1.1 索引基础
简单讲,索引就是书籍后面的“索引”-Index,帮助我们找到特定主题、词语,然后告诉我们具体对应的页码。在MySQL中存储引擎用类似的方法使用索引,先在索引中找到对应的值,然后根据匹配的索引记录找到对应的数据行。

简单例子: select name from actor where actor_id=5; 前提:actor_id 列上建有索引。MySQL 将使用在该列上创建的索引找到 actor_id 为 5 的行,按值在索引上查找,然后返回包含该值(5)的数据行。
像上面的例子,一般可能直接被认为 actor 表以 actor_id 一个列为索引,但正如大多数人做的那样,一个表的索引可能还会包含一个以上的列(多个列)的值。如果是多个列,那么顺序很重要,因为MySQL只能高效利用 最左前缀列。另外,创建一个包含两个列的索引,和创建两个只包含一个列的索引是大不相同的,未来解释。
无论多么复杂的ORM工具,在精妙和复杂的索引面前都是浮云!
索引有很多类型,索引在存储引擎层实现,不在服务器层,因此不同存储引擎、不同索引类型的底层实现都不相同。基本类型包括B-Tree索引、哈希索引、空间数据索引(R-Tree)、全文索引等。
====================B-Tree索引==============
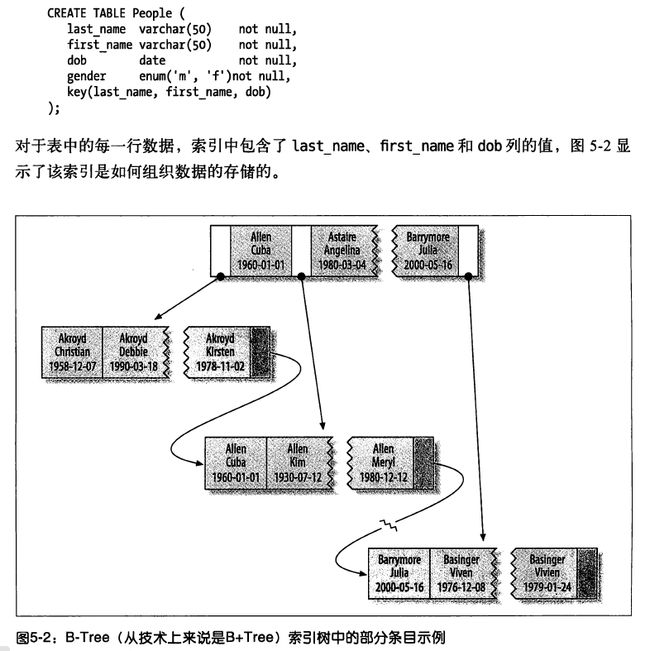
上面的表中,姓(last_name)、名(first_name)、出生日期(dob)为索引(key),图上为这三个列组成的索引的数据组织形式,其中 last_name (姓)是最左前缀,参考链接《最左前缀原则(博文)》
B-Tree索引适用于全值匹配(索引中所有列匹配,Allen、Cuba、1960-01-01)、匹配最左前缀(索引的前缀列,只使用索引第一列,姓 Allen)、匹配列前缀(索引列的前缀,姓列前缀,查 All开头的姓)、匹配范围值(查找 A字母~B字母开头的姓)、精确匹配某一列并范围匹配另外一列(姓列精确匹配=Allen,名称列范围,以K字母开头的名)、只访问索引的查询(不访问数据行,叫“覆盖索引”,未来解释)。
B-Tree以上查找原则,也使用于 ORDER BY 排序字段,能查找就能排序。
B-Tree有些傻乎乎,像人一样固执得狠!不能跳过最左前缀(last_name),只查满足名字和生日的不行;也不能跳过中间列,只查满足姓和生日的不行;如果中间列有范围查询,则居其右边的列优化用不上,例如:WHERE last_name='Smith' AND first_name LIKE 'J%' dob='1976-12-23',dob的优化用不上,因为 first_name 是个范围查询。
由上可以看出 B-Tree索引列的顺序多么多么的重要,在优化时,需要创建相同的多个列但顺序不同的索引,来满足不同的需求,如:key1(last_name, first_name, dob),key1(first_name,last_name,dob),key1(dob,first_name,last_name)
==================== 哈希索引==============
哈希索引,仅用于精确匹配,仅存在于Memory引擎,每行数据都计算一个哈希码(hash code),MySQL接收查询命令后,如:select last_name from People where first_name='Peter' ,先计算 Peter 的哈希值,然后用该哈希值找到记录数据行的指针,通过指针找到数据行,然后判断找到的数据是否为Peter,如果是返回数据。
哈希索引,特点结构紧凑,速度快。
伪哈希索引,因为哈希索引只在 Memory中存在,所以可以参考书中自行在其他引擎中创建伪哈希索引,效果不错,但注意哈希值冲突的解决。
====================空间数据索引(R-Tree)==============
MyISAM支持空间数据索引,可以用作地理数据存储。但MySQL做得不好,很少使用。
==================== 全文索引==============
全文索引,查找的是文本中的关键词,而不是直接比较索引中的值,与其他索引完全不同,不是简单的 WHERE 匹配,而更像搜索引擎做的事情,适用于 MATCH AGAINST 操作。
全文索引,详细见第七章。
===========================================================
1.2 索引优点
索引优点,大大减少了服务器需要扫描的数据量(快速定位);
索引优点,可以帮助服务器避免排序和临时表(顺序存储,便于ORDER BY、GROUP BY);
索引优点,将随机I/O,变为顺序I/O。
索引辩证法,小表,全表扫描更高效;中大表,索引高效;超大表,索引代价高,可以使用分区技术,见第7章。
===========================================================
1.3 高性能索引策略
1)将索引列要独立,放在比较符号的一侧,例如 select * from actor where actor_id + 1 = 5; 应写为 select * from actor where actor_id = 4;
2)前缀索引,一般对BLOB、TEXT、很长的VARCHAR使用,需要保证索引的选择性要高,就是索引的值的数量和记录的总数尽量持平,一般的自增id作为索引基本上选择性=1,不会重复。使用前缀索引要先预估选择性的值,书中有实例。
3)多列索引,在多个列上单独建立索引多数情况下不能提高效率,特别对于AND、OR操作,OR操作更浪费。
4)选择合适的索引列顺序,将选择性最高的列放最左,但只是经验做法。
5) 聚簇索引
6)覆盖索引
7)使用索引扫描来做排序!(很重要!!!)
MySQL通过两种方式生成有序结果:通过排序操作,或,按索引顺序扫描。当 Explain的结果中 type 为 index,就说明MySQL用了索引扫描来做排序了!
扫描索引是很快了的,但如果索引没有能覆盖查询中所需的全部列,那就不得不每扫描一条索引记录就回表查询一次对应的行(自问:为什么?:-))这基本就是随机I/O了,慢,慢!
设计时,一定要注意,如果有一条索引(可能多个列),既能满足查找,又能满足排序,那就好了。