1. 理论分析三次握手
要分析TCP三次握手的过程,得从TCP头部开始讲起
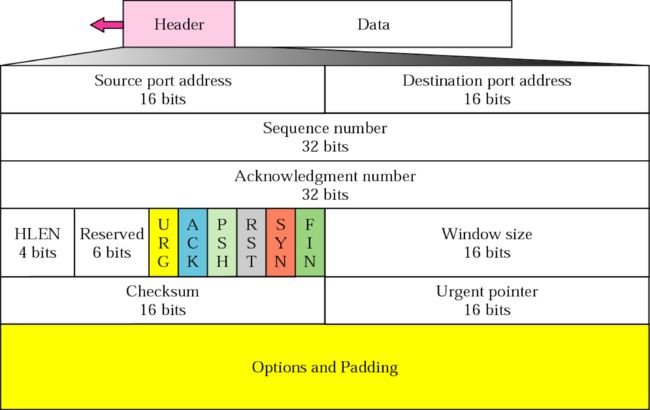
TCP三次握手建立连接的过程其实就是收发数据报时的一种特殊情况(四次挥手也是),只是三次握手的报头有一些特殊的设置。
序列号(Sequence number):4个字节。用来标记数据段的顺序,TCP把连接中发送的所有数据字节都编上一个序号,第一个字节的编号由本地随机产生;给字节编上序号后,就给每一个报文段指派一个序号;序列号seq就是这个报文段中的第一个字节的数据编号。
确认号(Acknowledgement number):4个字节。期待收到对方下一个报文段的第一个数据字节的序号;序列号表示报文段携带数据的第一个字节的编号;而确认号指的是期望接收到下一个字节的编号;因此当前报文段最后一个字节的编号+1即为确认号。
确认位(ACK):仅当ACK=1时,确认号字段才有效。ACK=0时,确认号无效。
同步位(SYN):连接建立时用于同步序号。当SYN=1,ACK=0时表示:这是一个连接请求报文段。若同意连接,则在响应报文段中使得SYN=1,ACK=1。因此,SYN=1表示这是一个连接
请求,或连接接受报文。SYN这个标志位只有在TCP建产连接时才会被置1,握手完成后SYN标志位被置0。终止位(FIN):用来释放一个连接。FIN=1表示:此报文段的发送方的数据已经发送完毕,并要求释放运输连接。
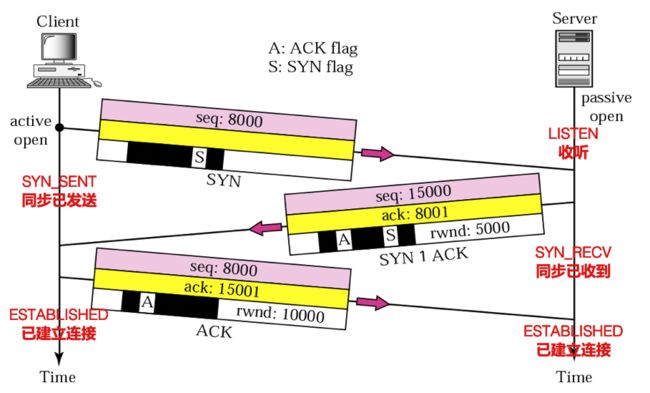
第一次握手:建立连接时,客户端发送SYN包(SYN=1, seq=x)到服务器,并进入SYN_SENT状态,等待服务器确认;
第二次握手:服务器收到SYN包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(SYN=1, ACK=1, seq=y, ack=x+1),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ACK=1, seq=x+1, ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手
2. 深入分析三次握手
TCP的三次握手从用户程序的角度看,就是客户端connect和服务端accept建立起连接时背后完成的工作。
这两个socket API函数分别对应着:
connect函数 --- sys_connect函数 --- sock->opt->connect函数指针 --- tcp_v4_connect函数(net/ipv4/tcp_ipv4.c)
accept函数 --- sys_accept函数 --- sock->opt->accept函数指针 --- inet_csk_accept函数(net/ipv4/inet_connection_sock.c)
启动MenuOS和gdb,分别在tcp_v4_connect、inet_csk_accept处打断点。
2.1 服务器调用accept函数,等待客户端发来的SYN报文
在MenuOS启动replyhi这个服务端程序,发现在inet_csk_accept停住。继续跟踪
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue; //
struct request_sock *req;
struct sock *newsk;
int error;
lock_sock(sk); // 连接之前要先把这个socket锁住
/* We need to make sure that this socket is listening,
* and that it has something pending.
*/
error = -EINVAL;
if (sk->sk_state != TCP_LISTEN) // 确保当前socket是在LISTEN状态
goto out_err;
/* Find already established connection */
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
/* If this is a non blocking socket don't sleep */
error = -EAGAIN;
if (!timeo)
goto out_err;
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
req = reqsk_queue_remove(queue, sk);
newsk = req->sk;
if (sk->sk_protocol == IPPROTO_TCP &&
tcp_rsk(req)->tfo_listener) {
spin_lock_bh(&queue->fastopenq.lock);
if (tcp_rsk(req)->tfo_listener) {
/* We are still waiting for the final ACK from 3WHS
* so can't free req now. Instead, we set req->sk to
* NULL to signify that the child socket is taken
* so reqsk_fastopen_remove() will free the req
* when 3WHS finishes (or is aborted).
*/
req->sk = NULL;
req = NULL;
}
spin_unlock_bh(&queue->fastopenq.lock);
}
out:
release_sock(sk);
if (req)
reqsk_put(req);
return newsk;
out_err:
newsk = NULL;
req = NULL;
*err = error;
goto out;
}通过gdb逐步调试我们发现,当只启动服务端时,gdb停在了inet_csk_wait_for_connect函数处不再往下走。
查看inet_csk_wait_for_connect实现可以发现,其用了一个死循环一直在判断socket请求队列是否为空。如果为空则跳出循环。
可以看到服务端在这里被阻塞住等待客户端的连接。
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
struct inet_connection_sock *icsk = inet_csk(sk);
DEFINE_WAIT(wait);
int err;
for (;;) {
...
if (!reqsk_queue_empty(&icsk->icsk_accept_queue)) // 若socket请求队列不为空则跳出循环
break;
...
}
finish_wait(sk_sleep(sk), &wait);
return err;
}2.2 第一次握手:客户端调用socket API的connect函数,并发送SYN报文
接着在MenuOS里启动hello,gdb停在了tcp_v4_connect处。
/* This will initiate an outgoing connection. */
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
...
// 调用IP层服务。这里的作用是通过路由表寻找路由。
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
orig_sport, orig_dport, sk);
//...
// 把socket状态设置为TCP_SYN_SENT
tcp_set_state(sk, TCP_SYN_SENT);
...
sk_set_txhash(sk);
// 调用IP层服务。作用是检查客户端本地端口和目的端口是否与路由表中的记录相同
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
...
err = tcp_connect(sk);
...
return err;tcp_v4_connect调用了IP层的服务,并通过tcp_connect(sk)来构造一个携带SYN标志位的TCP头并发送出去。同时还设置了计时器超时重发。
可以看到里面是通过tcp_transmit_skb函数负责将TCP数据报头发出去的。具体发送方式涉及TCP/IP协议栈的实现,比较复杂,重点先放在三次握手的实现。
// net/ipv4/tcp_output.c
/* 建了一个SYN并发出去*/
int tcp_connect(struct sock *sk)
{
...
/* Send off SYN; include data in Fast Open. */
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
if (err == -ECONNREFUSED)
eturn err;
}
...
/* 设置重发SYN的计时器,直到收到回复*/
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
return 0;2.3 第二次握手:服务器收到SYN报文并发出SYNACK报文
走出tcp_v4_connect后,gdb继续往下走,发现在inet_csk_accept再次停下。但在服务端的inet_csk_accept已无法再跟踪到第二次和第三次握手,因为接收数据放入accept队列的代码不在这。
换个思路:网卡接收到数据需要通知上层协议来接收并处理数据,则应有TCP协议的接收数据函数被底层网络驱动以callback的方式进行调用。
所以我们回头看TCP/IP协议栈的初始化过程,是否有将TCP的recv函数指针发布给网路底层代码。
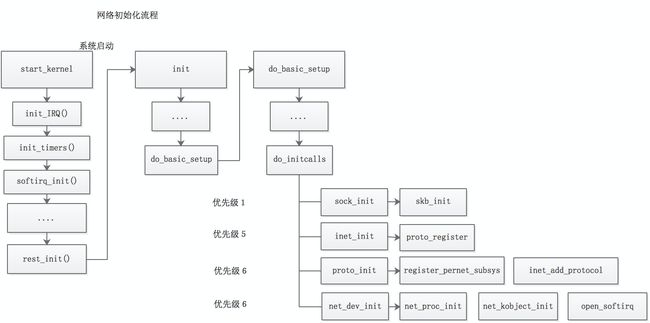
(图片来源:https://blog.csdn.net/notbaron/article/details/79601727)
重新整理TCP/IP协议栈初始化的函数调用栈:
start_kernel() ---> rest_init() ---> kernel_init() ---> do_basic_setup() ---> do_initcalls() ---> inet_init()
// net/ipv4/af_inet.c
/* thinking of making this const? Don't.
* early_demux can change based on sysctl.
*/
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
};
static int __init inet_init(void)
{
...
/*
* Add all the base protocols.
*/
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
...
}由tcp_protocol这个结构的定义和inet_init的内容,猜测底层网络接受数据应该是由这个结构体的handler来负责收取和处理。
实际上,在IP层处理本地数据包时,会获取到net_protocol结构的实例,并且调用实例的handler回调,也就是调用了tcp_v4_rcv
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
/* 获取协议处理结构 */
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
int ret;
/* 协议上层收包处理函数 */
ret = ipprot->handler(skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
}
}到此可以认定tcp_v4_rcv就是TCP协议中负责接受处理数据的入口。
通过gdb一路跟踪,可以发现服务端进入tcp_v4_rcv ---> tcp_v4_do_rcv ---> tcp_rcv_state_process,执行了acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0,将连接加入accept队列。 我们知道icsk->icsk_af_ops指向ipv4_specific,所以加入队列的操作更深层的是通过tcp_v4_conn_request- --> tcp_conn_request ---> inet_csk_reqsk_queue_hash_add 或 inet_csk_reqsk_queue_added实现的。
/* 定义了各个操作的函数指针的tcp_ipv4结构体 */
const struct inet_connection_sock_af_ops ipv4_specific = {
.queue_xmit = ip_queue_xmit,
.send_check = tcp_v4_send_check,
.rebuild_header = inet_sk_rebuild_header,
.sk_rx_dst_set = inet_sk_rx_dst_set,
.conn_request = tcp_v4_conn_request,
.syn_recv_sock = tcp_v4_syn_recv_sock,
.net_header_len = sizeof(struct iphdr),
.setsockopt = ip_setsockopt,
.getsockopt = ip_getsockopt,
.addr2sockaddr = inet_csk_addr2sockaddr,
.sockaddr_len = sizeof(struct sockaddr_in),
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_ip_setsockopt,
.compat_getsockopt = compat_ip_getsockopt,
#endif
.mtu_reduced = tcp_v4_mtu_reduced,
};
EXPORT_SYMBOL(ipv4_specific);
// net/ipv4/tcp_ipv4.c
int tcp_v4_rcv(struct sk_buff *skb)
{
...
if (sk->sk_state == TCP_LISTEN) { // 服务端的socket出于TCP_LISTEN状态
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
...
}
/* tcp_v4_do_rcv是个主要的报文处理函数。 */
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
...
// SYN报文走这里
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_cookie_check(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
} else
sock_rps_save_rxhash(sk, skb);
if (tcp_rcv_state_process(sk, skb)) {
rsk = sk;
goto reset;
}
return 0;
...
}
/* net/ipv4/tcp_input.c
* 函数功能:绝大多数状态的报文处理。*/
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb); //获取TCP报文头部
...
switch (sk->sk_state) {
...
case TCP_LISTEN:
if (th->ack)
return 1;
if (th->rst)
goto discard;
if (th->syn) { //如果syn标志位为1
if (th->fin)
goto discard;
/* It is possible that we process SYN packets from backlog,
* so we need to make sure to disable BH and RCU right there.
*/
rcu_read_lock();
local_bh_disable();
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0; // 将连接加入accept队列。
local_bh_enable();
rcu_read_unlock();
if (!acceptable)
return 1;
consume_skb(skb);
return 0;
}
goto discard;
...
}那么第二次握手到底是在哪里实现的?继续在tcp_conn_request往下读。终于找到了af_ops->send_synack,由上面我们已知af_ops指向ipv4_specific,而ipv4_specific的send_synack指向tcp_v4_send_synack。至此实现了服务器向客户端发送SYNACK报文。
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
...
if (fastopen_sk) {
af_ops->send_synack(fastopen_sk, dst, &fl, req,
&foc, TCP_SYNACK_FASTOPEN);
/* Add the child socket directly into the accept queue */
inet_csk_reqsk_queue_add(sk, req, fastopen_sk);
sk->sk_data_ready(sk);
bh_unlock_sock(fastopen_sk);
sock_put(fastopen_sk);
} else {
tcp_rsk(req)->tfo_listener = false;
if (!want_cookie)
inet_csk_reqsk_queue_hash_add(sk, req,
tcp_timeout_init((struct sock *)req)); // 将请求加入半连接队列,同时启动SYNACK定时器
af_ops->send_synack(sk, dst, &fl, req, &foc, // 调用tcp_v4_send_synack()发送SYNACK报文
!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE);
if (want_cookie) {
reqsk_free(req);
return 0;
}
}2.4 第三次握手:客户端收到SYNACK报文并发出ACK报文
在还没收到SYNACK报文之前,客户端一直是出于SYN_SENT的状态。
同样的,当SYNACK报文发来时,底层网路通知上层取报文,还是通过tcp_v4_rcv -> tcp_v4_do_rcv -> tcp_rcv_state_process来处理SYNACK报文的获取和ACK报文的发送。
继续深入,在tcp_ack(sk, skb, FLAG_SLOWPATH) 会调用到tcp_send_ack,并将自身状态改为ESTABLISHED
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
...
switch (sk->sk_state) {
...
case TCP_SYN_SENT:
tp->rx_opt.saw_tstamp = 0;
tcp_mstamp_refresh(tp);
queued = tcp_rcv_synsent_state_process(sk, skb, th);
if (queued >= 0)
return queued;
/* Do step6 onward by hand. */
tcp_urg(sk, skb, th);
__kfree_skb(skb);
tcp_data_snd_check(sk);
return 0;
}
static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th)
{
...
/* rfc793:
* "If the SYN bit is on ...
* are acceptable then ...
* (our SYN has been ACKed), change the connection
* state to ESTABLISHED..."
*/
tcp_ecn_rcv_synack(tp, th);
tcp_init_wl(tp, TCP_SKB_CB(skb)->seq);
tcp_ack(sk, skb, FLAG_SLOWPATH);
...
tcp_finish_connect(sk, skb);
}