1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
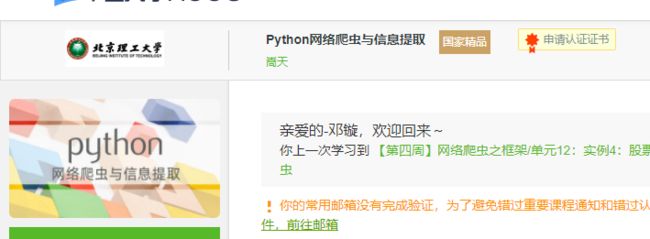
3.学习完成第0周至第4周的课程内容,并完成各周作业
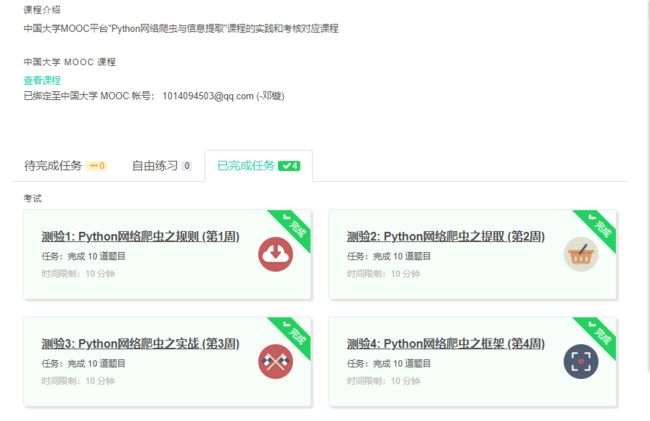
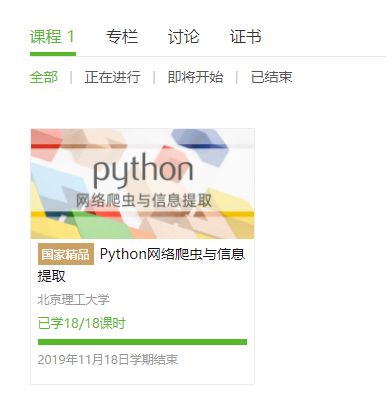
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
在过去的一周里,我在中国大学MOOC里学习了北京理工大学嵩天老师的《Python网络爬虫与信息提取》的前四周课程,学习到了很多以前没有接触到的python知识。第一次接触python是在大三的时候,那个时候我就觉得python是一个当今社会很厉害的一门编程语言,简单 Python的语法非常优雅,甚至没有像其他语言的大括号,分号等特殊符号,代表了一种极简主义的设计思想。阅读Python程序像是在读英语。在老师的介绍下,我从Mooc里初次认识到可以用Python进行网络爬虫。而这一次网络课程的学习,使我对python的认知更进一步,让我认识到python更高级的用法。
第一周《规则》里,我学习到了Requests库的七个主要方法,其中get()方法是最常使用的方法。Request库的异常处理很重要,嵩老师给出一个代码框架,是利用try-except的方式来实现,保证网络连接的异常能够被有效处理。嵩天老师给出一个代码框架,是利用try-except的方式来实现,保证网络连接的异常能够被有效处理。总之,我们要学会合理的使用网络爬虫,也要遵守协议规则。
第二周《提取》里,我学习到了Beautiful Soup库的安装和使用。我知道了Beautiful Soup库是解析、遍历、维护“标签树”的功能库,熟练使用Beautiful Soup库能更好进行网络爬虫。信息标记有XML、JSON、YAML三种形式。
第三周《实战》里,我学习到了正则表达式,正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。我们可以通过正则表达式然后能找到我们所需要的关键信息,它的数据位置比较固定。老师介绍的Re库的函数调用主要有两种方式,一种是直接加上方法名调用,还有一种是先将函数编译成正则表达式对象,再用正则表达式对象调用函数。
第四周《框架》里,我学习到了网络爬虫的框架结构,其实爬虫框架就是实现爬虫功能的一个软件结构和功能组件集合,老师介绍的Scrapy框架包括“5+2”结构和三个数据流的路径。把Scrapy与request进行比较,明白了两个的差异,使我们更加了解和使用。
在嵩天老师的讲课中我学会了很多,更加明白了爬虫的概念,老师讲解了很多实例练习,我基础比较差,所以需要时间一步一步跟着老师去试验一下,要自己尝试完才能真正的体验到该如何时间,遇到问题去解决,慢慢摸索,然后要更加努力的去学习,主动努力,才能使自己进步,老师列举的实例可以一个一个都去尝试一下,从中找到自己的问题和适合自己的解决方法。在网络上看视频的好处就是可以不断回放,题目里很多都是细节性的问题,看视频有时会忽略,所以课后还是需要多加理解和练习。