0.1 广度优先遍历
0.1.1 定义
广度优先遍历是连通图的一种遍历策略。因为它的思想是从一个顶点V0开始,辐射状地优先遍历其周围相邻的的区域。(处理最短路径问题)
0.1.1 代码实现方式
for循环或while循环实现,并利用队列数据结构存储上一层遍历的结果
0.2 深度优先遍历的定义
0.2.1 定义及思路
首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点;当没有未访问过的顶点时,则回到上一个顶点,继续试探访问别的顶点,直到所有的顶点都被访问。(处理最长路径问题)
0.2.2 代码实现方式
递归函数实现,利用编译器调用的stack数据结构存储每一次递归的数据,返回时就能找到递归之前的变量状态
0.3 看别人写的代码的快速方法
如果不太好理解别人写的代码,则最好拿例子一步一步地跟着代码走,这样就知道代码的每一步做了什么事情了
1. Surrounded Regions
题目描述
给定一个包含'X'和'O'(字母 O)的2D矩阵,检索所有被包围的区域'X'。
通过在所围绕的区域中将所有'O's 翻转成'X's 来捕获区域。
例如,矩阵形式如下:
XXXX
XOOX
XXOX
XOXX
运行你的函数后,该矩阵应该是:
XXXX
XXXX
XXXX
XOXX
代码实现(广度优先遍历)
public class Solution {
public void solve(char[][] board) {
if (board.length == 0) return;
int rowN = board.length;
int colN = board[0].length;
Queue queue = new LinkedList();
//get all 'O's on the edge first
for (int r = 0; r< rowN; r++){
if (board[r][0] == 'O') {
board[r][0] = '+';
queue.add(new Point(r, 0));
}
if (board[r][colN-1] == 'O') {
board[r][colN-1] = '+';
queue.add(new Point(r, colN-1));
}
}
for (int c = 0; c< colN; c++){
if (board[0][c] == 'O') {
board[0][c] = '+';
queue.add(new Point(0, c));
}
if (board[rowN-1][c] == 'O') {
board[rowN-1][c] = '+';
queue.add(new Point(rowN-1, c));
}
}
//BFS for the 'O's, and mark it as '+'
while (!queue.isEmpty()){
Point p = queue.poll();
int row = p.x;
int col = p.y;
if (row - 1 >= 0 && board[row-1][col] == 'O') {board[row-1][col] = '+'; queue.add(new Point(row-1, col));}
if (row + 1 < rowN && board[row+1][col] == 'O') {board[row+1][col] = '+'; queue.add(new Point(row+1, col));}
if (col - 1 >= 0 && board[row][col - 1] == 'O') {board[row][col-1] = '+'; queue.add(new Point(row, col-1));}
if (col + 1 < colN && board[row][col + 1] == 'O') {board[row][col+1] = '+'; queue.add(new Point(row, col+1));}
}
//turn all '+' to 'O', and 'O' to 'X'
for (int i = 0; i 代码实现(深度优先遍历)
class Solution {
public void solve(char[][] board) {
if (board.length == 0 || board[0].length == 0) return;
if (board.length < 3 || board[0].length < 3) return;
int m = board.length;
int n = board[0].length;
for (int i = 0; i < m; i++) {
if (board[i][0] == 'O') helper(board, i, 0);
if (board[i][n - 1] == 'O') helper(board, i, n - 1);
}
for (int j = 1; j < n - 1; j++) {
if (board[0][j] == 'O') helper(board, 0, j);
if (board[m - 1][j] == 'O') helper(board, m - 1, j);
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == 'O') board[i][j] = 'X';
if (board[i][j] == '*') board[i][j] = 'O';
}
}
}
private void helper(char[][] board, int r, int c) {
if (r < 0 || c < 0 || r > board.length - 1 || c > board[0].length - 1 || board[r][c] != 'O') return;
board[r][c] = '*';
helper(board, r + 1, c);
helper(board, r - 1, c);
helper(board, r, c + 1);
helper(board, r, c - 1);
}
}
2.Number of Islands
题目描述
给定'1's(陆地)和'0's(水)的二维网格图,计算岛的数量。一个岛被水包围,并且通过水平或垂直连接相邻的陆地而形成。你可以假设网格的所有四个边都被水包围。
例1:
11110
11010
11000
00000
答:1
例2:
11000
11000
00100
00011
答:3
代码实现(广度优先遍历)
public int numIslands(char[][] grid) {
int count=0;
for(int i=0;i queue = new LinkedList();
int code = x*m+y;
queue.offer(code);
while(!queue.isEmpty())
{
code = queue.poll();
int i = code/m;
int j = code%m;
if(i>0 && grid[i-1][j]=='1') //search upward and mark adjacent '1's as '0'.
{
queue.offer((i-1)*m+j);
grid[i-1][j]='0';
}
if(i0 && grid[i][j-1]=='1') //left
{
queue.offer(i*m+j-1);
grid[i][j-1]='0';
}
if(j 代码实现(深度优先遍历)
private int n;
private int m;
public int numIslands(char[][] grid) {
int count = 0;
n = grid.length;
if (n == 0) return 0;
m = grid[0].length;
for (int i = 0; i < n; i++){
for (int j = 0; j < m; j++)
if (grid[i][j] == '1') {
DFSMarking(grid, i, j);
++count;
}
}
return count;
}
private void DFSMarking(char[][] grid, int i, int j) {
if (i < 0 || j < 0 || i >= n || j >= m || grid[i][j] != '1') return;
grid[i][j] = '0';
DFSMarking(grid, i + 1, j);
DFSMarking(grid, i - 1, j);
DFSMarking(grid, i, j + 1);
DFSMarking(grid, i, j - 1);
}
3.Minesweeper
给你一个代表游戏板的2D字符矩阵。'M'代表一个未揭露的地雷,'E'代表一个未被揭露的空方块,'B'代表一个显露的空白方块,不存在相邻的(上,下,左,右和所有4个对角线)地雷,数字('1'到'8')表示有多少个地雷与这个暴露的正方形相邻,最后是'X'代表一个透露的地雷。
现在给出下一个点击位置(行和列索引)在所有未被揭示的方块('M'或'E')之间,按照以下规则揭示该位置后返回棋盘:
如果发现一个地雷('M'),那么游戏结束 - 将其更改为'X'。
如果显示没有相邻地雷的空方块('E'),则将其更改为显示空白('B'),并且所有相邻的未发现方块应递归显示。
如果显示至少有一个相邻地雷的空方块('E'),则将其更改为代表相邻地雷数量的数字('1'至'8')。
当没有更多的方块会显示时,请返回棋盘。
例1:
输入
[['E','E','E','E','E'],
['E','E','M','E','E'],
['E','E','E','E','E'],
['E','E','E','E','E']]
点击:[3,0]
输出:
[['B','1','E','1','B'],
['B','1','M','1','B'],
['B','1','1','1','B' ],
['B','B','B','B','B']
说明:

例2:
输入:
[['B','1','E','1','B'],
['B','1','M','1','B'],
['B','1','1','1','B' ],
['B','B','B','B','B']
点击:[1,2]
输出:
[['B','1','E','1','B'],
['B','1','X','1','B' ],
['B','1','1','1','B' ],
['B','B','B','B','B']
说明:
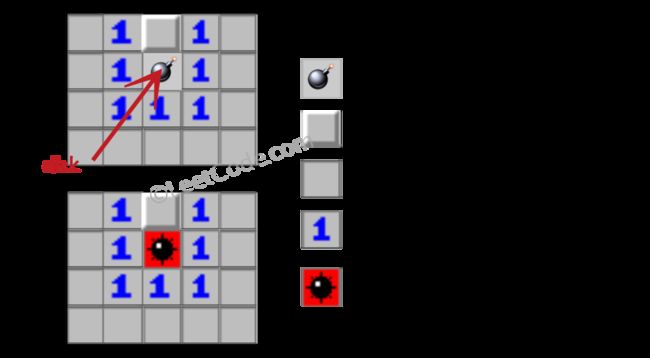
思路分析
这是一个典型的Search问题,无论是使用DFS或BFS。搜索规则:
1.如果点击地雷(' M'),将其标记为' X',停止进一步搜索。
2.如果点击空单元格(' E'),取决于周围的矿井数量:
2.1有周围的地雷,用周围地雷的数量标记,停止进一步的搜索。
2.2没有周围的地雷,将其标记为“ B',继续搜索它的8个邻居。
代码实现(广度优先遍历)
public class Solution {
public char[][] updateBoard(char[][] board, int[] click) {
int m = board.length, n = board[0].length;
Queue queue = new LinkedList<>();
queue.add(click);
while (!queue.isEmpty()) {
int[] cell = queue.poll();
int row = cell[0], col = cell[1];
if (board[row][col] == 'M') { // Mine
board[row][col] = 'X';
}
else { // Empty
// Get number of mines first.
int count = 0;
// 这里的两层for循环目的是为了检索这个点的上下左右和四个角,其实这个与前面的四个递归本质是一样的,只不过这里要8个,所以用for循环更好,而且本来用递归效率就不高。
for (int i = -1; i < 2; i++) {
for (int j = -1; j < 2; j++) {
if (i == 0 && j == 0) continue;
int r = row + i, c = col + j;
if (r < 0 || r >= m || c < 0 || c < 0 || c >= n) continue;
if (board[r][c] == 'M' || board[r][c] == 'X') count++;
}
}
if (count > 0) { // If it is not a 'B', stop further BFS.
board[row][col] = (char)(count + '0');
}
else { // Continue BFS to adjacent cells.
board[row][col] = 'B';
for (int i = -1; i < 2; i++) {
for (int j = -1; j < 2; j++) {
if (i == 0 && j == 0) continue;
int r = row + i, c = col + j;
if (r < 0 || r >= m || c < 0 || c < 0 || c >= n) continue;
if (board[r][c] == 'E') {
queue.add(new int[] {r, c});
board[r][c] = 'B'; // Avoid to be added again.
}
}
}
}
}
}
return board;
}
}
代码实现(深度优先遍历)
public class Solution {
public char[][] updateBoard(char[][] board, int[] click) {
int m = board.length, n = board[0].length;
int row = click[0], col = click[1];
if (board[row][col] == 'M') { // Mine
board[row][col] = 'X';
}
else { // Empty
// Get number of mines first.
int count = 0;
for (int i = -1; i < 2; i++) {
for (int j = -1; j < 2; j++) {
if (i == 0 && j == 0) continue;
int r = row + i, c = col + j;
if (r < 0 || r >= m || c < 0 || c < 0 || c >= n) continue;
if (board[r][c] == 'M' || board[r][c] == 'X') count++;
}
}
if (count > 0) { // If it is not a 'B', stop further DFS.
board[row][col] = (char)(count + '0');
}
else { // Continue DFS to adjacent cells.
board[row][col] = 'B';
for (int i = -1; i < 2; i++) {
for (int j = -1; j < 2; j++) {
if (i == 0 && j == 0) continue;
int r = row + i, c = col + j;
if (r < 0 || r >= m || c < 0 || c < 0 || c >= n) continue;
if (board[r][c] == 'E') updateBoard(board, new int[] {r, c}); //递归实现数据传递和深度优先遍历,这是唯一与广度优先遍历的区别
}
}
}
}
return board;
}
}
4. 0&1 Matrix
问题描述
给定一个由0和1组成的矩阵,找出每个单元最近的0的距离。
两个相邻单元之间的距离是1。
示例1:
输入:
0 0 0
0 1 0
0 0 0
输出:
0 0 0
0 1 0
0 0 0
例2:
输入:
0 0 0
0 1 0
1 1 1
输出:
0 0 0
0 1 0
1 2 1
注意:
给定矩阵的元素数量不会超过10,000。
给定矩阵中至少有一个0。
细胞只在四个方向上相邻:向上,向下,向左和向右。
代码实现(广度优先遍历)
public class Solution {
public int[][] updateMatrix(int[][] matrix) {
int m = matrix.length;
int n = matrix[0].length;
Queue queue = new LinkedList<>();
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (matrix[i][j] == 0) {
queue.offer(new int[] {i, j});
}
else {
matrix[i][j] = Integer.MAX_VALUE; //非0的矩阵值设为整型最大值
}
}
}
//此矩阵的目的就是实现寻找某个点的上下左右四个相邻点
int[][] dirs = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
while (!queue.isEmpty()) {
int[] cell = queue.poll();
for (int[] d : dirs) {
int r = cell[0] + d[0];
int c = cell[1] + d[1];
if (r < 0 || r >= m || c < 0 || c >= n ||
matrix[r][c] <= matrix[cell[0]][cell[1]] + 1) continue; //如果原来是1,则矩阵的值为整型最大值,没有谁会大于本点,如果本点的上下左右四个点都小于等于本点,表示本点的周围没有1
queue.add(new int[] {r, c});
matrix[r][c] = matrix[cell[0]][cell[1]] + 1; //如果遇到某个点的左右上下有大于本点的,表示遇到了本点相邻为1的情况,此时整型最大值加1就是1,因为溢出了
}
}
return matrix;
}
}
代码实现(深度优先遍历)
public class Solution {
public int[][] updateMatrix(int[][] matrix) {
if(matrix.length==0) return matrix;
for(int i = 0; i=matrix[0].length||x>=matrix.length||matrix[x][y]<=val)
return;
if(val>0) matrix[x][y] = val;
dfs(matrix, x+1, y, matrix[x][y]+1);
dfs(matrix, x-1, y, matrix[x][y]+1);
dfs(matrix, x, y+1, matrix[x][y]+1);
dfs(matrix, x, y-1, matrix[x][y]+1);
}
private boolean hasNeiberZero(int x, int y, int[][] matrix){
if(x>0&&matrix[x-1][y]==0) return true;
if(x0&&matrix[x][y-1]==0) return true;
if(y 5.Minimum Depth of Binary Tree
题目描述
给定一个二叉树,找到它的最小深度。
最小深度是沿着从根节点到最近叶节点的最短路径的节点数量。
代码实现(广度优先遍历)
public int minDepth(TreeNode root) {
if(root == null) return 0;
int depth = 1;
Queue q = new LinkedList();
q.offer(root);
while(!q.isEmpty()){
int size = q.size();
// for each level
for(int i=0;i 代码实现(深度优先遍历)
public class Solution {
public int minDepth(TreeNode root) {
if(root == null) return 0;
int left = minDepth(root.left);
int right = minDepth(root.right);
return (left == 0 || right == 0) ? left + right + 1: Math.min(left,right) + 1;
}
}
###复杂度
BFS和DFS的复杂度不一样,BFS要好些,所以虽然都可以完成功能,但是因为算法效率不一样,最后复杂度也不一样。
6.Course Schedule II
问题描述
总共有n个课程需要学习,标记为0 至 n - 1。
有些课程可能有先决条件,例如,如果选择课程0,则必须先参加课程1,该课程表示为一对: [0,1]
输入课程总数和先修课程的条件对列表,请返回应完成所有课程的顺序。
可能有多个正确的命令,你只需要返回其中的一个。如果不可能完成所有课程,则返回一个空数组。
例如:
2, [[1,0]]
总共有2门课程可供选择。要参加课程1,你应该已经完成课程0.所以正确的课程顺序是[0,1]
4, [[1,0],[2,0],[3,1],[3,2]]
总共有4门课程可供选择。要参加课程3,你应该已经完成了课程1和2.在完成课程0之后,应该采用课程1和2。因此,一个正确的课程顺序是[0,1,2,3]。另一个正确的顺序是[0,2,1,3]。
代码实现(广度优先遍历)
1.邻接表图结构
private int[] solveByBFS(int[] incLinkCounts, List> adjs){
int[] order = new int[incLinkCounts.length];
Queue toVisit = new ArrayDeque<>();
for (int i = 0; i < incLinkCounts.length; i++) {
if (incLinkCounts[i] == 0) toVisit.offer(i);
}
int visited = 0;
while (!toVisit.isEmpty()) {
int from = toVisit.poll();
order[visited++] = from;
for (int to : adjs.get(from)) {
incLinkCounts[to]--;
if (incLinkCounts[to] == 0) toVisit.offer(to);
}
}
return visited == incLinkCounts.length ? order : new int[0];
}
2.邻接矩阵图结构
public int[] findOrder(int numCourses, int[][] prerequisites) {
if (numCourses == 0) return null; //如果修的课程为0,则直接返回-1
// Convert graph presentation from edges to indegree of adjacent list.
int indegree[] = new int[numCourses], order[] = new int[numCourses], index = 0;
//order数组表示输出修的课程的顺序,indegree数组表示每一门课程前面需要修的其他课程的总数
for (int i = 0; i < prerequisites.length; i++) // Indegree - how many prerequisites are needed.
indegree[prerequisites[i][0]]++; //计算每门课需要需要先修的课数,即前面有几门课需要先修
Queue queue = new LinkedList();
for (int i = 0; i < numCourses; i++)
if (indegree[i] == 0) { //把不需要先修的课程放入到队列中,没有顺序,仅仅根据课程编号的顺序执行
// Add the course to the order because it has no prerequisites.
order[index++] = i;
queue.offer(i);
}
// How many courses don't need prerequisites.
while (!queue.isEmpty()) {
int prerequisite = queue.poll(); // Already finished this prerequisite course.
for (int i = 0; i < prerequisites.length; i++) {
if (prerequisites[i][1] == prerequisite) {
indegree[prerequisites[i][0]]--; //取出一个先修课程,然后遍历找出在此课程之前需要修的数量,减去1
if (indegree[prerequisites[i][0]] == 0) { //如果先修课程为0了,此时加入到队列中,作为其他的课程的先修课程
// If indegree is zero, then add the course to the order.
order[index++] = prerequisites[i][0]; //更新先修课程的输出顺序
queue.offer(prerequisites[i][0]);
}
}
}
}
return (index == numCourses) ? order : new int[0];
}
代码实现(深度优先遍历)
private int[] solveByDFS(List> adjs) {
BitSet hasCycle = new BitSet(1);
BitSet visited = new BitSet(adjs.size());
BitSet onStack = new BitSet(adjs.size());
Deque order = new ArrayDeque<>();
for (int i = adjs.size() - 1; i >= 0; i--) {
if (visited.get(i) == false && hasOrder(i, adjs, visited, onStack, order) == false) return new int[0];
}
int[] orderArray = new int[adjs.size()];
for (int i = 0; !order.isEmpty(); i++) orderArray[i] = order.pop();
return orderArray;
}
private boolean hasOrder(int from, List> adjs, BitSet visited, BitSet onStack, Deque order) {
visited.set(from);
onStack.set(from);
for (int to : adjs.get(from)) {
if (visited.get(to) == false) {
if (hasOrder(to, adjs, visited, onStack, order) == false) return false;
} else if (onStack.get(to) == true) {
return false;
}
}
onStack.clear(from);
order.push(from);
return true;
}
7.Cheapest Flights Within K Stops
题目描述
有m个航班连接n个城市。航班从城市u飞抵城市v,机票价格为w。
输入所有的城市和机票价格,出发城市为src和目的地为dst,任务是找到从城市src到dst中间停留最多k站的最便宜的机票价格。如果没有这样的路线,输出-1。
Example 1:
Input:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 1
Output: 200
Explanation:
The graph looks like this:
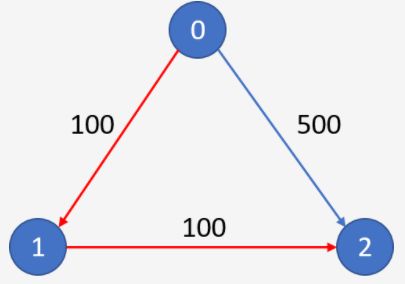
The cheapest price from city 0 to city 2 with at most 1 stop costs 200, as marked red in the picture.
题目分析
本题与上一题本质是一样的,就是从一个地方走到另外一个地方,之间有对应关系。直接表现为广度优先遍历或深度优先遍历的情况
代码实现(BFS)
public int findCheapestPrice(int n, int[][] flights, int src, int dst, int k) {
//使用map数据结构的目的是为了集合可能的多个从同一个城市(顶点)出发的数据,同时为了避免混淆同一个城市的数据,用目标城市来作为value中的map的key,price值作为目标城市的key,利用这种数据结构可以实现唯一性
Map> prices = new HashMap<>();
//创建图结构,利用map实现顶点f[0](城市名)到目标城市f[1]与价格f[2]的映射
for (int[] f : flights) {
if (!prices.containsKey(f[0])) prices.put(f[0], new HashMap<>());
prices.get(f[0]).put(f[1], f[2]);
}
//优先队列实现那个价格更小,然后放到前面,这样就可以实现找到结果就可以终止程序
Queue pq = new PriorityQueue<>((a, b) -> (Integer.compare(a[0], b[0])));
pq.add(new int[] {0, src, k + 1}); //加入起始城市
while (!pq.isEmpty()) {
int[] top = pq.remove();
int price = top[0];
int city = top[1];
int stops = top[2];
if (city == dst) return price;
if (stops > 0) {
Map adj = prices.getOrDefault(city, new HashMap<>());
for (int a : adj.keySet()) {//取出所有与city这个键对应的value,然后依次价格相加,起始城市更新为下一个城市,即当前city所邻接的城市,同时stops-1,表示当前city的相邻城市停了
pq.add(new int[] {price + adj.get(a), a, stops - 1});
}
}
}
return -1;
}
8. Employee Importance
题目描述
给你一个员工信息的数据结构,包括员工的唯一ID,他的重要性值和他的直属下属的ID。
例如,员工1是员工2的领导,员工2是员工3的领导。他们分别具有15,10和5的重要性值。然后,员工1具有[1,15,[2]]的数据结构,并且员工2具有[2,10,[3]],员工3具有[3,5,[]]。请注意,虽然员工3也是员工1的下属,但这种关系并不直接。
现在给出公司的员工信息和员工ID,您需要返回此员工及其所有下属的总重要性值。
例1:
输入: [[1,5,[2,3]],[2,3,[]],[3,3,[]]],1
输出: 11
说明:
员工1的重要性值为5,他有两个直接下属:员工2和员工3,他们都具有重要性值3,因此员工1的总重要值为5 + 3 + 3 = 11。
注意:
一名员工最多只有一名直接领导,可能有几名下属。
员工人数不得超过2000人。
员工数据结构定义
public class Employee {
// It's the unique id of each node;
// unique id of this employee
public int id;
// the importance value of this employee
public int importance;
// the id of direct subordinates
public List subordinates;
}
代码实现(广度优先遍历)
class Solution {
public int getImportance(List employees, int id) {
int total = 0;
Map map = new HashMap<>();
for (Employee employee : employees) {
map.put(employee.id, employee);
}
Queue queue = new LinkedList<>();
queue.offer(map.get(id));
while (!queue.isEmpty()) {
Employee current = queue.poll();
total += current.importance;
//如果一个顶点有很多个对应的相邻节点,同时这些节点又可能没有关系,就需要利用for循环一次性全部加载进来
for (int subordinate : current.subordinates) {
queue.offer(map.get(subordinate));
}
}
return total;
}
}
代码实现(深度优先遍历)
class Solution {
public int getImportance(List employees, int id) {
Map map = new HashMap<>();
for (Employee employee : employees) {
map.put(employee.id, employee);
}
return getImportanceHelper(map, id);
}
private int getImportanceHelper(Map map, int rootId) {
Employee root = map.get(rootId);
int total = root.importance;
for (int subordinate : root.subordinates) {
total += getImportanceHelper(map, subordinate);
}
return total;
}
}
9.Word Ladder
问题描述
给定两个单词(beginWord和endWord)和一个字典的单词列表,找到从beginWord到endWord的最短转换序列的长度,例如:
一次只能更改一个字母。
每个转换的单词必须存在于单词列表中。需要注意的是beginWord是可以变换的词。
例如,
例如:
beginWord = "hit"
endWord = "cog"
wordList =["hot","dot","dog","lot","log","cog"]
作为一个最短的转换"hit" -> "hot" -> "dot" -> "dog" -> "cog",
返回它的长度5。
注意:
如果没有这样的转换序列,则返回0。
所有单词具有相同的长度。
所有单词只包含小写字母字符。
您可能会认为单词列表中没有重复项。
你可能会认为beginWord和endWord是非空的并且不一样。
问题分析
让我们看看问题陈述中的例子。
start = "hit"
end = "cog"
dict = ["hot", "dot", "dog", "lot", "log"]
由于每次只能更改一个字母,如果我们从"hit"开始,我们只能更改当前单词只有一个字母不相等的单词,例如"hot"。以图论的方式来说,我们可以说这"hot"是一个邻居"hit"。
这个想法很简单,先来看看start的邻居,然后访问其邻居的未访问邻居......嗯,这只是典型的BFS结构。
为了简化问题,我们把end单词插入到dict。一旦我们在BFS 遇到end单词,我们找到了答案。我们为变换的当前距离保留一个变量dist,并在完成一轮BFS搜索(请注意,它应该符合问题描述中距离的定义)后更新它dist++。此外,为避免多次访问某个单词,我们会在访问该单词dict后将其删除。
代码实现
class Solution {
public:
int ladderLength(string beginWord, string endWord, unordered_set& wordDict) {
wordDict.insert(endWord); //把目标单词插入到字典中
queue toVisit; //队列保存单词的邻居,即将要访问的内容
addNextWords(beginWord, wordDict, toVisit);
int dist = 2; //记录单词修改的次数
while (!toVisit.empty()) {
int num = toVisit.size();
for (int i = 0; i < num; i++) { //一次性地把上一个单词的所有相邻单词都提取出来进行计算
string word = toVisit.front();
toVisit.pop();
if (word == endWord) return dist;
addNextWords(word, wordDict, toVisit); //没找到目标单词,则继续寻找下去
}
dist++;
}
}
private:
//本函数的目的是选择当前单词的一个索引位置并依次改为26个字母,也即修改单词,然后找到此单词的邻居,只能一个一个地去试一试。
void addNextWords(string word, unordered_set& wordDict, queue& toVisit) {
wordDict.erase(word); //删除访问过的单词
for (int p = 0; p < (int)word.length(); p++) { //单词的各个位置的字母进行修改
char letter = word[p];
for (int k = 0; k < 26; k++) { //修改为26个字母
word[p] = 'a' + k;
if (wordDict.find(word) != wordDict.end()) { //如果修改后的单词在字典中存在,则输入到toVisit队列中,表示修改有效
toVisit.push(word);
wordDict.erase(word);//放入到toVisit中的单词即为将来要访问的单词,为了避免重复访问,所以删除此单词
}
}
word[p] = letter; //记得把修改后的内容恢复,否则一次就修改了好多几个字母
}
}
};
参考文献:
[1] Leetcode
[2] 字符串每一次变化一个,从起始单词到目标单词的最短路径,就是一个BFS的计算过程,而且BFS的效率会更高,因为我们知道计算谁最短。
Dijkstra算法利用的是BFS原理实现的,但是通过斐波那契堆实现的Dijkstra算法的时间复杂度为O(n^2),空间复杂度为O(m+nlogn),其中n为顶点个数,m为边数
