repr()
x = 10 * 3.25
y = 200 * 200
s = 'x 的值为: ' + repr(x) + ', y 的值为:' + repr(y) + '...'
print(s)
x 的值为: 32.5, y 的值为:40000...
# repr() 函数可以转义字符串中的特殊字符
hello = 'hello, runoob\n'
hellos = repr(hello)
print(hellos)
'hello, runoob\n'
rjust()
print(repr(x).rjust(12), repr(x*x).rjust(3), end=',')
#输出的时候有时候会看到 rjust() 这种写法。这个是在你输出的X的最后一位与前面的信息之间的距离(可以理解为右对齐)。如果rjust中的数字 小于该值的长度。该值输出会向后位移。(可理解成左对齐)
上面例子展示了字符串对象的 rjust() 方法, 它可以将字符串靠右, 并在左边填充空格。
还有类似的方法, 如 ljust() 和 center()。 这些方法并不会写任何东西, 它们仅仅返回新的字符串。
另一个方法 zfill(), 它会在数字的左边填充 0,如下所示:
table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
print('Runoob: {0[Taobao]:4}'.format(table))
上面的代码中使用了.format的格式化输出方法。一般{}中可以不写 或者写索引号。在这个代码中 [Taobao] 是定义字典table的键,4是间隔。:号前一般都为0
open
参数
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener:
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
file.close()
关闭文件。关闭后文件不能再进行读写操作。
file.flush()
刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。
file.fileno()
返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。
file.isatty()
如果文件连接到一个终端设备返回 True,否则返回 False。
file.next()
返回文件下一行。
file.read([size])
从文件读取指定的字节数,如果未给定或为负则读取所有。
file.readline([size])
读取整行,包括 "\n" 字符。
file.readlines([sizeint])
读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。
file.seek(offset[, whence])
设置文件当前位置
file.tell()
返回文件当前位置。
file.truncate([size])
从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。
file.write(str)
将字符串写入文件,返回的是写入的字符长度。
file.writelines(sequence)
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。
open 举例
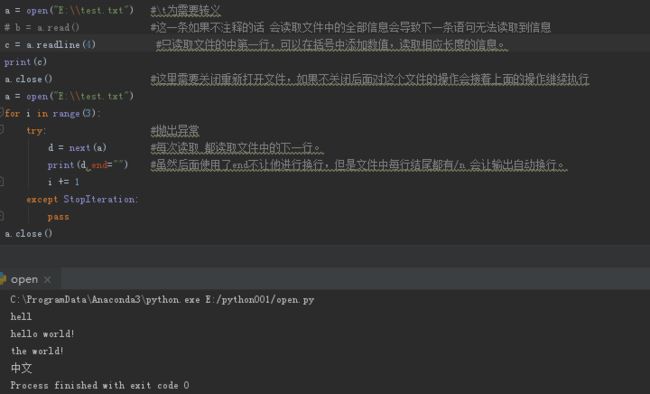
d = next(a) #每次读取 都读取文件中的下一行。
Repr = repr(d)
print(Repr) # 通常会有需求需要对文件中的内容进行处理 我们需要想办法吧/n显示出来 可以用这个
#然后可以对这个字符串进行你想要的处理