目录
一、RD缓存
1、cache/persist缓存
2、那么StorageLevel存储级别有哪些呢
二、内存优化之序列化
三、内存优化之Spark内存管理
1、StaticMemoryManager管理器
2、UnifiedMemoryManager 统一内存管理器
四、spark内存优化之GC调优
五、数据本地化
一、RD缓存
RDD Persistence
1、cache/persist缓存
背景:
1)对相同的RDD做action操作的时候,需要重新计算RDD:耗资源、耗时间。
2)RDD某分区数据丢失,需要分区重算。
所以可以使用cache/persist将RDD缓存进executor内存,可以很大程度的节省计算和程序运行时间。
执行:
rdd.cache() 或者使用 rdd.persist(StorageLevel.MEMORY_ONLY)
rdd.count()
1)cache是lazy的,需要触发一个action,才会产生job。
2)在Spark UI的storage页签中可以看到RDD占用的内存大小,但是默认比原来的文件大。
3)用完记得要释放内存:rdd.unpersist(true) 这个是立刻发生的。
如何查看RDD占用executor内存大小?
两种方式:
1)第一种:执行rdd.cache、rdd.count,查看Spark UI界面上的storage页签。
2)第二种:
import org.apache.spark.util.SizeEstimator
SizeEstimator.estimate(filepath)
cache进内存,为什么占用的内存变大了?(了解)
默认使用MEMORY_ONLY存储策略,存进executor内存,没有序列化。所以要考虑:
1)一个java对象中包含头信息(16字节)、指向对象的指针信息。如果一个java对象是很小的数据,比如int类型,如果用一个对象来存储,由于有头+指针信息,就会造成一个小对象占用过多信息的情况。比如一个2字节的数据存储为一个java对象,那么占用的内存就成了16字节+指针,就占用多了。
2)对于String类型,默认会多出来40个字节,存储每一个字符的时候会占用两个字节,因为底层使用的是UTF-16进行编码的,
3)对于集合的类,例如HashMap、LikedList要看底层源码,面试会问,底层使用的是Linked的数据结构,这种是包装过后的对象,比如MashMap底层是使用了Map.Entry的。这种集合的对象不仅有头,还是指针信息(8个字节)指向下一个对象。所以使用集合也会多出来很多信息。
4)集合中存储的原生类型数据,在集合中还会进行box包装的,比如int age = 10 会转为Integer age = new Integer(10)。
persist()与cacehe()有什么区别呢?
1)cache源码:def cache(): this.type = persist() 底层调用persist。
2)默认使用StorageLevel.MEMORY_ONLY存储策略:def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
3)注意:RDD和Spark SQL默认使用的存储级别都是MEMORY_ONLY,但是Streaming默认使用的存储级别是MEMORY_ONLY_SER。
2、那么StorageLevel存储级别有哪些呢
StorageLevel存储级别来决定RDD存储在内存、磁盘、、是否开启堆外内存、是否开启序列化、副本等。
Class StorageLevel定义:
class StorageLevel private(
private var _useDisk: Boolean, # 是否使用磁盘
private var _useMemory: Boolean, #是否使用内存
private var _useOffHeap: Boolean, #是否使用堆外Heap(不受GC管理)
private var _deserialized: Boolean, #是否使用反序列化的方式进行存储
private var _replication: Int = 1) #副本因子
extends Externalizable {
Object StorageLevel定义的存储级别:
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
1、理解一下:
1)MEMORY_ONLY:val MEMORY_ONLY=new StorageLevel(false,true,false,true) 表示:使用内存、不序列化、1个副本。
RDD默认的存储策略。如果内存不够,某些分区不会被缓存,RDD.action要重新计算未存储的部分分区。
在Spark UI的storage页签中也可以看到StorageLevel。
2)MEMORY_ONLY_2:这种带有尾巴的就是副本数不一样。
3)MEMORY_AND_DISK:内存存不够的,存磁盘上,必定慢。
4)MEMORY_ONLY_SER:存内存,开启序列化存储。
序列化必然省内存,但是耗CPU,所以要考虑CPU负载。
cache默认使用StorageLevel.MEMORY_ONLY存储策略,即内存+反序列化存储+1个副本。
2、这么多的缓存存储级别,使用的时候要怎么选择呢?
spark的存储级别旨在在内存使用率和CPU效率之间提供不同的权衡。
1)优先选择MEMORY_ONLY:但是不使用序列化且纯用内存,大数据场景使用有限,会OOM。
2)次选MEMORY_ONLY_SER:自己去搭配一个快速的序列化library。
纯使用内存,序列化存储更节省空间。
但是:序列化耗CPU、内存太大时有OOM,需要考虑调executor内存(Spark统一内存管理)。
3)注意:一般不用磁盘,太慢。
一般存内存,资源有限,不用副本。
二、内存优化之序列化
Tuning Spark、Data Serialization
前面介绍了RDD存储进内存,默认使用MEMORY_ONLY机制,占用内存空间更大,所以最好是使用序列化的方式。
序列化在分布式系统中是必须的。因为设计到网络传输,必然用序列化的方式。
序列化有两种:
1)Java serializatio 不推荐
默认使用的序列化方式
使用:实现java.io.Serializable接口
缺点:慢、对象会变大。
2)Kryo serialization 推荐
优点:快、紧凑(小)
注意:需要注册类型才能实现上述效果。
使用Kryo序列化的几种方式:
1)第一种方式:代码中添加
sparkConf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
sparkConf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
2)第二种方式:配置文件
vi $SPARK_HOME/conf/spark-defaults.conf
spark.serializer org.apache.spark.serializer.KryoSerializer
代码中:conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
3)第三种方式:作为提交参数
提交参数:./spark-submit --conf spark.serializer=org.apache.spark.serializer.KryoSerializer
代码:conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
例子:
def main(args:Array[String]):Unit={
val sparkConf = new SparkConf()
sparkConf.setAppName("LogApp").setMaster("local[2]")sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
sparkConf.registerKryoClasses(Array(classOf[Info]))
val sc = new SparkContext(sparkConf)
sc.stop()
}
class Info{}
准备一个151M的测试文件,测试序列化的效果:
1)情况1:
MEMORY_ONLY+java序列化
MEMORY_ONLY+Kryo序列化
MEMORY_ONLY+Kryo序列化+注册类
结果都是占用190M内存。因为使用MEMORY_ONLY存储策略,即反序列化存储,占用内存变大,所以这几种结果都是一样的。A。MEMORY_ONLY+java序列化:
package com.test
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import scala.collection.mutable.ListBuffer
object SparkTest {
def main(args:Array[String]):Unit = {
val sparkConf = new SparkConf().setAppName("SparkTest").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val users = new ListBuffer[User]
for(i <- 1 to 10000000){
users.+=(new User(i,"name"+i,i.toString))
}
val usersRDD=sc.parallelize(users)
usersRDD.persist(StorageLevel.MEMORY_ONLY)
println(usersRDD.count)Thread.sleep(1000000)
sc.stop()
}
class User(id:Int,username:String,age:String) extends Serializable {} //需要java序列化
}B。MEMORY_ONLY+Kryo序列化:
加入:sparkConf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
去掉:extends SerializableC。MEMORY_ONLY+Kryo序列化+注册类:
加入:
sparkConf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
sparkConf.registerKryoClasses(Array(classOf[User]))
去掉:extends Serializable2)情况2:
MEMORY_ONLY_SER+java序列化 60.7M
MEMORY_ONLY_SER+Kryo序列化 257.5M
MEMORY_ONLY_SER+Kryo序列化+注册类 19.1M
传输的类必须使用java序列化或者Kryo序列化。不能什么序列化都不用。
另外可以知道使用Kryo序列化必须注册,否则占用内存会变大。A。MEMORY_ONLY_SER+java序列化:
package com.test
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import scala.collection.mutable.ListBuffer
object SparkTest {
def main(args:Array[String]):Unit = {
val sparkConf = new SparkConf().setAppName("SparkTest").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val users = new ListBuffer[User]
for(i <- 1 to 10000000){
users.+=(new User(i,"name"+i,i.toString))
}
val usersRDD=sc.parallelize(users)
usersRDD.persist(StorageLevel.MEMORY_ONLY_SER)
println(usersRDD.count)
Thread.sleep(1000000)
sc.stop()
}
//传输的类必须使用java序列化或者Kryo序列化。不能什么序列化都不用。
class User(id:Int,username:String,age:String) extends Serializable {}
}B。MEMORY_ONLY_SER+Kryo序列化:
加入:sparkConf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
去掉:extends SerializableC。MEMORY_ONLY_SER+Kryo序列化+注册类:
加入:
sparkConf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
sparkConf.registerKryoClasses(Array(classOf[User]))
去掉:extends Serializable总结:
最优:MEMORY_ONLY_SER+Kryo序列化+注册类:节省7倍多的内存。
次优:MEMORY_ONLY_SER+java序列化 : 节省2倍多的内存。
次次优:MEMORY_ONLY 不序列化: 会增加内存。
次次次优:MEMORY_ONLY_SER+Kryo序列化: 会更增加内存。注意:
1)使用序列化的缺点:耗费CPU,如果CPU负载很高了,建议还是不要再用序列化了。
2)如果对象很大,可能还需要增加spark.kryoserializer.buffer配置。此值必须足够大,以容纳要序列化的最大对象。
3)自从Spark 2.0.0以来,RDD中简单类型、简单类型数组或字符串类型的简单类型,在内部已经使用了Kryo序列化器,在sc初始化的时候被注册进去了:
private[spark] class SerializerManager(
defaultSerializer: Serializer,
conf: SparkConf,
encryptionKey: Option[Array[Byte]]) {
private[this] val kryoSerializer = new KryoSerializer(conf)
private[this] val primitiveAndPrimitiveArrayClassTags: Set[ClassTag[_]] = {
val primitiveClassTags = Set[ClassTag[_]](
ClassTag.Boolean,
ClassTag.Byte,
ClassTag.Char,
ClassTag.Double,
ClassTag.Float,
ClassTag.Int,
ClassTag.Long,
ClassTag.Null,
ClassTag.Short
)
三、内存优化之Spark内存管理
也就是调节executor的内存。
spark中的内存使用主要分为两类:
1)执行内存:做计算:比如shuffle、join、sorts、aggregations。
2)存储内存:做存储:比如cache数据、广播数据。
SparkEnv确定了MemoryManager抽象类的具体实现:
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
new StaticMemoryManager(conf, numUsableCores) 静态内存管理器Spark1.6之前的
} else {
UnifiedMemoryManager(conf, numUsableCores) 统一内存管理器Spark1.6+开始的
}
}
1、StaticMemoryManager管理器
StaticMemoryManager.getMaxExecutionMemory(conf) 拿到最大存储内存
StaticMemoryManager.getMaxStorageMemory(conf) 拿到最大执行内存
1)getMaxExecutionMemory源码:
private def getMaxExecutionMemory(conf: SparkConf): Long = {val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
if (systemMaxMemory < MIN_MEMORY_BYTES) {//MIN_MEMORY_BYTES=32M
throw new IllegalArgumentException(s"System memory $systemMaxMemory must " +
s"be at least $MIN_MEMORY_BYTES. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}
if (conf.contains("spark.executor.memory")) {
val executorMemory = conf.getSizeAsBytes("spark.executor.memory")
if (executorMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$MIN_MEMORY_BYTES. Please increase executor memory using the " +
s"--executor-memory option or spark.executor.memory in Spark configuration.")
}
}val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)//(假设系统内存是10G)10G * 0.2 * 0.8 = 1.6G
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}2)getMaxStorageMemory源码:
StaticMemoryManager.getMaxStorageMemory(conf) {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)// (假设系统内存是10G)10G * 0.6 * 0.9 = 5.4G
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}
总结:
1)执行内存:
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)
val systemMaxMemory = "spark.driver.memory"值
(systemMaxMemory * memoryFraction * safetyFraction).toLong2)存储内存:
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
val systemMaxMemory = "spark.testing.memory"
(systemMaxMemory * memoryFraction * safetyFraction).toLong
出现OOM时,调整参数。
2、UnifiedMemoryManager 统一内存管理器
Memory Management
UnifiedMemoryManager(conf,numUsableCores)没有new,底层是Objetc的apply方法,源码:
def apply(conf: SparkConf, numCores: Int): UnifiedMemoryManager = {
val maxMemory = getMaxMemory(conf) 执行内存+存储内存
new UnifiedMemoryManager(
conf,
maxHeapMemory = maxMemory,
onHeapStorageRegionSize = 存储内存
(maxMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong,
numCores = numCores)
}
1)getMaxMemory源码:
private def getMaxMemory(conf: SparkConf): Long = {val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
//预留内存300M
val reservedMemory = conf.getLong("spark.testing.reservedMemory",
if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)val minSystemMemory = (reservedMemory * 1.5).ceil.toLong
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}
if (conf.contains("spark.executor.memory")) {
val executorMemory = conf.getSizeAsBytes("spark.executor.memory")
if (executorMemory < minSystemMemory) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$minSystemMemory. Please increase executor memory using the " +
s"--executor-memory option or spark.executor.memory in Spark configuration.")
}
}// (比如系统内存是10G)10G - 300M
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)// (假设系统内存是10G) (10G - 300M) * 60%
(usableMemory * memoryFraction).toLong
}2)存储内存:
(maxMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong
总结一下统一内存管理器:
1)总的可用内存maxMemory=执行内存+存储内存:
val usableMemory = systemMemory-reservedMemory=系统堆内存heap space-300M预留内存
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)
(usableMemory * memoryFraction).toLong2)存储内存:
(总内存maxMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong
所以默认统一内存管理中,执行内存和存储内存各占用50%。
画图理解:
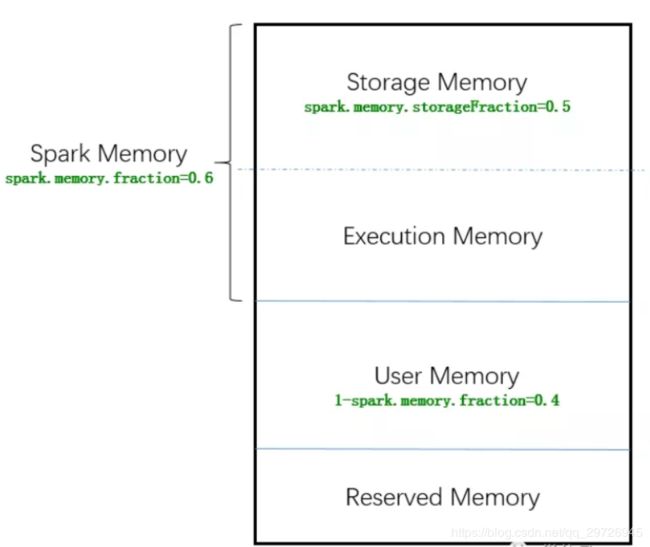
![]()
总的系统内存是所有的框。
Reserved Memory是预留内存。系统内存-预留内存=可用内存
可用内存的60%是SparkMemory,可用内存的40%是User Memory剩余内存。
SparkMemory分为两部分,各占50%,就是执行内存+存储内存。
注意:
1)默认执行内存和存储内存各占用50%,共享一个统一内存空间,当执行内存没有被使用时,存储可以获取所有spark内存,反之亦然,内存可以动态伸缩。
2)执行内存和存储内存一共占用了100%,如果执行内存不够,可以向存储内存借,强制的借,但是存储内存不能强制的去借执行内存中的内存。
Spark程序如果出现OOM,选判断是哪个端:
1)driver端:调driver内存
2)executor端:调executor统一内存管理。
四、spark内存优化之GC调优
Garbage Collection Tuning
JVM内存管理:
1)堆(GC管理):
年轻代:[Eden, Survivor1, Survivor2]
老年代:
2)metaspace:元数据
堆的GC:
1)如果Eden区满了的时候,就会有一个minor gc。清理Eden区,将Edenh和Survivor1中活着的对象拷贝到Survivor2区,同时把Edenh和Survivor1清空。
2)Survivor1, Survivor2可以交换:
A.Eden+Survivor1 ===>cpoy活的对象进Survivor2。Eden+Survivor1 清空
B.下次的时候Eden+Survivor2 ===>cpoy活的对象进Survivor1。Eden+Survivor2 清空
对象GC次数达到15,就会进入老年代。
或者是cpoy活的进Survivor2,如果Survivor2满了,或者对象真的很老,就把活的移动到Old区域。
3)年轻代满了之后的GC是:minor GC 大多数
老年代满了之后的GC是:full GC 耗费性能
GC调优信息查看:
第一步是:收集一些统计信息
添加-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps to the Java options
下一步:Spark运行的时候,要看打印在worker中的日志(通过UI可以看到)
Spark中GC调优的目的是:
年轻代放在Young,long-lived的RDDs移动到Old区域。
因为80%的对象都是Young的,所以尽可能的存储这些对象在Young,尽量减少full GC。
因为在task执行阶段如果发生了full GC,如果选择的GC不好的话,会直接停止用户程序。
一些可能有用的操作.............:
1)通过收集GC统计信息来检查垃圾收集是否太多。如果在任务完成之前多次调用full GC,则意味着没有足够的内存用于执行任务。GC的时间在UI上是有的:
![]()
![]()
2)如果有很多minor collections却没有很多major GCs,就需要去调整Eden的大小。可以为每个task设置超过所需内存的Eden大小。如果Eden大小是E,那么可以用-Xmn=4/3*E来设置Young的大小。设置4/3也是为了说明活着的对象使用的空间。
3)如果OldGen满了,请通过降低spark.memory.fraction来减少用于缓存的内存量。最好是减少缓存的对象为不是减慢任务的执行。或者考虑减少Young的规模。这意味着降低-Xmn。
如果没有降低-Xmn,请尝试更改JVM的newRatio参数的值。许多JVM将此值默认为2,这意味着Old占用堆的2/3。它应该足够大,以至于这个分数超过了spark.memory.fraction。
4)可以通过设置-XX:+UseG1GC来使用G1GC垃圾收集,在垃圾收集成为瓶颈的情况下,它可以提高性能。
请注意,对于较大的执行器堆大小,使用-xx:g1HeapRegionSize增加g1区域大小可能很重要。
5)例如,如果您的任务是从HDFS读取数据,则可以使用从HDFS读取的数据块大小来估计任务使用的内存量。请注意,解压块的大小通常是块大小的2到3倍。因此,如果我们希望有3或4个任务的工作空间,并且HDFS块大小为128MB,我们可以估计Eden的大小为4*3*128MB。
可以通过在作业配置中设置spark.executor.extraJavaOptions来指定执行器的GC优化标志。也就是设置使用什么GC,调优参数的配置。
更多的GC调优,参考:https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/index.html
五、数据本地化
希望运行的代码和数据在一起,但是一般是很难保证的。
数据本地化的几种机制(由优到差):
1)PROECSS_LOCAL:在同一个JVM里面,也就是代码和数据在同一个进程里面的,是最好的。可以理解为数据已经cacahe到你的本机器了。
2)NODE_LOCAL:在同一个节点上的(也就是executor代码与需要的数据都在一个节点上),
数据在两个进程中传输。因为一个在executor也就是yarn进程中,另一个在datanode也就是HDFS进程中
3)NO_PREF
4)RACK_LOCAL: 同一个机架 代码和数据在同一个机架但是不同的节点上
5)ANY:不同机架
Spark优先使用最好的本地化机制,但是一般都实现不了,Spark会从优到次递进使用。Spark在超过了等待的时间之后就会选择其他的机制,不同机制等待的时候参考spark.locality的配置:
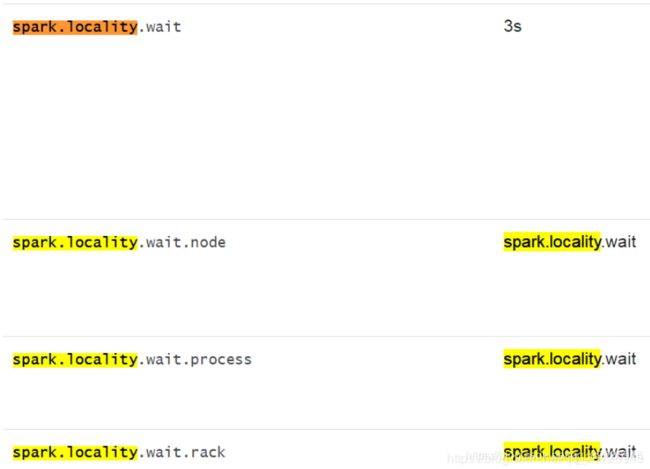
![]()
一般设置wait=1s