页的结构
页是一种InnoDB管理存储空间的基本单位,它一般大小在16kb左右。实际上存在着许多不同类型的页,我们这次主要介绍的页是用来存储数据的,也叫做索引页。
接下来看看索引页的结构图:
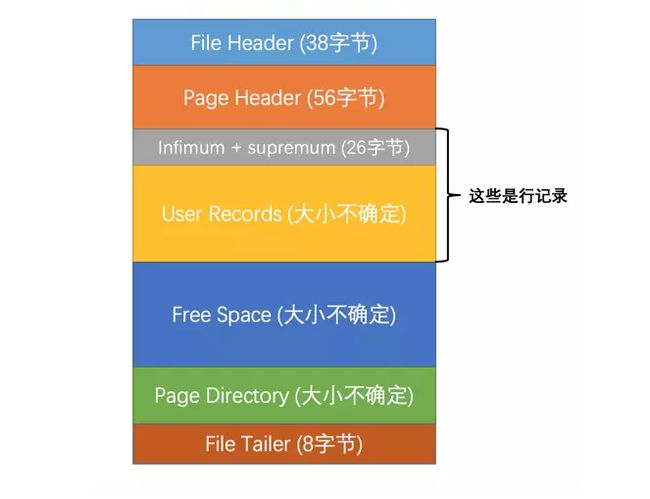
比较重要的有三块区域:
- Infimum + supremum
- User Records
- Page Directory
很明显里面叫User Records的空间就是储存行记录的地方,而Free Space其实就是页中尚未使用的空间,其他两个区域后面会解释到。
记录在页中的存储
先来回顾下简化版的行记录结构:
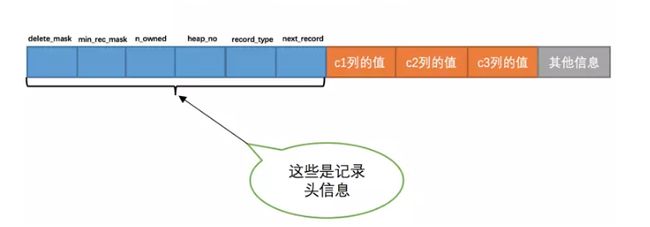
这其中c1,c2,c3就是真实的数据,头信息在页中发挥着至关重要的作用:
- delete_mask: 删除标识,标识这行记录是否被删除
- min_rec_mask:这个可以暂时先不管,属于索引的内容
- n_owned: 稍后会提及
- heap_no:表示记录在本页中的位置,注意这个字段的起始值是2。那么0和1呢?InnoDB会自动给每个页增加两个记录,一个代表最大记录,一个代表最小记录。还记得前面的Infimum + supremum空间吗?就是用来存这两个记录的。
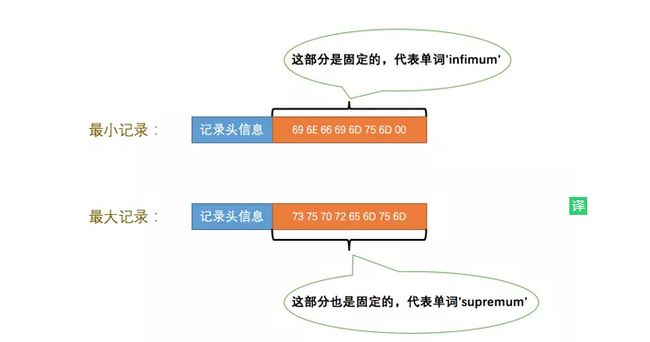
所以一个页中所有的记录都是按照主键大小的顺序排列的(这很重要) - record_type:表示当前记录的类型,也可以暂时不管
- next_record:这个字段标识了从当前记录的真实数据到下一条记录的真实数据的地址偏移量。
总结一下,实际上通过heap_no和next_record,就把页中的所有记录按照主键值的大小串成了一个有序的单链表。
Page Directory(页目录)
现在我们知道了所有的记录都会被串成一个有序的单链表,如果我们想查找某条记录,只需要将链表遍历过去就可以了。但是毫无疑问这样的效率是十分低下的,那么在Innodb中是如何作优化的呢?
优化的过程如下:
所有的记录会被分成几组,这包括前面所说的最大最小记录
其中最小记录所在的组只能有一条记录也就是它自己,最大记录所在的分组拥有的记录条数只能在 1~8 条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间
- 每组的最后一条记录(也就是主键值最大的一条记录)头信息中的n_owned属性表示该记录拥有多少条记录,也就是该组内共有几条记录。
每组的最后一条记录的地址会被单独提取出来,按照顺序存在页的尾部,其实就是我们前面所说的页目录的地方。每个地址的偏移量在Innodb中被称为插槽
按照上面的规则,我们可以得到这么一副图:

可以看到有两个插槽,意味着被分为了两组,其中:
- 最小记录的n_owned值为1,这就代表着以最小记录结尾的这个分组中只有1条记录,也就是最小记录本身。
- 最大记录的n_owned值为5,这就代表着以最大记录结尾的这个分组中只有5条记录,包括最大记录本身还有我们自己插入的4条记录。
说了这么多条条框框,这对于加快查找又有什么用呢?别着急现在就来揭晓如何使用。
为了更明显的看出区别,我们多加几条记录,并且逻辑上调整了下结构,便于理解:
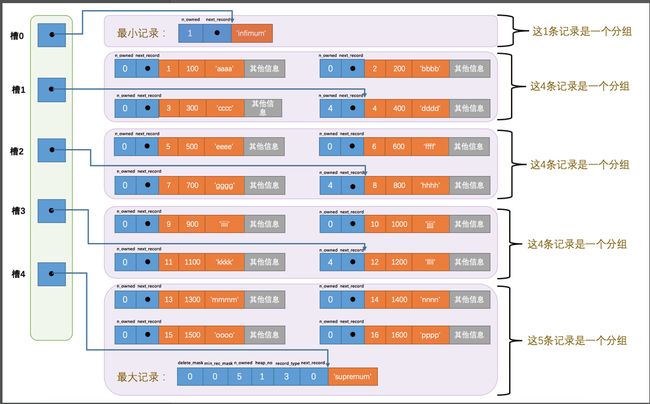
现在我们就可以利用二分法来查找,比如说我们想找主键值为10的记录,过程是这样的:
计算中间槽的位置:(0+4)/2=2,所以查看槽2对应记录的主键值为8,又因为8 < 10,所以设置low=2,high保持不变。
重新计算中间槽的位置:(2+4)/2=3,所以查看槽3对应的主键值为12,又因为12 > 10,所以设置high=3,low保持不变。
因为high - low的值为1,所以确定主键值为10的记录在槽3对应的组中。此刻我们需要找到槽3中主键值最小的那条记录,然后沿着单向链表遍历槽3中的记录。
怎么定位一个组中最小的记录呢?我们可以很轻易的拿到槽2对应的记录(主键值为8),该条记录的下一条记录就是槽3中主键值最小的记录,该记录的主键值为9。所以我们可以从这条主键值为5的记录出发,遍历槽3中的各条记录,直到找到主键值为6的那条记录即可。
由于前面规定了一个组中包含的记录条数只能是1~8条,所以遍历一个组中的记录的代价是很小的。
所以总结一下在一个页中查找指定主键值的记录的过程分为两步:
通过二分法确定该记录所在的插槽,并找到该插槽中主键值最小的那条记录。
通过记录的next_record属性遍历该槽所在的组中的各个记录。
可以看到在这种情况下,通过分组设置和二分法的配合查询,会比之前直接单链表遍历的方法快太多了。