1.选一个自己感兴趣的主题。
2.网络上爬取相关的数据。
3.进行文本分析,生成词云。
4.对文本分析结果解释说明。
5.写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。
3dm是国内知名游戏论坛 现对其首页进行爬取 分析当日网站标题热词

经分析 其首页标题的a标签在div class="c-1" /"c-2“/"c-3"之下

源代码如下
from bs4 import BeautifulSoup from os import path from PIL import Image import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud, STOPWORDS import urllib.request import sys import jieba font_path = "C:\\Windows\\Fonts\\STFANGSO.ttf" def getHtml(url): page = urllib.request.urlopen(url) html = page.read() return html url = "http://www.3dmgame.com/" htmlpage = urllib.request.urlopen(url).read() soup = BeautifulSoup(htmlpage, "html.parser") fo = open('database.txt', "w") for tag in soup.select('.c-1'): if len(tag.select('a')) > 0: title=tag.select('a')[0].text seg_list = jieba.lcut_for_search(title) # 搜索引擎模式 print(", ".join(seg_list)) fo.write(str(seg_list)+'\n') for tag in soup.select('.c-2'): if len(tag.select('a')) > 0: title=tag.select('a')[0].text seg_list = jieba.lcut_for_search(title) # 搜索引擎模式 print(", ".join(seg_list)) fo.write(str(seg_list)+'\n') fo.close() d = path.dirname(__file__) # Read the whole text. text = open(path.join(d, 'database.txt')).read() # read the mask image # taken from # http://www.stencilry.org/stencils/movies/alice%20in%20wonderland/255fk.jpg alice_mask = np.array(Image.open(path.join(d, "255fk.jpg"))) stopwords = set(STOPWORDS) stopwords.add("said") wc = WordCloud(font_path="C:\\Windows\\Fonts\\STFANGSO.ttf",background_color="white", max_words=2000, mask=alice_mask, stopwords=stopwords) # generate word cloud wc.generate(text) # store to file wc.to_file(path.join(d, "alice.png")) # show plt.imshow(wc, interpolation='bilinear') plt.axis("off") plt.figure() plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear') plt.axis("off") plt.show() # 搜索引擎模式 #print(", ".join(seg_list)) #fo.write((", ".join(seg_list) + '\r\n').encode('UTF-8')) #print (soup.select('a[target="_blank"]')) #def is_the_only_string_within_a_tag(s): # return (s == s.parent.string) #print (soup.find_all(text=is_the_only_string_within_a_tag))
分词效果

输出词云如下
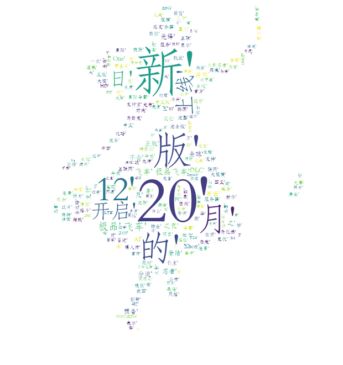
分析可发现 当日有个新的页游上线 极品飞车20在今天有新的发售消息,网站仍然充满了盗版游戏下载,但数量减少,但正版游戏出现频率增加,正版意识加强,网站对游戏的服务转向汉化开发。