1. 论文相关
CVPR2019

2.摘要
2.1 摘要
小样本学习是一个重要的研究领域。从概念上讲,只要举几个例子,人类就很容易理解新的概念,而从更实用的角度来说,有限的例子训练情景在实践中是常见的。最近有效的小样本学习方法使用一个度量学习框架来学习查询(测试)示例和少数支持(训练)示例之间的特征相似性比较。然而,这些方法将每个支持类彼此独立地对待,从不将整个任务视为一个整体。正因为如此,他们被限制为对所有可能的测试时间任务使用一组单一的特征,这妨碍了区分手头任务最相关维度的能力。在这项工作中,我们引入了类别遍历模块(Category Traversal Module),可以作为即插即用模块插入到大多数基于度量学习的小样本学习器中。该组件一次遍历整个支持集,根据特征空间中的类内通用性和类间唯一性(intra-class commonality 和 inter-class uniqueness)来识别与任务相关的特征。在miniImageNet和tieredImageNet基准上,与基准系统相比,合并我们的模块大大提高了性能(相对提高了5%-10%),总体性能与最新的最先进系统具有竞争力。
2.2 主要贡献
(1)为了结合支持集的类间和类内视图,我们引入了一个类别遍历模块(category traversal
module,CTM)。这样的模块在跨类别遍历之后选择最相关的特征维度。CTM的输出绑定到支持集和查询集的特征嵌入上,使得后续特征空间(subsequent feature space)的度量学习更加有效。CTM包括一个集中器单元(concentrator unit),用于提取一个类别中的嵌入以实现通用性,以及一个投影仪单元(projector unit),用于考虑集中器跨类别的输出以实现唯一性。集中器和投影仪可以实现为卷积层。图1(b)给出了如何将CTM应用到现有的基于度量的小样本学习算法中。它可以看作是一个即插即用的模块,通过考虑支持集中的全局特征分布来提供更具判别力和代表性的特征,从而使高维空间中的度量学习更加有效。
(2)我们证明了我们的类别遍历模块在小样本学习基准上的有效性。CTM与以前的最先进水平相当或超过以前的水平。将CTM结合到现有算法[36, 38, 35 ]中,我们在miniImageNet 和tieredImageNet上都看到大约5%到10%的一致相对增益。代码套件位于:https://github.com/Clarifai/few-shot-ctm。
2.3 思想
(1) In this paper, we extend the effective metric-learning based approaches to incorporate the context of the entire support set, viewed as a whole. By including such a view, our model finds the dimensions most relevant to each task. This is particularly important in few-shot learning: since very little labeled data is available for each task, it is imperative to make best use of all of the information available from the full set of examples, taken together.
在本文中,我们扩展了有效的基于度量学习的方法,将整个支持集视为一个整体。通过包含这样的视图,我们的模型可以找到与每个任务最相关的维度。这在小样本学习中尤为重要:由于每个任务几乎没有可用的标记数据,因此必须最好地利用全套示例中的所有可用信息。
(2) Thus, in addition to inter-class uniqueness, relevant dimensions can also be found using the intra-class commonality. Note in this k > 1 case, feature averaging within each class is an effective way to reduce intra-class variations and expose shared feature components; this averaging is performed in [35, 36]. While both inter- and intra-class comparisons are fundamental to classification, and have long been used in machine learning and statistics [8], metric based few-shot learning methods have not yet incorporated any of the context available by looking between classes.
因此,除了类间唯一性外,还可以利用类内公共性找到相关维度。注意在这1种情况下,每个类内的特征平均是减少类内变化和公开共享特征组件的有效方法;这种平均在[35,36]中执行。虽然类间和类内比较是分类的基础,并且在机器学习和统计中长期使用[8],但是基于度量的小样本学习方法还没有通过在类之间进行查找来整合任何可用的上下文。


3. 算法
3.1. 关于小样本学习的描述
在一些小样本分类任务中,我们给出了一个小的支持集,其中包含个不同的、以前看不见的类,每个类都有K个示例。给定一个查询示例,目标是将其分类为一个支持类别。
训练(Training)
Inference
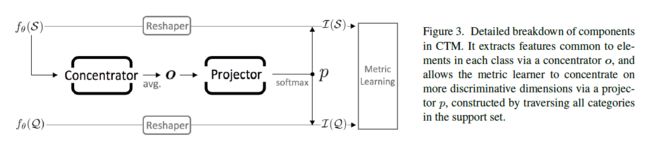
3.2. 类别遍历模块(CTM)
图3显示了我们的模型的总体设计。类别遍历模块以支持集特征作为输入,通过分别使用类内和类间视图的集中器和投影器生成掩码。掩码应用于支持和查询的降维特征,生成与当前任务相关的维度的改进特征。这些改进的特征嵌入最终被输入到度量学习器中。
3.2.1 集中器:类内公共性(Concentrator: Intra-class Commonality)
CTM中的第一个组件是一个集中器,用于查找一个类的所有实例共享的通用特征(universal features)。将特征提取器的输出形状表示为,其中分别表示通道数和空间大小(spatial size)。我们对集中器的定义如下:

其中和表示信道和空间大小的输出数目。请注意,输入首先被送到CNN模块以执行降维;然后对每个类中的样本进行平均以获得最终输出o。在单样本设置中,没有平均操作,因为每个类只有一个示例。
实际上,CNN模块可以是一个简单的CNN层或ResNet块[16]。其目的是消除实例之间的差异,提取同一类实例之间的共性。这是通过从到的适当向下采样来实现的。这样的学习组件被证明比平均方案[35]要好,后者在没有学习参数的情况下,当时可以被视为我们集中器的一个特殊情况。
3.2.2 投影仪:类间唯一性(Projector: Inter-class Uniqueness)
第二个组件是一个投影仪,它可以屏蔽(mask out)不相关的特征,并通过从所有支持类别同时查找集中器特征去选择对于目前小样本任务最具有判别力的特征:
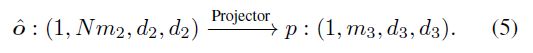
如果只是o的重塑版本(reshaped version);和遵循与集中器中类似的含义。我们通过将第一个维度(N)中的类原型连接到通道维度()来实现跨类遍历的目标,对连接的特征应用一个小CNN来生成大小的映射,最后在通道尺寸上应用softmax(分别用于×空间尺寸中的每一个)来产生掩模。这用于屏蔽查询和支持集中任务的相关特征维度。
3.2.3 整形器(Reshaper)
为了使投影仪的输出对特征嵌入产生影响,我们需要在网络中匹配这些模块之间的形状。这是通过分别应用于每个NK样本的整形器网络实现的:
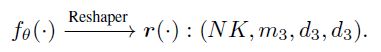
它是以轻量级的方式设计的,有一个CNN层。
3.2.4 CTM中的设计选择
在上述组件的支持下,我们可以通过遍历所有类别来生成一个掩码输出:。CTM的效果是通过将投影器输出绑定到支持和查询的特征嵌入上来实现的,表示为。因此,改进后的特征表示有望更具区分性。
对于查询,选择很简单,因为我们没有查询标签;组合是嵌入和投影器输出的元素乘法(elementwise multiplication):,其中表示在Q中沿样本维度(NK)广播的p的值。
然而,对于支持,由于我们知道查询标签,我们可以选择直接屏蔽p到嵌入(按样本),或者如果我们保持(m2,d2,d2)=(m3,d3,d3),我们可以使用它屏蔽集中器输出o(按集群)。从数学上讲,这两个选项是:
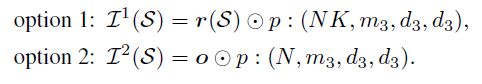
我们发现,由于比较次数较多,选项1的执行时间略有增加,因此其性能更佳;详细信息请参见第2节。4.2.1条。
3.3. CTM正在运行
提出的类别遍历模块是一个简单的即插即用模块,可以嵌入到任何基于metric的小样本学习方法中。本文考虑了三种基于度量的方法,并将其应用到匹配网络[38]、原型网络[35]和关系网络[36]中。如第2节所述。1、这三种方法都受到限制,不能同时考虑整个支持集。由于特征是为每个类独立创建的,因此与当前任务无关的嵌入最终可能会主导度量比较。这些现有的方法定义它们的相似性度量如等式(1);我们将其修改为使用我们的CTM,如下所示:
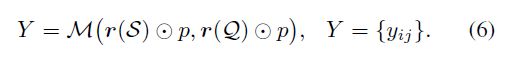
如我们稍后所示(见第4.3.1节)在整合了所提出的CTM单元之后,这些方法在不同的设置下得到了较大的改进(2%-4%)。
4. 评价
这些实验旨在回答以下关键问题:(1)在大规模的小样本学习基准上,CTM是否有竞争力?(2)CTM是否可以作为简单的即插即用,并获得现有方法的收益?什么是CTM工作的基本组成部分和要素?(3)CTM如何修改特征空间,使特征更具区分性和代表性?
4.1. 数据集和设置
数据集(Datasets)
minimagenet数据集[38]是从ILSVRC-12数据集[32]中选择的100个类的子集,每个类中有600个图像。它分为训练元集、验证元集和测试元集,分别有64、16和20个类。tieredImageNet数据集[30]是ILSVRC-12的一个较大的子集,其中608个类(779165个图像)基于WordNet层次结构分组为34个更高级别的节点[5]。这组节点被划分为20、6和8个不相交的训练、验证和测试节点集,相应的类由相应的元集组成。如[30]所述,tieredImageNet的分割更具挑战性,现实的测试类制度与训练类不太相似。请注意,验证集仅用于调整模型参数。
评估指标(Evaluation metric)
我们报告了600个随机产生的episode的平均准确度(%),以及测试集上95%的置信区间。在测试期间的每一集中,每个类都有15个查询,遵循大多数方法[35、36、33]。
实施细节(Implementation details)
对于训练,5路问题有15个查询图像,而20路问题有8个查询图像。20路设置中查询样本数较少的原因主要是出于GPU内存的考虑。输入图像大小调整为84×84。
我们使用Adam[18]优化器,初始学习率为0.001。miniImageNet和tieredImageNet上的总训练次数分别为600000和1000000次。每20万集或当损失进入平稳期时,学习率下降10%。重量衰减设定为0.0005。也应用渐变剪裁。
4.2. 烧蚀研究(Ablation Study)
4.2.1 浅层网络验证(Shallow Network Verification)
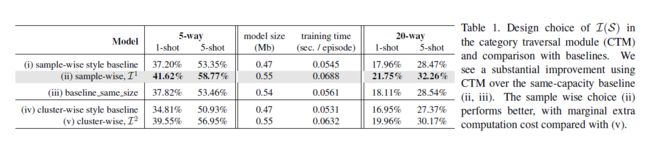
我们首先通过使用一个简单的骨干网与相同容量的基线进行比较来验证类别遍历的有效性。具体来说,采用4层神经网络作为骨干,直接计算和之间的特征相似度。报道了minimagenet的平均精度。特征嵌入后,m1=64,d1=21;集中器为步长为2的CNN层,即,m2=32,d2=10。为了比较两种选择(I1或I2),投影器保持尺寸不变,即,m3=m2,d3=d2。
基线比较(Baseline comparison)
结果报告在表1中。模型尺寸和训练时间是在5-way 5-shot的情况下测量的。第(i)行和第(iv)行中的“基线”仅评估具有重塑器网络和度量比较的模型,忽略CTM集中器和投影仪。第(ii)行显示了包含我们的CTM的模型。由于与基线(i)相比,添加CTM增加了模型容量,因此我们还包括一个相同大小的模型基线进行比较,如“基线相同大小”(i ii)所示,方法是在主干上添加额外的层,使其模型大小与(ii)相似。注意,(i)和(iv)之间的唯一区别是,后一种情况取每个类别内样本的平均数。
我们可以看到,与基线相比,在5-way and 20-way设置中使用CTM平均有10%的相对改善。值得注意的是,较大容量基线仅比原始基线略有改善,而使用CTM的改进是实质性的。这表明CTM获得的性能提升实际上是因为它能够为每个任务找到相关的特征。
哪个选项对比较好?
表1(ii,v)显示了和之间的比较。一般来说,抽样选择比好2%。请注意,这两个模型的大小完全相同;唯一的区别是p如何相乘。然而,的一个小缺点是时间稍慢(0.0688 vs 0.0632),因为它需要在所有样本中广播p。尽管效率很高,但我们还是选择第一个选项作为生成的首选项。
4.2.2 具有更深网络的CTM(CTM with Deeper Network)
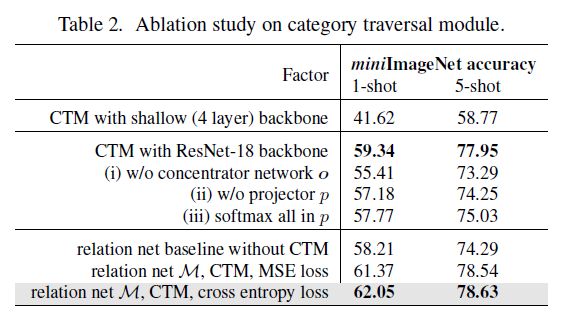
表2报告了CTM不同成分的消融分析。为特征抽取器使用更深的主干可以大大提高性能。第二块实验分别研究了集中器和投影器的效果。单独移除每个组件会导致性能下降(案例一、二、三)。如果去掉集中器的网络部分,则精度较低(-3.93%,单样本情况),这意味着它的降维和空间降采样对于最终的比较非常重要。移除投影器也会导致显著下降(-2.16%,单样本),这证实了这一步骤对于找到特定任务的区分维度是必要的。一个有趣的结果是,如果我们在p中的所有位置(m3; d3; d3)执行softmax操作,则精度(57.77%)低于分别针对每个位置(59.34%)沿信道维度(m3)执行softmax;这与数据一致,其中图像中的绝对位置仅与任何类差适度相关。
此外,我们将关系模块[36]作为最后一个模块M的度量学习器,它由两个CNN块和两个随后的fc层组成,生成一个查询支持对的关系得分。无CTM的基线关系网模型的准确率为58.21%。在包含了我们提议的模块之后,性能增加3.84%,达到62.05%。注意,原始文献[36]使用了均方误差(MSE);我们发现交叉熵稍好一些(分别为0.68%和0.09%的1-shot和5-shot),如等式2所定义。
4.3. 与最新技术的比较(Comparison with StateoftheArt)
4.3.1 将CTM应用到现有框架中(Adapting CTM into Existing Frameworks)
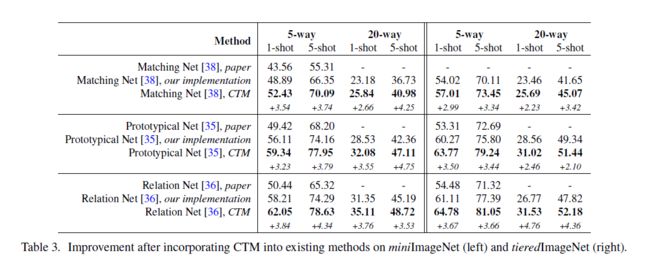
为了验证我们提出的类别遍历模块的有效性,我们将其嵌入到三个与我们的算法密切相关的基于度量的算法中。值得注意的是,应该在公平的环境下进行比较;但是,不同的来源报告不同的结果。这里我们描述我们使用的实现。
Matching Net [38] and Prototypical Net [35]
在这些情况下,度量模块M是成对特征距离。注意,在[38]和[35]之间改进的一个主要来源是,将查询与每个类的平均特征进行比较;这会产生包含类内通用性的效果,我们在集中器模块中使用了这一点。对于从原始论文到我们的基线的改进,我们使用带有欧几里德距离的ResNet-18模型进行相似性比较,而不是原来带有余弦距离的浅层CNN网络。
Relation Net [36]
对于从原始论文到基线的改进,骨干结构由4-conv模型转换为ResNet-18模型;关系单元M采用ResNet块代替CNN层;监督损失变为交叉熵。
表3显示了将CTM包含到每种方法中所获得的增益。我们观察到,平均而言,采用CTM后有大约3%的增加。这显示了我们的模块在多个基于度量的系统中即插即用的能力。此外,无论启动性能如何,每种方法的增益都保持一致水平。这支持了这样一个假设,即我们的方法能够将这些方法中任何一种以前都不可用的信号,即每个任务中的类间关系,合并在一起。
4.3.2 超越基于度量的方法的比较(Comparison beyond Metric-based Approaches)
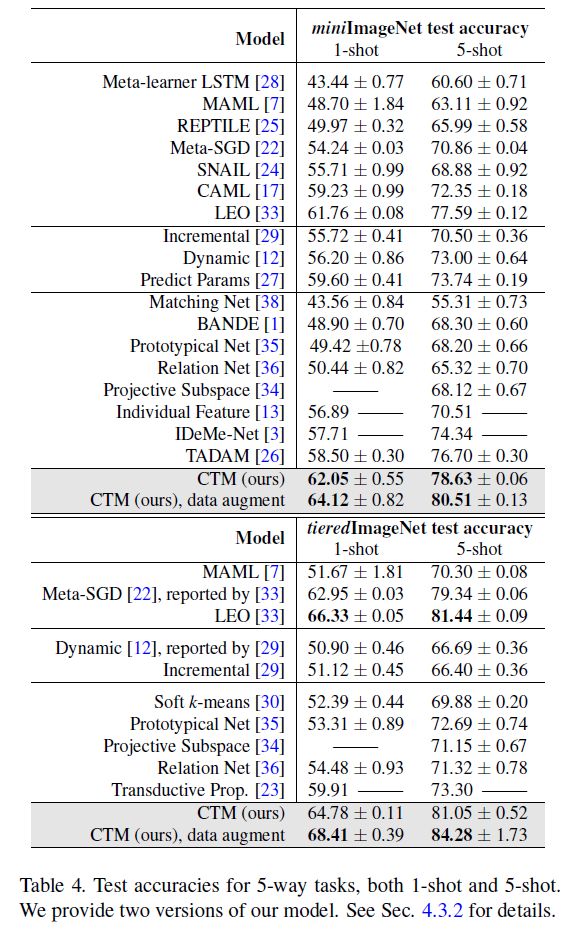
我们将我们提出的CTM方法与表4中的其他最新方法进行了比较。对于每个数据集,第一个方法块是基于优化的,第二个是基类语料库算法,第三个是基于度量的方法。我们使用ResNet-18主干作为特征抽取器,与其他方法进行比较。该模型采用标准初始化从头开始训练,不使用额外的训练数据(例如干扰器[30,23])。我们相信这样的设计与大多数比较过的算法在精神上是一致的。
结果表明,与大多数方法相比,我们的CTM方法有很大的优势,不仅限于基于度量的方法,而且还与基于优化的方法进行了比较。例如,在5-way 1-shot设置下,miniImageNet和tieredImageNet两个基准的性能分别为62.05%和59.60%[27]和64.78%和59.91%[23]。
LEO[33]在tieredimagnet上比我们的(不增加数据)稍好一些。它使用28层的宽残差网络[40];它们还对整个训练集使用监督任务对模型进行预训练,并基于这些预训练特征对网络进行微调。为了实际的兴趣,我们还训练了一个模型的版本,其中包括有监督的预训练(仅使用mini-或tieredimagnet训练集)、基本数据增强(包括随机裁剪、颜色抖动和水平翻转)和更高的权重衰减(0.005)。结果显示在每个数据集的最后一个案例中。注意,考虑到LEO的wideResNet-28,网络结构仍然是ResNet-18。
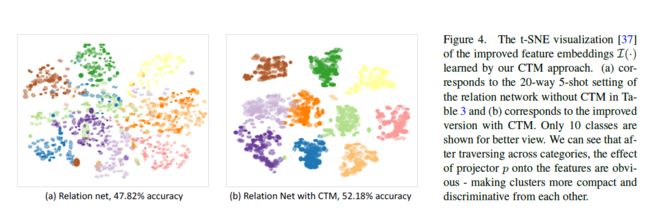
4.4. CTM学习特征可视化(Feature Visualization Learned by CTM)
图4使用t-SNE可视化特征分布[37]。以20-way 5-shot设置计算的特征,但仅显示10个类以便于比较。模型(a)在不使用CTM的情况下达到了47.32%的精度,改进后的模型(b)在使用CTM的情况下,性能提高了52.18%。在对模型的t-SNE特征进行采样时,我们使用,即在应用遮罩(mask p)之后。由于这取决于支持示例,因此根据所选的任务,特征将有很大的不同。因此,在采样任务以创建这些可视化特征时,我们首先选择了20个类,并在从该类集中绘制不同的随机支持样本时保持这些类不变。我们在测试集上总共画了50episode。
可以清楚地看到,CTM模型具有更紧密和可分离的聚类,这表明特征对任务的区分性更强。这源于类别遍历模块的设计。如果没有CTM,一些簇会相互重叠(例如,浅绿色和橙色),使得度量学习难以比较。
5. 结论
在本文中,我们提出了一个类别遍历模块(CTM),通过查看整个支持集的上下文,来提取与每个任务最相关的特征维度。通过这样做,它能够利用类间唯一性和类内公共性属性,这两个属性都是分类的基础。通过一起查看所有支持类,我们的方法能够为每个任务识别有区别的特征维度,同时仍然从头开始学习有效的比较特征。我们设计了一个集中器,通过有效地对输入特征进行降采样和平均,首先提取类内实例之间的特征共性。引入一个投影器来遍历支持集中所有类别的特征尺寸。投影器的类间关系主要集中在对相关特征维度的研究上。然后将CTM的输出合并到特征嵌入中,以便支持和查询;增强的特征表示对于任务来说更加独特和有判别力。我们已经证明,它比以前的方法有了很大的改进,并且与最先进的方法相比具有很强的竞争力。
参考资料
[1]
[2]
[3]
论文下载
[1] Finding Task-Relevant Features for Few-Shot Learning by Category Traversal
代码
[1] # Clarifai/few-shot-ctm