基于协同过滤的推荐引擎(理论部分)
时隔十日,终于决心把它写出来。大多数实验都是3.29日做的,结合3.29日写的日记完成了这篇实战。
数据集准备
数据集使用上篇提到的Movielens电影评分数据里的ml-latest-small数据集,下载完成后有下面四个csv文件。
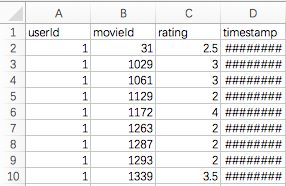
我们这里只需要ratings.csv就够了,打开以后会发现长这样:
是的,它果然和数据库里的没两样,上篇我们介绍的一般评分估计也好,神奇的SVD评分估计也好,前提都是有一个长成下面这样的物品-用户矩阵
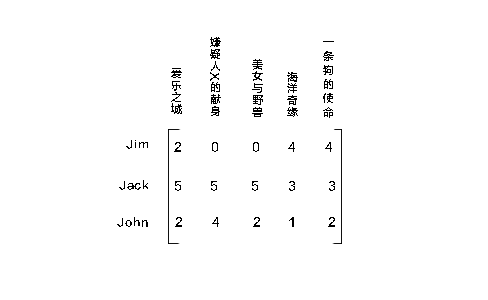
然后提出其中的两列,传给评分估计函数,但是真实的数据都长ratings.csv那样,果然童话里都是骗人的,在实际问题里,数据就是第一个拦路虎,难道要构建上述矩阵?这个代价好高,对python不熟悉是硬伤,100004条数据,根本经不起遍历,随便遍历一下算法复杂度就上来了,即使组好了矩阵,也稀疏可怕,一下子打乱了我先用一般评分估计函数做推荐,再用SVD评分估计函数做推荐,然后对比的计划T.T,没有矩阵,就用不上SVD的优势,真的,童话里都是骗人的……不过没关系,办法总比困难多。
数据处理
数据读取
先把数据读到内存中来,看看规模等等。
import pandas as pd
in_file = '/Users/liukaixin/MachineLearning/dataset/ml-latest-small/ratings.csv'
full_data = pd.read_csv(in_file)
print(full_data.head()) # 打表的前五行
print(len(full_data)) # 看看数据总条数

添加预测列
我们总要找一个算法评价标准,不研究那么深入,就简单化为看预测的评分跟真实评分差多少好了。那么首先要做的处理就是添加一列预测列,这一列里我们将rating列复制出一列,叫predict_rating,部分rating置零,当作要预测的评分,我们的程序就计算为零的rating,然后对比predict_rating和rating的差距。
这是又一个拦路虎,自认为比较理想的是每个都有1/3的predict_rating是0,用来做预测,想到下面个plan:
- excel复制rating,粘贴,重命名为predict_rating,看数据发现相同userId都在一起,所以挑着每个userId的数据1/3置0。
一开始我真的这样做了,复制粘贴重命名很快,置0是个问题,我傻乎乎置到第200条的时候发现我忘了一共有十万条数据,鼠标滚珠换坏了估计都置不完,笨办法果然不行,还得用程序。 - 遍历十万条数据,读的时候记录userId,同时累加计数器,userId改变的时候,计数器的数量除以3取整,得到要置零的数量,然后再把这个userId的1/3置零。
这是我第二个想到的方法,但是一算,第一层for循环100004条,第二个for循环取决于当前userId的数量,好像有670多个用户,一人不低于20条数据,这个O(n^2)的算法效率极低,如果取1/3置零是随机的,再加一个随机数产生,速度可想而知(我试过,4s多),不可取。 - 找出所有userId变化的点的下标,再遍历这些点,直接将两个下标之间的1/3数据置零。
绞尽脑汁想出这样一个办法,变化点的数量肯定远小于十万,经测试670个变化点,第一层for循环670,第二层for循环有两个变化点之间的数据乘以1/3次,效率明显提高。开始我测试了一下两个变化点之间的数据随机1/3置0,发现很慢很慢,于是退而求其次,不要随机数了,就前1/3置0吧。
import time
real_rating = full_data['rating'] # 原rating
predict_rating = np.array(full_data['rating']) # 复制的要1/3置零的rating
# 获得userId改变点的下标函数
def get_change_index_points(full_dataframe, key):
return np.array(full_dataframe.drop_duplicates([key]).index)
start = time.clock()
points = get_change_index_points(full_data, 'userId')
end = time.clock()
print "run time: %f s" % (end - start)
print(len(points))

full_dataframe.drop_duplicates([key])函数的意思是根据key去重,这个算法是dataframe优化过的,速度很快,得到的还是dataframe,只要取index,转成array就是我们想要的了。接下来写1/3置零的函数。
# 预测列置0,zero_percent是前百分之多少置0
def change_predict_data(predict_data, zero_percent):
last = 0
for i in points:
num = int((i-last) * zero_percent)
for j in range(0, num):
predict_data[last + j] = 0
last = i
return predict_data
import time
start = time.clock()
predict_rating = change_predict_data(predict_rating, 0.3)
end = time.clock()
print "run time: %f s" % (end - start) # run time: 0.031788 s
full_data.insert(4,'predict_rating',predict_rating)
print(full_data[:20])
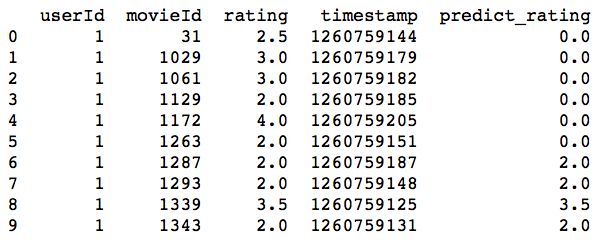
到这里,数据终于准备完了。
获得要比较的两个列向量
构建不了矩阵,就不构建了,想想评分估计函数的原理,不就是两个rating的列向量么,两个列向量的行对应的是同一个电影,上篇中用了很复杂的逻辑取出矩阵中都不为零的两列,我们也要保证两列中rating都没有0,也就是只取两个人都看过的电影的评分。用pandas从csv读出来是个DataFrame,可以很方便索引,和sql似的,尽管数据量大,但是它做了优化,效率肯定比自己写个for高。
获得要比较的两个列向量的思路是:从原DataFrame中根据要预测评分的电影的movie id查出所有数据,再遍历每一条数据,如果rating是0则跳过,否则看看该rating是哪个用户打得分,看看这个用户有没有也给我们要对照的那个电影打过分,如果有就同时把这两个rating分别加入预测列的rating和对照列的rating中,没有就两个都不加入,这样就实现了和“取出电影-用户矩阵中都不为零的两列”同样的效果。
# full_data:原DataFrame
# mov_id:要预测的movie id
# ref_mov_id:对照的movie id
# 返回值colA是要预测的列的rating,colB是对照列的rating,由于评分预测接受的传值是矩阵的列向量,所以转成矩阵
def get_colA_and_colB(full_data, mov_id, ref_mov_id):
colA = []
colB = []
movies = full_data[full_data['movieId'] == mov_id] # 相当于sql查询movie id是mov_id的所有数据,所以得到的是一个DataFrame
for i, movie in movies.iterrows(): # 遍历要预测的电影
if movie['predict_rating'] == 0.0: # 去掉没打分的电影
continue
user_id = movie['userId'] # 找打过分的记录,看是谁打的分
comp_user_movies = full_data[full_data['userId'] == user_id] # 找到打过分的用户的所有电影
rating = []
for i, mov in comp_user_movies.iterrows(): # 遍历电影,看他是否也看过要预测的电影,如果看过,则把打分加入colB
if mov['movieId'] == ref_mov_id:
rating.append(mov['predict_rating'])
if len(rating) == 0:
continue
else:
colA.append([movie['predict_rating']])
colB.append(rating)
return np.mat(colA), np.mat(colB)
计算预测评分
拿到两个列向量后,开始根据计算两个列向量的相似度预测用户对没看过的电影的打分,如果有点懵请看上篇。相似度计算有欧氏距离、皮尔逊系数和余弦距离三种,代码如下:
# 欧氏距离
def eulid_sim(colA, colB):
return 1.0 / (1.0 + np.linalg.norm(colA - colB))
# 皮尔逊系数
def pears_sim(colA, colB):
if len(colA) < 3:
return 1.0
return 0.5 + 0.5 * np.corrcoef(colA, colB, rowvar = 0)[0][1]
# 余弦相似度
def cos_sim(colA, colB):
if (colA.shape==(1,0)):
return 0
num = float(colA.T * colB) # colA和colB都是列向量,shape一样,都形如[[1],[2],[3],[4]],两个shape一样不能相乘,需要将其中一个转为行向量
denom = np.linalg.norm(colA) * np.linalg.norm(colB)
return 0.5 + 0.5 * (num / denom)
编写预测评分函数,预测评分的思路上篇也有介绍,大概就是加入用户已经看了电影A、B、C、D,打的分分别是a、b、c、d,要推荐电影E,则选择一个相似度计算公式,计算AE、BE、CE、DE的相似度,记为a%,b%,c%,d%,则对电影E的预测评分为电影ABCD的加权平均数,权是相似度。
# full_datas:原数据DataFrame
# user_id:要推荐的用户id
# movie_to_pre_id:要预测评分的电影id
# est:选择的相似度计算函数
def calculate_score(full_datas, user_id, movie_to_pre_id, est):
user_movies = full_datas[full_datas['userId'] == user_id]
sim_total = 0.0
rat_sim_total = 0.0
for i, movie in user_movies.iterrows():
if movie['predict_rating'] == 0.0:
continue
movie_id = movie['movieId']
colA, colB = get_colA_and_colB(full_data, movie_to_pre_id, movie_id)
similarity = est(colA, colB)
# print('the %d and %d similarity is %f' % (movie_to_pre_id, movie_id, similarity))
sim_total += similarity
rat_sim_total += similarity * movie['predict_rating']
return rat_sim_total / sim_total
print('eulid_sim = %f' % calculate_score(full_data, 12, 1028, eulid_sim))
print('pearson_sim = %f' % calculate_score(full_data, 12, 1028, pears_sim))
print('cos_sim = %f' % calculate_score(full_data, 12, 1028, cos_sim))

余弦相似度是nan,可能中间计算出了什么问题,现在还不确定,有可能是那两个colA和colB都是空,需要加这方面的判断吧。其他两个得到的评分预测还可以。
推荐
def new_recommend(full_datas, user_id):
user_movies = full_datas[full_datas['userId'] == user_id]
score_df = pd.DataFrame(columns=['movieId','predict_rating', 'real_rating'])
score = []
movid = []
rel_rat = []
for i, data in user_movies.iterrows():
if data['predict_rating'] == 0:
score.append(calculate_score(full_datas, user_id, data['movieId'], eulid_sim))
movid.append(data['movieId'])
rel_rat.append(data['rating'])
# score.sort()
score_df['movieId'] = movid
score_df['predict_rating'] = score
score_df['real_rating'] = rel_rat
return score_df.sort_values(by='predict_rating',ascending=False)
print(new_recommend(full_data, 1)) # 看第一个用户的预测评分
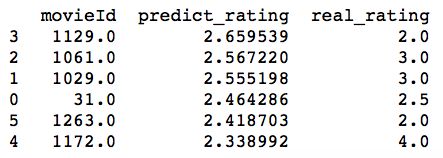
取前N个movieId进行推荐就好,可以把N作为传入参数。
准确的部分就是统计了,这里就不赘述了,其实可以看出欧氏距离不是很准,想做好一个推荐系统还需要做更细致的分析,此外,出了准确率的考虑,还有大数据量的问题,真实的数据总不像实验室里的,又小又规范,总有各种异常数据,上面的处理方式可能很蹩脚,有更好的方式感谢指点。
终于终于写完了:-):-):-):-):-)