在上一篇文章(Tensorflow(一)TFRecord生成与读取,这一篇我们来说一下如何利用预训练模型进行图像分类。下面我们分别通过一下几个.py文件来介绍原理以及如何运行。它们分别是preprocessing.py,model.py, train.py文件。
一、 .py文件介绍
- 首先我们来看一下
preprocess.py文件。我们可以根据preprocessing_fn_map(preprocessing_factory.py)看出不同模型对应的不同预处理文件
preprocessing_fn_map = {
'cifarnet': cifarnet_preprocessing,
'inception': inception_preprocessing,
'inception_v1': inception_preprocessing,
'inception_v2': inception_preprocessing,
'inception_v3': inception_preprocessing,
'inception_v4': inception_preprocessing,
'inception_resnet_v2': inception_preprocessing,
'lenet': lenet_preprocessing,
'mobilenet_v1': inception_preprocessing,
'mobilenet_v2': inception_preprocessing,
'mobilenet_v2_035': inception_preprocessing,
'mobilenet_v2_140': inception_preprocessing,
'nasnet_mobile': inception_preprocessing,
'nasnet_large': inception_preprocessing,
'pnasnet_mobile': inception_preprocessing,
'pnasnet_large': inception_preprocessing,
'resnet_v1_50': vgg_preprocessing,
'resnet_v1_101': vgg_preprocessing,
'resnet_v1_152': vgg_preprocessing,
'resnet_v1_200': vgg_preprocessing,
'resnet_v2_50': vgg_preprocessing,
'resnet_v2_101': vgg_preprocessing,
'resnet_v2_152': vgg_preprocessing,
'resnet_v2_200': vgg_preprocessing,
'vgg': vgg_preprocessing,
'vgg_a': vgg_preprocessing,
'vgg_16': vgg_preprocessing,
'vgg_19': vgg_preprocessing,
}
本篇文章使用resnet50来进行分类,因此我们选取vgg_preprocessing.py。但是这里我们稍做了修改。文件如下:
# -*- coding: utf-8 -*-
import math
import tensorflow as tf
slim = tf.contrib.slim
_R_MEAN = 123.68
_G_MEAN = 116.78
_B_MEAN = 103.94
_RESIZE_SIDE_MIN = 256
_RESIZE_SIDE_MAX = 512
# 普通切片,只能输入一张图片
# 指定切片的大小以及切片的位置
# 输入图片的长宽可以不知道,但通道数必须确定
def _crop(image, offset_height, offset_width, crop_height, crop_width):
"""Crops the given image using the provided offsets and sizes.
Note that the method doesn't assume we know the input image size but it does
assume we know the input image rank.
Args:
image: an image of shape [height, width, channels].
offset_height: a scalar tensor indicating the height offset.
offset_width: a scalar tensor indicating the width offset.
crop_height: the height of the cropped image.
crop_width: the width of the cropped image.
Returns:
the cropped (and resized) image.
Raises:
InvalidArgumentError: if the rank is not 3 or if the image dimensions are
less than the crop size.
"""
# 获取图片尺寸
original_shape = tf.shape(image)
# 判断图片通道数
rank_assertion = tf.Assert(
tf.equal(tf.rank(image), 3),
['Rank of image must be equal to 3.'])
with tf.control_dependencies([rank_assertion]):
cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]])
# 判断原始图片与切片的大小
size_assertion = tf.Assert(
tf.logical_and(
tf.greater_equal(original_shape[0], crop_height),
tf.greater_equal(original_shape[1], crop_width)),
['Crop size greater than the image size.'])
# 获取切片信息
offsets = tf.to_int32(tf.stack([offset_height, offset_width, 0]))
# Use tf.slice instead of crop_to_bounding box as it accepts tensors to
# define the crop size.
# 使用tf.slice进行切片,因为该方法能通过tf.Tensor来定义切片尺寸
with tf.control_dependencies([size_assertion]):
image = tf.slice(image, offsets, cropped_shape)
# 设置图片尺寸
return tf.reshape(image, cropped_shape)
# 随机切片
# 要求所有输入图片的尺寸一致
# 可以输入一些列图片,所有图片的切片方式相同
def _random_crop(image_list, crop_height, crop_width):
"""Crops the given list of images.
The function applies the same crop to each image in the list. This can be
effectively applied when there are multiple image inputs of the same
dimension such as:
image, depths, normals = _random_crop([image, depths, normals], 120, 150)
Args:
image_list: a list of image tensors of the same dimension but possibly
varying channel.
crop_height: the new height.
crop_width: the new width.
Returns:
the image_list with cropped images.
Raises:
ValueError: if there are multiple image inputs provided with different size
or the images are smaller than the crop dimensions.
"""
if not image_list:
raise ValueError('Empty image_list.')
# Compute the rank assertions.
# 判断每张图片的rank,必须为3
rank_assertions = []
for i in range(len(image_list)):
image_rank = tf.rank(image_list[i])
rank_assert = tf.Assert(
tf.equal(image_rank, 3),
['Wrong rank for tensor %s [expected] [actual]',
image_list[i].name, 3, image_rank])
rank_assertions.append(rank_assert)
with tf.control_dependencies([rank_assertions[0]]):
# 判断图片尺寸与切片尺寸
image_shape = tf.shape(image_list[0])
image_height = image_shape[0]
image_width = image_shape[1]
crop_size_assert = tf.Assert(
tf.logical_and(
tf.greater_equal(image_height, crop_height),
tf.greater_equal(image_width, crop_width)),
['Crop size greater than the image size.'])
asserts = [rank_assertions[0], crop_size_assert]
# 判断所有图片尺寸是否一致
for i in range(1, len(image_list)):
image = image_list[i]
asserts.append(rank_assertions[i])
with tf.control_dependencies([rank_assertions[i]]):
shape = tf.shape(image)
height = shape[0]
width = shape[1]
height_assert = tf.Assert(
tf.equal(height, image_height),
['Wrong height for tensor %s [expected][actual]',
image.name, height, image_height])
width_assert = tf.Assert(
tf.equal(width, image_width),
['Wrong width for tensor %s [expected][actual]',
image.name, width, image_width])
asserts.extend([height_assert, width_assert])
# Create a random bounding box.
#
# Use tf.random_uniform and not numpy.random.rand as doing the former would
# generate random numbers at graph eval time, unlike the latter which
# generates random numbers at graph definition time.
# 随机切片
with tf.control_dependencies(asserts):
max_offset_height = tf.reshape(image_height - crop_height + 1, [])
with tf.control_dependencies(asserts):
max_offset_width = tf.reshape(image_width - crop_width + 1, [])
offset_height = tf.random_uniform(
[], maxval=max_offset_height, dtype=tf.int32)
offset_width = tf.random_uniform(
[], maxval=max_offset_width, dtype=tf.int32)
return [_crop(image, offset_height, offset_width,
crop_height, crop_width) for image in image_list]
# 中心切片
# 要求输入图片的长宽相同,通道数可以不一样
def _central_crop(image_list, crop_height, crop_width):
"""Performs central crops of the given image list.
Args:
image_list: a list of image tensors of the same dimension but possibly
varying channel.
crop_height: the height of the image following the crop.
crop_width: the width of the image following the crop.
Returns:
the list of cropped images.
"""
outputs = []
for image in image_list:
image_height = tf.shape(image)[0]
image_width = tf.shape(image)[1]
offset_height = (image_height - crop_height) / 2
offset_width = (image_width - crop_width) / 2
outputs.append(_crop(image, offset_height, offset_width,
crop_height, crop_width))
return outputs
def _normalize(image, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
"""Normalizes an image."""
image = tf.to_float(image)
return tf.div(tf.div(image, 255.) - mean, std)
def _random_rotate(image, rotate_prob=0.5, rotate_angle_max=30,
interpolation='BILINEAR'):
"""Rotates the given image using the provided angle.
Args:
image: An image of shape [height, width, channels].
rotate_prob: The probability to roate.
rotate_angle_angle: The upper bound of angle to ratoted.
interpolation: One of 'BILINEAR' or 'NEAREST'.
Returns:
The rotated image.
"""
def _rotate():
rotate_angle = tf.random_uniform([], minval=-rotate_angle_max,
maxval=rotate_angle_max,
dtype=tf.float32)
rotate_angle = tf.div(tf.multiply(rotate_angle, math.pi), 180.)
rotated_image = tf.contrib.image.rotate([image], [rotate_angle],
interpolation=interpolation)
return tf.squeeze(rotated_image)
rand = tf.random_uniform([], minval=0, maxval=1)
return tf.cond(tf.greater(rand, rotate_prob), lambda: image, _rotate)
def _border_expand(image, mode='CONSTANT', constant_values=255):
"""Expands the given image.
Args:
Args:
image: A 3-D image `Tensor`.
output_height: The height of the image after Expanding.
output_width: The width of the image after Expanding.
resize: A boolean indicating whether to resize the expanded image
to [output_height, output_width, channels] or not.
Returns:
expanded_image: A 3-D tensor containing the resized image.
"""
shape = tf.shape(image)
height = shape[0]
width = shape[1]
def _pad_left_right():
pad_left = tf.floordiv(height - width, 2)
pad_right = height - width - pad_left
return [[0, 0], [pad_left, pad_right], [0, 0]]
def _pad_top_bottom():
pad_top = tf.floordiv(width - height, 2)
pad_bottom = width - height - pad_top
return [[pad_top, pad_bottom], [0, 0], [0, 0]]
paddings = tf.cond(tf.greater(height, width),
_pad_left_right,
_pad_top_bottom)
expanded_image = tf.pad(image, paddings, mode=mode,
constant_values=constant_values)
return expanded_image
def border_expand(image, mode='CONSTANT', constant_values=255,
resize=False, output_height=None, output_width=None,
channels=3):
"""Expands (and resize) the given image."""
expanded_image = _border_expand(image, mode, constant_values)
if resize:
if output_height is None or output_width is None:
raise ValueError('`output_height` and `output_width` must be '
'specified in the resize case.')
expanded_image = _fixed_sides_resize(expanded_image, output_height,
output_width)
expanded_image.set_shape([output_height, output_width, channels])
return expanded_image
# 减去平均数
# 输入一张图片,要求知道其通道数
def _mean_image_subtraction(image, means):
"""Subtracts the given means from each image channel.
For example:
means = [123.68, 116.779, 103.939]
image = _mean_image_subtraction(image, means)
Note that the rank of `image` must be known.
Args:
image: a tensor of size [height, width, C].
means: a C-vector of values to subtract from each channel.
Returns:
the centered image.
Raises:
ValueError: If the rank of `image` is unknown, if `image` has a rank other
than three or if the number of channels in `image` doesn't match the
number of values in `means`.
"""
if image.get_shape().ndims != 3:
raise ValueError('Input must be of size [height, width, C>0]')
num_channels = image.get_shape().as_list()[-1]
if len(means) != num_channels:
raise ValueError('len(means) must match the number of channels')
# 分别获取三个通道,并减去平均数,再组合起来
channels = tf.split(axis=2, num_or_size_splits=num_channels, value=image)
for i in range(num_channels):
channels[i] -= means[i]
return tf.concat(axis=2, values=channels)
# 通过图片的原有的长宽,以及要求的resize后短边大小,获取resize后图片的长宽
def _smallest_size_at_least(height, width, smallest_side):
"""Computes new shape with the smallest side equal to `smallest_side`.
Computes new shape with the smallest side equal to `smallest_side` while
preserving the original aspect ratio.
Args:
height: an int32 scalar tensor indicating the current height.
width: an int32 scalar tensor indicating the current width.
smallest_side: A python integer or scalar `Tensor` indicating the size of
the smallest side after resize.
Returns:
new_height: an int32 scalar tensor indicating the new height.
new_width: and int32 scalar tensor indicating the new width.
"""
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
height = tf.to_float(height)
width = tf.to_float(width)
smallest_side = tf.to_float(smallest_side)
# 判断长宽大小,获取比例,得到计算resize后的图片大小
scale = tf.cond(tf.greater(height, width),
lambda: smallest_side / width,
lambda: smallest_side / height)
new_height = tf.to_int32(tf.rint(height * scale))
new_width = tf.to_int32(tf.rint(width * scale))
return new_height, new_width
# 按比例resize图片
# 输入一张图片与短边的大小
def _aspect_preserving_resize(image, smallest_side):
"""Resize images preserving the original aspect ratio.
Args:
image: A 3-D image `Tensor`.
smallest_side: A python integer or scalar `Tensor` indicating the size of
the smallest side after resize.
Returns:
resized_image: A 3-D tensor containing the resized image.
"""
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
shape = tf.shape(image)
height = shape[0]
width = shape[1]
new_height, new_width = _smallest_size_at_least(height, width, smallest_side)
image = tf.expand_dims(image, 0)
# 通过短边与图片长宽,获取reisze后图片长宽
resized_image = tf.image.resize_bilinear(image, [new_height, new_width],
align_corners=False)
# 设置结果尺寸
resized_image = tf.squeeze(resized_image)
resized_image.set_shape([None, None, 3])
return resized_image
def _fixed_sides_resize(image, output_height, output_width):
"""Resize images by fixed sides.
Args:
image: A 3-D image `Tensor`.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
Returns:
resized_image: A 3-D tensor containing the resized image.
"""
output_height = tf.convert_to_tensor(output_height, dtype=tf.int32)
output_width = tf.convert_to_tensor(output_width, dtype=tf.int32)
image = tf.expand_dims(image, 0)
resized_image = tf.image.resize_nearest_neighbor(
image, [output_height, output_width], align_corners=False)
resized_image = tf.squeeze(resized_image)
resized_image.set_shape([None, None, 3])
return resized_image
# 获取训练图片
def preprocess_for_train(image,
output_height,
output_width,
resize_side_min=_RESIZE_SIDE_MIN,
resize_side_max=_RESIZE_SIDE_MAX,
border_expand=False, normalize=False,
preserving_aspect_ratio_resize=True):
"""Preprocesses the given image for training.
Note that the actual resizing scale is sampled from
[`resize_size_min`, `resize_size_max`].
Args:
image: A `Tensor` representing an image of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
resize_side_min: The lower bound for the smallest side of the image for
aspect-preserving resizing.
resize_side_max: The upper bound for the smallest side of the image for
aspect-preserving resizing.
Returns:
A preprocessed image.
"""
image = _random_rotate(image, rotate_angle_max=20)
if border_expand:
image = _border_expand(image)
if preserving_aspect_ratio_resize:
resize_side = tf.random_uniform(
[], minval=resize_side_min, maxval=resize_side_max+1, dtype=tf.int32)
image = _aspect_preserving_resize(image, resize_side)
else:
image = _fixed_sides_resize(image, resize_side_min, resize_side_min)
image = _random_crop([image], output_height, output_width)[0]
image.set_shape([output_height, output_width, 3])
image = tf.to_float(image)
image = tf.image.random_flip_left_right(image)
if normalize:
return _normalize(image)
return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
# 获取预测图片
def preprocess_for_eval(image, output_height, output_width, resize_side,
border_expand=False, normalize=False,
preserving_aspect_ratio_resize=True):
"""Preprocesses the given image for evaluation.
Args:
image: A `Tensor` representing an image of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
resize_side: The smallest side of the image for aspect-preserving resizing.
Returns:
A preprocessed image.
"""
if border_expand:
image = _border_expand(image)
if preserving_aspect_ratio_resize:
image = _aspect_preserving_resize(image, resize_side)
else:
image = _fixed_sides_resize(image, resize_side, resize_side)
image = _central_crop([image], output_height, output_width)[0]
image.set_shape([output_height, output_width, 3])
image = tf.to_float(image)
if normalize:
return _normalize(image)
return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
def preprocess_image(image, output_height, output_width, is_training=False,
resize_side_min=_RESIZE_SIDE_MIN,
resize_side_max=_RESIZE_SIDE_MAX,
border_expand=False, normalize=False,
preserving_aspect_ratio_resize=True):
"""Preprocesses the given image.
Args:
image: A `Tensor` representing an image of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
is_training: `True` if we're preprocessing the image for training and
`False` otherwise.
resize_side_min: The lower bound for the smallest side of the image for
aspect-preserving resizing. If `is_training` is `False`, then this value
is used for rescaling.
resize_side_max: The upper bound for the smallest side of the image for
aspect-preserving resizing. If `is_training` is `False`, this value is
ignored. Otherwise, the resize side is sampled from
[resize_size_min, resize_size_max].
Returns:
A preprocessed image.
"""
if is_training:
return preprocess_for_train(image, output_height, output_width,
resize_side_min, resize_side_max,
border_expand, normalize,
preserving_aspect_ratio_resize)
else:
return preprocess_for_eval(image, output_height, output_width,
resize_side_min, border_expand, normalize,
preserving_aspect_ratio_resize)
# 通过is_training来判断,是获取训练图片还是预测图片
def preprocess_images(images, output_height, output_width, is_training=False,
resize_side_min=_RESIZE_SIDE_MIN,
resize_side_max=_RESIZE_SIDE_MAX,
border_expand=False, normalize=False,
preserving_aspect_ratio_resize=True):
"""Preprocesses the given image.
Args:
images: A `Tensor` representing a batch of images of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
is_training: `True` if we're preprocessing the image for training and
`False` otherwise.
resize_side_min: The lower bound for the smallest side of the image
for aspect-preserving resizing. If `is_training` is `False`, then
this value is used for rescaling.
resize_side_max: The upper bound for the smallest side of the image
for aspect-preserving resizing. If `is_training` is `False`, this
value is ignored. Otherwise, the resize side is sampled from
[resize_size_min, resize_size_max].
Returns:
A batch of preprocessed images.
"""
images = tf.cast(images, tf.float32)
def _preprocess_image(image):
return preprocess_image(image, output_height, output_width,
is_training, resize_side_min,
resize_side_max, border_expand, normalize,
preserving_aspect_ratio_resize)
return tf.map_fn(_preprocess_image, elems=images)
具体做法:
- 图片预处理:对RGB三个通道, 分别减去ImageNet训练集的均值
- 训练:
a. 随机获取短边长度[256, 512]并等比例resize图片
b. 随机水平镜像。
c. 随机获取224*224的切片。
d. 减去ImageNet训练集的RGB均值。 - 预测:
a. 给定短边长度,等比例resize图片。
b. 中心切片。
c. 减去ImageNet训练集的RGB均值。 - 这里需要注意的是resize图片时,对图片尺寸没有要求(就算原始图片比目标图片尺寸小也没关系),
crop时,对原始图片尺寸有要求(必须大于切片尺寸,否则报错)
* 具体代码详细是如何进行操作的我们可以通过这篇文章来了解(Inside TF-Slim(13) preprocessing(图像增强相关)。
- 下面我们来介绍一下
model.py
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.contrib.slim import nets
import preprocessing
slim = tf.contrib.slim
class Model(object):
"""xxx definition."""
def __init__(self, num_classes, is_training,
fixed_resize_side=368,
default_image_size=336):
"""Constructor.
Args:
is_training: A boolean indicating whether the training version of
computation graph should be constructed.
num_classes: Number of classes.
"""
self._num_classes = num_classes
self._is_training = is_training
self._fixed_resize_side = fixed_resize_side
self._default_image_size = default_image_size
def preprocess(self, inputs):
"""preprocessing.
Outputs of this function can be passed to loss or postprocess functions.
Args:
preprocessed_inputs: A float32 tensor with shape [batch_size,
height, width, num_channels] representing a batch of images.
Returns:
prediction_dict: A dictionary holding prediction tensors to be
passed to the Loss or Postprocess functions.
"""
preprocessed_inputs = preprocessing.preprocess_images(
inputs, self._default_image_size, self._default_image_size,
resize_side_min=self._fixed_resize_side,
is_training=self._is_training,
border_expand=True, normalize=False,
preserving_aspect_ratio_resize=False)
preprocessed_inputs = tf.cast(preprocessed_inputs, tf.float32)
return preprocessed_inputs
def predict(self, preprocessed_inputs):
"""Predict prediction tensors from inputs tensor.
Outputs of this function can be passed to loss or postprocess functions.
Args:
preprocessed_inputs: A float32 tensor with shape [batch_size,
height, width, num_channels] representing a batch of images.
Returns:
prediction_dict: A dictionary holding prediction tensors to be
passed to the Loss or Postprocess functions.
"""
with slim.arg_scope(nets.resnet_v1.resnet_arg_scope()):
net, endpoints = nets.resnet_v1.resnet_v1_50(
preprocessed_inputs, num_classes=None,
is_training=self._is_training)
net = tf.squeeze(net, axis=[1, 2])
logits = slim.fully_connected(net, num_outputs=self.num_classes,
activation_fn=None, scope='Predict')
prediction_dict = {'logits': logits}
return prediction_dict
def postprocess(self, prediction_dict):
"""Convert predicted output tensors to final forms.
Args:
prediction_dict: A dictionary holding prediction tensors.
**params: Additional keyword arguments for specific implementations
of specified models.
Returns:
A dictionary containing the postprocessed results.
"""
logits = prediction_dict['logits']
logits = tf.nn.softmax(logits)
classes = tf.argmax(logits, axis=1)
postprocessed_dict = {'logits': logits,
'classes': classes}
return postprocessed_dict
def loss(self, prediction_dict, groundtruth_lists):
"""Compute scalar loss tensors with respect to provided groundtruth.
Args:
prediction_dict: A dictionary holding prediction tensors.
groundtruth_lists_dict: A dict of tensors holding groundtruth
information, with one entry for each image in the batch.
Returns:
A dictionary mapping strings (loss names) to scalar tensors
representing loss values.
"""
logits = prediction_dict['logits']
slim.losses.sparse_softmax_cross_entropy(
logits=logits,
labels=groundtruth_lists,
scope='Loss')
loss = slim.losses.get_total_loss()
loss_dict = {'loss': loss}
return loss_dict
def accuracy(self, postprocessed_dict, groundtruth_lists):
"""Calculate accuracy.
Args:
postprocessed_dict: A dictionary containing the postprocessed
results
groundtruth_lists: A dict of tensors holding groundtruth
information, with one entry for each image in the batch.
Returns:
accuracy: The scalar accuracy.
"""
classes = postprocessed_dict['classes']
accuracy = tf.reduce_mean(
tf.cast(tf.equal(classes, groundtruth_lists), dtype=tf.float32))
return accuracy
a. preprocess对图片进行变化增广扩充。
b. predict我们可以通过resnet_v1.py上面的使用resnet说明。具体细节可以参考Tensorflow(二) Residual Network原理及官方代码介绍。
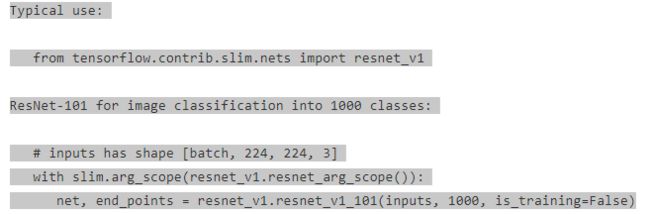
def predict(self, preprocessed_inputs):
"""Predict prediction tensors from inputs tensor.
Outputs of this function can be passed to loss or postprocess functions.
Args:
preprocessed_inputs: A float32 tensor with shape [batch_size,
height, width, num_channels] representing a batch of images.
Returns:
prediction_dict: A dictionary holding prediction tensors to be
passed to the Loss or Postprocess functions.
"""
with slim.arg_scope(nets.resnet_v1.resnet_arg_scope()):
net, endpoints = nets.resnet_v1.resnet_v1_50(
preprocessed_inputs, num_classes=None,
is_training=self._is_training)
net = tf.squeeze(net, axis=[1, 2])
logits = slim.fully_connected(net, num_outputs=self.num_classes,
activation_fn=None, scope='Predict')
prediction_dict = {'logits': logits}
return prediction_dict
TensorFlow-slim 封装好的 nets.resnet_v1.resnet_v1_50 神经网络得到图像特征,因为 ResNet-50 是用于 1000 个类的分类的,所以需要设置参数 num_classes=None 禁用它的最后一个输出层。我们假设输入的图像批量形状为 [None, 224, 224, 3],则 resnet_v1_50 函数返回的形状为 [None, 1, 1, 2048],为了输入到全连接层,需要用函数 tf.squeeze 去掉形状为 1 的第 1,2 个索引维度。最后,连接再一个全连接层得到 self.num_classes 个类的预测输出。
c. def loss()我们使用 sparse_softmax_cross_entropy来计算loss。
d. def accuracy我们同时为了方便展现我们的accuracy我们在这里也计算accuracy。
- 下面我们来介绍我们的
train.py文件
# -*- coding: utf-8 -*-
# @Time : 2018/12/3 22:11
# @Author : MaochengHu
# @Email : [email protected]
# @File : train.py
# @Software: PyCharm
import configparser
from read_tfrecord import read_tfrecord
import os
import tensorflow as tf
import model
import preprocessing
slim = tf.contrib.slim
config = configparser.ConfigParser()
config.read('params.config')
def get_init_fn():
"""Returns a function run by che chief worker to warm-start the training.
Modified from:
https://github.com/tensorflow/models/blob/master/research/slim/
train_image_classifier.py
Note that the init_fn is only run when initializing the model during the
very first global step.
Returns:
An init function run by the supervisor.
"""
checkpoint_path = config.get("finetune_ckpt", "ckpt_path")
logdir = config.get("finetune_ckpt", "logdir")
if checkpoint_path is None:
return None
# Warn the user if a checkpoint exists in the train_dir. Then we'll be
# ignoring the checkpoint anyway.
if tf.train.latest_checkpoint(logdir):
tf.logging.info(
'Ignoring --checkpoint_path because a checkpoint already exists ' +
'in %s' % logdir)
return None
if tf.gfile.IsDirectory(logdir):
checkpoint_path = tf.train.latest_checkpoint(checkpoint_path)
else:
checkpoint_path = checkpoint_path
tf.logging.info('Fine-tuning from %s' % checkpoint_path)
variables_to_restore = slim.get_variables_to_restore()
return slim.assign_from_checkpoint_fn(
checkpoint_path,
variables_to_restore,
ignore_missing_vars=True)
def configure_learning_rate(num_samples_per_epoch, global_step):
"""Configures the learning rate.
Modified from:
https://github.com/tensorflow/models/blob/master/research/slim/
train_image_classifier.py
Args:
num_samples_per_epoch: he number of samples in each epoch of training.
global_step: The global_step tensor.
Returns:
A `Tensor` representing the learning rate.
"""
num_epochs_per_decay = config.getfloat("model_params", "num_epochs_per_decay")
batch_size = config.getint("model_params", "batch_size")
learning_rate = config.getfloat("model_params", "learning_rate")
learning_rate_decay_factor = config.getfloat("model_params", "learning_rate_decay_factor")
decay_steps = int(num_samples_per_epoch * num_epochs_per_decay/batch_size)
return tf.train.exponential_decay(learning_rate,
global_step,
decay_steps,
learning_rate_decay_factor,
staircase=True,
name='exponential_decay_learning_rate')
def train():
tfrecord_path = config.get("input_path", "tfrecord_path")
resize_height = config.getint("image_size", "resize_height")
resize_width = config.getint("image_size", "resize_width")
num_samples = config.getint("input_data", "num_samples")
num_classes = config.getint("input_data", "num_class")
batch_size = config.getint("model_params", "batch_size")
checkpoint_path = config.get("finetune_ckpt", "ckpt_path")
logdir = config.get("finetune_ckpt", "logdir")
num_steps = config.getint("model_params", "num_steps")
resized_image, labels, image, height, width = read_tfrecord(tfrecord_path=tfrecord_path,
num_samples=num_samples,
num_classes=num_classes,
resize_height=resize_height,
resize_width=resize_width)
image = preprocessing.border_expand(image, resize=True, output_height=368, output_width=368)
inputs, labels = tf.train.batch([image, labels], batch_size=batch_size, allow_smaller_final_batch=True)
cls_model = model.Model(is_training=True, num_classes=7)
preprocessed_inputs = cls_model.preprocess(inputs)
prediction_dict = cls_model.predict(preprocessed_inputs)
loss_dict = cls_model.loss(prediction_dict, labels)
loss = loss_dict['loss']
postprocessed_dict = cls_model.postprocess(prediction_dict)
acc = cls_model.accuracy(postprocessed_dict, labels)
tf.summary.scalar('loss', loss)
tf.summary.scalar('accuracy', acc)
global_step = slim.create_global_step()
learning_rate = configure_learning_rate(num_samples, global_step)
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,
momentum=0.9)
train_op = slim.learning.create_train_op(loss, optimizer,
summarize_gradients=True)
tf.summary.scalar('learning_rate', learning_rate)
init_fn = get_init_fn()
slim.learning.train(train_op=train_op, logdir=logdir,
init_fn=init_fn, number_of_steps=num_steps,
save_summaries_secs=20,
save_interval_secs=600)
def main():
train()
if __name__ == '__main__':
main()
a. tf.train.batch我们来详细介绍一下这个函数。首先我们先看一下它内部可以传哪些参数。
tf.train.batch(tensors,
batch_size,
num_threads=1,
capacity=32,
enqueue_many=False,
shapes=None,
dynamic_pad=False,
allow_smaller_final_batch=False,
shared_name=None,
name=None )
作用:用来创建tensor的batches.
参数介绍 :
- tensors: 送入队列的tensor列表或者字典,这里我们传入的是列表,
tf.train.batch函数返回值是相同类型的tensors。- batches_size: 我们一个batch的大小。
- num_threads 入队tensors的线程数,如果
num_thread>1, 则batch操作非确定的。- capacity - 整数,队列容量,队列里样本元素的最大数.
- enqueue_many - tensors 内的每个 tensor 是否是单个样本.
- shapes - (可选)每个样本的 shape. 默认是 tensors 的shapes.
- dynamic_pad - Boolean 值. 输入 shapes 的变量维度. 出队后会自动填补维度,以保持batch内 shapes 一致.
- allow_smaller_final_batch - (可选) Boolean 值. 如果队列中样本不足 batch,允许最后的 batch 样本数小于 batch_size.
- shard_name - (可选). 如果设置了该参数,则在多个会话给定的名字时,共享队列.
- name - (可选). 操作operations 的名字.
具体说明可以参考这篇文章TensorFlow - tf.train.batch 函数。
b. configure_learning_rate
他的步骤:
1.首先使用较大学习率(目的:为快速得到一个比较优的解);
2.然后通过迭代逐步减小学习率(目的:为使模型在训练后期更加稳定);
tf.train.exponential_decay(
learning_rate,初始学习率
global_step,当前迭代次数
decay_steps,衰减速度(在迭代到该次数时学习率衰减为earning_rate * decay_rate)
decay_rate,学习率衰减系数,通常介于0-1之间。
staircase=False,(默认值为False,当为True时,(global_step/decay_steps)则被转化为整数) ,选择不同的衰减方式。
name=None
)
最终我们得到的学习率呈现如下公式变化
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
直观解释:假设给定初始学习率learning_rate为0.1,学习率衰减率为0.1,decay_steps为10000。
则随着迭代次数从1到10000,当前的学习率decayed_learning_rate慢慢的从0.1降低为0.10.1=0.01,
当迭代次数到20000,当前的学习率慢慢的从0.01降低为0.10.1^2=0.001,以此类推。 也就是说每10000次迭代,学习率衰减为前10000次的十分之一,该衰减是连续的,这是在staircase为False的情况下。如果staircase为True,则global_step / decay_steps始终取整数,也就是说衰减是突变的,每decay_steps次变化一次,变化曲线是阶梯状。
- 我们的params.config文件
[input_path]
tfrecord_path = /data1/humaoc_file/classify/data/train_tfrecord/train.record
[input_data]
num_samples = 14635
num_class = 7
[image_size]
resize_height = 800
resize_width = 800
[model_params]
batch_size = 32
num_epochs_per_decay = 100.0
learning_rate = 0.0001
learning_rate_decay_factor = 0.1
num_steps = 100000
[finetune_ckpt]
ckpt_path = /data1/humaoc_file/model_zoo/resnet_v1_50.ckpt
logdir = ./training
参考
- Tensorflow中tf.train.exponential_decay函数(指数衰减法)
- TensorFlow - tf.train.batch 函数