
前面我们了解了Transaction的定义和它的创建及初始化过程,其中涉及到了根Bucket的创建。Transaction主要是对Bucket进行创建、查找、删除等操作,Bucket可以嵌套形成树结构,故Transaction对Bucket的操作均从根Bucket开始进行的。BoltDB中所有的K/V记录或者page均通过Bucket组织起来,且一个Bucket内的所有node形成一颗B+Tree。我们先来看看Bucket的定义:
//boltdb/bolt/bucket.go
// Bucket represents a collection of key/value pairs inside the database.
type Bucket struct {
*bucket
tx *Tx // the associated transaction
buckets map[string]*Bucket // subbucket cache
page *page // inline page reference
rootNode *node // materialized node for the root page.
nodes map[pgid]*node // node cache
// Sets the threshold for filling nodes when they split. By default,
// the bucket will fill to 50% but it can be useful to increase this
// amount if you know that your write workloads are mostly append-only.
//
// This is non-persisted across transactions so it must be set in every Tx.
FillPercent float64
}
// bucket represents the on-file representation of a bucket.
// This is stored as the "value" of a bucket key. If the bucket is small enough,
// then its root page can be stored inline in the "value", after the bucket
// header. In the case of inline buckets, the "root" will be 0.
type bucket struct {
root pgid // page id of the bucket's root-level page
sequence uint64 // monotonically incrementing, used by NextSequence()
}
Bucket的各字段定义如下:
- *bucket: Bucket的头,其定义中的root是指Bucket根节点的页号,sequence是一个序列号,可以用于Bucket的序号生成器。这里稍微解释一下,Go中类型定义中未指明成员名称,则该成员是一个隐含成员,成员的成员以及与其绑定的方法可以被外层类型的变量直接访问或者调用,相当于通过组合的方式让外层内型"继承"了隐含成员的类型;
- tx: 当前Bucket所属的Transaction。请注意,Transaction与Bucket均是动态的概念,即内存中的对象,Bucket最终表示为BoltDB中的K/V记录,这将在后面看到;
- page: 内置(inline)Bucket的页引用,内置Bucket只有一个节点,即它的根节点,且节点不存在独立的页面中,而是作为Bucket的Value存在父Bucket所在页上,页引用就是指向Value中的内置页,我们将在分析Bucket创建时进一步说明;
- rootNode: Bucket的根节点,也是对应B+Tree的根节点;
- nodes: Bucket中的node集合;
- FillPercent: Bucket中节点的填充百分比(或者占空比)。该值与B+Tree中节点的分裂有关系,当节点中Key的个数或者size超过整个node容量的某个百分比后,节点必须分裂为两个节点,这是为了防止B+Tree中插入K/V时引发频繁的再平衡操作,所以注释中提到只有当确定大数多写入操作是向尾添加时,这个值调大才有帮助。该值的默认值是50%;
介绍完Bucket的定义后,为了让大家对Bucket及它在整个DB中的作用有个直观的认识,我们先来看一看BoltDB的画像:
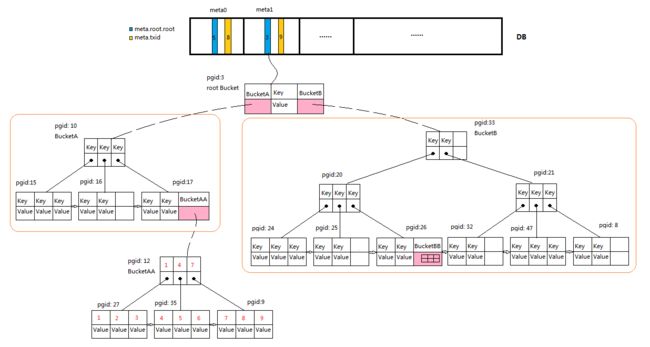
图中展示了5个Bucket: root Bucket、BucketA、BucketB、BucketAA及BucketBB。除root Bucket外,其余4个Bucket均由粉色区域标注。BucketA与BucketB是root Bucket的子Bucket,它们嵌套在root Bucket中; BucketAA是BucketA的嵌套子Bucket,BucketBB是BucketB的嵌套子Bucket,而且BucketBB是一个内置Bucket。嵌套Bucket形成父子关系,从而所有Bucket形成树结构,通过根Bucket可以遍历所有子Bucket,但是请注意,Bucket之间的树结构并不是B+Tree,而是一个逻辑树结构,如BucketBB是BucketB的子Bucket,但并不是说BucketBB所在的节点就是BucketB所在节点的子节点。从图中也可以看出,我们在《区块的持久化之BoltDB(二)》介绍的Transaction初始化时,从meta中读取根Bucket头就是为了找到根Bucket所在页,进而从页中读出根Bucket的根节点。
每一个Bucket都对应一颗B+Tree,Bucket结构中的rootNode指向根节点。需要说明的是,B+Tree的有些定义有争议: 如通过阶还是度来标识,度是指节点中最大或者最小的Key的数量还是子节点的数量,以及内节点或根节点中Pointer的数量是Key的数量加1还是等于Key的数量等等。在BoltDB中,内节点或根节点中Pointer的数量等于Key的数量,即子节点的个数与Key的数量相等。在我们的表述中,为了避免混淆,统一通过如下四个参数描述B+Tree: (每节点中Key的数量最大值,每节点中Pointer的数量最大值,每节点中Key的数量最小值,节点填充率)。对应地,我们图中的B+Tree的参数即是(3, 3, 1, 100%),为了便于说明,图中节点的填充率为100%,且一个节点中最多只有3个K/V对;请注意,BoltDB的实现上默认节点填充率是50%,而且节点中Key的数量的最大值和最小值是根据页大小与Key的size来动态决定的。对于不熟悉B+Tree的读者,可以对照BucketAA对应的B+Tree(图中左下角)来理解一下。为了便于说明有序关系,树中的Key均通过数字表示。从图中可以看出,实际的K/V对均保存在叶子节点中,节点中的K/V对按Key的顺序有序排列。父节点中只有Key和Pointer,没有Value,Pointer指向子节点,且Pointer对应的Key是它指向的子节点中最小Key值。父节点中的Key也按顺序排列,所以其子节点之间也是按顺序排列的,所有子节点会形成有序链表。图中的B+Tree上,当我们要查找Key为6的记录时,先从左至右查找(或者通过二分法查找)根节点的Key值,发现6大于4且小于7,那么可以肯定Key为6的记录位于Key为4对应的子节点上,因此进入对应的子节点查找,按相同的查找方法(从左至右或者二分法查找)查找Key为6的记录,最多经过三次比较后就可以找到。同时,在B+Tree中,一个节点中的Key的数量如果大于节点Key数量的最大值 x 填充率的话,节点会分裂(split)成两个节点,并向父节点添加一个Key和Pointer,添加后如果父节点也需要分裂的话那就进行分裂直到根节点;为了尽量减少节点分裂的情况,可以对B+Tree进行旋转(rotation)或者再平衡(rebalance):如果一个节点中的Key的数量小于设定的节点Key数量的最小值的话,那就将其兄弟节点中的Key移动到该节点,移动后产生的空节点将被删除,直到所有节点满足Key数量大于节点Key数量最小值。
如果被B+Tree的描述弄得有点头晕的话,上面的图我们先放一放,这里只关注Bucket的结构和B+Tree的大致结构即可,我们后面还会解释该图。接下来,我们继续从《区块的持久化之BoltDB(一)》中给的BoltDB典型应用示例中的tx.CreatBucket()入手来介绍Bucket的创建过程:
//boltdb/bolt/tx.go
// CreateBucket creates a new bucket.
// Returns an error if the bucket already exists, if the bucket name is blank, or if the bucket name is too long.
// The bucket instance is only valid for the lifetime of the transaction.
func (tx *Tx) CreateBucket(name []byte) (*Bucket, error) {
return tx.root.CreateBucket(name)
}
它实际上是通过tx的根Bucket来创建新Bucket的:
//boltdb/bolt/bucket.go
// CreateBucket creates a new bucket at the given key and returns the new bucket.
// Returns an error if the key already exists, if the bucket name is blank, or if the bucket name is too long.
// The bucket instance is only valid for the lifetime of the transaction.
func (b *Bucket) CreateBucket(key []byte) (*Bucket, error) {
......
// Move cursor to correct position.
c := b.Cursor() (1)
k, _, flags := c.seek(key) (2)
......
// Create empty, inline bucket.
var bucket = Bucket{ (3)
bucket: &bucket{},
rootNode: &node{isLeaf: true},
FillPercent: DefaultFillPercent,
}
var value = bucket.write() (4)
// Insert into node.
key = cloneBytes(key) (5)
c.node().put(key, key, value, 0, bucketLeafFlag) (6)
// Since subbuckets are not allowed on inline buckets, we need to
// dereference the inline page, if it exists. This will cause the bucket
// to be treated as a regular, non-inline bucket for the rest of the tx.
b.page = nil (7)
return b.Bucket(key), nil (8)
}
在CreateBucket()中:
- 代码(1)处为当前Bucket创建游标;
- 代码(2)处在当前Bucket中查找key并移动游标,确定其应该插入的位置;
- 代码(3)处创建一个空的内置Bucket;
- 代码(4)处将刚创建的Bucket序列化成byte slice,以作为与key对应的value插入B+Tree;
- 代码(5)处对key进行深度拷贝以防它引用的byte slice被回收;
- 代码(6)处将代表子Bucket的K/V插入到游标位置,其中Key是子Bucket的名字,Value是子Bucket的序列化结果;
- 代码(7)处将当前Bucket的page字段置空,因为当前Bucket包含了刚创建的子Bucket,它不会是内置Bucket;
- 代码(8)处通过b.Bucket()方法按子Bucket的名字查找子Bucket并返回结果。请注意,这里并没有将刚创建的子Bucket直接返回而是通过查找的方式返回,大家可以想一想为什么?
上述代码涉及到了Bucket的游标Cursor,为了理解Bucket中的B+Tree的查找过程,我们先来看一看Cursor的定义:
//boltdb/bolt/cursor.go
// Cursor represents an iterator that can traverse over all key/value pairs in a bucket in sorted order.
// Cursors see nested buckets with value == nil.
// Cursors can be obtained from a transaction and are valid as long as the transaction is open.
//
// Keys and values returned from the cursor are only valid for the life of the transaction.
//
// Changing data while traversing with a cursor may cause it to be invalidated
// and return unexpected keys and/or values. You must reposition your cursor
// after mutating data.
type Cursor struct {
bucket *Bucket
stack []elemRef
}
......
// elemRef represents a reference to an element on a given page/node.
type elemRef struct {
page *page
node *node
index int
}
Cursor的各字段意义如下:
- bucket: 要搜索的Bucket的引用;
- stack: 它是一个slice,其中的元素为elemRef,用于记录游标的搜索路径,最后一个元素指向游标当前位置;
elemRef的各字段意义是:
- page: elemRef所代表的page的引用;
- node:elemRef所代码的node的引用;
- index:page或node中元素的索引;
elemRef实际上指向B+Tree上的一个节点,节点有可能已经实例化成node,也有可能是未实例化的page。我们前面提到过,Bucket是内存中的动态对象,它缓存了node。Cursor在遍历B+Tree时,如果节点已经实例化成node,则elemRef中的node字段指向该node,page字段为空;如果节点是未实例化的page,则elemRef中的page字段指向该page,node字段为空。elemRef通过page或者node指向B+Tree的一个节点,通过index进一步指向节点中的K/V对。Cursor在B+Tree上的移动过程就是将elemRef添加或者移除出stack的过程。
前面我们介绍过page的定义,现在我们看看node的定义:
//boltdb/bolt/node.go
// node represents an in-memory, deserialized page.
type node struct {
bucket *Bucket
isLeaf bool
unbalanced bool
spilled bool
key []byte
pgid pgid
parent *node
children nodes
inodes inodes
}
......
// inode represents an internal node inside of a node.
// It can be used to point to elements in a page or point
// to an element which hasn't been added to a page yet.
type inode struct {
flags uint32
pgid pgid
key []byte
value []byte
}
type inodes []inode
node中各字段意义如下:
- bucket:指向node所属的Bucket;
- isLeaf: 当前node是否是一个叶子节点,与page中的flags对应;
- unbalanced: 指示当前node是否需要再平衡,如果unbalanced为true,则需要对它进行重平衡;当节点中有K/V对被删除时,该值设为true;
- spilled: 指示当前node是否已经溢出(spill),node溢出是指当node的size超过页大小,即一页无法存node中所有K/V对时,节点会分裂成多个node,以保证每个node的size小于页大小,分裂后产生新的node会增加父node的size,故父node也可能需要分裂;已经溢出过的node不需要再分裂;
- key: node的key或名字,它是node中第1个K/V对的key;
- pgid: 与node对应的页框的页号;
- parent: 父节点的引用,根节点的parent是空;
- children: 当前节点的孩子节点;
- inodes: 一个inode的slice,记录当前node中的K/V;
inode中各字段的意义是:
- flags: 指明该K/V对是否代表一个Bucket,如果是Bucket,则其值为1,否则为0;
- pgid: 根节点或内节点的子节点的pgid,可以理解为Pointer,请注意,叶子节点中该值无意义;
- key:K/V对的Key;
- value: K/V对的Value,请注意,非叶子节点中该值无意义;
在《区块的持久化之BoltDB(二)》中,我们介绍过node的序列化过程,即write(p *page)方法,为了进一步理解node各字段及其与page的对应关系,我们来看看它的反序列化方法read(p *page):
//boltdb/bolt/node.go
// read initializes the node from a page.
func (n *node) read(p *page) {
n.pgid = p.id
n.isLeaf = ((p.flags & leafPageFlag) != 0)
n.inodes = make(inodes, int(p.count))
for i := 0; i < int(p.count); i++ {
inode := &n.inodes[i]
if n.isLeaf {
elem := p.leafPageElement(uint16(i))
inode.flags = elem.flags
inode.key = elem.key()
inode.value = elem.value()
} else {
elem := p.branchPageElement(uint16(i))
inode.pgid = elem.pgid
inode.key = elem.key()
}
_assert(len(inode.key) > 0, "read: zero-length inode key")
}
// Save first key so we can find the node in the parent when we spill.
if len(n.inodes) > 0 {
n.key = n.inodes[0].key
_assert(len(n.key) > 0, "read: zero-length node key")
} else {
n.key = nil
}
}
node的实例化过程为:
- node的pgid设为page的pgid;
- node的isLeaf字段由page的flags决定,如果page是一个leaf page,则node的isLeaf为true;
- 创建inodes,其容量由page中元素个数决定;
- 接着,向inodes中填充inode。对于leaf page,inode的flags即为page中元素的flags,key和value分别为page中元素对应的Key和Value;对于branch page,inode的pgid即为page中元素的pgid,即子节点的页号,key为page元素对应的Key。node中的inode与page中的leafPageElement或branchPageElement一一对应,可以参考前文中的页磁盘布局图来理解inode与elemements的对应关系;
- 最后,将node的key设为其中第一个inode的key;
了解了Cursor及node的定义后,我们接着来看看CreateBucket()代码(2)处查找过程:
//boltdb/bolt/cursor.go
func (c *Cursor) seek(seek []byte) (key []byte, value []byte, flags uint32) {
_assert(c.bucket.tx.db != nil, "tx closed")
// Start from root page/node and traverse to correct page.
c.stack = c.stack[:0]
c.search(seek, c.bucket.root)
ref := &c.stack[len(c.stack)-1]
// If the cursor is pointing to the end of page/node then return nil.
if ref.index >= ref.count() {
return nil, nil, 0
}
// If this is a bucket then return a nil value.
return c.keyValue()
}
主要是两个步骤:
- 通过清空stack,将游标复位;
- 调用search方法从Bucket的根节点开始查找;
我们来看看search方法:
//boltdb/bolt/cursor.go
// search recursively performs a binary search against a given page/node until it finds a given key.
func (c *Cursor) search(key []byte, pgid pgid) {
p, n := c.bucket.pageNode(pgid)
if p != nil && (p.flags&(branchPageFlag|leafPageFlag)) == 0 {
panic(fmt.Sprintf("invalid page type: %d: %x", p.id, p.flags))
}
e := elemRef{page: p, node: n}
c.stack = append(c.stack, e)
// If we're on a leaf page/node then find the specific node.
if e.isLeaf() {
c.nsearch(key) (1)
return
}
if n != nil {
c.searchNode(key, n) (2)
return
}
c.searchPage(key, p) (3)
}
在search中:
- 通过Bucket的pageNode()方法根据pgid找到缓存在Bucket中的node或者还未实例化的page;
- 创建一个elemRef对象,它指向pgid指定的B+Tree节点,index为0;
- 将刚创建的elemRef对象添加到stack的尾部,实现将Cursor移动到相应的B+Tree节点;
- 如果游标指向叶子节点,则代码(1)处将开始在节点内部查找;
- 如果游标指向根节点或者内节点,且pgid有对应的node对象,则代码(3)处开始在非叶子节点中查找,以确定子节点并进行递归查找;
- 如果游标指向根节点或者内节点,且pgid没有对应的node,只能从page中直接读branchPageElement,由代码(4)处开始在非叶子节点中查找,以确定子节点并进行递归查找;
Bucket的pageNode()方法的思想是: 从Bucket缓存的nodes中查找对应pgid的node,若有则返回node,page为空;若未找到,再从Bucket所属的Transaction申请过的page的集合(Tx的pages字段)中查找,有则返回该page,node为空;若Transaction中的page缓存中仍然没有,则直接从DB的内存映射中查找该页,并返回。总之,pageNode()就是根据pgid找到node或者page。
接下来我们来分析c.searchNode(key, n)的过程,c.searchPage(key, p)的过程与之相似,我们就不作专门分析了,读者可以自行分析。
//boltdb/bolt/cursor.go
func (c *Cursor) searchNode(key []byte, n *node) {
var exact bool
index := sort.Search(len(n.inodes), func(i int) bool {
// TODO(benbjohnson): Optimize this range search. It's a bit hacky right now.
// sort.Search() finds the lowest index where f() != -1 but we need the highest index.
ret := bytes.Compare(n.inodes[i].key, key)
if ret == 0 {
exact = true
}
return ret != -1
})
if !exact && index > 0 {
index--
}
c.stack[len(c.stack)-1].index = index
// Recursively search to the next page.
c.search(key, n.inodes[index].pgid)
}
在searchNode()中:
- 对节点中inodes进行有序查找(Go中sort.Search()使用二分法查找),结果要么是正好找到key,即exact=true且ret=0;要么是找到比key大的最小inode(即ret=1)或者所有inodes的key均小于目标key;
- 如果查找结果是上述的第二情况,则将结果索引值减1,因为欲查找的key肯定位于前一个Pointer对应的子节点或子树中,可以对照我们前面举的BucketAA的例子进行理解;
- 将stack中的最后一个elemRef元素中的index置为查找结果索引值,即将游标移动到所指节点中具体的inode处;
- 从inode记录的pgid(可以理解为Pointer)对应的子节点处开始递归查找;
递归调用的结束条件是游标最终移动到一个叶子节点处,进入c.nsearch(key)过程:
//boltdb/bolt/cursor.go
// nsearch searches the leaf node on the top of the stack for a key.
func (c *Cursor) nsearch(key []byte) {
e := &c.stack[len(c.stack)-1]
p, n := e.page, e.node
// If we have a node then search its inodes.
if n != nil {
index := sort.Search(len(n.inodes), func(i int) bool {
return bytes.Compare(n.inodes[i].key, key) != -1
})
e.index = index
return
}
// If we have a page then search its leaf elements.
inodes := p.leafPageElements()
index := sort.Search(int(p.count), func(i int) bool {
return bytes.Compare(inodes[i].key(), key) != -1
})
e.index = index
}
在nsearch()中:
- 解出游标指向节点的node或者page;
- 如果是node,则在node内进行有序查找,结果为正好找到key或者未找到,未找到时index位于节点结尾处;
- 如果是page,则在page内进行有序查找,结果也是正好找到key或者未找到,未找到时index位于节点结尾于;
- 将当前游标元素的index置为刚刚得到的查找结果索引值,即把游标移动到key所在节点的具体inode处或者结尾处;
到此,我们就了解了Bucket通过Cursor进行查找的过程,我们回头看看seek()方法,在查找结束后,如果未找到key,即key指向叶子结点的结尾处,则它返回空;如果找到则返回K/V对。需要注意的是,在再次调用Cursor的seek()方法移动游标之前,游标一直位于上次seek()调用后的位置。
我们再回到在CreateBucket()的实现中,其中代码(3)处创建了一个内置的子Bucket,它的Bucket头bucket中的root为0,接着代码(3)处通过Bucket的write()方法将内置Bucket序列化,我们可以通过它了解内置Bucket是如何作为Value存于页框上的:
//boltdb/bolt/bucket.go
// write allocates and writes a bucket to a byte slice.
func (b *Bucket) write() []byte {
// Allocate the appropriate size.
var n = b.rootNode
var value = make([]byte, bucketHeaderSize+n.size())
// Write a bucket header.
var bucket = (*bucket)(unsafe.Pointer(&value[0]))
*bucket = *b.bucket
// Convert byte slice to a fake page and write the root node.
var p = (*page)(unsafe.Pointer(&value[bucketHeaderSize]))
n.write(p)
return value
}
从实现上看,内置Bucket就是将Bucket头和其根节点作为Value存于页框上,而其头中字段均为0。接着,CreateBucket()中代码(6)处将刚创建的子Bucket插入游标位置,我们来看看其中的c.node()调用:
//boltdb/bolt/cursor.go
// node returns the node that the cursor is currently positioned on.
func (c *Cursor) node() *node {
_assert(len(c.stack) > 0, "accessing a node with a zero-length cursor stack")
// If the top of the stack is a leaf node then just return it.
if ref := &c.stack[len(c.stack)-1]; ref.node != nil && ref.isLeaf() {
return ref.node
}
// Start from root and traverse down the hierarchy.
var n = c.stack[0].node
if n == nil {
n = c.bucket.node(c.stack[0].page.id, nil)
}
for _, ref := range c.stack[:len(c.stack)-1] {
_assert(!n.isLeaf, "expected branch node")
n = n.childAt(int(ref.index))
}
_assert(n.isLeaf, "expected leaf node")
return n
}
它的基本思路是: 如果当前游标指向了一个叶子节点,且节点已经实例化为node,则直接返回该node;否则,从根节点处沿Cursor的查找路径将沿途的所有节点中未实例化的节点实例化成node,并返回最后节点的node。实际上最后的节点总是叶子节点,因为B+Tree的Key全部位于叶子节点,而内节点只用来索引,所以Cursor在seek()时,总会遍历到叶子节点。也就是说,c.node()总是返回当前游标指向的叶子节点的node引用。代码(6)处通过c.node()的调用得到当前游标处的node后,随即通过node的put()方法向node中写入K/V:
//boltdb/bolt/node.go
// put inserts a key/value.
func (n *node) put(oldKey, newKey, value []byte, pgid pgid, flags uint32) {
......
// Find insertion index.
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, oldKey) != -1 })
// Add capacity and shift nodes if we don't have an exact match and need to insert.
exact := (len(n.inodes) > 0 && index < len(n.inodes) && bytes.Equal(n.inodes[index].key, oldKey))
if !exact {
n.inodes = append(n.inodes, inode{})
copy(n.inodes[index+1:], n.inodes[index:])
}
inode := &n.inodes[index]
inode.flags = flags
inode.key = newKey
inode.value = value
inode.pgid = pgid
_assert(len(inode.key) > 0, "put: zero-length inode key")
}
在node的put()方法中:
- 先查找oldKey以确定插入的位置。要么是正好找到oldKey,则插入位置就是oldKey的位置,实际上是替换;要么node中不含有oldKey,则插入位置就是第一个大于oldKey的前一个key的位置或者是节点结尾;
- 如果找到oldKey,则直接用newKey和value替代原来的oldKey和old value;
- 如果未找到oldKey,则向node中添加一个inode,并将插入位置后的所有inode向后移一位,以实现插入新的inode;
到此,我们就了解了整个Bucket创建的主要过程:
- 根据Bucket的名字(key)搜索父Bucket,以确定表示Bucket的K/V对的插入位置;
- 创建空的内置Bucket,并将它序列化成byte slice,以作为Bucket的Value;
- 将表示Bucket的K/V对(即inode的flags为bucketLeafFlag(0x01))写入父Bucket的叶子节点;
- 通过Bucket的Bucket(name []byte)在父Bucket中查找刚刚创建的子Bucket,在了解了Bucket通过Cursor进行查找和遍历的过程后,读者可以尝试自行分析这一过程,我们在后续文中还会介绍Bucket的Get()方法,与此类似。
在《区块的持久化之BoltDB(一)》中的典型调用示例中,创建完Bucket后,就可以调用它的Put()方法向其中添加K/V了:
//boltdb/bolt/node.go
// Put sets the value for a key in the bucket.
// If the key exist then its previous value will be overwritten.
// Supplied value must remain valid for the life of the transaction.
// Returns an error if the bucket was created from a read-only transaction, if the key is blank, if the key is too large, or if the value is too large.
func (b *Bucket) Put(key []byte, value []byte) error {
......
// Move cursor to correct position.
c := b.Cursor()
k, _, flags := c.seek(key)
// Return an error if there is an existing key with a bucket value.
if bytes.Equal(key, k) && (flags&bucketLeafFlag) != 0 {
return ErrIncompatibleValue
}
// Insert into node.
key = cloneBytes(key)
c.node().put(key, key, value, 0, 0)
return nil
}
可以看到,向Bucket添加K/V的过程与创建Bucket时的过程极其相似,因为创建Bucket实际上就是向父Bucket添加一个标识为Bucket的K/V对而已。不同的是,这里作了一个保护,即当欲插入的Key与当前Bucket中已有的一个子Bucket的Key相同时,会拒绝写入,从而保护嵌套的子Bucket的引用不会被擦除,防止子Bucket变成孤儿。当然,我们也可以调用新创建的子Bucket的CreateBucket()方法来创建孙Bucket,然后向孙Bucket中写入K/V对,其过程与我们上述从根Bucket创建子Bucket的过程是一致的。
到此,我们已经介绍了BoltDB中的Tx、Cursor、page、node及Bucket和背后的B+Tree结构等比较核心的概念和机制,后面我们介绍只读Transaction中的查找过程时将变得非常简单。但是,我们提到的B+Tree节点的分裂和再平衡是什么时候发生的呢,它们会对B+Tree的结构或者其上的节点有什么影响呢,新创建的内置Bucket什么时候会变成一个普通Bucket呢?这些均是在读写Transaction Commit的时候发生的,我们将在《区块的持久化之BoltDB(四)》中介绍。
==大家可以关注我的微信公众号,后续文章将在公众号中同步更新:==
