初衷
当我们需要下载一个软件,我们一般会怎么做呢?
1.打开搜索引擎
2.输入软件的名称
3.查看搜索结果
4.找到官方网站
5.下载
但是
如果我们需要下载的软件并不是像QQ/迅雷/暴风影音那么知名,被搜索引擎收录
如果它是由个人开发而且根本就没有官方网站呢
我们是不是就会想到到一些大的软件下载网站去查询
比如说:
1. ZOL下载
2. 华军软件园
3. 绿色软件联盟
......
但是,不知道大家有没有遇到过这样的情况
当我们兴冲冲地进入一个软件的下载页面以后...

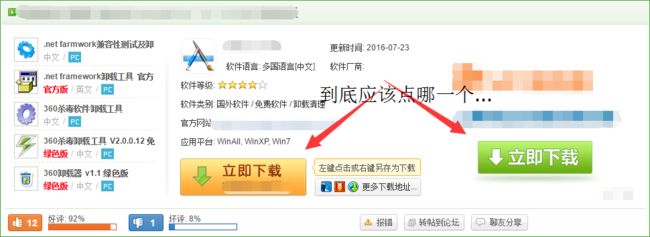
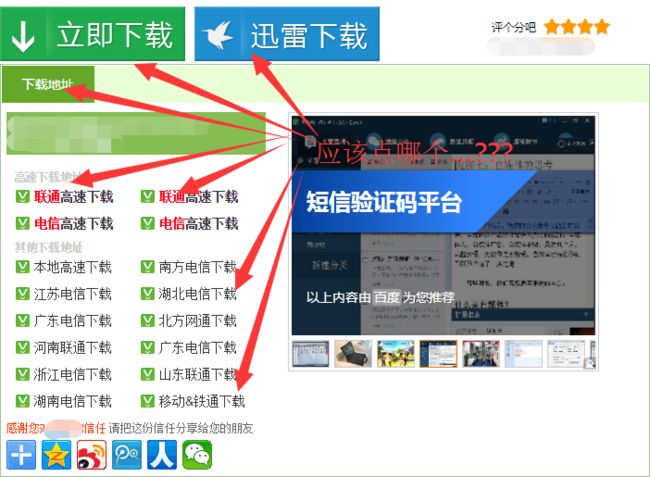
每当遇到这些不知道是广告还是病毒的垃圾链接,总是会点错
而且这些链接的样子都和我们软件真正的下载链接超级类似
稍微不小心就会点错
而且点错的后果一般都很严重,你的电脑就会被莫名其妙安装上各种各样乱七八糟的的软件,而且还超级难卸载
对于和我一样的对电脑有超级洁癖的小伙伴儿们来说
这怎么能忍...
一旦卸载不了...我一般就只好采取最暴力的手段---重装系统
然后又超级苦逼地重装一遍软件
再配置一遍开发环境...
所以如果能有一个小工具能帮我们迅速地定位软件的下载地址就太好了
这也是这个小工具产生的原因
非常欢迎大家一起来完善这个小工具帮助它成长,让它能够帮助到更多的人,希望产品能够更加注重用户体验
基本信息与下载地址
简介 :
一款帮你避免在下载软件的时候误点击了错误的下载地址而被动下载了一些乱七八糟的软件的工具,可以帮你迅速地定位网页中真正的软件的下载地址.非常欢迎大家一起来完善这个小工具帮助它成长,让它能够帮助到更多的人,希望产品能够更加注重用户体验
Jar下载地址:
FindDownloadLinks1.0(2016/07/23)(该版本Bug众多,已被作者废弃)
FindDownloadLinks1.1(2016/07/24)(该版本Bug众多,已被作者废弃)
FindDownloadLinks1.2(2016/07/24)
FindDownloadLinks1.3(2016/07/25)
FindDownloadLinks1.4(2016/07/25)
FindDownloadLinks1.5(2016/07/25)
FindDownloadLinks1.6(2016/07/25)
FindDownloadLinks1.7(2016/07/25)
FindDownloadLinks1.8(2016/07/27)
使用方法:
1.下载源码编译运行
2.下载jar包,在命令行中输入:java -jar 包路径/包名
如:"java -jar e:/"
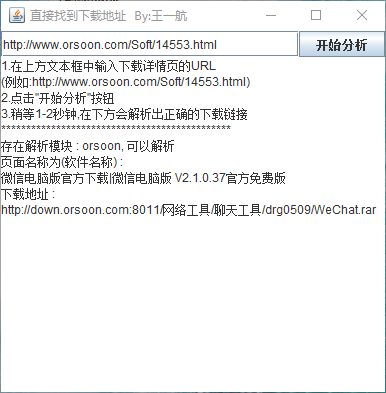
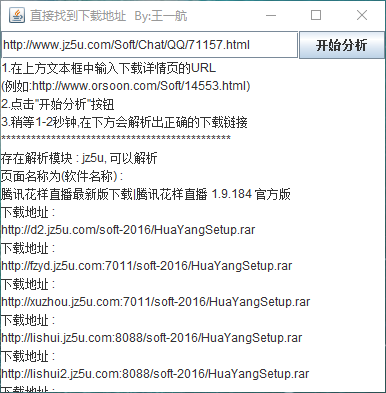
3.运行软件,输入软件站的下载详情页的URL
4.点击"开始分析"按钮
5.稍等一到两秒钟,可以看到正确的下载地址被软件成功解析
6.复制解析出的下载地址,使用下载工具进行下载
目前支持网站 :
1. JZ5U绿色下载站
2. 未来软件园
3. 非凡软件站
4. 华军软件园
5. 下载吧
6. 绿色下载站
7. 绿软家园
8. 太平洋软件下载中心
9. 多特软件站
10. 统一下载站
环境支持:
需要安装JRE(即java运行环境)
软件截图:
更新日志 :
- 2016/07/23(1.0版)
- 完成软件基本架构,具有可扩展性
- 添加对未来软件园和JZ5U绿色下载站的支持
- 2016/07/24(1.1版)
- 修复日志信息过长不能显示的BUG
- 添加对非凡软件站的支持
- 解决不同站点编码不同造成的乱码问题
- 添加对华军软件园的支持
- 2016/07/24(1.2版)
- 修复前两个版本打包失败无法使用的问题
- 完全修复所有支持网站的编码问题
- 精简jar包体积,从3M多减少到300k左右
- 2016/07/25(1.3版)
- 添加对下载吧的支持
- 优化程序结构(switch语句)
- 使用BASE64方式对下载链接进行解密
- 2016/07/25(1.4版)
- 添加对绿色下载站的支持
- 2016/07/25(1.5版)
- 添加对绿软家园的支持
- 2016/07/25(1.6版)
- 修复onlinedown模块对URL的处理中的BUG
- 添加对太平洋软件下载中心的支持
- 2016/07/25(1.7版)
- 修复由于获取软件名失败而导致无法正常解析下载链接的BUG
- 添加对多特软件站的支持
- 2016/07/27(1.8版)
- 添加对统一下载站的支持
- 修复URL格式不正确时没有提示信息的BUG
贡献者名单(特别感谢)
王一航 (http://www.wangyihang.space)
原理/工作流程与源码:
利用同一个站点不同软件下载页的结构类似
只需要根据一部分页面的结构提取出规律
理论上来说
就可以对该网站所有下载页面进行解析
并提取相关的软件信息
工作流程:
1.用户输入URL,点击"开始分析"按钮
2.软件根据用户输入的URL分析这个URL来自哪个软件站
3.如果软件不具有解析这个软件站的能力,则提示用户"暂不支持该网站!"
4.如果软件具有解析该网站的能力,则开始进入解析阶段
5.在解析阶段中,首先将页面的内容下载至本地
6.然后对HTML代码进行分析(一般来说同一个站点的页面的规格类似,可以使用相同的解析规则来提取真正的下载链接)
7.同时分析HTML代码提取软件名称
8.全部信息提取完成后,进行信息的显示
代码:
Github地址
1.Main.java
import javax.swing.*;
/**
* 主入口
* Created by 王一航 on 2016/7/23.
*/
public class Main extends JFrame{
/**
* 主入口
* @param args
*/
public static void main(String[] args) {
new MyFrame();
}
}
2.MyFrame.java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import javax.swing.*;
import java.awt.*;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
/**
* 主界面
* Created by 王一航 on 2016/7/23.
*/
public class MyFrame extends JFrame{
//全局变量
static java.util.List resultDownloadLionks;
static String softwareName;
//声明控件
JTextField jTextField_url;
JButton jButton_start;
JPanel jPanel_title;
//需要在外部更新日志
//TODO 考虑这种形式的合理性
static JTextArea jTextArea_result;
JScrollPane jScrollPane_result;
JPanel jPanel_result;
/**
* 构造方法
*/
public MyFrame(){
initView();
setView();
addView();
initEvent();
}
/**
* 实例化控件
*/
private void initView() {
jTextField_url = new JTextField("请输入URL");
jButton_start = new JButton("开始分析");
jPanel_title = new JPanel();
jTextArea_result = new JTextArea();
jScrollPane_result = new JScrollPane(jTextArea_result);
jPanel_result = new JPanel();
}
/**
* 设置控件属性
*/
private void setView() {
jTextArea_result.setText("1.在上方文本框中输入下载详情页的URL\n" +
"(例如:http://www.orsoon.com/Soft/14553.html)\n" +
"2.点击\"开始分析\"按钮\n" +
"3.稍等1-2秒钟,在下方会解析出正确的下载链接\n");
jPanel_title.setLayout(new BorderLayout());
jPanel_result.setLayout(new BorderLayout());
this.setTitle("直接找到下载地址 By:王一航");
this.setLayout(new BorderLayout());
this.setSize(400,400);
this.setVisible(true);
this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
}
/**
* 添加控件从属关系
*/
private void addView() {
jPanel_title.add(jTextField_url,BorderLayout.CENTER);
jPanel_title.add(jButton_start,BorderLayout.EAST);
jPanel_result.add(jScrollPane_result);
this.add(jPanel_title,BorderLayout.NORTH);
this.add(jPanel_result,BorderLayout.CENTER);
}
/**
* 添加监听事件
* 调度程序(核心)
*/
private void initEvent() {
jButton_start.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
//打印分隔符
jTextArea_result.append("**********************************************\n");
//TODO 业务逻辑
String url = jTextField_url.getText();
String module = "";//解析规则模式
String content = "";//待解析的解析网页内容
module = Utils.URLParser(url);
url = Utils.URLHandler(module,url);
if (!(module.equals(""))){//存在解析模块可以解析
//日志
jTextArea_result.append("存在解析模块 : " + module + ", 可以解析\n");
content = Utils.getContentAsString(url, module);
Document document = Jsoup.parse(content);
softwareName = Utils.getSoftwareName(module, document);
resultDownloadLionks = Utils.getDownloadLinks(module,document);
//日志
jTextArea_result.append("页面名称为(软件名称) : \n" + softwareName + "\n");
for (String res: resultDownloadLionks
) {
//日志
jTextArea_result.append("下载地址 : \n" + res + "\n");
}
}else{
//TODO 给用户提示暂不支持此网站
//日志
jTextArea_result.append("暂不支持该网站!\n");
}
}
});
}
}
3.Utils.java
import org.json.JSONArray;
import org.json.JSONObject;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import sun.misc.BASE64Decoder;
import sun.misc.BASE64Encoder;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
/**
* 工具类:
* Created by 王一航 on 2016/7/23.
*/
public class Utils {
/**
* URL解析器(解析URL并分发给对应的模块进行处理)
* @param url
* @return
*/
public static String URLParser(String url){
String modules = "";
if (url.contains("www.jz5u.com")){//jz5u绿色下载
modules = "jz5u";
}else if (url.contains("www.orsoon.com")){//未来软件园
modules = "orsoon";
}else if (url.contains("www.crsky.com")){//非凡软件站
modules = "crsky";
}else if (url.contains("www.onlinedown.net")){//华军软件园
modules = "onlinedown";
}else if (url.contains("www.xiazaiba.com")){//下载吧
modules = "xiazaiba";
}else if (url.contains("www.greenxiazai.com")){//绿色下载站
modules = "greenxiazai";
}else if (url.contains("www.downg.com")){//绿软家园
modules = "downg";
}else if (url.contains("dl.pconline.com.cn")){//太平洋电脑网
modules = "pconline";
}else if (url.contains("www.duote.com")){//多特软件站
modules = "duote";
}else if(url.contains("www.3987.com")){//统一下载站
modules = "3987";
}else {
modules = "";
}
return modules;
}
/**
* 获取给定URL网页内容
* @param url
* @return
*/
public static String getContentAsString(String url, String modules){
//保存结果
String temp = "";
String content = "";
try {
//判断URL是否正确
URL myUrl = new URL(url);
URLConnection urlConnection = myUrl.openConnection();
InputStream inputStream = urlConnection.getInputStream();
InputStreamReader inputStreamReader = null;
//TODO 解决不同网站编码不同造成的乱码问题
switch (modules){
case "jz5u":
case "xiazaiba":
case "crsky":
case "greenxiazai":
case "downg":
case "pconline":
case "duote":
inputStreamReader = new InputStreamReader(inputStream,"GBK");
break;
case "orsoon":
case "onlinedown":
case "3987":
inputStreamReader = new InputStreamReader(inputStream,"UTF-8");
break;
default:
//TODO 因为之前已经对modules进行了筛选,理论上来说,是不会进入Default的
break;
}
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
while((temp =bufferedReader.readLine()) != null){
content = content + temp;
}
bufferedReader.close();
inputStreamReader.close();
inputStream.close();
} catch (MalformedURLException e) {
MyFrame.jTextArea_result.append("输入URL非法!请检查是否以\"http://\"开头");
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//返回
return content;
}
/**
* 获得页面中所有的下载链接
* @param document
* @param modules
* @return 下载地址集合
*/
public static List getDownloadLinks(String modules, Document document){
List downloadLinks = new ArrayList<>();
switch (modules){
case "jz5u"://jz5u绿色下载
//选出真正DIV
Elements element_div = document.getElementsByClass("co_content5");
if (element_div.isEmpty()){//没有获取到下载地址
//TODO 将来给用户提示
System.out.println("输入网址有误,请您检查是否输入地址是否是软件的详情页");
}else{//成功解析到下载地址
Element element = element_div.get(0);
Elements a = element.getElementsByTag("a");
for (Element e: a) {
if (!(e.text().contains("高速")) && (e.text().contains("本地"))){
downloadLinks.add(e.attr("href"));
}
}
}
break;
case "orsoon"://未来软件园
Element element_pc = document.getElementById("x_downfile");
String content = element_pc.toString();
int start_orsoon = content.indexOf("push('");
int end = content.indexOf("');");
String result = content.substring(start_orsoon + 6, end);
//TODO 完成安卓客户端/苹果客户端
downloadLinks.add(result);
break;
case "crsky"://非凡软件园
Elements elements_crsky = document.getElementsByAttribute("itemprop");
for (Element e: elements_crsky
) {
if (e.attr("itemprop").equals("downloadUrl")){
downloadLinks.add(e.attr("href"));
}
}
break;
case "onlinedown"://华军软件园
//刚好这个script标签在下载链接之前
Elements element_js_before = document.getElementsByAttributeValue("src", "http://d.onlinedown.net/php/ajax_ip_1.2.php");
Element onlinedown_true = element_js_before.get(0).nextElementSibling();
String onlinedown_true_links = onlinedown_true.toString();
int json_onlinedown_start = onlinedown_true_links.indexOf("var durl = ");
int json_onlinedown_end = onlinedown_true_links.indexOf("]");
String json_onlinedown = onlinedown_true_links.substring(json_onlinedown_start + 11,json_onlinedown_end + 1);
//解析json对象
JSONArray jsonArray = new JSONArray(json_onlinedown);
for(int i = 0; i < jsonArray.length(); i++){
JSONObject jsonObject = jsonArray.getJSONObject(i);
//TODO 分开下载链接和服务器地址信息
//TODO 加入javabean
downloadLinks.add(jsonObject.getString("url") + " 服务器地址 : " + jsonObject.getString("name"));
}
break;
case "xiazaiba":
String content_xiazaiba = document.toString();
int start_xiazaiba = content_xiazaiba.indexOf("downlist(");
int end_xiazaiba = content_xiazaiba.indexOf("','");
String temp_xiazaiba = content_xiazaiba.substring(start_xiazaiba, end_xiazaiba);
int temp_start_xiazaiba = temp_xiazaiba.indexOf("\",TypeID:\"");
int temp_end_xiazaiba = temp_xiazaiba.length();
String half_xiazaiba = temp_xiazaiba.substring(temp_start_xiazaiba + 2, temp_end_xiazaiba);
String full_xiazaiba = "http://xiazai.xiazaiba.com" + half_xiazaiba;
downloadLinks.add(full_xiazaiba);
break;
case "greenxiazai":
Elements elements_greenxiazai = document.getElementsByAttributeValue("onclick", "SetHome();");
for (Element e: elements_greenxiazai
) {
downloadLinks.add(e.attr("href"));
}
break;
case "downg":
Elements elements_downg = document.getElementsByClass("download-list");
Elements elements_downg_a = elements_downg.get(0).getElementsByTag("a");
for (Element e: elements_downg_a
) {
downloadLinks.add(e.attr("href"));
}
break;
case "pconline":
Elements elements_pconline = document.getElementsByAttribute("tempUrl");
for (Element e:elements_pconline
) {
if (e.attr("class").equals("link-a")){//屏蔽高速下载,只留下本地下载
downloadLinks.add(e.attr("tempUrl"));
}
}
break;
case "duote":
//TODO 添加对该网站手机模块的支持(暂时只支持PC软件网页处理)
String content_duote = document.toString();
int start_duote = content_duote.indexOf("var sPubdown = '");
int ent_duote = content_duote.indexOf("var serUrl = '';");
String half_duote = content_duote.substring(start_duote + 16, ent_duote - 2);
downloadLinks.add(half_duote);
break;
case "3987":
Elements elements_3987 = document.getElementsByClass("dl-ico");
for (Element e: elements_3987
) {
Element element_3987 = e.nextElementSibling();
downloadLinks.add(element_3987.attr("href"));
}
break;
default:
break;
}
return downloadLinks;
}
/**
* 获取软件名称
* @param modules
* @param document
* @return
*/
public static String getSoftwareName(String modules,Document document) {
String softwareName = "";
Elements title = document.getElementsByTag("title");
Element tile_element = title.get(0);
String title_string = tile_element.text();;
switch (modules){
case "jz5u":
if (title_string.contains("-")){
softwareName = title_string.split("-")[0];
}
break;
case "orsoon":
if (title_string.contains(" - ")){
softwareName = title_string.split(" - ")[0];
}
break;
case "crsky":
if (title_string.contains("下载_")){
softwareName = title_string.split("下载_")[0];
}
break;
case "onlinedown":
if (title_string.contains(" - ")){
softwareName = title_string.split(" - ")[0];
}
break;
case "xiazaiba":
case "greenxiazai":
String temp1_greenxiazai = title_string;
String temp2_greenxiazai = title_string;
if (title_string.contains("-")){
temp1_greenxiazai = title_string.split("-")[0];
}
if (title_string.contains("\\|")){
temp2_greenxiazai = temp1_greenxiazai.split("\\|")[1];//注 : '|'的转义字符是'\\|'
}
softwareName = temp2_greenxiazai;
break;
case "downg":
//TODO 抽取软件名
softwareName = title_string;
break;
case "pconline":
String temp1_pconline = title_string;
String temp2_pconline = title_string;
if (title_string.contains("\\【")){
temp1_pconline = title_string.split("\\【")[0];
}
if (title_string.contains("_")){
temp2_pconline = temp1_pconline.split("_")[1];
}
softwareName = temp2_pconline;
break;
case "duote":
String temp1_duote = title_string;
String temp2_duote = title_string;
if (title_string.contains("\\】")){
temp1_duote = title_string.split("\\】")[1];
}
if (title_string.contains("_")){
temp2_duote = temp1_duote.split("_")[0];
}
softwareName = temp2_duote;
break;
case "3987":
String temp1_3987 = title_string;
String temp2_3987 = title_string;
if (title_string.contains("_")){
temp1_3987 = title_string.split("_")[0];
}
if (title_string.contains("\\|")){
temp2_3987 = temp1_3987.split("\\|")[1];//注 : '|'的转义字符是'\\|'
}
softwareName = temp2_3987;
break;
default:
softwareName = title_string;
break;
}
return softwareName;
}
/**
* URL处理(有的时候用户需要多次跳转才能到达真正的下载页面)
* 功能: 直接跳转到真正页面
* @return
*/
public static String URLHandler(String module, String url) {
switch (module){
case "jz5u":
if (url.contains("html")){//判断是否是真正的下载页面(如果包含了html,有可能需要再跳转一下)
String fileName = url.split("/")[url.split("/").length - 1];
int indexOfPoint = fileName.indexOf(".");
String fileNumber = fileName.substring(0, indexOfPoint);
url = "http://www.jz5u.com/Soft/softdown.asp?softid=" + fileNumber;
}
break;
case "onlinedown":
if (url.contains("htm") && (!url.contains("_"))) {//判断是否是真正的下载页面(如果包含了htm,有可能需要再跳转一下)
String fileName = url.split("/")[url.split("/").length - 1];
int indexOfPoint = fileName.indexOf(".");
String fileNumber = fileName.substring(0, indexOfPoint);
url = "http://www.onlinedown.net/softdown/" + fileNumber + "_2.htm";
}
break;
case "pconline":
if (url.contains("html") && (!url.contains("-"))) {
String filename = url.split("/")[url.split("/").length - 1];
String fileNumber = filename.split("\\.")[0];
url = "http://dl.pconline.com.cn/download/" + fileNumber + "-1.html";
}
break;
default:
break;
}
return url;
}
/**
* Unicode转中文
*/
public void unicodeToChinese(){
//TODO 完成编码转换(华军软件园)
}
/**
* base64加密
* @param content 明文
* @return 密文
*/
public static String myBASE64Encoder(String content){
String result;
BASE64Encoder base64Encoder = new BASE64Encoder();
result = base64Encoder.encodeBuffer(content.getBytes());
return result;
}
/**
* base64解密
* @param content 明文
* @return 密文
*/
public static String myBASE64Decoder(String content){
String result = "";
BASE64Decoder base64Decoder = new BASE64Decoder();
try {
byte[] bytes = base64Decoder.decodeBuffer(content);
result = new String(bytes, "UTF-8");
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
}
作者的话 :
最近会逐步更新,扩大支持的网站范围
希望可以在这里可以获得大家的喜欢和支持
一直认为用户体验是一个软件产品吸引用户的核心
(其实不仅仅是软件,任何一个产品都离不开与用户的交互)
但是许多的网站并不是特别地注重这些,可能不得已还会做一些降低用户效率的行为
但是这并不是最好的解决冲突的方法
希望可以呼吁更多的产品不要太注重眼前的利益
更注重用户体验才会吸引更多的用户
尤其是在一个行业中,许多产品的功能都类似的情况下
如何才能吸引用户,我觉得让用户在使用产品的过程中能不自觉的对产品产生依赖和感情
这很重要
这种依赖并不一定体现在用户的停留时间
比如说对于一个工具类的网站
用户来到这些网站的目的当然是最快地找到自己需要的信息然后离开
而真正关心用户体验的网站应该做的就是最迅速地检索到用户需要的信息或者是最迅速地帮助用户解决他的问题
然后让用户心满意足的离开
这才是这些网站的初衷
而不是为了增加广告的点击量来用一些类似下载链接的标签来迷惑用户
这是在欺骗上帝呀...
这只会让用户对产品的印象越来越差
黏着力会大大降低
刚才说的,如果这种类型的网站可以迅速地帮用户解决问题
从表面上看来,可能用户滞留的时间降低了
但是可能用户访问的频率会大大增加
用户得到了非常满意的服务,他就极有可能把产品介绍给身边的人
这样产品的用户量又会进一步增加
说了这么多
是真心希望可以有更多的产品可以站在用户的角度
考虑用户真正需要的是什么
用户来到软件下载站
最需要的当然是直接下载自己需要的软件然后迅速离开
如果网站可以制作成一个清爽的页面中只有一个下载的按钮
点击就可以直接下载
那么该有多美好
最后
希望大家可以一起完善这个小工具
帮助它慢慢成长
让它能帮助到更多的人
也希望大家可以喜欢
谢谢