对于程序员来说,技术进步大大超过世人的想象,如果你不跟随时代进步,就会落后于时代。
我其实已经听过很多人跟我说过类似的话。只不过不同人嘴里提到的词汇各有不同——大数据、数据挖掘、机器学习、人工智能…… 这些当前火热的概念各有不同,又有交叉,总之都是推动我们掌控好海量数据,并从中提取到有价值信息的技术。

自己建的大数据学习交流群:522189307,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。
程序员对这些技术跃跃欲试,「普通程序员如何向人工智能靠拢?」等问题都有很高的关注度。我们在招聘市场也能够看到,越来越多的技术候选人在跳槽时会思考,能否从事相关岗位的工作。
从 100offer 平台上的数据来看,大数据相关职位的面试邀请占比也与日俱增。
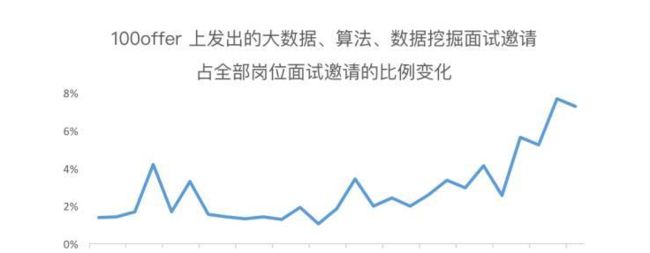
当前,很多候选人对大数据相关岗位的青睐并非偶然
处理器速度的加快,大规模数据处理技术的日渐成熟,让我们从 Big Data 中快速提取有价值的信息成为可能。几十年前神经网络算法被提出之初,捉襟见肘的计算能力很难让这个计算密集的算法发挥出它应有的作用。而现在,PB 级别的数据也可以在短时间内完成机器学习的模型训练。这让格灵深瞳、科大讯飞等高度依赖深度学习的图像、语音识别公司得以对产品进行快速迭代。
互联网行业的快速发展,让不少公司拥有了成千上万的用户数据,各家都想挖掘这座储量丰富的金矿,由此延伸出数据在自家业务不同应用场景中的巨大价值——京东、淘宝等电商网站利用用户画像做个性化推荐,PayPal、宜信等互联网金融公司通过识别高危行为的特征实施风险控制,滴滴、达达等出行、配送业务利用交易数据进行实时定价从而使利润最大化……
还有一些公司,借助大数据相关技术创造出新的业务模式——比如利用算法做个性化内容推荐的今日头条、一点资讯,比如通过监测服务整合海量数据、做数据价值变现的 TalkingData,当然还有一些底层架构的支持服务商如阿里云、UCloud 也开通了托管集群、机器学习平台等服务。
这些企业整体对大数据、数据挖掘相关人才的需求非常之大,导致行业内人才的供给相对不足。因而薪资通常也相对高一些。
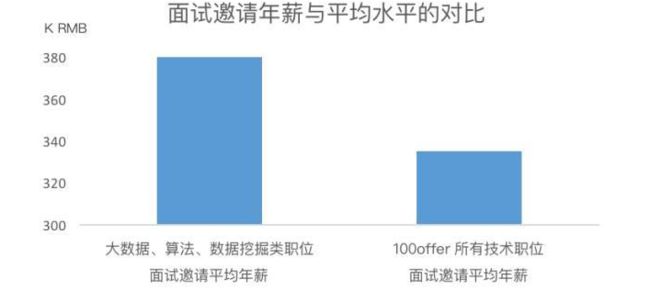
再加上这些岗位相比于传统的软件工程,有更高的挑战空间和更大的难度,自然引得更多人才进入到这个领域。
最近,为了了解大数据相关工程师的招聘现状,我们走访了几家紧需大数据相关人才的公司,与他们的技术 Leader 聊了聊相关人才的招聘现状。
对于工程师来说,可以考虑的大数据相关岗位有哪些?
从各家招聘的工程师来看,与大数据打交道的核心工程师通常分为这么两大类
大数据平台/开发工程师
他们的工作重心在于数据的收集、存储、管理与处理。
通常比较偏底层基础架构的开发和维护,需要这些工程师对 Hadoop/Spark 生态有比较清晰的认识,懂分布式集群的开发和维护。熟悉 NoSQL,了解 ETL,了解数据仓库的构建,还可能接触机器学习平台等平台搭建。
有些大数据开发工程师做的工作可能也会偏重于应用层,将算法工程师训练好的模型在逻辑应用层进行实现,不过有些公司会将此类工程师归入软件开发团队而非大数据团队。
算法&数据挖掘工程师
此类工程师的工作重心在于数据的价值挖掘。
他们通常利用算法、机器学习等手段,从海量数据中挖掘出有价值的信息,或者解决业务上的问题。虽然技能构成类似,但是在不同团队中,因为面对的业务场景不同,对算法 & 数据挖掘工程师需要的技能有不同侧重点。因而这个类目下还可细分为两个子类:
算法工程师
这类团队面对的问题通常是明确而又有更高难度的,比如人脸识别、比如在线支付的风险拦截。这些问题经过了清晰的定义和高度的抽象,本身又存在足够的难度,需要工程师在所研究的问题上有足够的专注力,对相关的算法有足够深度的了解,才能够把模型调到极致,进而解决问题。这类工程师的 Title 一般是「算法工程师」。
数据挖掘工程师
有的团队面对的挑战不限于某一个具体问题,而在于如何将复杂的业务逻辑转化为算法、模型问题,从而利用海量数据解决这个问题。这类问题不需要工程师在算法上探索得足够深入,但是需要足够的广度和交叉技能。他们需要了解常见的机器学习算法,并知晓各种算法的利弊。同时他们也要有迅速理解业务的能力,知晓数据的来源、去向和处理的过程,并对数据有高度的敏感性。这类工程师的 Title 以「数据挖掘工程师」居多。
从技术 Leader 对人才的要求看,转岗机会在哪里?
没有一个技术 Leader 不希望自己手下是一班虎将。他们期盼团队中每个工程师都是能独当一面的全才。
基础的逻辑、英文等素质是必须的,聪明、学习能力强是未来成长空间的保障,计算机基础需要扎实,最好做过大规模集群的开发和调优,会数据处理,还熟悉聚类、分类、推荐、NLP、神经网络等各种常见算法,如果还实现过、优化过上层的数据应用就更好了……
嗯,以上就是技术 Leader 心中完美的大数据相关候选人形象。
但是,如果都以尽善尽美的标准进行招聘的话,恐怕没几个团队能够招到人。现在大数据、数据挖掘火起来本身就没几年,如果想招到一个有多年经验的全才,难度不是一般的高。在这点上,各位技术 Leader 都有清晰的认识。
不过,全才难招,并不代表 Leader 会放低招聘要求。他们绝不容忍整个团队的战斗力受到影响。面对招聘难题,他们会有一些对应的措施——
可以不求全才,但要求团队成员各有所长,整体可形成配合
刚刚提到了,要想为大数据相关岗位找到一个各方面条件都不错的人才,难度非常大。因而技术 Leader 会更加务实地去招聘「更适合的人」——针对不同岗位吸收具有不同特长的人才。
以格灵深瞳为例,这是一家计算机视觉领域的大数据公司,团队中既需要对算法进行过透彻研究的人才,把图像识别有关算法模型调整到极致,也需要工程实力比较强的人才,将训练好的算法模型在产品中进行高性能的实现,或者帮助团队搭建一整套视频图像数据采集、标注、机器学习、自动化测试、产品实现的平台。
对于前一种工程师,他需要在深度学习算法甚至于在计算视觉领域都有过深入的研究,编程能力可以稍弱一些;而对于后一种工程师,如果他拥有强悍的工程能力,即使没有在深度学习算法上进行过深入研究,也可以很快接手对应的工作。这两种人才需在工作中进行密切的配合,共同推动公司产品的产出与优化。
即使在算法工程师团队内部,不同成员之间的技能侧重点也可能各不相同。
比如个性化内容推荐资讯平台——一点资讯的算法团队中,一部分工程师会专注于核心算法问题的研究,对解决一个非常明确的问题(比如通过语义分析进行文章分类的问题,如何判断「标题党」的问题等等),他们需要有足够深度的了解;另外一部分工程师,则专注于算法模型在产品中的应用,他们应该对业务非常有 sense,具备强悍的分析能力,能够从复杂的业务问题中理出头绪,将业务问题抽象为算法问题,并利用合适的模型去解决。两者一个偏重于核心算法的研究,一个偏重业务分析与实现,工作中互为补充,共同优化个性化内容推荐的体验。
对于后者来说,因为对核心算法能力要求没有前者那么高,更重视代码能力与业务 sense,因而这个团队可以包容背景更丰富的人才,比如已经补充过算法知识的普通工程师,以及在研究生阶段对算法有一些了解的应届生。
雇主对大数据相关候选人的经验、背景有更大接受空间,这就给了非大数据相关候选人进入大数据、算法团队的机会。此时,梳理清楚自己现有技能对于新团队的价值非常重要,这是促使新团队决定吸收自己的关键。
现在在云计算服务商 UCloud 工作的宋翔,过去四五年一直致力于计算机底层系统的研究。在百度,他曾经为深度学习算法提供支持,用硬件和底层系统优化,加快机器学习算法的运算速度。进入 UCloud 之初,宋翔主要研究的方向也是如何利用 GPU 服务器进行运算加速。
后来,考虑到越来越多企业依赖机器学习进行数据挖掘,UCloud 期望推出一个兼容主流开源机器学习系统的 Paas,使得使用这个机器学习平台的工程师能够专注于模型训练本身,而无需考虑模型部署、系统性能、扩展性、计算资源等问题。
宋翔在底层系统优化上的特长刚好可以在这项工作中发挥,因而他立刻被赋予主导这个平台搭建的任务。
让算法在机器上运转得够快,才能够缩短模型迭代的时间,加速模型优化的过程。大部分算法工程师可能对此了解甚少,但是宋翔可以充分发挥自己的特长,利用硬件和底层系统加速机器学习算法。
当需要训练的数据量特别大的时候,比如几十 T 以上甚至 PB 级的时候,在分布式系统中, I/O 或者网络可能成为瓶颈了,这时需要系统工程师的介入,看怎么优化数据传输使得 I/O 的使用率提高;看怎么去存储,用 HDFS 还是用 Key Value Store 或者其他存储方式,可以让你更快地拿到数据去计算,或者你用磁盘的存储还是 SSD 存储 或者 in-memory 的存储。这其中,系统工程师也需要平衡成本和效率之间的关系。
系统工程师还可以帮助你设计一个系统,让算法工程师快速地提交任务,或者方便地同时训练多个模型,尝试多个参数。
系统工程师非常擅长把本来串行的工作拆分之后变成并行工作。比如可以把数据预处理和深度学习运算做一个并发,等等。
除了对底层系统有深入了解之外,他现在也在了解机器学习的算法。他带领的小团队中,除了有2名系统工程师之外,还有两名算法工程师,他一直鼓励两种工程师互相学习,共同提高,这样才能够让整个团队效率最大化。如果系统工程师对算法不了解的话,可能也不知道怎么去优化算法运行的效率;算法工程师也应大概了解不同模型在CPU、GPU机器上的运算速度,帮助自己设计出更高效的算法。
对于期望转岗为大数据相关的普通工程师来说,一旦通过自身擅长的技能切入新团队之后,就有了更多横向发展的机会,帮助自己在大数据相关领域建立更强竞争力。
相比于苛求当前技能水平,更看重扎实的基础和成长空间
无论何种工程师,雇主都希望人才具备综合素质,而非片面苛求当前的技能水平。特别是对于当前市场供给偏少的大数据相关领域,已经在大数据、算法方面有所建树的人才毕竟只占少数。具备不错的基础素养,并拥有巨大潜力的工程师也很受企业青睐。这些工程师可以利用已有的工程实力完成一部分基础工作,并在经过1-2年的锻炼之后,接手更复杂的问题。
我们可以把大数据相关工程师能力模型抽象为以下的核心技能金字塔
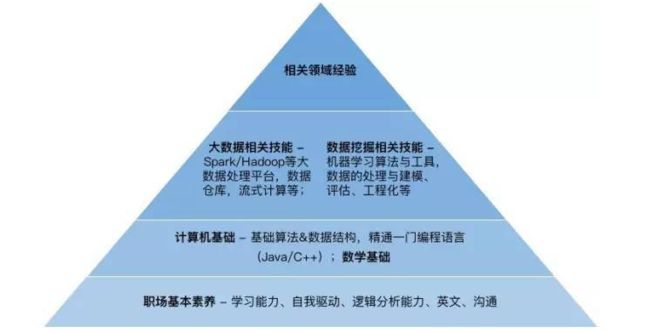
越是偏金字塔底部的素养,对于企业来说越是重要。最底部的基础素养,代表的是未来的成长空间。当前互联网高速发展,每家企业都是跑步前进,如果一个当前技能不错的工程师,未来成长空间有限,也可能变成企业的负担。
再上一层的计算机基础 - 基本的算法与数据结构,某一门编程语言的精通,是几乎每个工程师岗位都重视的能力。一个基础不扎实的程序员,可能会让企业怀疑其学习能力。扎实的基础,会为应用技能的学习扫除障碍,更容易建立深度的理解;而数学基础对于算法理解上的帮助十分重要。
这最下方的两层构成了一个工程师人才的基础素养。如果底层的基础比较扎实,掌握应用层技能所需要的时间也许比我们预想的要少一些。
格灵深瞳技术副总裁 - 邓亚峰提到:
对于计算机视觉领域算法工程师,我们当然希望招募无论在基础层面还是应用层面,技能都完备的候选人。
但是如果你算法、数据结构比较强,编程语言上对 C++ 比较理解,那你在应用层的学习上,可能会比其他人快很多。比如在深度学习上付出 1-2 年的时间,在图像 domain knowledge 上付出半年到一年就可以有基础的了解。
其实现在计算机视觉领域更加依靠深度学习之后,特征选取等依赖 domain knowledge 的门槛已经降下来了,因而我曾见到不少有很好基础的人,包括一些基础扎实的应届生,在图像领域工作了半年到一年之后就能拿到不错的成绩。
在看待大数据工程师的招聘上,TalkingData 的技术 VP 闫志涛和首席数据科学家张夏天也提到:
TalkingData 的大数据工程师工作中非常依赖 Spark 技能,但是了解 Spark 本身并没有那么难,因而候选人的 Spark 技能对我而言并不是最强吸引点。
相比于对 Spark 了解更多的人,我更愿意招收那些 Java 学得好的人。因为 Spark 的接口学习起来相对容易,但是要想精通 Java 是一件很难的事情。
如果你把 Java 或者 C++ 学透了,你对计算机技术的认识是不一样的。这其实是道和术的问题。
TalkingData 的 两位 Leader 也为我举了一个自家团队中的例子:
他们在14年招收了一位专科学校毕业的工程师,在上一家公司做过一点推荐算法,会写 Hadoop Mapreduce,但是并没有在大数据上有深入的研究。这位工程师当时的大数据技能并不能达到 TalkingData 的招聘标准,不过好在他思维清晰,看待问题有自己独特的想法。加之 Java 基础不错,在上一家公司做事情也很扎实,所以就招聘进来了。
说到这里,两位 Leader 坦言「当时幸好还不怎么挑简历,也许按照后来的标准未必能把这位工程师招聘进来。」
不曾想到,这位工程师主动性非常强,Leader 只需给到工作方向,他就会驱动自己学习相关知识,快速完成目标。2年以后,这位工程师的 Spark 能力已经锻炼得非常强悍,用 Leader 的话说「可以以一当十」;他对大数据、机器学习都有浓厚的兴趣,Spark 基础夯实之后,又转岗到了算法工程师团队,写出了 TalkingData 机器学习平台的核心代码,这个平台大大提高了团队的机器学习效率。
从上边的例子中,我们也可以额外收获一个信息,相比于跳槽转岗,内部转岗会更容易一些。因为在公司内部中,企业有充分的时间考察工程师的能力、潜力。企业对工程师的认可度提升之后,才会更加放心的予以新的挑战。
赵平是宜信技术研发中心的一位工程师,加入宜信之前,他曾帮助中国移动机顶盒业务的后端架构进行服务化转型。抱着对基础平台架构的浓厚兴趣,赵平加入了宜信。他在这家公司做的第一个项目是分布式存储系统的设计和开发。第一个项目完美收官之后,他的学习能力、基础能力备受褒奖。当宜信开始组建大数据平台团队时,赵平看到了自己理想的职业发展方向并提交了转岗申请,基于他过往的优异表现,顺利地拿到了这个工作机会。
转岗之后,赵平也遇到了一些挑战,比如大数据涉及的知识点、需要用到的工具更加丰富,Spark,Scala,HBase,MongoDB…,数不清的技能都需要边用边学,持续恶补;比如思维方式上,需要从原来的定时数据处理思维向 Spark 所代表的流式实时处理思维转变。不过基于他扎实的基础,以及之前做分布式存储系统经验的平滑过渡,加之整个团队中良好技术氛围的协助,最终顺利完成第一个大数据项目的开发工作。
对希望转做大数据相关工作的普通工程师,一些中肯的建议
在文章的末尾,我们基于文章中提到的多个案例,总结一下帮助普通工程师走向大数据相关岗位的几个 tips 吧:
重视基础。无论各种岗位,基础是成长的基石。
发挥专长。从能够发挥自己现有专长的岗位做起,可以让新团队更欢迎你的加入。比如算法模型的工程化,偏重于业务的数据挖掘,大数据平台开发,机器学习系统开发等等,这些工作对于普通工程师更容易上手。而普通工程师直接转偏研究方向的算法工程师,难度更高。
准备充分。请预先做好相关知识的学习,有动手实践更佳。如果没有一点准备,雇主如何相信你对这个领域真的有兴趣呢?
考虑同公司转岗。在同公司转岗阻力更小。亦可考虑加入一家重视大数据的公司,再转岗。
最后,如果你确实对大数据、数据挖掘有浓厚兴趣,最好的办法是立刻开始实践。也许你不会以此为职业,但是可以多一技傍身。
也许,未来这些技能对于程序员而言,就好比现在 MS Office 对于职场人一样普遍。
自己建的大数据学习交流群:522189307,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。