前言
| 目录 |
|---|
| 01 文法和语言、词法分析复习 |
| 02 自顶向下、自底向上的LR分析复习 |
| 03 语法制导翻译和中间代码生成复习 |
| 04 符号表、运行时存储组织和代码优化复习 |
| 05 用C++手撕PL/0 |
在之前的编译原理实验课是要求对现有的PL/0编译程序代码进行修改以添加一些功能,于是我拿到C++和C语言版本的实现来看。但是C++的要安装C++ Builder,C语言的实现有种上古世纪的味道,实在是没有欲望去改他的代码。思来想去,还是决定自己拿出最多一周的时间自己重新用C++写一个PL/0程序,把实验当成课设来做吧。
ps.因为不是课设,所以我也不需要特意去画太多的图。
项目源码地址
概述
原课程实验要求
以下实验未完成的部分,用删除线表示。
一、必做内容:
对PL/0作以下修改和扩充,并使用测试用例验证:
(1)修改单词:不等号# 改为 != ,!变为逻辑非,同时#成为非法符号。
(2)增加单词(只实现词法分析部分):
保留字 ELSE,FOR,STEP,UNTIL,DO,RETURN
运算符 *=,/=,&,||
注释符 //
(3)增加条件语句的ELSE子句(实现语法语义目标代码),要求:写出相关文法和语法图,分析语义规则的实现。
二、选做内容1:
(1)扩充赋值运算:*= 和 /=
(2)扩充语句(Pascal的FOR语句):
FOR := STEP UNTIL Do
三、选做内容2:
(1)增加类型:① 字符类型; ② 实数类型(仅限于词法分析)。
(2)增加 注释; 注释由/*和*/包含,或由//注释一行;
(3)扩充函数:① 有返回值和返回语句;② 有参数函数。
(4)增加一维数组类型(可增加指令)。
(5)其他典型语言设施。
当前实验环境
运行环境:Windows
开发环境:Visual Studio 2019
程序编写所用语言:C++14
源语言:PL/0
目标语言:类P-Code指令代码
PL/0程序概述
一个PL/0程序可以分为词法分析部分、语法/语义分析+翻译部分、虚拟机(解释执行)部分:
- 词法分析部分:负责将输入的代码字符串进行词法分析处理,最终输出的是一个词语序列。
- 语法/语义分析+翻译部分:负责将词语序列进行递归式的自顶向下分析,并且一边分析、一边翻译成中间码,建立符号表,最终输出程序信息
- 虚拟机部分:根据输入的程序信息构建虚拟环境,并执行该程序。
每个部分都是一个独立的模块,并且上一个模块的输出往往就是下一个模块的输入,故可以确保各个模块专注于自己的任务。
实验情况
本程序参考了原PL/0实验程序的源码,从0开始实现一个自己的PL/0程序,完成了以下实验要求,也做出了一些限制:
语法分析层面:
(1)修改单词:不等号# 改为 !=,而!变为了逻辑非
(2)增加单词:
- 保留字else, for, step, until, do, return
- 双目运算符 +, -, *, /, %, &&, ||, >=, <=
- 单目运算符 +, -, !
- 赋值运算符 +=, -=, =, /=, %=
- 注释符 //, /* */
- 括号 (, )
(3)增加条件语句的else子句
(4)增加字符串、字符、实数类型的识别
语法/语义分析层面:
(1)循环支持:while循环、for循环
(2)复杂表达式与条件支持:可以使用+, -, *, /, %, &&, ||, >=, >, <=, <, =, !=, !, (, )
(3)带形参的过程(不支持返回值)
(4)返回语句支持
(5)过程调用递归支持,但不支持过程递归声明
(6)仅支持int型,不支持float型(需额外扩充指令,这里不考虑)
补充说明
我知道将来很多人肯定会看到这篇甚至想白*这份代码和报告的,不过得看你本人能否hold得住这份代码了。实验报告我就没必要贴出来了,这一篇博客本身也可以当作报告。有能力修改的人或许可以这份代码上完成更多的事情(坑我是不会填的),比如:
- 实现数组类型(一维即可)
- 支持float类型,意味着要增加和float相关的指令,如浮点加减乘除法、浮点存取、浮点取余。这也还意味着要开始判别运算符两边的数据类型,做类型提升。注意还要为read和write作支持。
- 支持字符类型和字符串类型,用+和+=实现字符串拼接,:=实现字符串复制。注意还要为read和write作支持。
- 支持过程嵌套定义
- 项目分化出编译器和虚拟机,前者负责编译出.PL0文件,后者负责运行.PL0文件
词法分析
讲解的时候只放出重要的代码部分,其余可以在下面下载了解
项目源码地址
词法分析是整个编译过程的第一步,我们可以把单词分为:关键字、符号名、值类型、特殊符号。即便你没学过编译原理,也是可以完成这一步的,而且为了省时间,有些东西能交给C/C++标准库的就交给他们实现。
词法单位
首先说明EBNF描述的符号含义:{ }表示里面的内容可以出现任意次(0次及以上),<>表示只出现一次,[ ]表示不出现或只出现一次,|表示或,::=即左边的内容可以表示成右边的形式
关键字:完整支持的关键有begin call const do else end for if int procedure read return step then until while write;仅在词法分析支持的关键字有char float string
值类型:完整支持的类型只有整型,仅在词法分析支持的类型有实型 字符型 字符串常量。
注意:整数仅支持连续10位数字,超过的部分将会引发编译错误。
标识符:和C语言的标识符一样,除了首字符不能为数字外,字符组成可以包含字母、数字、下划线,即 ::= | { | | }
值类型: ::= { }
特殊符号:
- 算术运算符: + - * / %
- 比较运算符:> < >= <= = !=
- 逻辑运算符:&& || !
- 括号:( )
- 赋值运算符: := += -= *= /= %=
- 分隔符: , ; .
- 注释: // /* */
对于像>=和>这样的情况,我们只需要在拿到>后再向后探一个字符(而不是取出),如果是=则为>=,反之则为>。
与词法分析相关的一些定义
在PL0_Common.h里面定义了这些和词法分析有关的常量、枚举和结构体:
namespace PL0
{
// ...
// 常量
constexpr size_t g_KeywordOffset = 100; // 关键字相对于符号类型枚举值的偏移
constexpr size_t g_KeywordCount = 20; // 关键字数目
constexpr size_t g_MaxIdentifierLength = 47;// 标识符最大长度
constexpr size_t g_MaxIntegerLength = 10; // 整数最大长度
// 符号类型
enum SymbolType
{
ST_Null = 0, // 空
ST_Error, // 错误类型
// 值类型
ST_Identifier = 10, // 标识符
ST_Integer, // 整型
ST_Real, // 实型
ST_Character, // 字符型
ST_StringConst, // 字符串常量
// 算术运算符
ST_Plus = 20, // 加 +
ST_Minus, // 减 -
ST_Multiply, // 乘 *
ST_Divide, // 除 /
ST_Mod, // 取余 %
// 赋值
ST_Assign = 30, // 赋值语句 :=
ST_PlusAndAssign, // 加后赋值 +=
ST_MinusAndAssign, // 减后赋值 -=
ST_MultiplyAndAssign, // 乘后赋值 *=
ST_DivideAndAssign, // 除后赋值 /=
ST_ModAndAssign, // 取余后赋值 %=
// 比较运算符
ST_Equal = 40, // 判断lhs == rhs
ST_NotEqual, // 判断lhs != rhs
ST_Less, // 判断lhs < rhs
ST_LessEqual, // 判断lhs <= rhs
ST_Greater, // 判断lhs > rhs
ST_GreaterEqual, // 判断lhs <= rhs
// 逻辑运算符
ST_LogicalAnd = 50, // 逻辑与 &&
ST_LogicalOr, // 逻辑或 ||
ST_LogicalNot, // 逻辑非 !
// 括号
ST_LeftParen = 60, // 小括号 左 (
ST_RightParen, // 小括号 右 )
ST_LeftBracket, // 中括号 左 [
ST_RightBracket, // 中括号 右 ]
ST_LeftBrace, // 大括号 左 {
ST_RightBrace, // 大括号 右 }
// 分割符
ST_Comma = 70, // 逗号 ,
ST_SemiColon, // 分号 ;
ST_Period, // 句号 .
// 注释
ST_Comment = 80, // 注释
// 关键字
ST_Begin = 100, // 代码片段开始 begin
ST_Call, // 函数调用
ST_Char, // char声明语句
ST_Const, // 常量声明修饰符
ST_Do, // do语句
ST_Else, // else语句
ST_End, // 代码片段结束 end
ST_Float, // float声明语句
ST_For, // for语句
ST_If, // if语句
ST_Int, // int声明语句
ST_Procedure, // 程序声明修饰符
ST_Read, // read语句
ST_Return, // return语句
ST_Step, // step语句
ST_String, // string语句
ST_Then, // then语句
ST_Until, // until语句
ST_While, // while语句
ST_Write, // write语句
};
// 标识符类型
enum IDType
{
ID_INT = 0x1,
ID_FLOAT = 0x2,
ID_PROCEDURE = 0x4,
ID_CONST = 0x10,
ID_VAR = 0x20,
ID_PARAMETER = 0x40
};
// 关键字字符串
const char* const g_KeyWords[g_KeywordCount] = {
"begin", "call", "char", "const", "do", "else", "end", "float", "for", "if", "int",
"procedure", "read", "return", "step", "string", "then", "until", "while", "write"
};
// 错误码
using ErrorCode = uint32_t;
// 代码坐标(从1开始)
struct CodeCoord
{
size_t row;
size_t col;
};
// 符号(完成词法分析)
struct Symbol
{
std::string word;
CodeCoord beg, end;
SymbolType symbolType;
};
// 错误信息
struct ErrorInfo
{
CodeCoord beg, end;
ErrorCode errorCode;
};
}词法分析器类
词法分析器的定义如下:
//
// 词法分析器
//
class WordParser
{
public:
WordParser() : m_pCurrContent(), m_CurrCoord() {}
~WordParser() = default;
// 对内容进行完整的词法分析
bool Parse(_In_ const std::string& content);
// 对内容进行完整的词法分析
bool Parse(_In_ const char* content);
// 获取分析处理的所有符号
const std::vector& GetSymbols() const;
// 获取词法分析发现的错误信息
const std::vector& GetErrorInfos() const;
private:
// 获取下一个符号,并推进分析中的内容
Symbol GetNextSymbol(_Out_ ErrorInfo * errorInfo);
// 获取下一个字符,并推进分析中的内容
char GetNextChar();
// 抛弃下一个字符,并推进分析中的内容
void IgnoreNextChar();
// 获取下一个字符,但不推进分析中的内容
char PeekNextChar();
// 分析一个字符,得到分析完的末尾位置,但不推进分析中的内容
// 如content = "\x12\' + " ,则EndPos = "\' + "
// 如content = "e\"" , 则EndPos = "\""
void TryPraseChar(_In_ const char* content, _Out_ const char** pEndCharPos);
private:
const char * m_pCurrContent; // 当前遍历的代码内容所处位置
std::vector m_Symbols; // 符号集
CodeCoord m_CurrCoord; // 当前坐标
std::vector m_ErrorInfos; // 错误消息
};
其中m_CurrCoord记录的是m_pCurrContent当前所指的字符对应代码第几行第几列,用于标出错误位置。
整个词法分析的过程如下:
bool WordParser::Parse(_In_ const char* content)
{
m_pCurrContent = content;
m_Symbols.clear();
m_ErrorInfos.clear();
m_CurrCoord = { 1, 1 };
ErrorInfo errorInfo;
Symbol symbol;
while (*m_pCurrContent)
{
symbol = GetNextSymbol(&errorInfo);
// 注释部分需要忽略,否则将词语放入符号集
if (symbol.symbolType != ST_Comment)
{
m_Symbols.push_back(symbol);
}
// 若产生错误码则记录错误信息
if (errorInfo.errorCode != 0)
{
m_ErrorInfos.push_back(errorInfo);
}
}
// 没有错误信息意味着分析成功
return m_ErrorInfos.empty();
}词法分析是以一个个的词语为单位分析,即GetNextSymbol方法。而词语的分析内部则是以字符为单位分析。下面三个方法涵盖了分析词语的主要方面:
char WordParser::GetNextChar()
{
char ch = *m_pCurrContent;
// 已经达到代码尾部
if (ch == '\0')
{
return '\0';
}
// 已经达到当前行末
if (ch == '\n')
{
++m_CurrCoord.row;
m_CurrCoord.col = 1;
}
else
{
++m_CurrCoord.col;
}
++m_pCurrContent;
return ch;
}
void WordParser::IgnoreNextChar()
{
char ignoreCh = GetNextChar();
}
char WordParser::PeekNextChar()
{
return *m_pCurrContent;
}在需要抓取下一个字符的时候,直接使用GetNextChar方法,在获取字符的同时更新当前字符的位置;而需要根据下一个字符来判断具体是什么词语的时候,先使用PeekNextChar方法,然后分析完后再用IgnoreNextChar方法忽略。
这里只以关键字和标识符为例展示分析过程:
Symbol WordParser::GetNextSymbol(_Out_ ErrorInfo* pErrorInfo)
{
Symbol symbol;
symbol.symbolType = ST_Null;
ErrorInfo errorInfo;
errorInfo.beg = errorInfo.end = m_CurrCoord;
errorInfo.errorCode = 0;
// 抓取下一个字符
char ch;
// 清理换行符、制表符、空格
while (isspace(ch = PeekNextChar()))
{
IgnoreNextChar();
}
// 记录起始内容和位置
const char* startContent = m_pCurrContent;
symbol.beg = m_CurrCoord;
ch = GetNextChar();
#pragma region 关键字或标识符
// 符号类型可能是关键字或标识符 [keyword][identifier]
if (isalpha(ch) || ch == '_')
{
ch = PeekNextChar();
while (isalpha(ch) || isdigit(ch) || ch == '_')
{
IgnoreNextChar();
ch = PeekNextChar();
}
// 判断是否为关键字
std::string word(startContent, m_pCurrContent);
for (size_t i = 0; i < g_KeywordCount; ++i)
{
if (word == g_KeyWords[i])
{
symbol.symbolType = static_cast(g_KeywordOffset + i);
break;
}
}
// 不是关键字的话则为标识符
if (symbol.symbolType == ST_Null)
{
// 标识符长度不能超出最大定义长度
if (symbol.word.size() > g_MaxIdentifierLength)
{
errorInfo.errorCode = 12; // [Error012] Identifier length exceed.
}
else
{
symbol.symbolType = ST_Identifier;
}
}
}
#pragma endregion 关键字或标识符
// ... 由于词语种类繁多,GetNextSymbol的实现就占据了将近500行代码,需要将各种情况都考虑到。
注意:可以使用C/C++标准字符库,如
strtol(对应std::stoi)和strtof(对应std::stof)之类的函数辅助分析出字符串的整数/浮点数部分,以节省一部分工作量。
词法分析这部分的技术含量不算高,花些时间还是能实现的。
语法/语义分析、翻译中间码、建立符号表
在进行了第一趟扫描后,我们得到了符号序列。接下来就是对符号序列进行第二趟扫描,通过递归自顶向下法,在进行语法语义分析(检验程序合法性)的同时,还需要翻译成中间码,并且对扫描到的符号声明建立同一个符号表来记录哪些符号名是合法的。
现在第一步我们需要先确定语法单位。为了能够用自顶向下法表示,设计的语法单位合集必须要满足LL(1)文法,或者说设计的语法单位不能出现二义性。在这里我不会专门再讲这些基础概念,可以自行回顾前面的内容,我只用尽量简短的描述来说明含义。
下面给出的是当前程序所用的语法单位(不支持嵌套过程):
// <程序> ::= <常量说明部分><变量说明部分><过程说明部分><语句>.
// <常量说明部分> ::= {const <值类型><常量定义>{,<常量定义>};}
// <常量定义> ::= :=<值>
// <变量说明部分> ::= {<值类型><变量定义>{,<变量定义>};}
// <变量定义> ::= [:=<值>]
// <过程说明部分> ::= <过程首部><分程序>;{<过程说明部分>}
// <过程首部> ::= procedure '('[<值类型>{,<值类型>}]')';
// <分程序> ::= <常量说明部分><变量说明部分><语句>
// <语句> ::= <空语句>|<赋值语句>|<条件语句>|||<过程调用语句>|<读语句>|<写语句>|<返回语句>|<复合语句>
// <赋值语句> ::= :=|+=|-=|*=|/=|%= <表达式>
// <复合语句> ::= begin <语句>{;<语句>} end
// <空语句> ::= ε
// <条件语句> ::= if <条件> then <语句> {else if <条件> then <语句>}[else <语句>]
// ::= while <条件> do <语句>
// ::= for :=<表达式> step <表达式> until <条件> do <语句>
// <读语句> ::= read '('{,}')'
// <写语句> ::= write '('<表达式>{,<表达式>}')'
// <过程调用语句> ::= call '('[<表达式>{,<表达式>}]')'
// <返回语句> ::= return
// <条件> ::= <二级条件>{<逻辑或><二级条件>}
// <二级条件> ::= <三级条件>{<逻辑与><三级条件>}
// <三级条件> ::= <四级条件>{!=|= <四级条件>}
// <四级条件> ::= <表达式>{>|>=|<|<= <表达式>}
// <表达式> ::= <二级表达式>{+|- <二级表达式>}
// <二级表达式> ::= <三级表达式>{*|/|% <三级表达式>}
// <三级表达式> ::= [!|-|+]<四级表达式>
// <四级表达式> ::= ||'('<条件>')' 通过多层条件和表达式,我们可以实现塞入多个优先级的运算符。当然代价是一次括号8层调用。层数越深的符号优先级越高。
语法/语义分析器类
语法/语义分析器类的定义如下:
//
// 语法/语义分析器
//
class ProgramParser
{
public:
ProgramParser() : m_CurrLevel(), m_CurrProcIndex(), m_CurrProcAddressOffset() {}
~ProgramParser() = default;
// 对分析好的词组进行语法分析
bool Parse(_In_ const std::vector& symbols);
// 获取语法语义分析发现的错误信息
const std::vector& GetErrorInfos() const;
// 获取翻译结果
const ProgramInfo& GetProgramInfo() const;
private:
// <程序> ::= <常量说明部分><变量说明部分><过程说明部分><语句>.
bool PraseProgram();
// <常量说明部分> ::= {const <值类型><常量定义>{,<常量定义>};}
bool PraseConstDesc(_Inout_ std::vector& constants);
// <常量定义> ::= :=<值>
void PraseConstDef(_In_ SymbolType type, _Inout_ std::vector& constants);
// <变量说明部分> ::= {<值类型><变量定义>{,<变量定义>};}
bool PraseVarDesc(_Inout_ std::vector& variables);
// <变量定义> ::= [:=<值>]
void PraseVarDef(_In_ SymbolType type, _Inout_ std::vector& variables);
// <过程说明部分> ::= <过程首部><分程序>;{<过程说明部分>}
bool PraseProcedureDesc();
// <过程首部> ::= procedure '('[<值类型>{,<值类型>}]')';
void PraseProcedureHeader();
// <分程序> ::= <常量说明部分><变量说明部分><语句>
void PraseSubProcedure();
// <语句> ::= <空语句>|<赋值语句>|<条件语句>|||<过程调用语句>|<读语句>|<写语句>|<返回语句>|<复合语句>
bool PraseStatement();
// <赋值语句> ::= :=|+=|-=|*=|/=|%= <表达式>
void PraseAssignmentStat();
// <复合语句> ::= begin <语句>{;<语句>} end
void PraseComplexStat();
// <条件语句> ::= if <条件> then <语句> {else if <条件> then <语句>}[else <语句>]
void PraseConditionalStat();
// ::= while <条件> do <语句>
void PraseWhileLoopStat();
// ::= for :=<表达式> step <表达式> until <条件> do <语句>
void PraseForLoopStat();
// <读语句> ::= read '('{,}')'
void PraseReadStat();
// <写语句> ::= write '('<表达式>{,<表达式>}')'
void PraseWriteStat();
// <过程调用语句> ::= call '('[<表达式>{,<表达式>}]')'
void PraseCallStat();
// <返回语句> ::= return
void PraseReturnStat();
// <条件> ::= <二级条件>{<逻辑或><二级条件>}
void PraseConditionL1();
// <二级条件> ::= <三级条件>{<逻辑与><三级条件>}
void PraseConditionL2();
// <三级条件> ::= <四级条件>{!=|= <四级条件>}
void PraseConditionL3();
// <四级条件> ::= <表达式>{>|>=|<|<= <表达式>}
void PraseConditionL4();
// <表达式> ::= <二级表达式>{+|- <二级表达式>}
void PraseExpressionL1();
// <二级表达式> ::= <三级表达式>{*|/|% <三级表达式>}
void PraseExpressionL2();
// <三级表达式> ::= [!|-|+]<四级表达式>
void PraseExpressionL3();
// <四级表达式> ::= ||'('<条件>')'
void PraseExpressionL4();
private:
// 检查当前符号是否为ST,如果不是,则填入错误码并抛出异常
void SafeCheck(SymbolType ST, ErrorCode errorCode, const char* errorStr = "");
// 获取id在符号表中的索引和层级
uint32_t GetIDIndex(const std::string& str, int * outLevel = nullptr);
private:
int m_CurrLevel; // 当前代码层级
ProgramInfo m_ProgramInfo; // 程序信息
uint32_t m_CurrProcIndex; // 当前过程标识符的对应索引
uint32_t m_CurrProcAddressOffset; // 当前过程对应起始地址偏移值
std::vector::const_iterator m_pCurrSymbol; // 当前符号的迭代器
std::vector::const_iterator m_pEndSymbol; // 符号集尾后的迭代器
std::vector m_ErrorInfos; // 错误消息
}; 递归式的自顶向下分析
由于我们的文法满足LL(1)文法,故可以很方便的用递归方式实现自顶向下语法分析。现在我们把翻译部分和建符号表的环节都忽略掉,这样自顶向下的分析目的就是要检查语法是否错误,若不符合语法要求,应当产生报错信息。这里使用的是SafeCheck方法,如果检测到不符合语法要求,就抛出异常,交给上层处理。上层负责跳过当前分析的这条语句即可。
void ProgramParser::SafeCheck(SymbolType st, ErrorCode errorCode, const char* errorStr)
{
// 若当前已经扫完整个符号序列,或者当前期望的符号类型与实际的不一致,则记录错误信息并抛出异常
if (m_pCurrSymbol == m_pEndSymbol || m_pCurrSymbol->symbolType != st)
{
ErrorInfo errorInfo;
if (m_pCurrSymbol != m_pEndSymbol)
{
errorInfo.beg = m_pCurrSymbol->beg;
errorInfo.end = m_pCurrSymbol->end;
}
else
{
--m_pCurrSymbol;
errorInfo.beg = m_pCurrSymbol->beg;
errorInfo.end = m_pCurrSymbol->end;
++m_pCurrSymbol;
}
errorInfo.errorCode = errorCode;
m_ErrorInfos.push_back(errorInfo);
throw std::exception(errorStr);
}
}以<复合程序>为例,PraseComplexStat的实现如下:
void ProgramParser::PraseComplexStat()
{
//
// <复合语句> ::= begin <语句>{;<语句>} end
//
// begin
++m_pCurrSymbol;
// <语句>
PraseStatement();
//
// {;<语句>}
//
// ;
while (m_pCurrSymbol != m_pEndSymbol && m_pCurrSymbol->symbolType == ST_SemiColon)
{
++m_pCurrSymbol;
// <语句>
PraseStatement();
}
// end
SafeCheck(ST_End, 26); // [Error026] Keyword 'end' expected.
++m_pCurrSymbol;
}在编写语法分析/翻译器的时候,先根据EBNF描述先把整个自顶向下的递归代码部分优先实现出来,确保整个语法检测功能是正确的,然后才是在这个基础上逐步实现翻译功能和符号表功能。
符号表
符号表的作用是在编译期间确定哪些变量被声明出来,以及代码中引用的变量是否有效。
现在把目光聚焦到符号表的实现上。在PL0_Common.h中包含了标识符的定义
// 标识符类型
enum IDType
{
ID_INT = 0x1,
ID_FLOAT = 0x2,
ID_PROCEDURE = 0x4,
ID_CONST = 0x10,
ID_VAR = 0x20,
ID_PARAMETER = 0x40
};
// 标识符(完成语法分析)
struct Identifier
{
char name[g_MaxIdentifierLength + 1]; // 名称
uint32_t kind; // 符号类型
int value; // 值
int level; // 层级
int offset; // 地址偏移
};
Identifier中的成员kind是由上面的IDType枚举的组合。比如说const int对应的是枚举组合ID_INT | ID_CONST。
而由于取消了递归定义过程,标识符的层级level只可能在第0层或第1层,过程内定义的符号为第1层。这样在代码运行到子过程,查找符号的时候,先在自己过程区域内的符号查找,再在主过程区域内的符号查找即可。此外为了方便,这里将一开始调用的主过程命名为__main__。
而成员offset对于过程而言是指位于指令序列的索引,对于过程内的变量而言则是运行栈基址处的偏移量(用于定位变量所存地址),而常量直接查符号表获取。
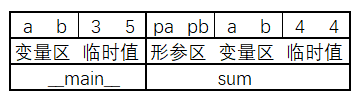
对于以下程序:
const int c := 2;
int a, b;
procedure sum(int pa, int pb);
int a, b;
write(pa + pb);
call sum(a, b).
它的符号表为:
| 符号 | 类型 | 值 | 层级 | 偏移 |
|---|---|---|---|---|
__main__ |
procedure | 0 | 7 | |
| a | var int | 0 | 0 | |
| b | var int | 0 | 1 | |
| c | const int | 2 | 0 | 0 |
| sum | procedure | 0 | 1 | |
| pa | param var int | 1 | 0 | |
| pb | param var int | 1 | 1 | |
| a | var int | 1 | 2 | |
| b | var int | 1 | 3 |
若要查询符号表,可以通过GetIDIndex方法实现。如果找到可以访问的变量,则返回它在符号表中的索引(非偏移)及所在层数。具体的代码就不在这里贴出。
类P-Code指令
类P-Code指令是一组简化指令集,对数据的操作都是基于数据栈进行的。其中使用的寄存器如下:
i(ir) 指令寄存器,保存当前指令
p(pr) 指令地址寄存器,保存当前指令所处地址
t(tr) 栈顶寄存器,保存当前函数调用下所指向的最后一个元素所处的地址
b(br) 基址寄存器,保存当前函数调用下数据栈的基准地址
接下来是指令集:
过程调用相关指令
| 功能 | 层差 | 地址偏移/立即数/指令 | 含义 |
|---|---|---|---|
| POP | 0 | N | 退避N个存储单元,用于函数形参(仅改变栈顶指针,不移除上面的内容) |
| INT | 0 | N | 在栈顶开辟N个存储单元,通常在函数调用后需要立即执行 |
| OPR | 0 | 0 | 结束被调用过程,返回调用点并退栈 |
| CAL | L | A | 调用地址为A的过程,调用过程与被调用过程的层差为L |
存取指令
| 功能 | 层差 | 地址偏移/立即数/指令 | 含义 |
|---|---|---|---|
| LIT | 0 | A | 立即数存入栈顶,t加1 |
| LOD | L | A | 将层差为L,偏移量为A的存储单元的值取到栈顶,t加1 |
| STO | L | A | 将栈顶的值存入层差为L、偏移量为A的单元,t减1 |
一元运算指令
| 功能 | 层差 | 地址偏移/立即数/指令 | 含义 |
|---|---|---|---|
| OPR | 0 | 1 | 栈顶 := -栈顶 |
| OPR | 0 | 2 | 栈顶 := !栈顶 |
二元运算指令
| 功能 | 层差 | 地址偏移/立即数/指A | 含义 |
|---|---|---|---|
| OPR | 0 | 3 | 次栈顶 := 次栈顶 + 栈顶,t减1 |
| OPR | 0 | 4 | 次栈顶 := 次栈顶 - 栈顶,t减1 |
| OPR | 0 | 5 | 次栈顶 := 次栈顶 * 栈顶,t减1 |
| OPR | 0 | 6 | 次栈顶 := 次栈顶 / 栈顶,t减1 |
| OPR | 0 | 7 | 次栈顶 := 次栈顶 % 栈顶,t减1 |
二元比较指令
| 功能 | 层差 | 地址偏移/立即数/指A | 含义 |
|---|---|---|---|
| OPR | 0 | 8 | 次栈顶 := (次栈顶 = 栈顶),t减1 |
| OPR | 0 | 9 | 次栈顶 := (次栈顶 != 栈顶),t减1 |
| OPR | 0 | 10 | 次栈顶 := (次栈顶 < 栈顶),t减1 |
| OPR | 0 | 11 | 次栈顶 := (次栈顶 <= 栈顶),t减1 |
| OPR | 0 | 12 | 次栈顶 := (次栈顶 > 栈顶),t减1 |
| OPR | 0 | 13 | 次栈顶 := (次栈顶 >= 栈顶),t减1 |
转移指令
| 功能 | 层差 | 地址偏移/立即数/指令 | 含义 |
|---|---|---|---|
| JMP | 0 | A | 无条件转移至地址A |
| JPC | 0 | A | 若栈顶为0,转移至地址A,t减1 |
输入输出指令
| 功能 | 层差 | 地址偏移/立即数/指令 | 含义 |
|---|---|---|---|
| OPR | 0 | 14 | 栈顶的值输出至控制台屏幕,t减1 |
| OPR | 0 | 15 | 控制台屏幕输出一个换行 |
| OPR | 0 | 16 | 从控制台读入一行输入,植入栈顶,t加1 |
翻译成中间码
中间码由一些列指令构成。下面包含了功能类型、操作类型和指令的定义:
// 功能类型
enum FuncType
{
Func_LIT, // 取立即数
Func_OPR, // 操作
Func_LOD, // 读取
Func_STO, // 保存
Func_CAL, // 调用
Func_INT, // 初始化空间
Func_POP, // 退栈
Func_JMP, // 无条件跳转
Func_JPC // 有条件跳转
};
// 操作类型
enum OprType
{
Opr_RET, // 过程返回
Opr_NEG, // 栈顶 := -栈顶
Opr_NOT, // 栈顶 := !栈顶
Opr_ADD, // 次栈顶 := 次栈顶 + 栈顶,t减1
Opr_SUB, // 次栈顶 := 次栈顶 - 栈顶,t减1
Opr_MUL, // 次栈顶 := 次栈顶 * 栈顶,t减1
Opr_DIV, // 次栈顶 := 次栈顶 / 栈顶,t减1
Opr_MOD, // 次栈顶 := 次栈顶 % 栈顶,t减1
Opr_EQU, // 次栈顶 := (次栈顶 = 栈顶),t减1
Opr_NEQ, // 次栈顶 := (次栈顶 != 栈顶),t减1
Opr_LES, // 次栈顶 := (次栈顶 < 栈顶),t减1
Opr_LEQ, // 次栈顶 := (次栈顶 <= 栈顶),t减1
Opr_GTR, // 次栈顶 := (次栈顶 > 栈顶),t减1
Opr_GEQ, // 次栈顶 := (次栈顶 >= 栈顶),t减1
Opr_PRT, // 栈顶的值输出至控制台屏幕,t减1
Opr_PNL, // 控制台屏幕输出一个换行
Opr_SCN // 从控制台读取输入,植入栈顶,t加1
};
// 指令
struct Instruction
{
uint32_t func; // 功能
int level; // 层级差
int mix; // 地址偏移/立即数/指令
int reserved; // 保留字(暂时无用)
};
// 程序信息
struct ProgramInfo
{
// [4字节]标识符起始位置 [4字节]标识符数目 [4字节]指令起始位置 [4字节]指令数目
// {
// [64字节] 过程标识符
// { [64字节] 该过程的形参}
// { [64字节] 该过程的变量}
// }
//
// {[16字节] 指令}
std::vector identifiers; // 标识符
std::vector instructions; // 指令
}; 对于一个这样的程序:
procedure A();
// ...
procedure B();
// ...
// 主过程...中间码的结构为:
add func level mix
0 JMP 0 25 ; 跳转到过程__main__
1 INT 0 0 ; 过程A的开始
...
10 INT 0 0 ; 过程B的开始
...
25 INT 0 0 ; 过程__main__的开始
...
40 OPR 0 RET ; 函数返回这里把讲解的重心放在各种含指令跳转的语句设计。
while 循环
while循环的实现相对容易一些,它的代码结构如下:
while a < 5 do
begin
write(a);
a -= 1;
end;大体的指令结构为:
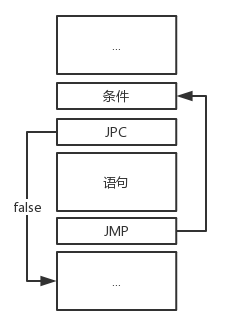
一开始翻译到JPC指令时还不知道待跳转的位置,因此需要先继续向下翻译到JMP指令,再回填JPC的跳转地址。具体代码详见源码
for 循环
相比while循环,for循环的实现更加复杂一些。它的代码结构如下:
for i := 0 step 1 until i >= 10 do
begin
write(a);
end;在代码层面上,step是先翻译的,但是在最终的指令序列中,step部分又得排到执行语句之后。下图展示了for循环的指令结构:
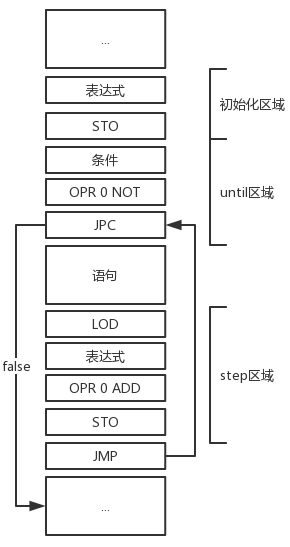
if-else语句
if-else语句相比前两个实现起来更加复杂,因为它可以任意延伸。
if型、if-else型、if-else if型、if-else if-else型(从左到右依次排列)的指令结构如下:
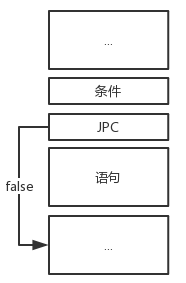
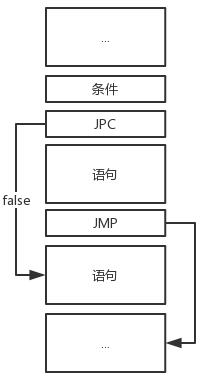
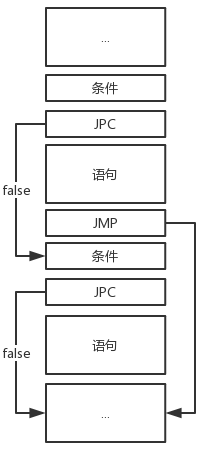
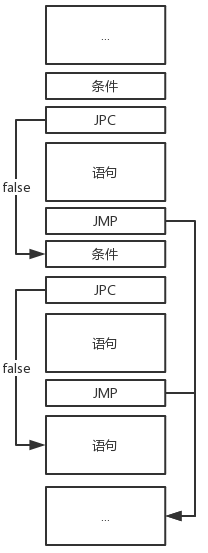
为了实现地址回填,我们需要分别构造真链和假链。假链记录了每一个JPC指令的位置,并且每一个JPC指令最终跳转到距离它下面最近的那个JMP指令处的下一个位置,而真链记录了每一个JMP指令的位置,最终都要跳转到同一个位置。
条件短路
由于逻辑表达式具有这样的特性:对于a && b && ... n,从左向右判断若遇到有一个条件为假,就不再判断后面的表达式,并将结果判假;对于a || b || ... n,从左向右判断若遇到有一个条件为真,就不再判断后面的表达式,并将结果判真。
a && b && …n (左)和a || b || …n (右)的指令结构如下:
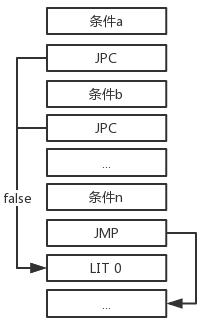
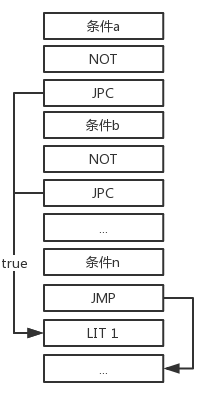
数据栈区
由于含参过程的加入,数据栈的参数如何从调用方的区域转向被调用方的区域就成为了一个问题。
数据栈区从宏观角度上来看可以划分为各个函数片段,每个函数片段内又分为形参区、变量区和临时值区。
注意:这里的栈区是向高地址方向增长。
关于函数的调用与传参,需要进行下述操作:
(1)将call语句传入的参数从左往右依次入栈,更新栈顶指针tr
(2)通过POP指令,根据形参数目让栈顶指针tr退避n个单位偏移量(即回到没入栈时栈顶的位置)
(3)保存当前基址、栈顶、指令地址寄存器的状态,然后将基址偏移量设为栈顶指针的下一个位置(即第一个形参的位置)
(4)完成CAL指令后,下一步的INT指令会为形参和变量开辟空间(这种开辟不是破坏式的,对原压栈的形参无影响),这样原来塞入的值恰好作为形参的值,至于变量,在移动栈顶指针tr的同时查看符号表来赋初值
在函数结束调用后,要进行现场恢复。
错误码与含义
词法分析相关的错误码如下:
| 错误码 | 含义 |
|---|---|
| 1 | Integer length exceed. |
| 2 | Invalid Value. |
| 3 | '=' expected after ':'. |
| 4 | Missing */ |
| 5 | Unknown Character. |
| 6 | '\'' expected. |
| 7 | Character expected between '\''s. |
| 8 | '\"' expected. |
| 9 | Extra '|' Expected. |
| 10 | Extra '&' Expected. |
| 11 | Too much Characters between '\''s. |
| 12 | Identifier length exceed. |
语法分析相关的错误码如下:
| 错误码 | 含义 |
|---|---|
| 21 | ';' expected. |
| 22 | Identifier Expected. |
| 23 | ':=' Expected. |
| 24 | '(' Expected. |
| 25 | ')' Expected. |
| 26 | Keyword 'end' expected. |
| 27 | Keyword 'then' expected. |
| 28 | Keyword 'do' expected. |
| 29 | Keyword 'step' expected. |
| 30 | Keyword 'until' expected. |
| 31 | Typename expected. |
| 32 | Value expected. |
| 33 | Unknown identifier. |
| 34 | Identifier redefined. |
| 35 | Identifier can't be assigned. |
| 36 | Identifier is not a procedure. |
| 37 | Number of function parameter mismatch. |
| 38 | Expression/Condition expected. |
| 39 | '.' Expected. |
| 40 | Invalid expression. |
| 41 | Unexpected content after '.'. |
虚拟机
熬过了语法/语义分析、翻译这个最大难点之后,虚拟机的实现相对就容易的多了。当前虚拟机支持的功能如下:
(1)完整执行程序
(2)逐指令执行程序
(3)逐过程执行程序
(4)执行到跳出当前过程
其中功能2-4适用于调试分析指令。
环境及虚拟机定义
下面定义了程序运行所需的环境及虚拟机
// 环境信息
struct EnvironmentInfo
{
int pr; // 指令地址寄存器
int tr; // 栈顶寄存器
int br; // 基址寄存器
Instruction ir; // 指令寄存器
std::vector dataStack; // 数据栈区
std::stack prStack; // 指令地址寄存栈
std::stack trStack; // 栈顶寄存栈
std::stack brStack; // 基址寄存栈
std::vector funcStack; // 函数调用栈
};
//
// 虚拟机
//
class VirtualMachine
{
public:
// 初始化虚拟机
void Initialize(const ProgramInfo& programInfo);
// 完整执行
void Run();
// 逐指令执行
void RunNextInstruction();
// 逐过程执行
void RunProcedure();
// 执行到跳出该过程
void RunToReturn();
// 程序是否运行结束
bool IsFinished() const;
// 打印当前寄存器信息
void PrintRegisterInfo() const;
// 获取当前寄存器信息
const EnvironmentInfo& GetRegisterInfo() const;
private:
void PrintInstruction(uint32_t address) const;
uint32_t GetProcedureIndex(const std::string& str);
private:
EnvironmentInfo m_EnvironmentInfo; // 寄存器信息
ProgramInfo m_ProgramInfo; // 程序信息
}; 类P-Code指令基本上都是零地址指令和一地址指令,由于没有数据寄存器,所有的值操作都是在数据栈上执行的。
剩余实现详见源码部分。
样例测试
下面给出一些用于测试的代码,样例尽可能做到复杂和覆盖面广
样例1 复杂表达式测试
/*
复杂表达式测试
*/
int a;
begin
a := 345;
write(a); // 345
a := 17 +23;
write(a); // 40
a := 6 * 15;
write(a); // 90
a := 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8+ 9 +10;
write(a); // 55
a := 1 * 2 * 3 * 4 * 5 *6 * 7 * 8 * 9 * 10;
write(a); // 3628800
a := 1 + 2 * 3;
write(a); // 7
a := 10 + 35 / 3 / 4;
write(a); // 12
a := 2 * 3 * 4 - 7 / 3 * 5 + 6*2;
write(a); // 26
a := 4 + 5 + 2 * 3 - 0 / 7 - 4 * 1 +
12 + 13 * 4 / 6 * 5 - 2 * 2 * 3;
write(a); // 51
a := 0+1+2-0*0-0/3- 3;
write(a); // 0
a := 3 - 5;
write(a); // -2
a := (3 + 5) - (2 + 4);
write(a); // 2
a := (3+ (10 -(4 - 2) ) );
write(a); // 11
a := (1+(4+5+2)-3)+(6+8);
write(a); // 23
a := 3+(4+(5+(6+(7-1)-2)-3)-4)-5;
write(a); // 10
a := 23-(18 - ((14-17) - 12));
write(a); // -10
a := (100 +99+(98+97+(96+95+((94+93+(92+(91 ))
+(90 +(89+ 88) + (87+86+ 85)))+
((84+(83+82))+81+80)))));
write(a); // 1890
a := (2 + 3) * 5;
write(a); // 25
a := 4 - (5 - 2) + (3 - 7) * 2;
write(a); // -7
a := 100 * (2+12)-(20/3) *2;
write(a); // 1388
a := (12- (6 - 3) * (7 -4) + 7 * 3) / 5;
write(a); // 4
a := ((((((((1 + 2) * 2) + 3) * 3) + 4) * 4)
+ 5) * 5);
write(a); // 645
a := (1 + ((2 + 3) * (3 + 4)) /
((4 - 2) * (7 - 4))) % 5;
write(a); // 1
a := (((((1))))) + ((2)) + ((((3)))) * ((((4))));
write(a); // 15
a := ((100 * 4) - (((31 / (7 - 3) + 2) * 18 - 5)
/ 6) + (35 / 7 + 4) * (31 - 15)) % 15;
write(a); // 8
a := -3;
write(a); // -3
a := +4;
write(a); // 4
a := -3 * -2;
write(a); // 6
a := -(3 + 4);
write(a); // -7
a := -3 + -(2 * 5);
write(a); // -13
a := -4 / -(-3);
write(a); // -1
a := -(-(-(-(-(-5)))));
write(a); // 5
end.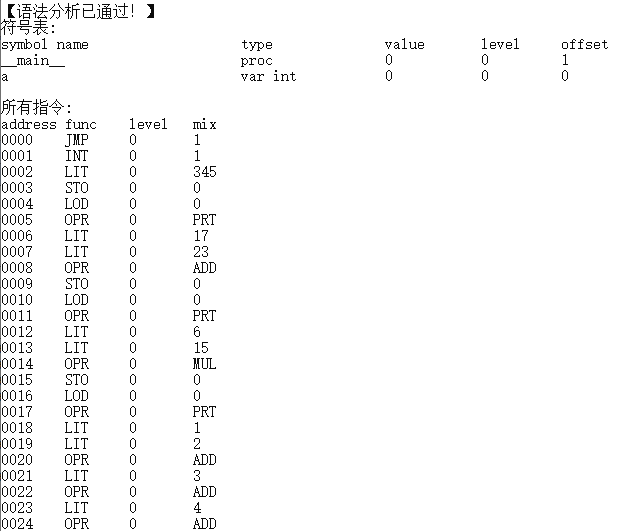

样例2 复杂条件语句测试
// *********************
// 复杂条件语句测试
//
int a, b;
begin
a := 3;
b := 5;
//
// if
//
if (a > 4) then
begin
b := 7;
end;
//
// if else
//
if (a > 2) then
b := 8
else
begin
a := 3
end;
//
// if else-if
//
if (a > 4) then
b := 8
else if a < 2 then
begin
a := 3
end;
//
// if else-if else
//
if (a > 4) then
b := 8
else if a < 2 then
begin
a := 3
end
else
write(a, b);
//
// if else-if else-if
//
if a > 6 + 4 then
b := 8
else if a < 2 then
begin
a := 3
end
else if a = 3 then
write(b, a)
end.

样例3 复杂条件值测试
//
// 复杂条件值测试
//
int a, b;
begin
a := 3;
b := 5;
if a > b && a > 5 then write(1);
if a < b || a > 5 then write(2);
if a <= b || a > 3 && b <= 4 then write(3);
if a != b && b != a || a = b && b = a then write(4);
if a + 3 > b && (a - 3 < b || b >= 0) then write(5);
if !(a > b) then write(6);
if !(a > b && b > 0) then write(7);
if !(a < b) || !(a = 3) then write(8);
if !(!(!(!(!(-a + b > 0))))) then write(9);
if (a = b || a - (-b) > 3) && (b >= 4 || a <= 5) then write(10);
end.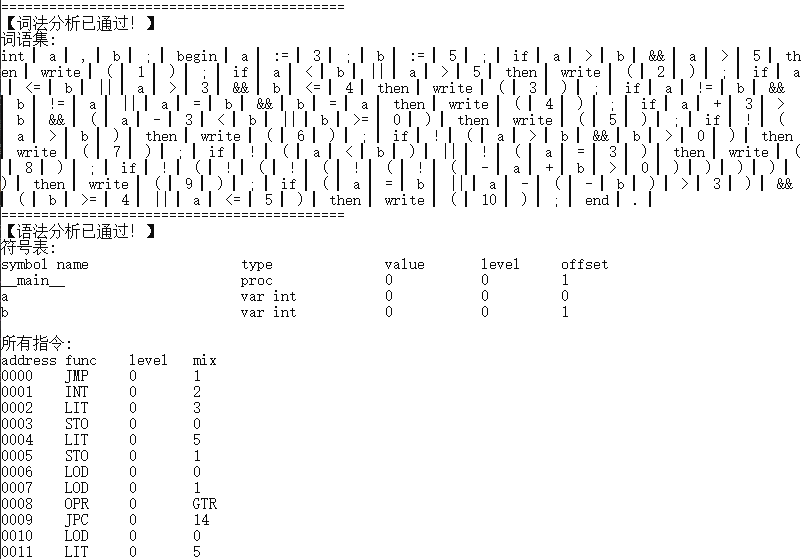

样例4 短路测试
//
// 短路测试
//
int a, b;
begin
a := 3;
b := 5;
// false && false
if a > 4 && b > 5 then
write(1);
// false && true
if a > 4 && b > 4 then
write(2);
// true && false
if a > 2 && b > 5 then
write(3);
// true && true
if a > 2 && b > 3 then
write(4);
// false || false
if a > 4 || b > 5 then
write(5);
// false || true
if a > 4 || b > 4 then
write(6);
// true || false
if a > 2 || b > 5 then
write(7);
// true || true
if a > 2 || b > 3 then
write(8);
if a <= b || a > 3 && b <= 4 then
write(9);
if a + 3 > b && (a - 3 > b || b >= 0) then
write(10);
end.
样例5 for循环语句测试
int i, sum, times;
// 计算1+2+3+...+times
begin
sum := 0;
read(times);
for i := 1 step 1 until i > times do
begin
sum += i;
end;
write(sum);
end.

样例6 while循环语句测试
本测试除了验证基本的语法/语义分析外,还需要验证指令产生和运行结果:
// *********************
// while循环语句测试
//
int i, sum, sum2;
begin
sum := 0;
sum2 := 0;
//
// while+语句块
//
i := 100;
while (i > 0) do
begin
sum += i;
i -= 1;
end;
write(sum);
//
// while+语句
//
read(i);
while (i < 100 && i != 0) do
i *= i;
write(i);
end.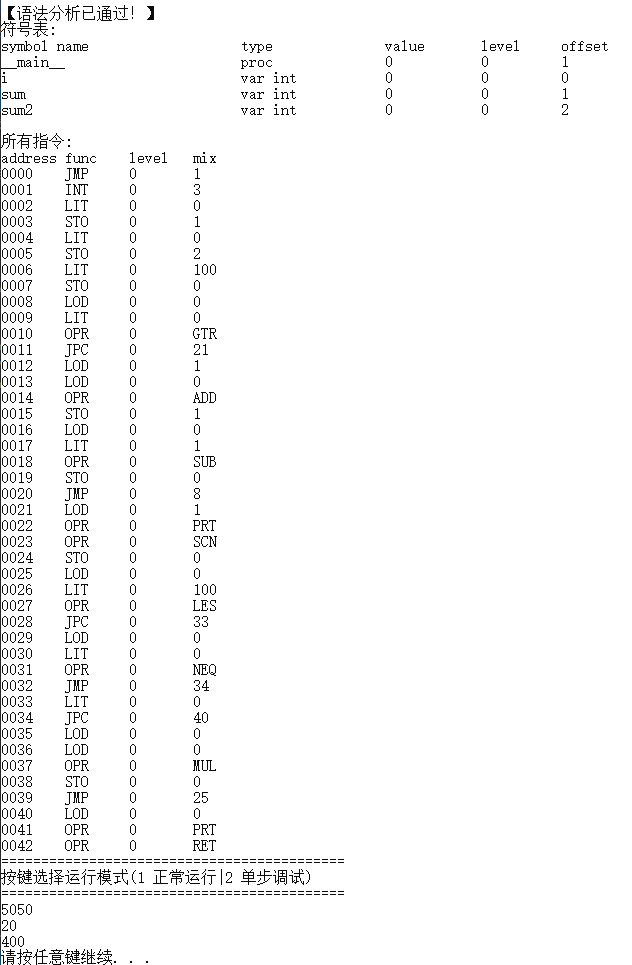
样例7 过程调用测试
int a, b, c;
procedure output(int a, int b);
write(a, b);
procedure swapAB();
begin
c := a;
a := b;
b := c;
end;
begin
a := 3;
b := 5;
call swapAB();
call output(a, b);
end.

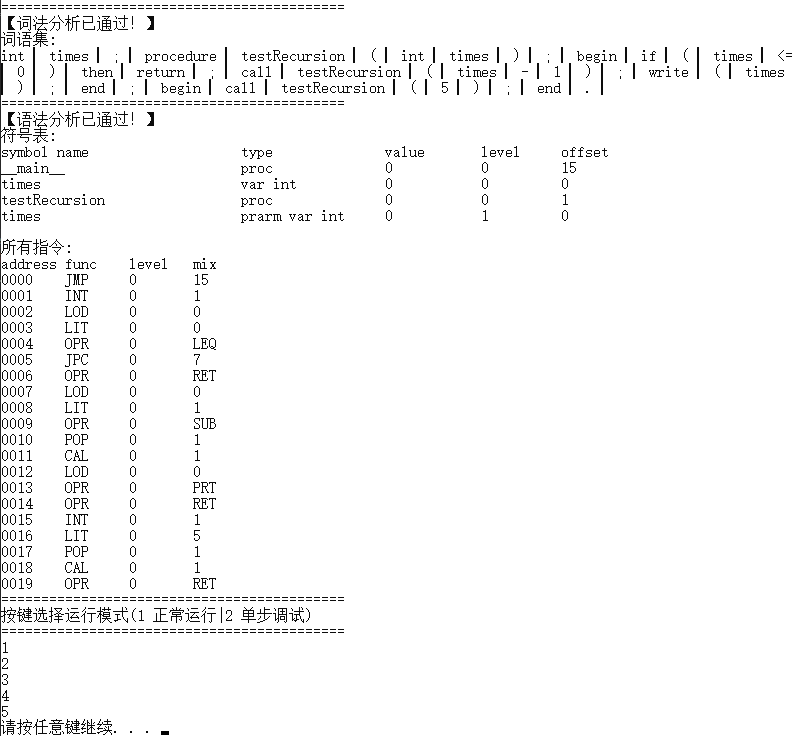
样例8 递归调用测试
//
// 递归测试
//
int times;
procedure testRecursion(int times);
begin
if (times <= 0) then return;
call testRecursion(times - 1);
write(times);
end;
begin
call testRecursion(5);
end.
样例9 加减乘除余后赋值测试
// *********************
// 加减乘除余后赋值测试
//
int a, b;
begin
a := 5;
a += 4;
write(a);
a -= 3;
write(a);
a *= 6;
write(a);
a /= 9;
write(a);
a %= 3;
write(a);
a += 3 * 4;
write(a);
end.
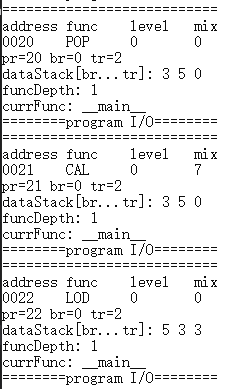
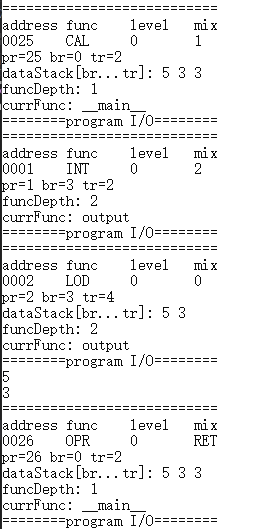
调试功能测试
本测试使用样例8的递归程序,对逐指令、逐过程、跳出过程调试功能进行验证。
逐指令调试:

逐过程调试:
跳出过程调试:
报错信息测试
本测试主要针对出现拼写错误、不正确语法的部分情况:

