文章原创,最近更新:2018-08-13
本章节的主要内容是:
重点介绍项目案例1:判定鱼类和非鱼类选择最好的数据集划分方式的函数代码。
1.决策树项目案例介绍:
项目案例1:
判定鱼类和非鱼类
项目概述:
- 根据以下 2 个特征,将动物分成两类:鱼类和非鱼类。
- 特征: 1. 不浮出水面是否可以生存 2. 是否有脚蹼
开发流程:
- 收集数据:可以使用任何方法
- 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化
- 分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期
- 训练算法:构造树的数据结构
- 测试算法:使用决策树执行分类
- 使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义
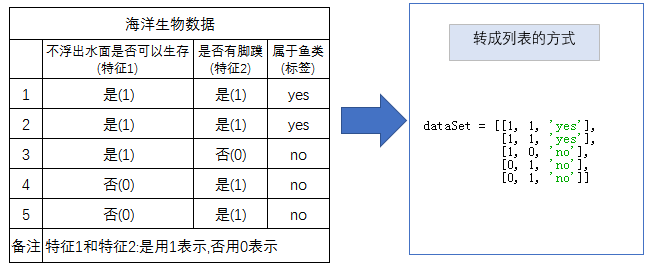
数据集介绍

2.选择最好的数据集划分方式的函数代码
接下来我们将遍历整个数据集,循环计算香农熵和 splitDataSet()函数,找到最好的特征划分方式。熵计算将会告诉我们如何划分数据集是最好的数据组织方式.
打开文本编辑器,在 trees.py文件中输入下面的程序代码。
def chooseBestFeatTopSplit(dataSet):
"""chooseBestFeatureToSplit(选择最好的特征)
Args:
dataSet 数据集
Returns:
bestFeature 最优的特征列
"""
# 求第一行有多少列的 Feature, 减去1,是因为最后一列是label列
numFeatures = len(dataSet[0])-1
# 计算没有经过划分的数据的香农熵
baseEntropy = calcShannonEnt(dataSet)
# 最优的信息增益值
bestInfoGain = 0.0
#最优的Featurn编号
bestFeature = -1
for i in range(numFeatures):
# 创建唯一的分类标签列表,获取第i个的所有特征(信息元纵排列!)
featList = [example[i] for example in dataSet]
"""
print(featList)结果为
[1, 1, 1, 0, 0]
[1, 1, 0, 1, 1]
"""
# 使用set集,排除featList中的重复标签,得到唯一分类的集合
uniqueVals = set(featList)
"""
print(uniqueVals)结果为
{0, 1}
{0, 1}
"""
newEntropy = 0.0
# 遍历当次uniqueVals中所有的标签value(这里是0,1)
for value in uniqueVals:
# 对第i个数据划分数据集, 返回所有包含i的数据(已排除第i个特征)
subDataSet = splitDataSet(dataSet, i, value)
"""
print(subDataSet)结果为
[[1, 'no'], [1, 'no']]
[[1, 'yes'], [1, 'yes'], [0, 'no']]
[[1, 'no']]
[[1, 'yes'], [1, 'yes'], [0, 'no'], [0, 'no']]
"""
# 计算包含个i的数据占总数据的百分比
prob = len(subDataSet)/float(len(dataSet))
"""
print(prob)结果为
0.4
0.6
0.2
0.8
"""
# 计算新的香农熵,不断进行迭代,这个计算过程仅在包含指定特征标签子集中进行
newEntropy += prob * calcShannonEnt(subDataSet)
"""
print(calcShannonEnt(subDataSet))
0.0
0.9182958340544896
0.0
1.0
print(newEntropy)结果为
0.0
0.5509775004326937
0.0
0.8
"""
# 计算信息增益
infoGain = baseEntropy - newEntropy
# 如果信息增益大于最优增益,即新增益newEntropy越小,信息增益越大,分类也就更优(分类越简单越好)
"""
print(infoGain)结果为
0.4199730940219749
0.17095059445466854
"""
if (infoGain > bestInfoGain):
# 更新信息增益
bestInfoGain = infoGain
# 确定最优增益的特征索引
bestFeature = i
# 更新信息增益
# 返回最优增益的索引
return bestFeature
测试代码及其 结果如下:
import trees
myDat,labels=trees.createDataSet()
myDat
Out[182]: [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
trees.chooseBestFeatTopSplit(myDat)
Out[183]: 0
通过数学计算演算以上数据集的最优增益,具体如下:
整个样本集合的熵公式,如下:
为了简便运算,属于鱼类的设为y,不属于鱼类的设为n,具体见表格:
| 类别 | 属于鱼类y | 不属于鱼类n | 总共 |
|---|---|---|---|
| 个数 | 2 | 3 | 5 |
| 所占比例 | 1 |
由此可知,区分是否鱼类的整个样本的熵为如下计算过程:
假设用某一个字段A来划分,在这种划分规则下的熵为
由数据集可知道,数据集有特征1和特征2,因此我们分别计算特征1和特征2的熵.
假设用特征1来划分:
这里的特征1(不浮出水面是否可以生存)共有2个枚举值(是、否),表示划分成2组,那么本案例中特征1字段划分就是v=2的情况。表示这种分组产生的概率,即不浮出水面是否可以生存各自的比例,具体可见如下表格:
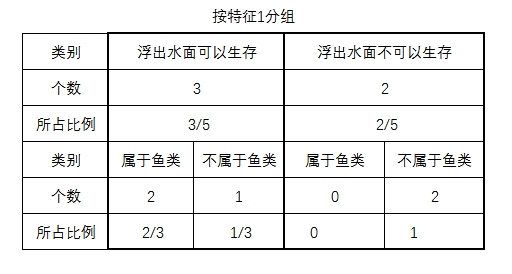
为了简便运算,浮出水面可以生存的设为,浮出水面不可以生存的设为,则特征1的熵()计算结果如下:
=(浮出水面可以生存浮出水面不可以生存
浮出水面可以生存分割熵)浮出水面不可以生存分割熵
假设用特征2来划分:
这里的特征2(是否有脚蹼)共有2个枚举值(是、否),表示划分成2组,那么本案例中特征2字段划分就是v=2的情况。表示这种分组产生的概率,即是否有脚蹼各自的比例,具体可见如下表格:
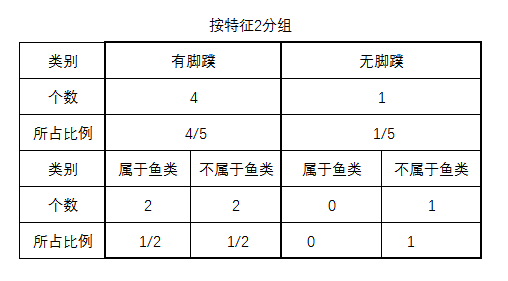
为了简便运算,有脚蹼的设为,无脚蹼设为,则特征2的熵()计算结果如下:
=(有脚蹼无脚蹼
有脚蹼分割熵)无脚蹼分割熵
信息增益公式如下:
由此可以得到以特征1为根的信息增量为:
由此可以得到以特征2为根的信息增量为:
因为>,所以特征1是最好的用于划分数据集的特征.
3.相关知识点:信息增量的小案例
假设相亲信息表如下所示:
| 网站ID | 年龄(岁) | 身高(cm) | 年收入(万元) | 学历 | 是否相亲 |
|---|---|---|---|---|---|
| XXXXXXX | 25 | 179 | 15 | 大专 | N |
| XXXXXXX | 33 | 190 | 19 | 大专 | Y |
| XXXXXXX | 28 | 180 | 18 | 硕士 | Y |
| XXXXXXX | 25 | 178 | 18 | 硕士 | Y |
| XXXXXXX | 46 | 177 | 100 | 硕士 | N |
| XXXXXXX | 40 | 170 | 70 | 本科 | N |
| XXXXXXX | 34 | 174 | 20 | 硕士 | Y |
| XXXXXXX | 36 | 181 | 55 | 本科 | N |
| XXXXXXX | 35 | 170 | 25 | 硕士 | Y |
| XXXXXXX | 30 | 180 | 35 | 本科 | Y |
| XXXXXXX | 28 | 174 | 30 | 本科 | N |
| XXXXXXX | 29 | 176 | 36 | 本科 | Y |
假设拿到真实的12个样本,由于网站ID这种信息对大龄女青年们做出相亲决策没有什么影响,所以直接忽略,下面来看后面的数据项。
整个样本集合的熵如下:
为了简便运算,属于相亲的设为y,不相亲的设为n,具体见表格:
| 类别 | 相亲y | 不相亲n | 总共 |
|---|---|---|---|
| 个数 | 7 | 5 | 12 |
| 所占比例 | 1 |
由此可知,区分是否相亲的整个样本的熵为如下计算过程:
现在要做的是挑出这个“树根”,挑出“树根”的原则是这一个点挑出来一刀切下去,要尽可能消除不确定性,最好一刀下去就把两个类分清楚,如果不行才会选择在下面的子节点再切一次,切的次数越少越好。`
假设用某一个字段A来划分,在这种划分规则下的熵为
以“学历”字段做分割的情况下,熵有什么变化。,具体运算过程如下:
是指要求的熵,右侧从1到v做加和,其中v表示一共划分为多少组,A字段有3个枚举值,表示划分成3组,如例子中“学历”字段就有3个枚举值,那么用“学历”字段划分就是v=3的情况。Pj表示这种分组产生的概率,也可以认为是一种权重,即3种学历各自占的比例,这里大专是2/12,本科是5/12,硕士是5/12。是在当前分组状态下的期望信息值。
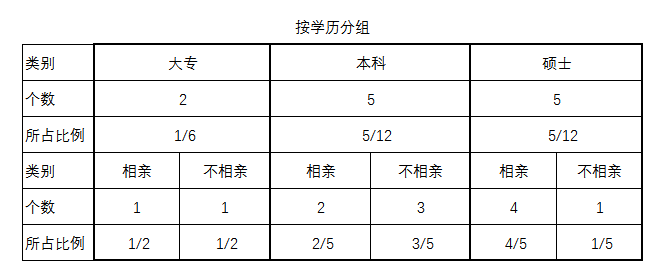
=大专项本科项硕士项
大专大专分割熵)本科本科分割熵硕士硕士分割熵
则以“学历”字段作为根的信息增益如下:
Gain(学历)=Info-Info(学历)=0.98-0.872=0.108bit
如果希望挑选到的是增益最大的那种方式,那么还需要试试其他字段是否有更大的信息增益。
总结:
信息熵,是用来描述信息混乱程度或者说确定程度的一个值。熵越大说明信息混乱程度越高,做切割时越复杂,要切割若干次才能完成;熵越小说明信息混乱程度越低,做切割时越容易,切割次数也就越少。