从广义上来讲:数据结构就是
一组数据的存储结构, 算法就是操作数据的方法数据结构是为算法服务的,算法是要作用在特定的数据结构上的。
10个最常用的数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie树
10个最常用的算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
本文总结了20个最常用的数据结构和算法,不管是应付面试还是工作需要,只要集中精力攻克这20个知识点就足够了。
数据结构和算法(一):复杂度、数组、链表、栈、队列的传送门
数据结构和算法(二):递归、排序、通用排序算法的传送门
数据结构和算法(三):二分查找、跳表、散列表、哈希算法的传送门
数据结构和算法(四):二叉树、红黑树、递归树、堆和堆排序、堆的应用的传送门
数据结构和算法(五):图、深度优先搜索和广度优先搜索、字符串匹配算法、Trie树、AC自动机的传送门
数据结构和算法(六):贪心算法、分治算法、回溯算法、动态规划、拓扑排序的传送门
第二十一章 图
首先呢,先思考一个问题,如何存储微博、微信等社交网络中的好友关系呢?
一、什么是图?及图中的几个基础概念
-
-
图跟前边讲的树一样,也是一种非线性表结构,比树更加复杂,树中的元素我们称之为节点,图中的元素就称之为顶点,从下图可以看出,图的顶点可以与任意顶点建立关系,我们把这种关系称之为边(edge)。
 图中的顶点和边
图中的顶点和边
-
-
- 我们可以把微信的好友关系看做一张图,其中每个用户都可以看做一个顶点,用户之间的好友关系就可以看做边,每个用户有多少好友,就叫做顶点的
度,度就是跟顶点相连接的边的条数。
- 我们可以把微信的好友关系看做一张图,其中每个用户都可以看做一个顶点,用户之间的好友关系就可以看做边,每个用户有多少好友,就叫做顶点的
-
- 微博中允许单向关注,也就是用户A关注了用户B,但是用户B没有关注用户A,我们就可以用
有向图,来表示这种关系,如下图所示,我们把有方向的图叫做有向图,没有方向的图叫做无向图。
 有向图
有向图
- 微博中允许单向关注,也就是用户A关注了用户B,但是用户B没有关注用户A,我们就可以用
-
- 在图中,我们把一个顶点有多少条边叫做
度,如果图有方向,就把指向顶点的边数叫做入度,从这个顶点指出去的边叫做出度,如下图所示。对应到微博的例子,入度就表示有多少粉丝,出度就表示关注了多少人。
 度、入度、出度
度、入度、出度
- 在图中,我们把一个顶点有多少条边叫做
-
- QQ中不但记录了好友关系,还记录了亲密度,这种带亲密度的好友关系,我们可以用
带权图来表示,如下图,每条边都有一个权重(weight),可以通过这个权重来表示QQ中的亲密度。
 带权图
带权图
- QQ中不但记录了好友关系,还记录了亲密度,这种带亲密度的好友关系,我们可以用
二、如何在内存中存储图?
方法一:邻接矩阵法
-
- 用连续的内存空间存储图的方法叫做
领接矩阵(Adjacency Matrix),邻接矩阵的底层是二维数组,对无向图来说,如果顶点i和顶点j之间有边,我们就将A[i][j]和A[j][i]标记为1;对于有向图来说,如果顶点i和顶点j之间只有一条从顶点i指向顶点j的边,就只将A[i][j]标记为1;对于带权图来说,数组中存放的是响应的权重。如下图所示:
 邻接矩阵存储法.png
邻接矩阵存储法.png
- 用连续的内存空间存储图的方法叫做
-
- 用邻接矩阵存储图,虽然简单直观,但是比较浪费内存空间。例如在无向图中,如果
A[i][j]等于1,那么A[j][i]也一定等于1,我们存储一个其实就够了,从对角线一份为二,我们只需要存储一半就够了,另一半就浪费了。如下图:
 用邻接矩阵存储无向图有点浪费
用邻接矩阵存储无向图有点浪费
- 用邻接矩阵存储图,虽然简单直观,但是比较浪费内存空间。例如在无向图中,如果
-
- 用邻接矩阵的方法存储图,相当于给所有的顶点之间的关系都预留的内存,但是如果我们是
稀疏图,也就是说,顶点很多,但是每个顶点的边并不多的时候,用邻接矩阵就更加浪费了,例如,微信有好几个亿的用户,但是每个用户的好友并不多,一般也就几百个,对应在图中,就是好几亿个顶点,每个顶点就几百个边,用邻接矩阵来存储的话,绝大部分的空间都被浪费了。
- 用邻接矩阵的方法存储图,相当于给所有的顶点之间的关系都预留的内存,但是如果我们是
-
- 也不是说邻接矩阵存储法完全没有优点,首先,邻接矩阵存储方式简单、直观,基于数组,获取顶点之间的关系非常高效;其次,计算方便,很多图的运算可以转换成矩阵之间的运算,例如求解最短路径问题,就是利用矩阵循环相乘若干次得到结果。
方法二:邻接表存储法
-
-
邻接表的每个顶点对应一条链表,链表中存储的是与此顶点有关系的其他顶点,如下图,就是一个有向图用邻接表法存储的直观展示。
 有向图用邻接表存储
有向图用邻接表存储
-
-
- 相比于邻接矩阵存储,邻接表存储更节省内存,但是使用起来比较耗时,例如,想知道顶点2与顶点4之间是否存在关系,就需要遍历顶点2所对应的的链表。我们也可以仿照前边处理散列冲突的方式,来处理遍历链表所带来的的耗时问题,将链表替换成跳表或者红黑树,这样查找的时间复杂度就从O(n)变成了O(logn)了。
三、如何在存储微博中的社交关系呢?
-
-
社交网络是一个稀疏图,用邻接矩阵法存储比较浪费时间,所以应该采用邻接表法来存储,但是用一个邻接表只能表示用户关注了谁,无法知道粉丝列表,所以我们还需要一个逆邻接表,来存放粉丝,也就是存放指向这个定向的边,如下图:
 邻接表和逆邻接表
邻接表和逆邻接表
-
-
- 用链表的话时间复杂度是O(n),所以我们应该将链表替换成跳表或者红黑树等动态数据结构,由于微博中需要按照用户首字母排序,所以我们可以使用跳表,跳表的插入、查找、删除的时间复杂度都是O(logn)非常高效,同时跳表中的数据都是有序的,分页获取粉丝列表或者关注列表也很高效。
-
-
微博拥有好几亿的用户,一台机器的内存肯定是不够的,我们可以用过哈希算法进行数据分片,将邻接表存放到不同机器上。可以这样处理:对数据进行哈希得到哈希值,再用这个哈希值和机器总数取模,得到机器编号,将这个数据的邻接表放到这台机器上就可以了。
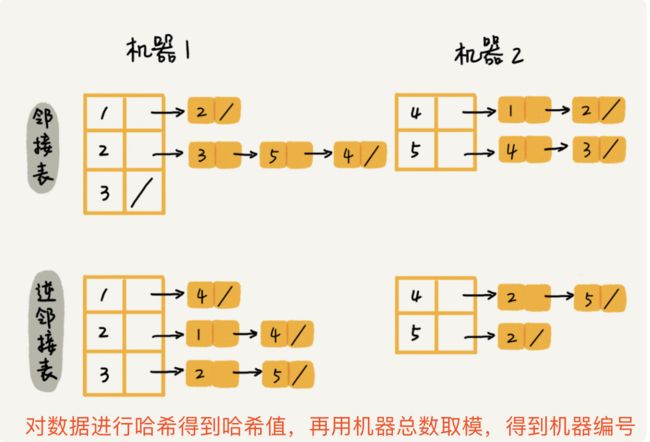 用哈希算法进行数据分片
用哈希算法进行数据分片
-
-
- 我们还可以利用外部存储来持久化存储数据,例如使用数据库,并建立多级索引。
第二十二章 深度优先搜索和广度优先搜索
一、什么是搜索算法
-
- 算法是作用在具体数据结构上的,深度优先搜索和广度优先搜索算法都是作用于图这种数据结构上的,这是因为图的表达能力很强,大部分涉及搜索的场景都可以抽象成“图”。
-
- 图的搜索算法,其实在图上找出从一个顶点到另一个顶点的路径,今天介绍两种最简单、最暴力的搜索算法:
广度优先搜索(Breadth-First-Search)和深度优先搜索(Depth-First-Search)
- 图的搜索算法,其实在图上找出从一个顶点到另一个顶点的路径,今天介绍两种最简单、最暴力的搜索算法:
二、BFS-广度优先搜索(Breadth-First-Search)
-
-
广度优先搜索,其实就是地毯式的层层递进策略,即先查找最近的顶点,再找次近的,依次往外搜索,如下图:
 广度优先搜索
广度优先搜索
-
-
- 用Swift代码实现,如下
//单链表
class SingleLinkedList{
var headNode: SingleLinkedNode?
var nodeMap: Dictionary?
var nodeCount: Int = 0
//插入一个节点
func insertNode(node: SingleLinkedNode){
nodeMap?.updateValue(node, forKey: node.key)
nodeCount = nodeCount + 1
if headNode == nil{
headNode = node
}else{
lastNode().next = node
}
}
//获取一个节点
func lastNode() -> SingleLinkedNode{
var node = headNode
while node?.next != nil {
node = node?.next
}
if node != nil{
return node!
}else{
return SingleLinkedNode(key: "error", value: "error")
}
}
//根据key获取节点
func getNode(key: String) -> SingleLinkedNode?{
return nodeMap?[key]
}
//删除node的下一个节点
func deleteNode(_ node: SingleLinkedNode){
if (nodeMap?[node.key] ?? SingleLinkedNode(key: "", value: "")) == node{
nodeCount = nodeCount - 1
node.next = node.next?.next
}else{
print("该节点不存在")
}
}
func size() -> Int{
return nodeCount
}
}
//单链表的节点
class SingleLinkedNode: Equatable{
static func == (lhs: SingleLinkedNode, rhs: SingleLinkedNode) -> Bool {
if lhs.key == rhs.key && lhs.value == rhs.value && lhs.next == rhs.next{
return true
}
return false
}
var key:String = "-1"
var value: String?
var next: SingleLinkedNode?
init(key: String,value: String) {
self.key = key
self.value = value
}
}
//先入先出的顺序队列
class Queue{
private var array: Array = Array()
//入队
func enqueue(_ e: T){
array.append(e)
}
//出队
func dequeue() -> T?{
if let first = array.first{
array.remove(at: 0)
return first
}
return nil
}
func size() -> Int{
return array.count;
}
}
let queue = Queue()
queue.enqueue(11)
queue.enqueue(2)
queue.enqueue(333)
let testQueue1 = queue.dequeue()
let testQueue2 = queue.dequeue()
let testQueue3 = queue.dequeue()
//无向图
class Graph{
private var peakCount: Int = 0 //顶点的个数
private var linkedArray = Array() //单链表的数组
//初始化
init(peakCount: Int) {
self.peakCount = peakCount
let linkedList = SingleLinkedList()
self.linkedArray = Array(repeating: linkedList, count: self.peakCount)
}
//增加一条边(无向图一条边需要存两次)
func addEdge(s: Int,t: Int){
let nodeT = SingleLinkedNode(key:"\(t)" ,value: "\(t)")
let nodeS = SingleLinkedNode(key: "\(s)", value: "\(s)")
linkedArray[s].insertNode(node: nodeT)
linkedArray[t].insertNode(node: nodeS)
}
// 广度优先搜索 从顶点开始 寻找到t顶点的路径 打印出来
func bfs(start_s: Int,target_t: Int){
//如果起点等于重点 直接return
if start_s == target_t {
return
}
//已经访问过的顶点
var visited = Array()
//先入先出的队列,负责存储已经被访问过但其相连的顶点还没有访问的顶点
let queue = Queue()
//将第一个顶点s加入队列
queue.enqueue(start_s)
//记录搜索路径
var recordSearchPath = Array(repeating: -1, count: peakCount)
while(queue.size() != 0){
//当前顶点
let currentPeak = queue.dequeue() ?? 0
for i in 0.. -
- 广度优先搜索最坏情况下,终止顶点t与起始顶点s相距很远,需要遍历整个图才能找到,每个顶点都要进队列一次,每条边也都要被访问一次,所以广度优先搜索的时间复杂度是O(V+E),V代表顶点数量,E代表边的数量;对于一个连通图来说,图中的所有顶点都是连通的,E肯定大于等于V-1,所以广度优先搜索的时间复杂度也可以简写为O(E),E代表边数。
-
- 广度优先搜索的空间消耗主要在几个辅助变量上,辅助变量的存储空间的大小不过超过顶点的个数,所以空间复杂度是O(V),V代表顶点数。
三、DFS-深度优先搜索(Depth-First-Search)
-
-
深度优先搜索,其实就是走迷宫,你站在岔路口上,选择一条路往下走,走着走着发现走不通了,就退回到上一个岔路口,重新选择一条路继续走,按照这种策略,一直走下去,直到找到出口为止。如下图:
 深度优先搜索策略
深度优先搜索策略
-
-
- 用Swift代码实现,如下
-
- 从上图中可以看出,按照深度优先搜索策略,每条边最多会被访问2次,一次是遍历,一次是回退,所以深度优先搜索的时间复杂度是O(E),E代表边数
-
- 从代码可以看出,深度优先搜索的内存消耗跟顶点的个数成正比,所以空间复杂度为O(V),V代表顶点数。
第二十三章 字符串匹配基础
字符串匹配算法分为单模式串匹配和多模式串匹配。单模式匹配,即一个串和另一个串进行匹配,例如:BF算法、RK算法、BM算法、KMP算法;也有多模式串匹配,即在一个串中同时查找多个串,例如:Tire树。
一、BF算法
-
- BF算法的BF是Brute Force的缩写,中文叫做暴力匹配算法,从名字就可以看出,这种算法简单、暴力、好懂,相应的性能也不高。
-
- 这里有两个概念必须先弄懂:主串和模式串,我们在字符串A中查找字符串B,A就是主串,B就是模式串。我们把主串的长度记为n,模式串长度记为m,因为在主串中查找模式串,主串肯定比模式串长,n>m.
-
- BF的核心思想是:在主串中,检查起始位置分别是0、1、2...n-m且长度为m的n-m+1个子串,看有没有和模式串匹配的。例如下图所示
 BF核心思想.png
BF核心思想.png
- BF的核心思想是:在主串中,检查起始位置分别是0、1、2...n-m且长度为m的n-m+1个子串,看有没有和模式串匹配的。例如下图所示
-
- 极端情况下,BF需要匹配n-m+1次,每次匹配m个字符,所以最坏时间复杂度为O(n*m)
二、RK算法
-
- RK算法的全称是Rabin-Karp算法,是BF算法的升级版,RK算法在BF算法的基础上,引入了哈希算法,降低了时间复杂度。
-
- RK算法的思想是这样的:我们通过哈希算法对主串中的n-m+1个子串求哈希值,然后逐个与模式串的哈希值比较,如果相同就证明匹配成功了。(如果出现哈希冲突,可以将哈希值相同的两个串,在进行一次逐个字符的比较)
-
- 整个RK算法可以分为两部分:计算子串的哈希值、模式串的哈希值与子串哈希值进行比较。我们可以通过设计巧妙的哈希算法,使得扫描一次主串就可以得到所有子串的哈希值,这部分的时间复杂度为O(n);哈希值之间的比较的时间复杂度是O(1),需要比较n-m+1次,所以这部分的时间复杂度也是O(n),所以整体RK算法的时间复杂度是O(n)。
三、BM算法
-
- BM算法是一种非常高效的字符串匹配算法,其性能是著名的KMP算法的3~4倍。
-
-
前边讲的匹配算法都是像下图一样,将模式串一位一位的往前移动,与主串的子串进行一次一次的对比进行查找的,而BM算法就第二个图一样,为了提高查找效率,找出了移动规律,按照规律跳着往后移动,例如:发现c与d不匹配了,就将模式串往后移动三位。
 模式串一位一位往后移动
模式串一位一位往后移动
 BM找到了移动规律,可以移动多位
BM找到了移动规律,可以移动多位
-
-
- BM算法发现移动规律有两个:坏字符规则和好后缀规则
-
- 坏字符规则
- (1). 我们从模式串的末尾往前倒着匹配,当我们发现某个字符没法匹配时,我们就把这个字符叫做坏字符。
 坏字符.png
坏字符.png - (2). 如果坏字符在模式串中存在,那么我们就把怀字符对应的模式串中的这个字符的下标记做
xi,如果怀字符在模式串中不存在,我们就把xi记作-1;我们把怀字符对应在模式串中的字符的下标记做si;规律就是:模式串往后移动的位置就等于si-xi。如下图所示:
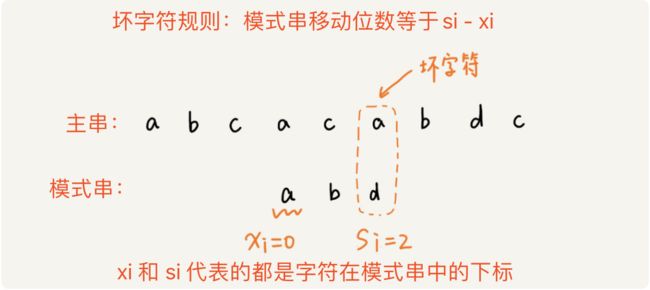 坏字符规则移动位数
坏字符规则移动位数
-
- 好后缀规则
-
(1). 我们把主串中和模式串相匹配的字符,称之为好后缀,如下图:
 好后缀
好后缀 - (2). 我们把好后缀
bc记做{u},拿{u}在模式串中查找,如果找到了另一个跟{u}相匹配的子串{u*},我们就将模式串滑动到子串{u*}跟主串中{u}对齐的位置,如下图:
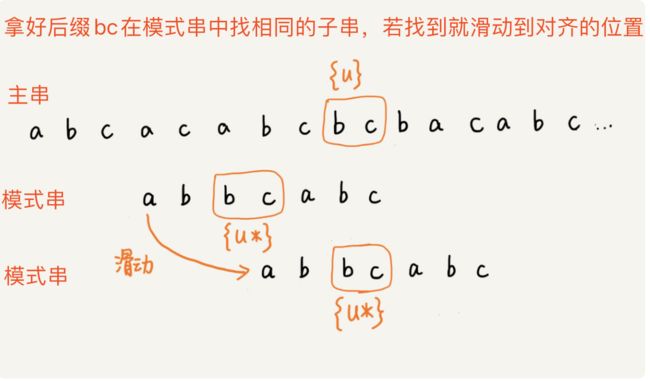 找到与好后缀相同的子串,则滑动对齐
找到与好后缀相同的子串,则滑动对齐 - (3). 如果在模式串中找不到另一个与
{u}相匹配的子串,我们还得考察好后缀的后缀子串,是否存在跟模式串的前缀子串相匹配。如果好后缀的后缀子串跟模式串的前缀子串相匹配,则将模式串滑动到对齐的位置,如下图:
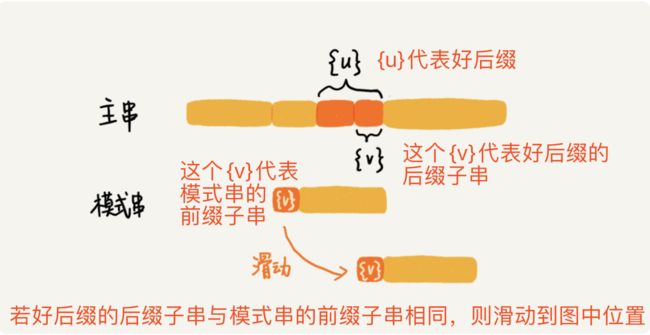 滑动模式串到图中位置
滑动模式串到图中位置 - (4). 如果好后缀的后缀子串与模式串的前缀子串不匹配,则直接将模式串滑动到主串的好后缀
{u}的后面,如下图:
 {u}代表好后缀
{u}代表好后缀
-
- 当模式串和主串中的某个字符不匹配时,我们该如何选择使用坏字符规则还是好后缀规则呢?我们可以分别计算坏字符规则和好后缀规则往后移动的位数,然后取两个数最大的,作为模式串往后移动的位数。
第二十四章 Trie树
一、什么是Trie树
-
- Trie树,也叫字典树,顾名思义,是一种树形结构,专门用来处理字符串匹配,经常用来解决在一组字符串集合中快速查找某个字符串的问题。
-
-
Trie树的本质就是,利用字符串之间的公共前缀,将重复的前缀组合在一起,就像下图一样:
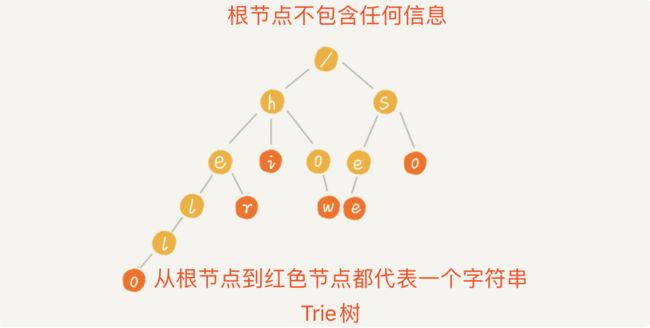 Trie树
Trie树
-
-
-
利用how、hi、her、hello、so、see等字符串构造一颗Trie树,过程如下图所示:
 构造一颗Tire树
构造一颗Tire树
-
二、如何实现一颗Trie树?
-
- Trie树主要有两个操作:将字符串集合构造成Trie树、在Trie树中查找一个字符串
-
-
Trie树是一个多叉树,可以通过下标和字符一一对应的数组,来存储子节点的指针,如下图所示:
 Trie树的存储
Trie树的存储
-
-
- 一个Trie树的结点,用代码可以这么写:
class TrieNode{
var data: Character? //存放一个字符,例如:“h”
var childArray: [TrieNode]? //存放子节点指针的数组,例如:存放以h开头的字符的子节点的指针
}
-
- 想在一组字符串中频繁的查找一个字符串,使用Trie树解决就会非常高效,过程分为构建Tire树和查找该字符串。构建Trie树的过程需要扫描所有字符串,时间复杂度是O(n),
n代表所有字符串的长度之和,一旦构建Trie树成功,后续查询就会非常高效,如果要查询的字符串长度为k,那么我们只需要对比大约k个节点,就可以完成操作,时间复杂度为O(k),k表示要查找的字符串的长度。
- 想在一组字符串中频繁的查找一个字符串,使用Trie树解决就会非常高效,过程分为构建Tire树和查找该字符串。构建Trie树的过程需要扫描所有字符串,时间复杂度是O(n),
-
- Trie树比较消耗内存,是一种空间换时间的思路,用数组存放子节点的指针,我们知道存放一个字符需要1个字节,而存放26个字母的指针,需要26*8=208个字节,额外占用了208个字节,这还只是26个字母的情况。我们可以将数组换成有序数组、跳表、散列表、红黑树等数据结构,来节省内存的消耗。
三、Trie树与散列表、红黑树的比较
-
- 如果想要在一组字符串中精确查找某个字符串,一般建议使用散列表或者红黑树。
-
- Trie树的优势不在于动态集合数据的查找,而在于查找前缀匹配的字符串,例如:搜索引擎中的关键词提示功能、输入法自动补全功能、IDE代码编辑器自动补全功能等。