1. 学科最受欢迎老师解法补充
day21中该案例的解法四还有一个问题,就是当各个老师受欢迎度是一样的时候,其排序规则就处理不了,以下是对其优化的解法
实现方式五
FavoriteTeacher5
package com._51doit.spark04 import org.apache.spark.{Partitioner, SparkConf, SparkContext} import org.apache.spark.rdd.RDD import scala.collection.mutable object FavoriteTeacher5 { def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } val sc = new SparkContext(conf) //指定以后从哪里读取数据创建RDD val lines: RDD[String] = sc.textFile(args(1)) //对数据进行切分 val subjectTeacherAndOne = lines.map(line => { val fields = line.split("/") val subject = fields(2).split("[.]")(0) val teacher = fields(3) ((subject, teacher), 1) }) //计算所有的学科,并收集到Driver端 val subjects: Array[String] = subjectTeacherAndOne.map(_._1._1).distinct().collect() //paritioner是在Driver端被new出来的,但是他的方法是在Executor中被调用的 val partitioner = new SubjectPartitioner3(subjects) //根据指定的key和分区器进行聚合(减少一次shuffle) val reduced: RDD[((String, String), Int)] = subjectTeacherAndOne.reduceByKey(partitioner, _+_) val topN = args(2).toInt val result = reduced.mapPartitions(it => { //定义一个key排序的集合TreeSet val sorter = new mutable.TreeSet[OrderingBean]() //遍历出迭代器中的数据 it.foreach(t => { sorter += new OrderingBean(t._1._1, t._1._2, t._2) if (sorter.size > topN) { val last = sorter.last //移除最后一个 sorter -= last } }) sorter.iterator }) val r = result.collect() println(r.toBuffer) sc.stop() } } class SubjectPartitioner3(val subjects: Array[String]) extends Partitioner { //初始化分器的分区规则 val rules = new mutable.HashMap[String, Int]() var index = 0 for(sub <- subjects) { rules(sub) = index index += 1 } override def numPartitions: Int = subjects.length //该方法会在Executor中的Task中被调用 override def getPartition(key: Any): Int = { val tuple = key.asInstanceOf[(String, String)] val subject = tuple._1 //到实现初始化的规则中查找这个学科对应的分区编号 rules(subject) } }
OrderingBean(重新定义的排序规则)
package com._51doit.spark04 import scala.collection.mutable.ArrayBuffer class OrderingBean(val subject: String, val name: String, val count: Int) extends Ordered[OrderingBean] with Serializable { val equiv = new ArrayBuffer[(String, String, Int)]() equiv += ((subject, name, count)) override def compare(that: OrderingBean): Int = { if (this.count == that.count) { equiv += ((that.subject, that.name, that.count)) 0 } else { -(this.count - that.count) } } override def toString: String = if (equiv.size > 1) { equiv.toString() } else s"($subject, $name, $count)" }
实现方式六(使用repartitionAndSortWithinPartitions)
repartitionAndSortWithinPartitions按照指定的分区器进行排序并且在每个分区内进行排序
FavoriteTeacher6
object FavoriteTeacher06 { def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[1]") } val sc = new SparkContext(conf) //指定以后从哪里读取数据创建RDD val lines: RDD[String] = sc.textFile(args(1)) //对数据进行切分 val subjectTeacherAndOne = lines.map(line => { val fields = line.split("/") val subject = fields(2).split("[.]")(0) val teacher = fields(3) ((subject, teacher), 1) }) //聚合 val reduced = subjectTeacherAndOne.reduceByKey(_ + _) //计算所有的学科,并收集到Driver端 val subjects: Array[String] = reduced.map(_._1._1).distinct().collect() //paritioner是在Driver端被new出来的,但是他的方法是在Executor中被调用的 val partitioner = new SubjectPartitionerV2(subjects) //对原来的数据进行整理 val keyByRDD: RDD[((String, String, Int), Null)] = reduced .map(t => ((t._1._1, t._1._2, t._2), null)) //隐式转换 implicit val orderRules = new Ordering[(String, String, Int)] { override def compare(x: (String, String, Int), y: (String, String, Int)): Int = { -(x._3 - y._3) } } val topN = args(2).toInt //repartitionAndSortWithinPartitions按照指定的分区器进行排序并且在每个分区内进行排序 val result: RDD[((String, String, Int), Null)] = keyByRDD .repartitionAndSortWithinPartitions(partitioner) result.foreachPartition(it => { var index = 1 while (it.hasNext && index <= topN) { val tuple = it.next() println(tuple) index += 1 } }) sc.stop() } }
SubjectPartitionerV2
class SubjectPartitionerV2(val subjects: Array[String]) extends Partitioner { //初始化分器的分区规则 val rules = new mutable.HashMap[String, Int]() var index = 0 for(sub <- subjects) { rules(sub) = index index += 1 } override def numPartitions: Int = subjects.length //该方法会在Executor中的Task中被调用 override def getPartition(key: Any): Int = { val tuple = key.asInstanceOf[(String, String, Int)] val subject = tuple._1 //到实现初始化的规则中查找这个学科对应的分区编号 rules(subject) } }
2. 自定义排序
数据形式:姓名,年龄,颜值
需求:首先按照颜值排序(颜值高的排前面),当颜值相同的情况下,年龄小的人排前面
2.1 第一种形式
思路,定义一个Boy类(case class),用来加载这些属性,利用隐式转换定义一个排序规则,具体如下
CustomSort1
object CustomSort1 { def main(args: Array[String]): Unit = { import com._51doit.spark04.MyPredef val conf: SparkConf = new SparkConf() .setAppName(this.getClass.getSimpleName) .setMaster("local[*]") // 创建SparkContext val sc: SparkContext = new SparkContext(conf) val lines: RDD[String] = sc.parallelize(List("jack,30,99.99", "sherry,18,9999.99", "Tom,29,99.99")) // 处理数据,使用mapPartitions,减少Boy的创建 val BoyRDD: RDD[Boy] = lines.mapPartitions(it => { it.map(t => { val split: Array[String] = t.split(",") Boy(split(0), split(1).toInt, split(2).toDouble) }) }) import MyPredef.Boy2OrderingBoy val res: RDD[Boy] = BoyRDD.sortBy(t => t) print(res.collect().toBuffer) } }
MyPredef
两种写法都行
Ordered的形式
object MyPredef { implicit val Boy2OrderingBoy: Boy => Ordered[Boy] = (boy:Boy) => new Ordered[Boy]{ override def compare(that: Boy): Int = { if(boy.fv == that.fv){ boy.age - that.age } else{ -(boy.fv - that.fv).toInt } } } }
Ordering的形式
object MyPredef { implicit val Boy2OrderingBoy: Ordering[Boy] = new Ordering[Boy] { override def compare(x: Boy, y:Boy): Int = { if (x.fv == y.fv) { x.age - y.age } else { -(x.fv - y.fv).toInt } } } }
Boy
case class Boy(name:String, age:Int, fv: Double)
2.2 第二种形式(借助元组)
object CustomSort2 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf() .setAppName(this.getClass.getSimpleName) .setMaster("local[*]") // 创建SparkContext val sc: SparkContext = new SparkContext(conf) val lines: RDD[String] = sc.parallelize(List("jack,30,99.99", "sherry,18,9999.99", "Tom,29,99.99")) // 处理数据,使用mapPartitions,减少Boy的创建 val tpRDD: RDD[(String, Int, Double)] = lines.mapPartitions(it => { it.map(t => { val split: Array[String] = t.split(",") (split(0), split(1).toInt, split(2).toDouble) }) }) // 使用元组的默认规则进行排序 val sorted: RDD[(String, Int, Double)] = tpRDD.sortBy(t => (-t._3, t._2)) println(sorted.collect().toBuffer) } }
3. spark任务执行过程
- Driver端
(1)new SparkContext时,driver端向Master提交一个Application,确定在该集群中每个executor需要多少内存,所有Executor共有的cores,然后由master通过控制worker产生executor,并向其分配core(一个一个的均摊)
(2)使用sc创建RDD,并且调用RDD的转换算子,最后调用Action算子,一旦触发Action,就形成了一个完整的DAG图,一个DAG就是一个job
(3)根据最后一个RDD,从后往前推,将DAG根据shuffle(宽依赖)切分成多个stage,一个stage对应一个TaskSet,并将生成的Task(动态生成)放入到TaskSet,同一个TaskSet中的Task的计算逻辑是一样的
(4)先提交前面的stage,一个stage对应一个TaskSet,那就意味着将TaskSet中的Task要调度到Executor中(说明:Task是在drever端产生的)
(5)TaskScheduler将Task先序列化,然后通过网络传输给Executorzai
- Executor端
(6)将Task反序列化,然后用一个实现Runnable的类包装,然后丢入线程池,run方法就执行了,即调用Task的执行逻辑
流程图如下

4. SparkTask的分类

(1)ShuffleMapTask
- 可以读取外部的数据源
- 可以对数据进行处理
- 主要功能就是为Shuffle做准备,将数据溢写到磁盘中
- ShuffleMapTask可以读取上一阶段产生的shuffle数据
(2)ResultTask
- 就是计算产生最终的结果,可以写入到外部的存储系统中,也可以收集到driver
- 可以读取上一个阶段产生的shuffle数据
- 对数据进行处理
- 可以读取外部数据源的数据(一个DAG中没有ShuffleMapTask,如下图)
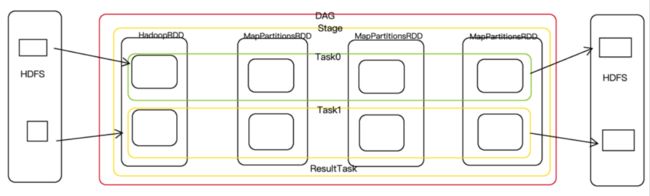
5 Task的序列化
(1)引用类型在Driver端初始化
RulesMapObjNoSer
object RulesMapObjNoSer { val rules = Map("jx" -> "江西省", "zj" -> "浙江省", "hn" -> "湖南省", "fj" -> "福建省") }
SerTest1
object SerTest1 { def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } // 创建SparkContext val sc: SparkContext = new SparkContext(conf) // 读取hdfs中的文件,获取rdd val lines: RDD[String] = sc.textFile(args(1)) // Driver端初始化规则 val rulesMap = RulesMapObjNoSer val wordAndProvinceRDD: RDD[(String, String, String, Int, Long, RulesMapObjNoSer.type)] = lines.map(word => { // 关联外部规则,获取省份信息,此处相当于闭包(函数内部调用函数外部的引用类型) val province: String = rulesMap.rules(word) // 获取分区号 val partitionId: Int = TaskContext.getPartitionId() // 获取主机名 val hostname = InetAddress.getLocalHost.getHostName // 获取线程id val threadId = Thread.currentThread().getId (word, province, hostname, partitionId, threadId, rulesMap) }) // 将处理好的数据写回到HDFS wordAndProvinceRDD.saveAsTextFile(args(2)) sc.stop() } }
这样运行会报如下错误

原因:在Driver端初始化的规则也会随着任务被一起调度(RPC传输)到executor中执行,网络传输需要序列化,所以汇报序列化错误
改变:将引用数据类型序列化
object RulesMapObjNoSer extends Serializable { val rules = Map("jx" -> "江西省", "zj" -> "浙江省", "hn" -> "湖南省", "fj" -> "福建省") }
注意:此处若将RulesMapObjNoSer的类型改为Class的话,相对来讲耗费资源(一个Task创建一个对象),而使用object则是一个executor中创建一个对象,executor中的Task数量越多,class形式的效率就越低。但有些时候只能用class,object会存在线程不安全

(2)引用类型在函数内部初始化
这种情形的闭包中使用的外部引用类型不需要序列化
object RulesMapObjNoSer { val rules = Map("jx" -> "江西省", "zj" -> "浙江省", "hn" -> "湖南省", "fj" -> "福建省") }
SerTest2
object SerTest2 { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME", "root") val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } // 创建SparkContext val sc: SparkContext = new SparkContext(conf) // 读取hdfs中的文件,获取rdd val lines: RDD[String] = sc.textFile(args(1)) val wordAndProvinceRDD: RDD[(String, String, String, Int, Long, RulesMapObjNoSer.type)] = lines.map(word => { //函数内部初始化规则 val rulesMap = RulesMapObjNoSer // 关联外部规则,获取省份信息,此处相当于闭包(函数内部调用函数外部的引用类型) val province: String = rulesMap.rules(word) // 获取分区号 val partitionId: Int = TaskContext.getPartitionId() // 获取主机名 val hostname = InetAddress.getLocalHost.getHostName // 获取线程id val threadId = Thread.currentThread().getId (word, province, hostname, partitionId, threadId, rulesMap) }) // 将处理好的数据写回到HDFS wordAndProvinceRDD.saveAsTextFile(args(2)) sc.stop() } }
说明:此处的引用类型不需要序列化,因为引用类型并不需要传输至executor端,此处若将引用类型改为class,则效率会非常的低 , 没处理一条数据就要创建一个对象(此处是RulesMapObjNoSer),极度耗费资源。若是因为线程安全,一定要使用class,则引用类型写在Driver端的效率会比写在函数内部高(更好的解决方法:使用mapPartition(),见下面线程安全)。
6. Task的多线程问题
需求:先要将一些date格式的时间数据转换成Long类型的数据,数据如下

(1)工具类为Object
Utils类
object DateUtils { val sdf1 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") def parse1(line: String): Long = { val date: Date = sdf1.parse(line) date.getTime } }
TaskThreadNotSafe01
object TaskThreadNotSafe01 { def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } val sc = new SparkContext(conf) val lines: RDD[String] = sc.textFile(args(1)) // 处理数据 val timeRDD: RDD[Long] = lines.map(line => { val time: Long = DateUtils.parse1(line) time }) val res: Array[Long] = timeRDD.collect() println(res.toBuffer) sc.stop() } }
多次运行,发现有正常运行的情况,也有不能正常运行的情况,不能正常运行的情况报错如下:

原因,多个线程争抢处理一个时间数据,当一个线程正在转换一个数据时(还没转换完),另一个线程任务就开始转换这条数据剩下的部分,这就会导致出错,即线程不安全
解决方法:加锁,如下
object DateUtils { val sdf1 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") //为了避免多个线程同时使用一个SimpleDateFormat出现问题,加锁 def parse1(line: String): Long = synchronized { val date = sdf1.parse(line) date.getTime } //FastDateFormat内部实现了锁机制 val sdf2 = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss") def parse2(line: String): Long = { val date = sdf2.parse(line) date.getTime } }
但是,加锁的话程序运行的效率就不高了,若想提高效率,解决办法:class来代替object
(2)工具类为class
Utils
class DateUtilsClass extends Serializable { val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") def parse(line: String): Long = { val date = sdf.parse(line) date.getTime } }
方式一:在Driver端创建Utils的实例,这种形式可以接受(一个task创建一个对象)
object TaskThreadNotSafe02 { def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } val sc = new SparkContext(conf) //在Driver端被创建的【new一个类的实例】 val dateUtils = new DateUtilsClass val lines = sc.textFile(args(1)) val timeRdd: RDD[Long] = lines.map(line => { val time: Long = dateUtils.parse(line) time }) //触发Action val r = timeRdd.collect() println(r.toBuffer) sc.stop() } }
方式二:在函数内创建Utils的实例,并且使用map来处理数据,这种形式不能接受,效率太低,一条数据就要创建一个对象
object TaskThreadNotSafe02 { def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } val sc = new SparkContext(conf) val lines = sc.textFile(args(1)) val timeRdd: RDD[Long] = lines.map(line => { //在函数内部创键一个实例 val dateUtils = new DateUtilsClass val time: Long = dateUtils.parse(line) time }) //触发Action val r = timeRdd.collect() println(r.toBuffer) sc.stop() } }
方式三:在函数内创建Utils的实例,但是使用mapPartitions来处理数据,这种形式的效率是三种实现中效率最高的(一个executor创建一个对象)
object TaskThreadNotSafe03 { def main(args: Array[String]): Unit = { val isLocal = args(0).toBoolean //创建SparkConf,然后创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getSimpleName) if (isLocal) { conf.setMaster("local[*]") } val sc = new SparkContext(conf) val lines = sc.textFile(args(1)) val timeRdd = lines.mapPartitions(it => { //一个分区new一个DateUtilsClassNoSer工具类 val dateUtils = new DateUtilsClassNoSer it.map(line => { dateUtils.parse(line) }) }) //触发Action val r = timeRdd.collect() println(r.toBuffer) sc.stop() } }