在数据库方面,索引很常见。 迟早会出现数据库性能不再令人满意的情况。 当发生这种情况时,你应该转向的第一件事是数据库索引。
在数据库中的特定表上创建索引的目的是使搜索表并查找我们想要的行更快。 可以使用数据库表的一列或多列创建索引,为快速随机查找和有序记录的有效访问提供基础。
一个图书馆的例子。
图书馆目录的组织方式类似于数据库表,通常包含四列:书名,作者,主题和出版日期。通常有两个这样的目录,一个按书名排序,另一个按作者姓名排序。这样你就可以想到一个你想要阅读的作家,然后查看他们的书籍,或者查找你知道你想要阅读的特定书名。这些目录就像书籍数据库的索引。它们提供了一个排序的数据列表,可以通过相关信息轻松搜索。
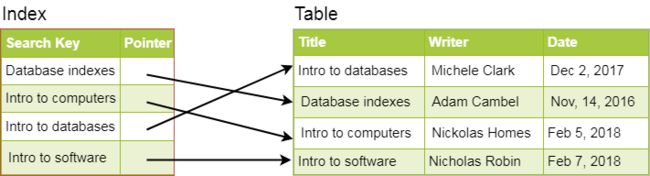
简单地说,索引是一种数据结构,可以被视为一个目录,指向我们实际数据所在的位置。因此,当我们在表的列上创建索引时,我们将该列和指针存储到索引中的整行。我们假设一个包含书籍列表的表格,下图显示了“标题”列上的索引如何:
就传统的关系数据库而言,我们也可以将此概念应用于更大的数据集。 索引的技巧是我们必须仔细考虑用户将如何访问数据。 在数据集大小为数TB但具有非常小的有效载荷(例如,1KB)的情况下,索引是优化数据访问的必要条件。 在如此大的数据集中寻找小的有效载荷可能是一个真正的挑战,因为我们不可能在任何合理的时间内迭代那么多的数据。 此外,很可能这么大的数据集分布在几个物理设备上 - 这意味着我们需要一些方法来找到所需数据的正确物理位置。 索引是执行此操作的最佳方式。
索引构建的二种方式
聚集索引,索引与表的物理顺序一一对应,所以一个数据表只能有一个聚集索引。聚簇索引能提高多行检索的速度
非聚集索引,是通过一个指针,就是上图的方式,建立索引。所以可以有多个。非聚簇索引对于单行的检索很快。
索引的优点
在设计数据库时,通过创建一个惟一的索引,能够在索引和信息之间形成一对一的映射式的对应关系,增加数据的惟一性特点。
能提高数据的搜索及检索速度,符合数据库建立的初衷。
能够加快表与表之间的连接速度,这对于提高数据的参考完整性方面具有重要作用。
在信息检索过程中,若使用分组及排序子句进行时,通过建立索引能有效的减少检索过程中所需的分组及排序时间,提高检索效率。
建立索引之后,在信息查询过程中可以使用优化隐藏器,这对于提高整个信息检索系统的性能具有重要意义。
索引的缺点
在数据库建立过程中,需花费较多的时间去建立并维护索引,特别是随着数据总量的增加,所花费的时间将不断递增。
在数据库中创建的索引需要占用一定的物理存储空间,这其中就包括数据表所占的数据空间以及所创建的每一个索引所占用的物理空间。
在对表中的数据进行修改时,例如对其进行增加、删除或者是修改操作时,索引还需要进行动态的维护,这给数据库的维护速度带来了一定的麻烦。
B树索引的优点
一般使用磁盘I/O次数评价索引结构的优劣。先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
从上面介绍我们知道,B树的搜索复杂度为O(h)=O(logdN),所以树的出度d越大,深度h就越小,I/O的次数就越少。B+Tree恰恰可以增加出度d的宽度,因为每个节点大小为一个页大小,所以出度的上限取决于节点内key和data的大小:
dmax=floor(pagesize/(keysize+datasize+pointsize))//floor表示向下取整
由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,从而拥有更好的性能。
1)B树
B树中每个节点包含了键值和键值对于的数据对象存放地址指针,所以成功搜索一个对象可以不用到达树的叶节点。
成功搜索包括节点内搜索和沿某一路径的搜索,成功搜索时间取决于关键码所在的层次以及节点内关键码的数量。
在B树中查找给定关键字的方法是:首先把根结点取来,在根结点所包含的关键字K1,…,kj查找给定的关键字(可用顺序查找或二分查找法),若找到等于给定值的关键字,则查找成功;否则,一定可以确定要查的关键字在某个Ki或Ki+1之间,于是取Pi所指的下一层索引节点块继续查找,直到找到,或指针Pi为空时查找失败。
2)B+树
B+树非叶节点中存放的关键码并不指示数据对象的地址指针,非也节点只是索引部分。所有的叶节点在同一层上,包含了全部关键码和相应数据对象的存放地址指针,且叶节点按关键码从小到大顺序链接。如果实际数据对象按加入的顺序存储而不是按关键码次数存储的话,叶节点的索引必须是稠密索引,若实际数据存储按关键码次序存放的话,叶节点索引时稀疏索引。
B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
所以 B+树有两种搜索方法:
一种是按叶节点自己拉起的链表顺序搜索。
一种是从根节点开始搜索,和B树类似,不过如果非叶节点的关键码等于给定值,搜索并不停止,而是继续沿右指针,一直查到叶节点上的关键码。所以无论搜索是否成功,都将走完树的所有层。
B+ 树中,数据对象的插入和删除仅在叶节点上进行。
这两种处理索引的数据结构的不同之处:
a,B树中同一键值不会出现多次,并且它有可能出现在叶结点,也有可能出现在非叶结点中。而B+树的键一定会出现在叶结点中,并且有可能在非叶结点中也有可能重复出现,以维持B+树的平衡。
b,因为B树键位置不定,且在整个树结构中只出现一次,虽然可以节省存储空间,但使得在插入、删除操作复杂度明显增加。B+树相比来说是一种较好的折中。
c,B树的查询效率与键在树中的位置有关,最大时间复杂度与B+树相同(在叶结点的时候),最小时间复杂度为1(在根结点的时候)。而B+树的时候复杂度对某建成的树是固定的。