现的数字。

以下代码是自己运行的结果:
USE tempdb;
--SELECT *
-- INTO dbo.Orders
-- FROM testdb.dbo.Orders
-- WHERE orderid % 2=0;
SELECT n
FROM testdb.dbo.Nums
WHERE n BETWEEN (SELECT MIN(O.orderid) FROM dbo.Orders AS O) AND (SELECT MAX(O.orderid) FROM dbo.Orders AS O)
AND n NOT IN (SELECT O.orderid FROM dbo.Orders AS O);
4.2相关子查询
相关子查询是指引用外部查询中出现的表的列的子查询,这就意味着子查询要依赖于外部查询。
以下代码查询会为每一个客户返回其订单ID的最大的订单:
SELECT orderid,custid,orderts,empid
FROM dbo.Orders AS O1
WHERE orderid=(
SELECT MAX(O2.orderid) FROM dbo.Orders AS O2
WHERE O2.custid=O1.custid//子查询依赖于外部查询,一个客户可能有多个订单,我们选择orderid最大的那个
);
以下代码返回,当前订单金额占客户订单总额的百分比:

4.2.1 EXISTS谓词
它的输入是一个子查询,,如果子查询能够返回任何行,则谓词返回TRUE,否则返回FALSE。
以下代码返回,下过订单的西班牙客户:

以下代码返回没有下过订单的西班牙客户:

EXISTS谓词是使用二值逻辑
对于每一个订单,返回当前订单的信息和前一个订单的ID,示例代码如下所示:
SELECT orderid,orderts,empid,
(SELECT MAX(O2.orderid) FROM dbo.Orders AS O2
WHERE O2.orderid < O1.orderid) AS preorderid
FROM dbo.Orders AS O1;
对于每一个订单,返回当前订单的信息和下一个订单的ID,示例代码如下:
SELECT orderid,orderts,empid,
(SELECT MIN(O2.orderid) FROM dbo.Orders AS O2
WHERE O2.orderid > O1.orderid) AS nextorderid
FROM dbo.Orders AS O1;
假设现在有个任务需要返回每年的订单年份、订货量,以及连续几年的订货量:

现在我们要返回没有下过订单的客户,示例代码如下:

现在我们假设Orders订单表中,新增一条数据然后将他的custid设置为NULL,那么以上的代码就会返回空集,unknown,那么这时候怎么做才能让他显示上面的结果呢?示例代码如下:
SELECT empid,firstname,lastname
FROM dbo.Employees AS E
WHERE empid NOT IN(SELECT O.empid FROM dbo.Orders AS O WHERE O.empid IS NOT NULL);
隐式的排除NULL值的一个例子是使用NOT EXISTS谓词取代NOT IN谓词,如下图所示:

--IF OBJECT_ID('dbo.MyShippers','U') IS NOT NULL
-- DROP TABLE dbo.MyShippers;
--CREATE TABLE dbo.MyShippers(
-- shipper_id INT NOT NULL,
-- companyname NVARCHAR(40) NOT NULL,
-- phone NVARCHAR(24) NOT NULL,
-- CONSTRAINT PK_MyShippers PRIMARY KEY (shipper_id)
--);
--INSERT INTO dbo.MyShippers(shipper_id,companyname,phone) VALUES(1,N'Shipper GVSUA','(503) 555-0137');
--INSERT INTO dbo.MyShippers(shipper_id,companyname,phone) VALUES(2,N'Shipper ETYNR','(425) 555-0136');
--INSERT INTO dbo.MyShippers(shipper_id,companyname,phone) VALUES(3,N'Shipper ZHISN','(415) 555-0138');
以下查询返回将订单发货给1号客户的发货人,代码如下:
SELECT shipper_id,companyname
FROM dbo.MyShippers
WHERE shipper_id IN(SELECT shipper_id FROM dbo.Orders WHERE custid=1);
以上的代码是有问题的,因为Orders表中没有shipper_id列,但是它也能返回以下的数据:
1 Shipper GVSUA
2 Shipper ETYNR
3 Shipper ZHISN
因为在子查询中没有找到,就会去外部查询中找,这样就变成了相关子查询了。
怎么解决这个问题呢?
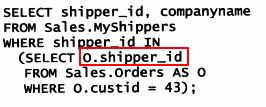
为表起别名,在被查询的列名前加上前缀。
1)返回活动最后一天所下的所有订单
SELECT orderid,empid,orderts,custid
FROM dbo.Orders
WHERE orderts=(SELECT MAX(O.orderts) FROM dbo.Orders AS O);
2)返回订单数量最多的客户的信息
SELECT TOP(1) WITH TIES O.custid
FROM dbo.Orders AS O
GROUP BY O.custid
ORDER BY COUNT(*) DESC;//先获取订单最多的客户的ID
//接下来在根据custid查询订单最多的客户下过的所有订单
SELECT custid,orderid,orderts,empid
FROM dbo.Orders
WHERE custid IN(SELECT TOP(1) WITH TIES O.custid
FROM dbo.Orders AS O
GROUP BY O.custid
ORDER BY COUNT(*) DESC);
3)返回从2017/03/10以后没有处理过订单的雇员
首先查询03/10以后的处理订单的雇员ID
SELECT O.empid
FROM dbo.Orders AS O
WHERE orderts > '20170310';
然后再在Employees表中查找empid列不属于以上结果集的记录
SELECT empid,firstname,lastname
FROM dbo.Employees
WHERE empid NOT IN(SELECT O.empid
FROM dbo.Orders AS O
WHERE orderts > '20170310');
还有例子没有列出来