0. 零碎概念
(1)

(2)

此处就算地址写错了也不会报错,因为此操作只是读取数据的操作(元数据),表示从此地址读取数据但并没有进行读取数据的操作
(3)分区(有时间看HaDoopRDD这个方法的源码,用来计算分区数量的)
- 从HDFS指定的目录创建RDD(此处默认的并行数的源码有点问题)
物理切片:实际将数据切分开,即以前的将数据分块(每个数据块的存储地址不一样),hdfs中每个分块的大小为128m
逻辑切片:指的是读取数据的时候,将一个数据逻辑上分成多块(这个数据在地址上并没有分开),即以偏移量的形式划分(各个Task从某个数据的不同位置读取这个数据)
分区数与最小分区数有关,如果最小分区数为1 ,输入切片小于128m,就不在进行逻辑切分多个输入切片了。如果最小分区数为2,有两个文件,一个文件比较大,一个文件比较小,大的文件会被逻辑划分为两个输入切片,即大的文件对应两个分区,小的文件对应一个分区

一般来说,一个文件对应于一个分区数,但是若两个文件的大小相差很大,则一个文件会有2个分区,即将这个大的文件进行了逻辑切片,如下
文件夹下有2个文件:1.txt,words.txt(words.txt比1.txt大很多)

在IDEA中执行wc任务后,日志文件如下,可见words.txt被逻辑切片成了两个分区

如果自己指定的分区数小于输入的切片数,则分区数会默认使用切片数作为分区数
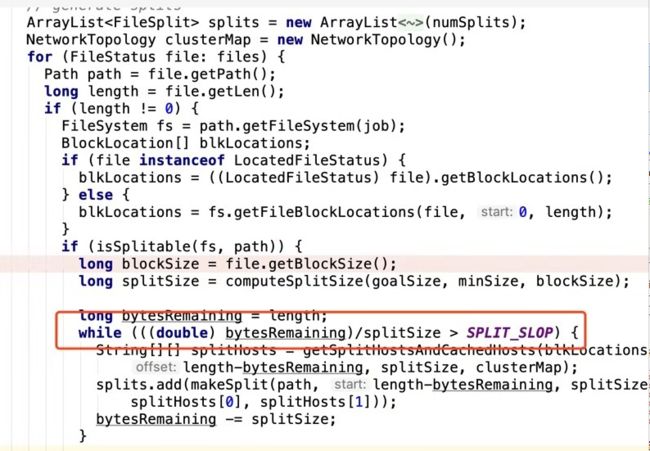
注意:文件进行逻辑切片的条件:
(一个文件的字节数据 / (目录下文件总的字节数 / 最小分区的数量)) > 1.1 就划分多个输入切片
最小分区数一般为2,但当自己设置并行度为1时,则最小分区数为1,原因如下:

![]()
例:
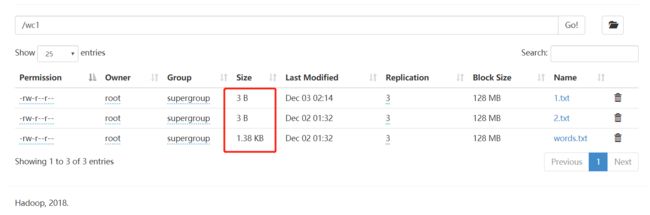
wc1目录中有3个文件,大小如下
代码(用来测试分区数)
object WordCount { def main(args: Array[String]): Unit = { // val conf: SparkConf = new SparkConf().setAppName("WordCount") //往HDFS中写入数据,将程序的所属用户设置成更HDFS一样的用户 System.setProperty("HADOOP_USER_NAME", "root") //Spark程序local模型运行,local[*]是本地运行,并开启多个线程 val conf: SparkConf = new SparkConf() .setAppName("WordCount") .setMaster("local[*]") //设置为local模式执行 // 1 创建SparkContext,使用SparkContext来创建RDD val sc: SparkContext = new SparkContext(conf) // spark写Spark程序,就是对神奇的大集合【RDD】编程,调用它高度封装的API // 2 使用SparkContext创建RDD val lines: RDD[String] = sc.textFile("hdfs://feng05:9000/wc1", 1) println(lines.partitions.length) lines.saveAsTextFile("E:/javafile/wc/out4") // 释放资源 sc.stop() } }
运行结果:3个分区
查看日志文件,如下,发现words.txt没有进行逻辑切片(符合上面逻辑切片发生的条件)

上面自己设定的并行度为1,导致最小分区为1,下面不设置并行度(其他代码同上),即最小分区会变成2,这个时候,按照上面逻辑切分的条件,words.txt会被逻辑切分为两个切片,即最终会得到4个分区,事实也是如此,如下日志文件

如果最小分区数为1 ,输入切片小于128m,就不在进行逻辑切分多个输入切片了,若大于128m,则会被逻辑切分成2个切片(几乎平均切分)
总结:
从hdfs中读取数据创建rdd,其并没有立即读取数据,而是记录以后要从hdfs中某个地址读取数据(读取数据的操作由其调度的task来执行),分区的数量有输入切片来决定。输入切片并不是看到的文件数量以及分块数,而是在读取数据的时候,尽量让每个task读取的数据大小均匀,所以相对大的文件会进行逻辑切片,即输入切片的数目就会增大
- 并行化的方式创建rdd
// 使用parallelize val rdd1 =sc.parallelize(List(1,2,3,4,5,6,7))
此处的并行度与一开始设置的executor-cores有关,若设置为3,则会有3个分区,则会有3个Task
分区和分区器的区别
分区是rdd用来决定spark中task的并行度的,而分区器则是决定上游的数据到下游哪个地方的(类似MR程序中,maptask处理完的数据会被分到下游的哪个reduceTask中)
(3) RDD中的collect
collect相当于将executor计算好的数据收集起来,放置于driver端,以下是具体的

1. RDD的使用
1.1 什么是RDD
RDD(Resilient Distributed Dataset)是一个抽象数据集,RDD中不保存要计算的数据集,保存的是元数据,即数据的描述信息和运算逻辑,比如数据要从哪里去读取,怎么运算等。RDD可以理解为一个代理,你对RDD进行操作,相当于在Driver端先是记录下计算的描述信息,然后生成Task,将Task调度到Executor端才执行真正的计算逻辑
1.2 RDD的特点

- 有一些连续的分区
分区编号从0开始,分区数量决定了对应阶段Task的并行度
- 有一个函数作用在每个输入切片上
每一个分区都会生成一个Task,对该分区的数据进行计算,这个函数就是具体的计算逻辑
- RDD和RDD之间存在一些依赖关系
RDD调用Transformation后会生成一个新的RDD,子RDD会记录父RDD的依赖关系,包括宽依赖(有shuffle)和窄依赖(没有shuffle)

- (可选的)K-V的RDD在shuffle会有分区器,默认使用HashPartioner
- (可选的)如果从HDFS中读取数据,会有一个最优位置:
spark在调度任务之前会读取NameNode的元数据信息,获取数据的位置,移动计算而不是移动数据,这样可以提高计算效率
1.3 RDD的算子分类
- Transformation:即转换算子,调用转换算子会生成一个新的RDD,R=Transfoemation是Lazzy的,不会触发job的执行
- Action:行动算子,调用行动算子会触发job执行,本质上调用了sc.runJob方法,该方法从最后一个RDD,根据其依赖关系,从后往前,划分Stage,生成TaskSet
1.3.1 RDD常用的Transformation算子
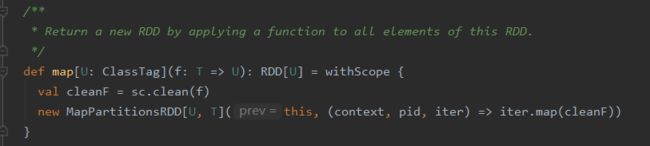
- map算子,功能是做映射
将原数据的每个元素传给函数func进行格式化,返回一个新的分布式数据集。源码如下
测试(spark-shell中测试)

- flatMap算子,先map再压平,spark中没有flatten方法
测试
(1)

此处若将flatMap换成map则会有如下结果
![]()
flat相当于压平操作,外部的Array可比成一个大的气球,里面的各个Array相当于里面的小气球,而flat的操作就是将这些小气球压破,使所有元素都放在外部的气球(Array)中
(2)测试的数据位集合中包含集合(使用了两次flatMap)

此处若将flatMap换成map,则运行的结果为

- filter算子 ,功能为过滤数据

- mapPartitions
将数据以分区的形式返回map操作,一个分区对应一个迭代器,该方法和map方法类似,只不过该方法的参数由RDD中的每一个元素变成了RDD中每一个分区的迭代器,如果在映射的过程中需要频繁创建额外的对象,使用mapPartions要比map高效的多
使用map的话,若是要从数据库中拿数据,则每拿一条数据就要建立一次数据库的连接,比较耗费性能,但mapPartitions则是一个分区建立一次连接,这一个连接可以处理这个分区中的数据

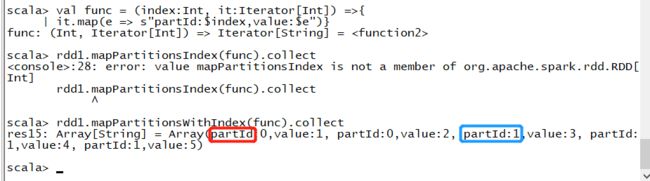
- mapPartitionsWithIndex
类似于mapPartitions,不过函数要输入两个参数,第一个参数为分区的索引,第二个是对应分区的迭代器。函数返回的是一个经过该函数转换的迭代器
- sortBy算子,用来排序

此处若是将函数x=>x改为x=>x+“”,表示的是排序以字符串的形式排
-
sortByKey算子,按照key排序

- groupBy算子,分组,既可以按照key也可以按照值分组

将_1换成_2就是按值排序了
- groupByKey 按照key进行分组
只能按照key排序,不需要参数


hello和flink的hashcode值一样,所以在一个分区中,但不在一个分组中,一个分区可以有多个分组
- reduceByKey
reduceByKey就是对元素为KV对的RDD中Key相同的元素进行binary_function的reduce操作(见action算子部分),因此,Key相同的多个元素的值被reduce为一个值,然后RDD中的Key组成一个新的KV对

groupByKey结合mapValues也能达到此聚合的目的,如下

那么,groupByKey和reduceByKey有什么区别呢?
GroupByKey是直接将数据分组到下游,没有对数据进行处理,加大了shuffle的网络传输,但ReduceByKey则不一样,reduceByKey先是局部聚合再全局聚合,可以减少shuffle网络传输,提高聚合效率,两者的逻辑图如下


- distinct算子,去重
![]()
- union,intersection,subtract


- join,相当于SQL中的内关联

- leftOuterJoin,相当于SQL中的左外关联

- rightOuterJoin,相当于SQL中的右外关联

- fullOuterJoin,相当于SQL中的全关联

- cartesian算子,笛卡尔积

- cogroup算子(用的比较多),协分组,有点跟fullOuterJoin类似,但是没有关联上的返回CompactBuffer()
源码如下

Other,this,that,找个时间看下

- aggregateByKey
按照key进行聚合,跟reduceByKey类似,可以输入两个函数,第一个函数局部聚合,第二个函数全局聚合。初始值自在局部聚合时使用,全局聚合不使用。源码如下
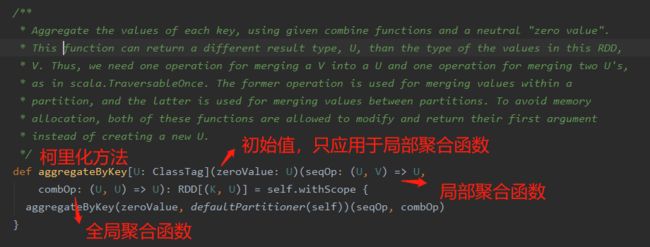
例()


此处有两个分区,第一个分区中分为两个组cat部分和mouse部分,所以第一个分区的cat值为100,mouse也为100,同理第二个分区,所以得到如图所示的结果
- combineByKey
需要输入三个参数,第一个参数为分组后value的第一个元素,第二个参数为局部聚合函数,第三个参数为全局聚合函数

reduceByKey、foldByKey、aggregateByKey、combineByKey底层调用的都是combineByKeyWithClassTag
例1

x=>x:取出分区后各个组中value的第一个元素;(a: Int, b: Int) => a + b :将各个组的值相加,即局部聚合;(m: Int, n: Int) => m + n:此处m表示第一个分区中的值,n为第二个分区中的值,将各个分区中key相同的值相加,即全局聚合
例2

解法如下:
![]()
x=>List(x):将分组后各组中value的第一个元素放入一个List;(a:List[String],b:String) => a:+b:将分组后各组中value的其他元素也加到各自的List中;(m:List[String],n:List[String]) => m ++ n):全局聚合
知识点补充

1.3.2 RDD常用的Action算子
- reduce(binary_function)
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止
与reduce对应的算子是fold,与reduce不同的是reduce可以给一个初始值,此处的初始值在局部聚合和全局聚合都会使用(foldByKey只是在聚不聚合时使用了初始值)

- collect,将数据以数组形式手机回收Driver端,数据按照分区编号有序返回

- count,返回rdd元素的数量

- top 将RDD中数据按照降序(默认降序)或者指定的排序规则,返回前n个数据

- take,返回一个由数据集的前n个元素组成的数组

- first,返回数据集中的第一个元素

- takeOrdered和top类似,默认升序返回

- saveAsTextFile以文本的形式保存到文件系统中
val rdd1 = sc.parallelize(List(3,2,4,1,5), 2) //2个分区 rdd1.saveAsTextFile("hdfs://feng05:9000/haha")
结果查看

- aggregate, 传入两个函数,第一个函数在分区内聚合,第二个全局聚合,可以传初始值,并且初始值在聚不聚he和全局聚合都会被使用

- foreach 将数据一条一条的取出来进行处理,函数没有返回

task是在excutor中执行,此处的spark-shell为Driver端,数据并没有被收集到Driver端,前面能返回数据都是因为executor的数据被收集到Driver端,所以才能被显示,要想看到结果可以去executor的输出日志中看,如下


- foreachPartition, 和foreach类似,只不过是以分区为单位,一个分区对应一个迭代器,应用外部传的函数,函数没有返回值,通常使用该方法将数据写入到外部存储系统中,一个分区获取一个连接,效果更高

若直接打印迭代器,并不会将数据迭代出来,打印的只是迭代器的引用地址,所以使用foreach(迭代器中的foreach)将之遍历出来
2.Spark中的一些重要概念
2.1 Application
使用SparkSubmit提交的计算应用,一个Application中可以触发Action,触发一次Action产生一个Job,一个Application中可以有一到多个Job
Application是Driver在构建SparkContent的上下文的时候创建的, 就想申报员,现在要构建一个能完成任务的集群,需要申报的是这次需要多少个Executor,每个executor需要多少内存,以及所有executor可用的cpu数
2.2 Job
Driver向Executor提交的作业,触发一次Acition形成一个完整的DAG,一个DAG对应一个Job,一个Job中有多个Stage,一个Stage中有多个Task
2.3 DAG
概念:有向无环图(即RDD有方向没有形成闭环,如下图),是对多个RDD转换过程和依赖关系的描述,触发Action就会形成一个完整的DAG,一个DAG对应一个Job

2.4 Stage
概念:任务执行阶段,Stage执行是有先后顺序的,先执行前的,在执行后面的,一个Stage对应一个TaskSet,一个TaskSet中的Task的数量取决于Stage中最后一个RDD分区的数量
2.5 Task
概念:Spark中任务最小的执行单元,Task分类两种,即ShuffleMapTask和ResultTask
Task其实就是类的实例,有属性(从哪里读取数据),有方法(如何计算),Task的数量决定决定并行度,同时也要考虑可用的cores
2.6 TaskSet
保存同一种计算逻辑多个Task的集合,一个TaskSet中的Task计算逻辑都一样,计算的数据不一样