Advanced Web Scraping: Bypassing "403 Forbidden," captchas, and more
—— github
我尝试过x-ray/cheerio, nokogiri等等爬虫框架,最终还是回到了我的最爱: scrapy。它确实非常直观,学习曲线友好。
通过The Scrapy Tutorial(中文版)你可以在几分钟之内上手你的第一只爬虫。然后,当你需要完成一些复杂的任务时,你很可能会发现有内置好的、文档良好的方式来实现它。(Scrapy内置了许多强大的功能,但Scrapy的框架结构良好,如果你还不需要某个功能,它就不会影响你。)再者,如果你最终需要某些新功能,例如一个布隆过滤器来去重大量的链接,通常只需要简单地子类化某个组件,并做点小小的修改就可以了。
- 注:作者为了爬虫道德,在教程中使用了虚拟的目标网站Zipru,假想它为一个种子站点。自己尝试时,修改为自己的需求网址即可。
新建项目
- scrapy安装参看新手向爬虫(三)别人的爬虫在干啥
- 命令行新建名为
zipru_scraper的工程目录。
scrapy startproject zipru_scraper
- 这会创建如下的目录结构:
└── zipru_scraper
├── zipru_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
默认情况下,大多数这些文件实际上不会被使用,它们的存在只是建议我们以一个合理的方式组织我们的代码。当前,你只需要考虑zipru_scraper(第一个)作为项目的顶层目录,这就是任何scrapy命令应该运行的地方,也是任何相对路径的根。
添加一个基本爬虫
- 现在我们需要添加一个小爬虫来真正做点什么。
- 创建文件
zipru_scraper/spiders/zipru_spider.py添加如下内容:
import scrapy
class ZipruSpider(scrapy.Spider):
name = 'zipru'
start_urls = ['http://zipru.to/torrents.php?category=TV']
- 我们的小爬虫继承了
scrapy.Spider,它内置的start_requests()方法会自动遍历start_urls列表中的链接来开始我们的抓取。我们先尝试一个类似下图的种子列表页面。

对页码审查元素我们会看到:
2
3
4
- 为了让我们的小爬虫知道如何爬取这些链接,我们需要为
ZipruSpider类添加一个parse(response)方法:(页面元素选取可参看Selectors选择器简介或新手向爬虫(一)利用工具轻松爬取并分析)
def parse(self, response):
# 从页面中取出页码里包含的链接
for page_url in response.css('a[title ~= page]::attr(href)').extract():
page_url = response.urljoin(page_url)
# 将解析出的href里的链接自动判断补全
yield scrapy.Request(url=page_url, callback=self.parse)
# 由解析出的url生成新的请求对象
- 在爬取从
start_urls自动开始后,服务器返回的响应会自动传递给parse(self, response)方法。在解析了页面中的页码元素里包含的链接后,我们由每个解析出的url生成新的请求对象,它们的响应的解析方法即回调函数还是这个parse方法。只要这些url还没被处理过,这些请求将被转换为响应对象,仍然馈入parse(self, response)方法(感谢dupe过滤器帮我们自动去重链接)。 - 现在我们的小爬虫已经可以不断地爬取新的列表页面了。但是我们还没有获取到实际的信息。让我们加上对表格中元素的解析来获取种子信息。
def parse(self, response):
# 从页面中取出页码里包含的链接
for page_url in response.xpath('//a[contains(@title, "page ")]/@href').extract():
page_url = response.urljoin(page_url)
yield scrapy.Request(url=page_url, callback=self.parse)
# 提取种子信息
for tr in response.css('table.lista2t tr.lista2'):
tds = tr.css('td')
link = tds[1].css('a')[0]
yield {
'title' : link.css('::attr(title)').extract_first(),
'url' : response.urljoin(link.css('::attr(href)').extract_first()),
'date' : tds[2].css('::text').extract_first(),
'size' : tds[3].css('::text').extract_first(),
'seeders': int(tds[4].css('::text').extract_first()),
'leechers': int(tds[5].css('::text').extract_first()),
'uploader': tds[7].css('::text').extract_first(),
}
- 在解析出url生成新的请求后,我们的小爬虫会处理当前页面的种子信息,生成一个字典项目,作为我们爬虫数据输出的一部分。(Scrapy会根据类型自动判断我们
yield产出的是新的请求还是数据信息。)
对大多数网站的数据抓取来说,我们的任务就已经完成了。在命令行运行:
scrapy crawl zipru -o torrents.jl
几分钟后,一个格式良好的JSON Lines文件torrents.jl就生成了,包含了我们需要的种子信息。相反,我们会得到这样的输出:
[scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
[scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
[scrapy.core.engine] DEBUG: Crawled (403) (referer: None) ['partial']
[scrapy.core.engine] DEBUG: Crawled (403) (referer: None) ['partial']
[scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 http://zipru.to/torrents.php?category=TV>: HTTP status code is not handled or not allowed
[scrapy.core.engine] INFO: Closing spider (finished)
这时我们要考虑是否有公开API可以使用,或者耐心分析下问题。
简单的问题
- 我们的第一个请求获得了一个
403响应,它会被忽略,然后因为我们只给了一个目标网址爬虫停止了。 - 如果手动浏览器访问该链接显示正常,我们可以用tcpdump来比较两次请求的差异。但我们首先需要检查的是User Agent参数。
- 默认情况下,Scrapy将其标识为“Scrapy / 1.3.3(+ http://scrapy.org)”,某些服务器可能会阻止它或者甚至只是将有限数量的User Agent列入白名单。
- 我们可以找到最常用的User Agents,使用其中之一通常足以绕过基本的防爬措施。这里我们将
zipru_scraper/settings.py文件中的
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'zipru_scraper (+http://www.yourdomain.com)'
替换为
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36'
为了使我们的爬虫访问表现得更像人类的操作,让我们降低请求速率(原理上借助AutoThrottle 拓展),在settings.py中继续添加
CONCURRENT_REQUESTS = 1
DOWNLOAD_DELAY = 5
此外,我们的爬虫还会自动遵守robots.txt,可谓爬虫界的好公民了。现在运行 scrapy crawl zipru -o torrents.jl 应该会有如下输出:
[scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to from
[scrapy.core.engine] DEBUG: Crawled (200) (referer: None) ['partial']
[scrapy.core.engine] INFO: Closing spider (finished)
不错,有所进展。我们得到两个200状态码和一个下载器中间件会自动处理的302重定向响应。不幸的是,302将我们指向一个看上去不详的链接threat_defense.php。毫不意外,爬虫在那没找到什么有用的信息,爬取终止了。
下载器中间件
- 在我们深入探索之前了解下Scrapy是如何处理请求和响应的很有帮助。
- 当我们创建基本爬虫时,生成了
scrapy.Request对象,然后它以某种方式转换为对应服务器响应的scrapy.Response。某种方式中的一大部分是下载器中间件的作用。 - 下载器中间件继承
scrapy.downloadermiddlewares.DownloaderMiddleware,并且同时实现了process_request(request, spider)和process_response(request, response, spider)方法。顾名思义,可以猜得它们是做什么的。实际上,有一大堆默认的下载器中间件在工作。这是标准配置的样子(当然你可以修改它们):
DOWNLOADER_MIDDLEWARES_BASE = {
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
- 在一个请求到达服务器的路上,它依次通过每个使能的中间件的
process_request(request, spider)方法。按照数字由小到大的顺序依次进行,RobotsTxtMiddleware首先处理该请求,HttpCacheMiddleware最后处理。一旦响应被服务器返回,它也会依次经历这些中间件的process_response(request, response, spider)方法。这以相反的顺序发生(数字大的先处理)。也就是说,数字越大,越靠近服务器端,数字越小,越接近爬虫端。
一个特别简单的中间件是CookiesMiddleware。它只是简单地检查传入响应的Set-Cookie头,并且持久化cookies。当传出请求时,它会适当地设置Cookie头。当然,由于考虑cookie过期等因素它会复杂一点,但是概念是比较清楚的。
另一个相当基础的中间件是RedirectMiddleware,它只处理3XX重定向。对于所有非3XX状态码的响应它一律放行。当有重定向发生时,它会由服务器返回的重定向链接地址生成一个新的请求。当process_response(request, response, spider)方法返回一个请求对象而不是一个响应对象时,当前的响应对象会被丢弃,然后一切随着新请求重新开始。之前看到的输出信息就是如此。
如果你对这么多默认的下载器中间件感兴趣,可以查看架构总览。实际上还有很多其它的东西。但Scrapy伟大的地方在于你不必了解很多,正如不需要知道下载器中间件的存在也能写出功能足够的爬虫,写出一个工作良好的下载器中间件也不需要你对其它部分的了解。
困难的问题
- 回到我们的小爬虫,我们发现我们被重定向到
threat_defense.php?defense=1&...链接而得不到想要的页面。在浏览器中查看这个页面,会是这样:
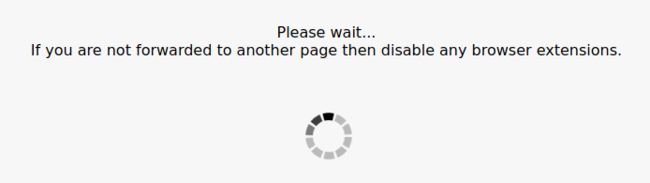
在被重定向到threat_defense.php?defense=2&...之前是这样的:
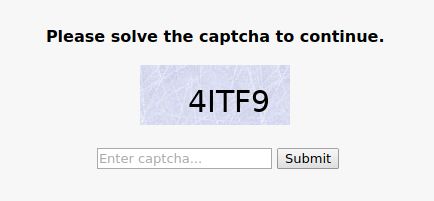
查看第一个页面的源码可以发现,页面中有一些JavaScript代码用于构造一个特殊的重定向URL与设置浏览器cookies。
我们需要解决这两个问题,当然也需要识别验证码并提交答案。如果我们不小心弄错了,有时会被重定向到其他的验证码页面,有时我们会终止于这样的页面:

我们需要点击Click here来开始整个重定向周期。小菜一碟,对吧! - 既然所有的问题都来自于一开始的
302重定向,那么顺理成章,让我们在定制的redirect middleware(重定向中间件)里解决它们。在遇到特殊的302重定向到threat_defense.php之外,我们想要这个中间件仍然像普通重定向中间件一样工作。当它遇到了这个特殊的302,我们希望它绕过所有这些防范措施,为会话添加访问Cookie,最终请求到原始网页。如果顺利的话,对于我们之前写的小爬虫来说,就不需要关心这些细节,像过去一样正常请求即可。 - 替换
zipru_scraper/middlewares.py中的内容为
import os, tempfile, time, sys, logging
logger = logging.getLogger(__name__)
import dryscrape
import pytesseract
from PIL import Image
from scrapy.downloadermiddlewares.redirect import RedirectMiddleware
class ThreatDefenceRedirectMiddleware(RedirectMiddleware):
def _redirect(self, redirected, request, spider, reason):
# 如果没有特殊的防范性重定向那就正常工作
if not self.is_threat_defense_url(redirected.url):
return super()._redirect(redirected, request, spider, reason)
logger.debug(f'Zipru threat defense triggered for {request.url}')
request.cookies = self.bypass_threat_defense(redirected.url)
request.dont_filter = True # 防止原始链接被标记为重复链接
return request
def is_threat_defense_url(self, url):
return '://zipru.to/threat_defense.php' in url
- 我们继承了
RedirectMiddleware中间件,使得我们可以复用内置的重定向处理操作,而只需要将我们的代码插入_redirect(redirected, request, spider, reason)方法,一旦构建了重定向请求,它会被process_response(request, response, spider)方法调用。对于非防范性重定向,我们调用父类的标准方法处理。这里,我们还未实现bypass_threat_defense(url)方法,但是它任务很明确,就是返回访问cookies,使得我们可以刷新原始请求的cookies,而重新处理原始请求。 - 为了启用我们的新中间件,要在
zipru_scraper/settings.py中添加如下内容:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': None,
'zipru_scraper.middlewares.ThreatDefenceRedirectMiddleware': 600,
}
它禁用了默认的重定向中间件,并将我们自己的中间件插入到相同的位置。此外,我们还需要安装一些需求包:
pip install dryscrape # headless webkit 无头webkit
pip install Pillow # image processing 图像处理
pip install pytesseract # OCR 字符识别
要注意,这些包都具有pip不能处理的外部依赖。如果安装出错,你需要访问dryscrape,Pillow以及 pytesseract来获取安装指导。
- 接下来,我们只需要实现
bypass_thread_defense(url)。我们可以解析JavaScript来获取需要的变量,并在python中重建逻辑,不过那显得琐碎而麻烦。让我们选择笨拙而简单的做法,使用无头webkit实例。这有不少选择,不过我独爱dryscrape(之前安装的)。 - 首先,在我们的中间件构造器里初始化一个dryscrape会话。
def __init__(self, settings):
super().__init__(settings)
# start xvfb to support headless scraping
if 'linux' in sys.platform:
dryscrape.start_xvfb()
self.dryscrape_session = dryscrape.Session(base_url='http://zipru.to')
你可以把这个会话当作一个浏览器标签,它会做所有浏览器通常所做的事(如获取外部资源,获取脚本)。我们可以在选项卡中导航到新的URL,点击按钮,输入文本以及做其它各类事务。Scrapy支持请求和项目处理的并发,但响应的处理是单线程的。这意味着我们可以使用这个单独的dryscrape会话,而不用担心线程安全。
- 现在我们来看一下绕过服务器防御的基本逻辑。
def bypass_threat_defense(self, url=None):
# 有确实的url则访问
if url:
self.dryscrape_session.visit(url)
# 如果有验证码则处理
captcha_images = self.dryscrape_session.css('img[src *= captcha]')
if len(captcha_images) > 0:
return self.solve_captcha(captcha_images[0])
# 点击可能存在的重试链接
retry_links = self.dryscrape_session.css('a[href *= threat_defense]')
if len(retry_links) > 0:
return self.bypass_threat_defense(retry_links[0].get_attr('href'))
# 否则的话,我们是在一个重定向页面上,等待重定向后再次尝试
self.wait_for_redirect()
return self.bypass_threat_defense()
def wait_for_redirect(self, url = None, wait = 0.1, timeout=10):
url = url or self.dryscrape_session.url()
for i in range(int(timeout//wait)):
time.sleep(wait)
# 如果url发生变化则返回
if self.dryscrape_session.url() != url:
return self.dryscrape_session.url()
logger.error(f'Maybe {self.dryscrape_session.url()} isn\'t a redirect URL?')
raise Exception('Timed out on the zipru redirect page.')
- 这里我们处理了在浏览器访问时可能遇到的各种情况,并且做了一个正常人类会做出的操作。任何时刻采取的行动取决于当前的页面,代码以一种优雅的方式顺序处理变化的情况。
- 最后一个谜题是解决验证码。有不少解决验证码服务的API供你在紧要关头使用,但是这里的验证码足够简单我们可以用OCR来解决它。使用pytesseract做字符识别,我们最终可以添加
solve_captcha(img)方法来完善我们的bypass_threat_defense()。
def solve_captcha(self, img, width=1280, height=800):
# 对当前页面截图
self.dryscrape_session.set_viewport_size(width, height)
filename = tempfile.mktemp('.png')
self.dryscrape_session.render(filename, width, height)
# 注入javascript代码来找到验证码图片的边界
js = 'document.querySelector("img[src *= captcha]").getBoundingClientRect()'
rect = self.dryscrape_session.eval_script(js)
box = (int(rect['left']), int(rect['top']), int(rect['right']), int(rect['bottom']))
# 解决截图中的验证码
image = Image.open(filename)
os.unlink(filename)
captcha_image = image.crop(box)
captcha = pytesseract.image_to_string(captcha_image)
logger.debug(f'Solved the Zipru captcha: "{captcha}"')
# 提交验证码结果
input = self.dryscrape_session.xpath('//input[@id = "solve_string"]')[0]
input.set(captcha)
button = self.dryscrape_session.xpath('//button[@id = "button_submit"]')[0]
url = self.dryscrape_session.url()
button.click()
# 如果我们被重定向到一个防御的URL,重试
if self.is_threat_defense_url(self.wait_for_redirect(url)):
return self.bypass_threat_defense()
# 否则就可以返回当前的cookies构成的字典
cookies = {}
for cookie_string in self.dryscrape_session.cookies():
if 'domain=zipru.to' in cookie_string:
key, value = cookie_string.split(';')[0].split('=')
cookies[key] = value
return cookies
可以看到,如果验证码解析失败,我们会回到bypass_threat_defense()。这样我们拥有多次尝试的机会,直到成功一次。
看起来我们的爬虫应该成功了,可是它陷入了无限循环中:
[scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
[zipru_scraper.middlewares] DEBUG: Zipru threat defense triggered for http://zipru.to/torrents.php?category=TV
[zipru_scraper.middlewares] DEBUG: Solved the Zipru captcha: "UJM39"
[zipru_scraper.middlewares] DEBUG: Zipru threat defense triggered for http://zipru.to/torrents.php?category=TV
[zipru_scraper.middlewares] DEBUG: Solved the Zipru captcha: "TQ9OG"
[zipru_scraper.middlewares] DEBUG: Zipru threat defense triggered for http://zipru.to/torrents.php?category=TV
[zipru_scraper.middlewares] DEBUG: Solved the Zipru captcha: "KH9A8"
...
看起来我们的中间件至少成功解决了验证码,然后重新发起请求。问题在于新的请求重又触发了防御机制。我一开以为bug在解析与添加cookies,可再三检查无果。这是另一个“唯一可能不同的东西是请求头”的情况。
Scrapy和dryscrape的请求头显然都绕过了触发403的第一层过滤器,因为我们没有得到任何403响应。但这肯定是因为某种请求头的差异造成的问题。我的猜测是,其中一个加密的访问Cookie包含了完整的原始访问请求头的哈希值,如果两次请求头不匹配,将触发威胁防御机制。这里的意图可能是防止某人直接将浏览器的cookies复制到爬虫中,但也只是增加了点小麻烦。
- 所以让我们在
zipru_scraper/settings.py明确指定我们的请求头:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'User-Agent': USER_AGENT,
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,*',
}
注意这里,我们显式地使用之前定义的USER_AGENT赋值给User-Agent,虽然它已经被用户代理中间件自动添加,但是这样做会便于我们复制请求头到dryscrape中。下面修改我们的ThreatDefenceRedirectMiddleware的初始化函数为:
def __init__(self, settings):
super().__init__(settings)
# start xvfb to support headless scraping
if 'linux' in sys.platform:
dryscrape.start_xvfb()
self.dryscrape_session = dryscrape.Session(base_url='http://zipru.to')
for key, value in settings['DEFAULT_REQUEST_HEADERS'].items():
# seems to be a bug with how webkit-server handles accept-encoding
if key.lower() != 'accept-encoding':
self.dryscrape_session.set_header(key, value)
现在scrapy crawl zipru -o torrents.jl命令行运行,成功了!数据流不断涌出!并且都记录到了我们的torrents.jl文件里。
总结
- 我们成功应对了
- User agent 过滤
- 模糊的JavaScript重定向
- 验证码
- 请求头一致性检验
- 虽然我们的目标网站Zipru是虚构的,但是原理是通用的,希望对你的爬虫探险有所帮助!