前沿:第一次在上留下印迹。毕业后的第一篇文章,贡献给了,只因被它的简约风格所吸引。今天我分享的主题是"CNN如何应用在句子分类任务上"。我主要从思路和源码的角度进行分析。
一、 任务介绍
句子分类任务,主要是将某个query句子,进行类别的划分;例如美食类、娱乐类、音乐类、学习类、旅游类等多种类别。本文,主要介绍如何构建出一个end2end的深度学习模型,不需要人为手工进行特征工程的设计,以期达到90%+精度的句子分类需求。
源码Github链接 https://github.com/yzx1992/sentence_classification (顺便帮忙start一下)
源码基于Tensorflow1.1版本。 只展示了部分Demo数据集合,还望读者理解(建议:自己构建爬虫代码,自给自足最靠谱)。
train set: 1000条
test set: 500条
二、设计思路
由于句子分类任务中,"类别类型"只对句子中某个字词或几个字词较为敏感。例如:"我们去吃海底捞吧?" 若模型能够捕捉到"海底捞"这三个字的特征信息,那么毫无疑问,句子将应该被分到美食这个类别上。
因此,我们可以先将句子切成 "字" 级别或 "词级别"(python中可以采用jieba包进行切词)。值得说明的是,若训练集较小,"词"级别的效果会更好一些;另外,添加pre-train的embbeding效果会有几个点的提升。然而,词级别所对应的词向量矩阵较大,参数较多,最终训练得到的模型参数较大(即,字典的size较大,所需要训练的embbed_matrix 参数较多,很容易挤爆显存,出行OOM的情况。例如,中文高频词字典取10w ,word_emb的维度取200维,单单一个embbed_matrix的参数就有10w*200=2000w个参数,2000w *4个Byte(float浮点型占4个字节)约等于80M)。 实际我跑的句子分类任务中,词模型的参数大小在300M左右,字模型则可以控制在10M左右。我当时做任务的训练语料达100W+, 因此,词模型和字模型,最终精确率、召回率、F1等各项指标的表现差别不大。
下文,主要以"字"模型来进行分析。
采用CNN框架,利用不同size的卷积核(kernel)来捕捉句子的ngram特征(1个字,2个字,3个字,4个字等),值得注意的是,相同size的卷积核,通常会包含多个,通过不同初始化卷积核的参数,来达到多维度获取句子ngram的语意信息。实验中我设置为100,即num_filtes=100。此外,大部分分类任务采用较粗粒度的特征就可以搞定(当然,取决于你类别体系的粒度,可以分为一级标签,二级标签,三级标签等等),为了降低模型参数,可以采用max pooling的方式,来保留ngram中最明显的特征;例如对于"我们去吃海底捞吧?" 3-gram的信息包含"0 0 我"、"0 我 们"、"我们去"、"们 去 吃"、"去吃海"、"吃 海 底"、"海 底 捞 " …… 等等,对于3-gram的所有特征,我们当然希望模型学到只留下"海 底 捞"一个就好。
最终,对于单个query,我们总共抽取了100个1-gram, 100个2-gram, 100个3-gram,100个4-gram特征,即400个特征。
通常,这时候你可以接多层全连接,一般取1~3层,每层可接tanh或者relu等激活函数,来达到非线性的效果(如果没添加非线性的激活函数,多层全连接等价于单层,数学上,矩阵求解可知--> W2 (W1 X))=WX (其中,X表示特征向量,W表示参数向量)
最后,映射到9维的向量空间,即得到每个类别对应的score得分,再经过softmax函数作用之后,将各个类别的score得分转化为归一化概率分布(即,各个类别的概率值相加等于1)
三、走进代码
1)首先看data.py 数据处理部分:
采用迭代器的设计思路,每次从文件读取mini_batch个训练样本。迭代器设计的优势在于,每次只读取mini_batch个句子到内存中,而不是把所有训练集一股脑扔到内存。对于那种千万级个sample以上的文件,采用迭代器,可大大降低内存的开销,提高执行效率。
def BatchIter(data_path, batch_size) 函数:
data_path: train set 或 valid set的路径
batch_size: 模型梯度的更新参用mini_batch进行,防止单个异常样本,梯度波动太大。
def BatchIter(data_path, batch_size):
0 #print(data_path)
1 with open(data_path, 'r') as f:
2 sample_num = 0
3 samples = []
4 for line in f:
5 line = line.strip()
6 samples.append(line)
7 sample_num += 1
8 if sample_num == batch_size:
9 a = zip(*[s.split("\t") for s in samples])
10 l = list(a[0])
11 x = [s.strip() for s in a[1]]
12 x = np.array(text2list(x))
13 y = []
14 for i in l:
15 y.append([0]*9)
16 y[len(y)-1][int(i)-1] = 1
17 batch_data = list(zip(x, y))
18 batch_data = np.array(batch_data)
19 yield batch_data
20 sample_num = 0
21 samples = []
其中,第9~12行代码:
a = zip(*[s.split("\t") for s in samples]) 表示合并batch_size个样本。
单个样本对构造为: label_id \t word_id1 word_id2 word_id3 …… 即,句子所属标签,句子以单字表示对应的id序列,两者以\t分隔符进行分割。
eg:
case1: 4 32 33 1571 20 57 58 0 0
case2: 1 108 287 916 917 101 572 0 0
case3: 2 318 319 95 646 647 319 192 95
即,max_len=8, batch_size=3
此时,值对应如下:
a=[('4', '1', '2'), ('32 33 1571 20 57 58 0 0', '108 287 916 917 101 572 0 0', '318 319 95 646 647 319 192 95')]
l=['4', '1', '2']
x=['32 33 1571 20 57 58 0 0', '108 287 916 917 101 572 0 0', '318 319 95 646 647 319 192 95']
x=[[ 32 33 1571 20 57 58 0 0]
[ 108 287 916 917 101 572 0 0]
[ 318 319 95 646 647 319 192 95]]
第13~16行代码: 本份代码只针对9个类别进行阐述,若你任务的分类类别有x种,则把9改成x。
这几句代码,对batch个句子的label标签构造成one-hot向量。方便后续求预测lable和真实label的交叉熵,即损失函数Loss。
例如:case1的标签是4, 即对于9维度的向量,其第3个位置置1,其他位置置0,(位置索引是从index=0开始的),即, case1对应的ground_true的向量标签为 [0, 0, 0, 1, 0, 0, 0, 0, 0] 。同理,case2的标签是1,对应[1, 0, 0, 0, 0, 0, 0, 0, 0] ,case3的标签是2,则对应 [0, 1, 0, 0, 0, 0, 0, 0, 0]。
对于,case1来说,当你经过最后一层全连接的输出,得到一个维度为9的向量,即对应各个类别的score得分。取argmax后,该值即对应最终句子分类的label id,例如对于case1来说,argmax(9维向量的概率分布 or 9维向量的score得分)=2,表示case1最后预测的score向量为[y0, y1, y2,y3, y4, y5, y6, y7, y8]。这时候预测与真实值就有了误差,采用交叉熵的方式求解其对应的误差表征,最后采用梯度下降算法(即反向传播back-propagation algorithm),来更新参数,使得预测值更加靠近ground True的label值。
y=[[0, 0, 0, 1, 0, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0]]
第17行~19行,对x和y进行zip,方便训练样本与label标签一一对应,最后再转成numpy数组的形式,准备训练的时候,feed给模型。
batch_data=[(array([ 32, 33, 1571, 20, 57, 58, 0, 0]), [0, 0, 0, 1, 0, 0, 0, 0, 0]),
(array([108, 287, 916, 917, 101, 572, 0, 0]), [1, 0, 0, 0, 0, 0, 0, 0, 0]), (array([318, 319, 95, 646, 647, 319, 192, 95]), [0, 1, 0, 0, 0, 0, 0, 0, 0])]
batch_data=[[array([ 32, 33, 1571, 20, 57, 58, 0, 0]) list([0, 0, 0, 1, 0, 0, 0, 0, 0])]
[array([108, 287, 916, 917, 101, 572, 0, 0]) list([1, 0, 0, 0, 0, 0, 0, 0, 0])]
[array([318, 319, 95, 646, 647, 319, 192, 95]) list([0, 1, 0, 0, 0, 0, 0, 0, 0])]]
yield 是一个类似return的关键字,只不过其返回的是个生成器,不是具体的值。
在train_multi_gpu.py脚本中,Train()则可以方便地调用data.py函数,从而得到batch个训练样本与其所对应的label值
train_iter = BatchIter(train_path, batch_size) #返回可迭代对象
for train_batch in train_iter:
x_batch, y_batch = zip(*train_batch) #返回batch个数据
2)直接进入模型代码,转移到text_cnn.py 这个函数。
def inference(input_x, input_y, sequence_length,
vocab_size, embedding_size, filter_sizes, num_filters,
x_size, cpus, l2_reg_lambda=0.0, dropout_keep_prob=0.5)
input_x: 表示batch个输入序列的字id,shape=[batch,max_len] batch表示mini_batch的大小,max_len,表现句子的最大长度,(大于max_len的句子截断,小于max_len的句子补0)
input_y: 表示batch个ground True label的向量(如上所述,向量维度为9,总共分为9个类别) ,shape=[batch,9]
embedding_size: 即,每个字用多少维向量来表示,通常维度取100~300即可。
filter_sizes:[2,3,4,5],表示卷积核的大小(kernel_size)取宽度=embbedding_size,高度分别取2,3,4,5。即捕获句子2-gram,3-gram,4-gram,5-gram的特征。这里大家可能会有疑惑,为什么宽度一定要取embbeding_size,而不能像图像(CV)一样,来个33或者55的卷积核? 对于句子而言,我们最主要的是想捕捉n-gram的特征,例如捕获句子"我们去吃海底捞吧?",我们主要想捕获3-gram的特征就OK了。如果卷积核的宽度不取embbeding_size的维度,则会破坏字向量的语意信息,自然也就谈不上ngram特征了。
num_filters: 本文设置为100,即不同kernel_size的卷积核,取100个。通过不同初始化参数,来达到多角度,更加全面的获取相对应ngram的信息。
x_size:暂时没用到,略。
l2_reg_lambda: L2,正则化惩罚系数。目的,防止模型因参数过于复杂:出现过拟合现象。通常,会在损失函数上,加上参数的惩罚,本文暂时取0,可根据模型效果,自行调(lian)参 (dan)。
dropout_keep_prob:本文取0.5,让每个神经元以50%的概率不工作,即处于睡眠状态,不进行前向score传播,也不进行反向error传递。 目的:减少神经元之间复杂的共适应性,提高模型的泛化能力。
import tensorflow as tf
TOWER_NAME = 'CNN'
def _variable_on_cpu(name, shape, initializer, cpus):
with tf.device('/gpu:6' ):
var = tf.get_variable(name, shape, initializer=initializer)
return var
def inference(input_x, input_y, sequence_length,
vocab_size, embedding_size, filter_sizes, num_filters,
x_size, cpus, l2_reg_lambda=0.0, dropout_keep_prob=0.5):
0 l2_loss = tf.constant(0.0)
1 with tf.variable_scope("embedding") as scope:
2 W = _variable_on_cpu("W", [vocab_size+22, embedding_size],
3 tf.random_uniform_initializer(-1.0, 1.0), cpus)
4 #print vocab_size,input_x
5 embedded_chars = tf.nn.embedding_lookup(W, input_x)
6 embedded_chars_expanded = tf.expand_dims(embedded_chars, -1)
7 pooled_outputs = []
8 for i, filter_size in enumerate(filter_sizes):
9 with tf.variable_scope("conv-maxpool-%s" % filter_size) as scope :
10 # Convolution Layer
11 filter_shape = [filter_size, embedding_size, 1, num_filters]
12 W = _variable_on_cpu("W", filter_shape, tf.truncated_normal_initializer(stddev=0.1), cpus)
13 b = _variable_on_cpu('b', [num_filters],tf.constant_initializer(0.1), cpus)
14 conv = tf.nn.conv2d(embedded_chars_expanded,
15 W,
16 strides=[1, 1, 1, 1],
17 padding="VALID",
18 name="conv")
19
20 # Apply nonlinearity
21 h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
22 # Maxpooling over the outputs
23 pooled = tf.nn.max_pool(h,
24 ksize=[1, sequence_length - filter_size + 1, 1, 1],
25 strides=[1, 1, 1, 1],
26 padding='VALID',
27 name="pool")
28
29 pooled_outputs.append(pooled)
30 # Combine all the pooled features
31 with tf.variable_scope("combine") as scope :
32 num_filters_total = num_filters * len(filter_sizes)
33 h_pool = tf.concat( pooled_outputs,3)
34 h_pool_flat = tf.reshape(h_pool, [-1, num_filters_total], name="encode")
35 # Add dropout
36 with tf.variable_scope("dropout") as scope :
37 h_drop = tf.nn.dropout(h_pool_flat, dropout_keep_prob, name="h_drop")
38
39 # 4 Hidden layer to map all the pooled features
40 with tf.variable_scope("output") as scope:
41 W = _variable_on_cpu("W1", [num_filters_total, 9], tf.truncated_normal_initializer(stddev=0.1), cpus)
42 b = _variable_on_cpu('b1', [9], tf.constant_initializer(0.1), cpus)
43 l2_loss += tf.nn.l2_loss(W)
44 l2_loss += tf.nn.l2_loss(b)
45 scores = tf.nn.xw_plus_b(h_drop, W, b, name='scores')
46 probs = tf.nn.softmax(scores, name='probs')
47 predictions = tf.argmax(scores, 1, name = 'predictions')
48
49 # CalculateMean cross-entropy loss
50 with tf.variable_scope("loss") as scope :
51 losses = tf.nn.softmax_cross_entropy_with_logits(labels=input_y,logits=scores)
52 loss = tf.reduce_mean(losses) + l2_reg_lambda*l2_loss
53
54 # Accuracy
55 with tf.name_scope("accuracy"):
56 correct = tf.equal(predictions, tf.argmax(input_y, 1))
57 accuracy = tf.reduce_mean(tf.cast(correct, "float"), name="accuracy")
58 return loss, accuracy
代码第0~6行:
W:word_embbeding matrix shape=[vocab_size+22, embedding_size] , 其中,22可以随便换个正整数,防止id索引word_embbeding matrix越界。
embbed_chars: batch个句子的词向量表征。 shape=[batch, max_len, embedding_size]
embedded_chars_expanded:shape=[batch, max_len, embedding_size,1] ,在最末尾增加一个维度,因为TF的卷积操作,要求参数必须是4维。
代码第8~29行:
第8行:对每个不同size的卷积核(kernel)进行遍历,这里filter_size=2,3,4,5,这里以filter_size=3 、max_len=50 、num_filters=100 来进行分析。
filter_shape: 卷积核的维度 shape=[3,embedding_size,1,100]
w: 卷积核参数 shape=[3,embedding_size,1,100] ,采用标准差为0.1的正太分布进行参数初始化。
b: 偏置参数, shape=[100],初始化为0.1
tf.nn.conv2d(input,filters,strides,padding)
input: shape=[batch, max_len, embedding_size,1] 以图像进行类比:batch_size,对应图片的数量,可以暂时忽略这个维度。max_len, 类比图像的高度,embedding_size,类比图像的宽度,1,类比图像的通道数(1表示单通道的灰色图像)
filters: shape=[3,embedding_size,1,100] 3代表卷积核的高度,embedding_siez表示卷积核的宽度,1,类比图像的通道数,100表征卷积核的数目。
padding: string类型,值为“SAME” 和 “VALID”,表示的是卷积的形式,是否考虑边界。”SAME”是考虑边界,不足的时候用0去填充周围,”VALID”则不考虑.
最终conv: shape=[batch, max_len-filter_size+1, 1, 100] = [batch, 100-3+1, 1, 100]
经过一层relu非线性函数激活后,再进行max pooling
此时,pooled:shape=[batch,1,100]
因为pooled_outputs添加了4种不同size卷积核的特征输出,即pooled_outputs=[[batch,1,100] ,[batch,1,100] ,[batch,1,100] ,[batch,1,100] ]
代码第31~37行:
首先,对pooled_outputs进行最后一个维度的拼接。即h_pool:shape=[batch,1,100*4]
然后,在flatten,得到h_pool_flat: shape=[batch,400]
再进行dropout操作,得到最终句子的特征。
代码第40~57:
采用单层全连接,将CNN捕获到的400维特征向量,映射到9个类别, 得到每个类别的得分。
值得注意的是,如果训练语料足够多,大50w以上,可以尝试3层的全连接层,增大模型的容量,泛化效果可以更好一些。
此时,scores: shape=[batch,9] 9个类别
进行softmax操作,将9个类别的socre得分映射成概率分布。
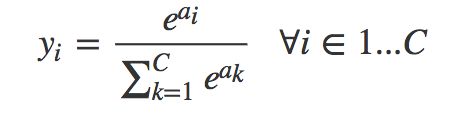
probs: shape=[batch,9] ,9个类别的概率值相加=1
predictions即为最终预测label的id shape=[batch,]
采用交叉熵来作为损失函数LOSS
值得注意的是:tf.nn.softmax_cross_entropy_with_logits(labels,logits) 交叉熵计算函数输入中的logits并不是softmax或sigmoid的输出,而是未经过非线性函数前的得分scores,因为该函数内部会对score进行sigmoid或softmax操作。
此时losses shape=[batch,9]
进行最后一个维度的求和,即,累加9个类别的损失。loss shape=[batch,]
correct 返回True,False列表 shape=[batch,]
accuracy 返回准确率 shape=[batch,]
OK,不出意外的话,你的模型应该顺利run起来了! 记得GPU训练,否则你得等到猴年马月!
不过,你可以缩小batch的值,调整训练集的大小,在本地电脑run看看代码是否有bug,或者修改模型框架,封装成自己看起来顺眼的API !
-
测试模型效果,目光移步到evaluation.py 脚本。
记得,修改好数据路径和模型路径。
对于一个query,可以根据top函数,输出top 1或者top3的指标,分别包含recall_rate、precision_rate、F1指标。
加载模型你可saver=tf.train.import_meta_graph(FLAGS.model_dir+'/model.ckpt-24.meta') sess.graph.get_tensor_by_name('dev_x:0') #根据tensor的名字加载变量
也可以采用
ckpt = tf.train.get_checkpoint_state(checkpoint_path)
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
print("Reloading model parameters..")
_model.saver.restore(sess=session, save_path=ckpt.model_checkpoint_path)
四、总结
一定要统计好数据分布,即各个类别的数据分布应该保持在相同数量级别。否则,模型容易 "剑走偏锋",一直倾向于输出某个类别。 数据才是决定最终的指标的上限!!!
对于类别体系较为复杂的分类,需要捕捉更加细粒度的特征,直接分词+max pooling 效果可能会欠佳。可以拼接"字"特征+ "词"特征,最好也引入ner(实体特征)等多维度信息。
3)对于短文本,也可以引入Bi-LSTM 直接捕获整个句子的信息,直接暴力采用最后一个step的隐藏层即可,(拼接前向隐藏层和后向隐藏层),注意一定要mask掉padding 0带来的误差影响。
4)如果是中长文本,超过100个词,采用Bi-LSTM框架 则需要加入attention机制,来挑选关键的词。
5)……