出处---Go编程语言
- 欢迎来到 Go 编程语言指南。本指南涵盖了该语言的大部分重要特性
- Go 语言的交互式简介,它分为三节。第一节覆盖了基本语法及数据结构,第二节讨论了方法与接口, 第三节则简单介绍了 Go 的并发原语。每节末尾都有几个练习,你可以对自己的所学进行实践。 你可以 在线学习 或 安装到本地。
Go基础语法,方便查阅
包、变量和函数
- 学习 Go 程序的基本组件
1.包
- 每个 Go 程序都是由包组成的。
- 程序运行的入口是包 main。
- 这个程序使用并导入了包 "fmt" 和 "math/rand" 。
- 按照惯例,包名与导入路径的最后一个目录一致。例如,"math/rand" 包由 package rand 语句开始。
- 注意:这个程序的运行环境是确定性的,因此 rand.Intn每次都会返回相同的数字。 (为了得到不同的随机数,需要提供一个随机数种子,参阅 rand.Seed。)
package main
import (
"fmt"
"math/rand"
)
func main() {
fmt.Println("My favorite number is", rand.Intn(10))
}
- 结果
My favorite number is 1
2.导入
- 这个代码用圆括号组合了导入,这是“打包”导入语句。
- 同样可以编写多个导入语句,例如:
import "fmt"
import "math"
- 不过使用打包的导入语句是更好的形式。
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("Now you have %g problems.", math.Sqrt(7))
}
- 结果
Now you have 2.6457513110645907 problems.
3.导出名
- 在 Go 中,首字母大写的名称是被导出的。
- 在导入包之后,你只能访问包所导出的名字,任何未导出的名字是不能被包外的代码访问的。
- Foo 和 FOO 都是被导出的名称。名称 foo是不会被导出的。执行代码,注意编译器报的错误。然后将 math.pi改名为 math.Pi再试着执行一下。
package main
import (
"fmt"
"math"
)
func main() {
fmt.Println(math.pi)
}
- 结果
tmp/sandbox583763709/main.go:9: cannot refer to unexported name math.pi
tmp/sandbox583763709/main.go:9: undefined: math.pi
4.函数
- 函数可以没有参数或接受多个参数。
- 在这个例子中, add接受两个 int类型的参数。
- 注意类型在变量名 之后 。
- (参考 这篇关于 Go 语法定义的文章了解类型以这种形式出现的原因。)
package main
import "fmt"
func add(x int, y int) int {
return x + y
}
func main() {
fmt.Println(add(42, 13))
}
- 结果
55
5.函数(续)
- 当两个或多个连续的函数命名参数是同一类型,则除了最后一个类型之外,其他都可以省略。
- 在这个例子中 ,
x int, y int
被缩写为
x, y int
package main
import "fmt"
func add(x, y int) int {
return x + y
}
func main() {
fmt.Println(add(42, 13))
}
- 结果
55
6.多值返回
- 函数可以返回任意数量的返回值。
-
swap函数返回了两个字符串。
package main
import "fmt"
func swap(x, y string) (string, string) {
return y, x
}
func main() {
a, b := swap("hello", "world")
fmt.Println(a, b)
}
- 结果
world hello
7.命名返回值
- Go 的返回值可以被命名,并且就像在函数体开头声明的变量那样使用。
- 返回值的名称应当具有一定的意义,可以作为文档使用。
- 没有参数的 return语句返回各个返回变量的当前值。这种用法被称作“裸”返回。
- 直接返回语句仅应当用在像下面这样的短函数中。在长的函数中它们会影响代码的可读性。
package main
import "fmt"
func split(sum int) (x, y int) {
x = sum * 4 / 9
y = sum - x
return
}
func main() {
fmt.Println(split(17))
}
- 结果
7 10
8.变量
- var 语句定义了一个变量的列表;跟函数的参数列表一样,类型在后面。
- 就像在这个例子中看到的一样, var 语句可以定义在包或函数级别。
package main
import "fmt"
var c, python, java bool
func main() {
var i int
fmt.Println(i, c, python, java)
}
- 结果
0 false false false
9.初始化变量
- 变量定义可以包含初始值,每个变量对应一个。
- 如果初始化是使用表达式,则可以省略类型;变量从初始值中获得类型。
package main
import "fmt"
var i, j int = 1, 2
func main() {
var c, python, java = true, false, "no!"
fmt.Println(i, j, c, python, java)
}
- 结果
1 2 true false no!
10.短声明变量
- 在函数中, :=简洁赋值语句在明确类型的地方,可以用于替代 var
定义。 - 函数外的每个语句都必须以关键字开始( var、 func、等等), :=结构不能使用在函数外
package main
import "fmt"
func main() {
var i, j int = 1, 2
k := 3
c, python, java := true, false, "no!"
fmt.Println(i, j, k, c, python, java)
}
- 结果
1 2 3 true false no!
11.基本类型
- Go 的基本类型有Basic types
- bool
- string
- int int8 int16 int32 int64
- uint uint8 uint16 uint32 uint64 uintptr
- byte // uint8 的别名
- rune // int32 的别名
- // 代表一个Unicode码
- float32 float64
- complex64 complex128
- 这个例子演示了具有不同类型的变量。 同时与导入语句一样,变量的定义“打包”在一个语法块中。
- int,uint 和 uintptr类型在32位的系统上一般是32位,而在64位系统上是64位。当你需要使用一个整数类型时,你应该首选 int,仅当有特别的理由才使用定长整数类型或者无符号整数类型。
package main
import (
"fmt"
"math/cmplx"
)
var (
ToBe bool = false
MaxInt uint64 = 1<<64 - 1
z complex128 = cmplx.Sqrt(-5 + 12i)
)
func main() {
const f = "%T(%v)\n"
fmt.Printf(f, ToBe, ToBe)
fmt.Printf(f, MaxInt, MaxInt)
fmt.Printf(f, z, z)
}
- 结果
bool(false)
uint64(18446744073709551615)
complex128((2+3i))
12.类型转换
- 表达式 T(v)将值 v 转换为类型 T 。
- 一些关于数值的转换:
- var i int = 42
- var f float64 = float64(i)
- var u uint = uint(f)
- 或者,更加简单的形式:
- i := 42
- f := float64(i)
- u := uint(f)
- 与 C 不同的是 Go 的在不同类型之间的项目赋值时需要显式转换。 试着移除例子中 float64 或 int 的转换看看会发生什么。
package main
import (
"fmt"
"math"
)
func main() {
var x, y int = 3, 4
var f float64 = math.Sqrt(float64(x*x + y*y))
var z uint = uint(f)
fmt.Println(x, y, z)
}
- 结果
3 4 5
13.零值
- 变量在定义时没有明确的初始化时会赋值为 零值 。
- 零值是:
- 数值类型为 0,
- 布尔类型为 false ,
- 字符串为 ""(空字符串)。
package main
import "fmt"
func main() {
var i int
var f float64
var b bool
var s string
fmt.Printf("%v %v %v %q\n", i, f, b, s)
}
- 结果
0 0 false ""
14.类型推导
- 在定义一个变量却并不显式指定其类型时(使用 :=语法或者 var =表达式语法), 变量的类型由(等号)右侧的值推导得出。
- 当右值定义了类型时,新变量的类型与其相同:
var i int
j := i // j 也是一个 int
- 但是当右边包含了未指名类型的数字常量时,新的变量就可能是 int、 float64或 complex128。 这取决于常量的精度:
i := 42 // int
f := 3.142 // float64
g := 0.867 + 0.5i // complex128
- 尝试修改演示代码中 v的初始值,并观察这是如何影响其类型的。
package main
import "fmt"
func main() {
v := 42 // change me!
fmt.Printf("v is of type %T\n", v)
}
- 结果
v is of type int
15.常量
- 常量的定义与变量类似,只不过使用 const关键字。
- 常量可以是字符、字符串、布尔或数字类型的值。
- 常量不能使用 :=语法定义。
package main
import "fmt"
const Pi = 3.14
func main() {
const World = "世界"
fmt.Println("Hello", World)
fmt.Println("Happy", Pi, "Day")
const Truth = true
fmt.Println("Go rules?", Truth)
}
- 结果
Hello 世界
Happy 3.14 Day
Go rules? true
16.数值常量
- 数值常量是高精度的 值 。
- 一个未指定类型的常量由上下文来决定其类型。
- 也尝试一下输出
needInt(Big)吧。 - (int可以存放最大64位的整数,根据平台不同有时会更少。)
package main
import "fmt"
const (
Big = 1 << 100
Small = Big >> 99
)
func needInt(x int) int { return x*10 + 1 }
func needFloat(x float64) float64 {
return x * 0.1
}
func main() {
fmt.Println(needInt(Small))
fmt.Println(needFloat(Small))
fmt.Println(needFloat(Big))
}
- 结果
21
0.2
1.2676506002282295e+29
流程控制语句:for、if、else 、switch 和 defer
- 学习如何用条件、循环、开关和推迟语句控制代码的流程。
1.for
- Go 只有一种循环结构—— for循环。
- 基本的 for循环包含三个由分号分开的组成部分:
- 初始化语句:在第一次循环执行前被执行
- 循环条件表达式:每轮迭代开始前被求值
- 后置语句:每轮迭代后被执行
- 初始化语句一般是一个短变量声明,这里声明的变量仅在整个 for循环语句可见。
- 如果条件表达式的值变为 false,那么迭代将终止。
- 注意:不像 C,Java,或者 Javascript 等其他语言,for语句的三个组成部分 并不需要用括号括起来,但循环体必须用 { }括起来。
package main
import "fmt"
func main() {
sum := 0
for i := 0; i < 10; i++ {
sum += i
}
fmt.Println(sum)
}
- 结果
45
2.for(续)
- 循环初始化语句和后置语句都是可选的。
package main
import "fmt"
func main() {
sum := 1
for ; sum < 1000; {
sum += sum
}
fmt.Println(sum)
}
- 结果
1024
3.for 是 Go 的 “while”
- 基于此可以省略分号:C 的 while在 Go 中叫做 for。
package main
import "fmt"
func main() {
sum := 1
for sum < 1000 {
sum += sum
}
fmt.Println(sum)
}
- 结果
1024
- 無窮迴圈
- 如果省略了循環條件,循環就不會結束,因此可以用更簡潔地形式表達無窮迴圈。
package main
func main() {
for {
}
}
- 结果
process took too long
4.if
- 就像 for循环一样,Go 的 if语句也不要求用 ( )将条件括起来,同时, { }还是必须有的
package main
import (
"fmt"
"math"
)
func sqrt(x float64) string {
if x < 0 {
return sqrt(-x) + "i"
}
return fmt.Sprint(math.Sqrt(x))
}
func main() {
fmt.Println(sqrt(2), sqrt(-4))
}
- 结果
1.4142135623730951 2i
5.if 的便捷语句
- 跟 for一样, if语句可以在条件之前执行一个简单语句。
- 由这个语句定义的变量的作用域仅在 if范围之内。
- (在最后的 return语句处使用 v看看。)
package main
import (
"fmt"
"math"
)
func pow(x, n, lim float64) float64 {
if v := math.Pow(x, n); v < lim {
return v
}
return lim
}
func main() {
fmt.Println(
pow(3, 2, 10),
pow(3, 3, 20),
)
}
- 结果
9 20
6.if 和 else
- 在 if的便捷语句定义的变量同样可以在任何对应的 else块中使用。
- (提示:两个 pow调用都在 main调用 fmt.Println前执行完毕了。)
package main
import (
"fmt"
"math"
)
func pow(x, n, lim float64) float64 {
if v := math.Pow(x, n); v < lim {
return v
} else {
fmt.Printf("%g >= %g\n", v, lim)
}
// 这里开始就不能使用 v 了
return lim
}
func main() {
fmt.Println(
pow(3, 2, 10),
pow(3, 3, 20),
)
}
- 结果
27 >= 20
9 20
7.switch
- 你可能已经知道 switch语句会长什么样了。
- 除非以 fallthrough语句结束,否则分支会自动终止
package main
import (
"fmt"
"runtime"
)
func main() {
fmt.Print("Go runs on ")
switch os := runtime.GOOS; os {
case "darwin":
fmt.Println("OS X.")
case "linux":
fmt.Println("Linux.")
default:
// freebsd, openbsd,
// plan9, windows...
fmt.Printf("%s.", os)
}
}
- 结果
Go runs on nacl.
8.switch 的执行顺序
- switch 的条件从上到下的执行,当匹配成功的时候停止。
(例如,
switch i {case 0:case f():}
当 i==0
时不会调用 f
。) - 注意:Go playground 中的时间总是从 2009-11-10 23:00:00 UTC 开始, 如何校验这个值作为一个练习留给读者完成。
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("When's Saturday?")
today := time.Now().Weekday()
switch time.Saturday {
case today + 0:
fmt.Println("Today.")
case today + 1:
fmt.Println("Tomorrow.")
case today + 2:
fmt.Println("In two days.")
default:
fmt.Println("Too far away.")
}
}
- 结果
When's Saturday?
Too far away.
9.没有条件的 switch
- 没有条件的 switch 同 switch true一样。
- 这一构造使得可以用更清晰的形式来编写长的 if-then-else 链。
package main
import (
"fmt"
"time"
)
func main() {
t := time.Now()
switch {
case t.Hour() < 12:
fmt.Println("Good morning!")
case t.Hour() < 17:
fmt.Println("Good afternoon.")
default:
fmt.Println("Good evening.")
}
}
- 结果
Good evening.
10.defer
- defer 语句会延迟函数的执行直到上层函数返回。
- 延迟调用的参数会立刻生成,但是在上层函数返回前函数都不会被调用。
package main
import "fmt"
func main() {
defer fmt.Println("world")
fmt.Println("hello")
}
- 结果
hello
world
11.defer 栈
- 延迟的函数调用被压入一个栈中。当函数返回时, 会按照后进先出的顺序调用被延迟的函数调用。
- 阅读博文了解更多关于 defer
语句的信息。
package main
import "fmt"
func main() {
fmt.Println("counting")
for i := 0; i < 10; i++ {
defer fmt.Println(i)
}
fmt.Println("done")
}
- 结果
counting
done
9
8
7
6
5
4
3
2
1
0
复杂类型: struct、slice 和 map。
- 学习如何基于已有类型定义新的类型:本课涵盖了结构体、数组、slice 和 map。
1.指针
- Go 具有指针。 指针保存了变量的内存地址。
- 类型
*T是指向类型 T的值的指针。其零值是 nil。
var p *int
-
&符号会生成一个指向其作用对象的指针。
i := 42p = &i
-
*符号表示指针指向的底层的值。
fmt.Println(*p) // 通过指针 p 读取 i*p = 21 // 通过指针 p 设置 i
- 这也就是通常所说的“间接引用”或“非直接引用”。
- 与 C 不同,Go 没有指针运算。
package main
import "fmt"
func main() {
i, j := 42, 2701
p := &i // point to i
fmt.Println(*p) // read i through the pointer
*p = 21 // set i through the pointer
fmt.Println(i) // see the new value of i
p = &j // point to j
*p = *p / 37 // divide j through the pointer
fmt.Println(j) // see the new value of j
}
- 结果
42
21
73
2.结构体
- 一个结构体( struct)就是一个字段的集合。
- (而 type的含义跟其字面意思相符。
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
fmt.Println(Vertex{1, 2})
}
- 结果
{1 2}
3.结构体字段
- 结构体字段使用点号来访问。
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
v := Vertex{1, 2}
v.X = 4
fmt.Println(v.X)
}
- 结果
4
4.结构体指针
- 结构体字段可以通过结构体指针来访问。
- 通过指针间接的访问是透明的。
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
v := Vertex{1, 2}
p := &v
p.X = 1e9
fmt.Println(v)
}
- 结果
{1000000000 2}
5.结构体文法
- 结构体文法表示通过结构体字段的值作为列表来新分配一个结构体。
- 使用 Name:语法可以仅列出部分字段。(字段名的顺序无关。)
- 特殊的前缀
&返回一个指向结构体的指针。
package main
import "fmt"
type Vertex struct {
X, Y int
}
var (
v1 = Vertex{1, 2} // 类型为 Vertex
v2 = Vertex{X: 1} // Y:0 被省略
v3 = Vertex{} // X:0 和 Y:0
p = &Vertex{1, 2} // 类型为 *Vertex
)
func main() {
fmt.Println(v1, p, v2, v3)
}
- 结果
{1 2} &{1 2} {1 0} {0 0}
6.数组
- 类型 [n]T是一个有 n个类型为 T的值的数组。
- 表达式
var a [10]int
- 定义变量 a是一个有十个整数的数组。
- 数组的长度是其类型的一部分,因此数组不能改变大小。 这看起来是一个制约,但是请不要担心; Go 提供了更加便利的方式来使用数组。
package main
import "fmt"
func main() {
var a [2]string
a[0] = "Hello"
a[1] = "World"
fmt.Println(a[0], a[1])
fmt.Println(a)
}
- 结果
Hello World
[Hello World]
7.slice
- 一个 slice 会指向一个序列的值,并且包含了长度信息。
-
[]T是一个元素类型为 T的 slice。 -
len(s)返回 slice s 的长度。
package main
import "fmt"
func main() {
s := []int{2, 3, 5, 7, 11, 13}
fmt.Println("s ==", s)
for i := 0; i < len(s); i++ {
fmt.Printf("s[%d] == %d\n", i, s[i])
}
}
- 结果
s == [2 3 5 7 11 13]
s[0] == 2
s[1] == 3
s[2] == 5
s[3] == 7
s[4] == 11
s[5] == 13
8.slice 的 slice
- slice 可以包含任意的类型,包括另一个 slice。
package main
import (
"fmt"
"strings"
)
func main() {
// Create a tic-tac-toe board.
game := [][]string{
[]string{"_", "_", "_"},
[]string{"_", "_", "_"},
[]string{"_", "_", "_"},
}
// The players take turns.
game[0][0] = "X"
game[2][2] = "O"
game[2][0] = "X"
game[1][0] = "O"
game[0][2] = "X"
printBoard(game)
}
func printBoard(s [][]string) {
for i := 0; i < len(s); i++ {
fmt.Printf("%s\n", strings.Join(s[i], " "))
}
}
- 结果
X _ X
O _ _
X _ O
9.对 slice 切片
- slice 可以重新切片,创建一个新的 slice 值指向相同的数组。
- 表达式
s[lo:hi]
- 表示从 lo到 hi-1的 slice 元素,含前端,不包含后端。因此
s[lo:lo]- 是空的,而
s[lo:lo+1]
- 有一个元素。
package main
import "fmt"
func main() {
s := []int{2, 3, 5, 7, 11, 13}
fmt.Println("s ==", s)
fmt.Println("s[1:4] ==", s[1:4])
// 省略下标代表从 0 开始
fmt.Println("s[:3] ==", s[:3])
// 省略上标代表到 len(s) 结束
fmt.Println("s[4:] ==", s[4:])
}
- 结果
s == [2 3 5 7 11 13]
s[1:4] == [3 5 7]
s[:3] == [2 3 5]
s[4:] == [11 13]
10.构造 slice
- slice 由函数
make创建。这会分配一个全是零值的数组并且返回一个 slice 指向这个数组:
a := make([]int, 5) // len(a)=5
- 为了指定容量,可传递第三个参数到 make:
b := make([]int, 0, 5) // len(b)=0, cap(b)=5
b = b[:cap(b)] // len(b)=5, cap(b)=5
b = b[1:] // len(b)=4, cap(b)=4
package main
import "fmt"
func main() {
a := make([]int, 5)
printSlice("a", a)
b := make([]int, 0, 5)
printSlice("b", b)
c := b[:2]
printSlice("c", c)
d := c[2:5]
printSlice("d", d)
}
func printSlice(s string, x []int) {
fmt.Printf("%s len=%d cap=%d %v\n",
s, len(x), cap(x), x)
}
- 结果
a len=5 cap=5 [0 0 0 0 0]
b len=0 cap=5 []
c len=2 cap=5 [0 0]
d len=3 cap=3 [0 0 0]
11.nil slice
- slice 的零值是 nil 。
- 一个 nil 的 slice 的长度和容量是 0。
package main
import "fmt"
func main() {
var z []int
fmt.Println(z, len(z), cap(z))
if z == nil {
fmt.Println("nil!")
}
}
- 结果
[] 0 0
nil!
12.向 slice 添加元素
- 向 slice 的末尾添加元素是一种常见的操作,因此 Go 提供了一个内建函数
append。 内建函数的文档对append有详细介绍。
func append(s []T, vs ...T) []T
-
append的第一个参数 s是一个元素类型为 T的 slice ,其余类型为 T的值将会附加到该 slice 的末尾。 -
append的结果是一个包含原 slice 所有元素加上新添加的元素的 slice。 - 如果
s的底层数组太小,而不能容纳所有值时,会分配一个更大的数组。 返回的 slice 会指向这个新分配的数组。 - (了解更多关于 slice 的内容,参阅文章Go 切片:用法和本质。)
package main
import "fmt"
func main() {
var a []int
printSlice("a", a)
// append works on nil slices.
a = append(a, 0)
printSlice("a", a)
// the slice grows as needed.
a = append(a, 1)
printSlice("a", a)
// we can add more than one element at a time.
a = append(a, 2, 3, 4)
printSlice("a", a)
}
func printSlice(s string, x []int) {
fmt.Printf("%s len=%d cap=%d %v\n",
s, len(x), cap(x), x)
}
- 结果
a len=0 cap=0 []
a len=1 cap=2 [0]
a len=2 cap=2 [0 1]
a len=5 cap=8 [0 1 2 3 4]
Go 切片:用法和本质
引言
- Go的切片类型为处理同类型数据序列提供一个方便而高效的方式。 切片有些类似于其他语言中的数组,但是有一些不同寻常的特性。 本文将深入切片的本质,并讲解它的用法。
数组
- Go的切片是在数组之上的抽象数据类型,因此在了解切片之前必须要先理解数组。
- 数组类型定义了长度和元素类型。例如, [4]int 类型表示一个四个整数的数组。 数组的长度是固定的,长度是数组类型的一部分( [4]int和 [5]int
是完全不同的类型)。 数组可以以常规的索引方式访问,表达式 s[n]
访问数组的第 n 个元素。
var a [4]int
a[0] = 1
i := a[0]
// i == 1
- 数组不需要显式的初始化;数组的零值是可以直接使用的,数组元素会自动初始化为其对应类型的零值:
// a[2] == 0, int 类型的零值
- 类型 [4]int对应内存中四个连续的整数:

类型 [4]int对应内存中四个连续的整数
- Go的数组是值语义。一个数组变量表示整个数组,它不是指向第一个元素的指针(不像 C 语言的数组)。 当一个数组变量被赋值或者被传递的时候,实际上会复制整个数组。 (为了避免复制数组,你可以传递一个指向数组的指针,但是数组指针并不是数组。) 可以将数组看作一个特殊的struct,结构的字段名对应数组的索引,同时成员的数目固定。
- 数组的字面值像这样:
b := [2]string{"Penn", "Teller"}
- 当然,也可以让编译器统计数组字面值中元素的数目:
b := [...]string{"Penn", "Teller"}
- 这两种写法, b都是对应 [2]string类型。
切片
- 数组虽然有适用它们的地方,但是数组不够灵活,因此在Go代码中数组使用的并不多。 但是,切片则使用得相当广泛。切片基于数组构建,但是提供更强的功能和便利。
- 切片类型的写法是 []T, T是切片元素的类型。和数组不同的是,切片类型并没有给定固定的长度。
- 切片的字面值和数组字面值很像,不过切片没有指定元素个数:
letters := []string{"a", "b", "c", "d"}
- 切片可以使用内置函数 make创建,函数签名为:
func make([]T, len, cap) []T
- 其中T代表被创建的切片元素的类型。函数 make接受一个类型、一个长度和一个可选的容量参数。 调用 make时,内部会分配一个数组,然后返回数组对应的切片。
var s []bytes = make([]byte, 5, 5)// s == []byte{0, 0, 0, 0, 0}
- 当容量参数被忽略时,它默认为指定的长度。下面是简洁的写法:
s := make([]byte, 5)
- 可以使用内置函数
len和cap获取切片的长度和容量信息。
len(s) == 5
cap(s) == 5
- 接下来的两个小节将讨论长度和容量之间的关系。
- 切片的零值为
nil。对于切片的零值,len和cap都将返回0。 - 切片也可以基于现有的切片或数组生成。切分的范围由两个由冒号分割的索引对应的半开区间指定。 例如,表达式
b[1:4]创建的切片引用数组 b
的第1到3个元素空间(对应切片的索引为0到2)。
b := []byte{'g', 'o', 'l', 'a', 'n', 'g'}
// b[1:4] == []byte{'o', 'l', 'a'}, sharing the same storage as b
- 切片的开始和结束的索引都是可选的;它们分别默认为零和数组的长度。
// b[:2] == []byte{'g', 'o'}
// b[2:] == []byte{'l', 'a', 'n', 'g'}
// b[:] == b
- 下面语法也是基于数组创建一个切片:
x := [3]string{"Лайка", "Белка", "Стрелка"}
s := x[:] // a slice referencing the storage of x
切片的内幕
- 一个切片是一个数组片段的描述。它包含了指向数组的指针,片段的长度, 和容量(片段的最大长度)。

切片是一个数组片段的描述
- 前面使用 make([]byte, 5)创建的切片变量 s的结构如下:
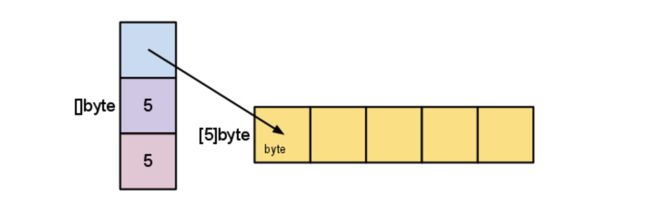
s的结构
- 长度是切片引用的元素数目。容量是底层数组的元素数目(从切片指针开始)。 关于长度和容量和区域将在下一个例子说明。
- 我们继续对 s进行切片,观察切片的数据结构和它引用的底层数组:
s = s[2:4]
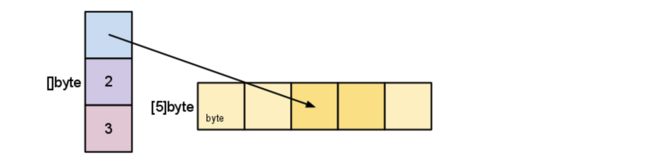
数据结构和它引用的底层数组
- 切片操作并不复制切片指向的元素。它创建一个新的切片并复用原来切片的底层数组。 这使得切片操作和数组索引一样高效。因此,通过一个新切片修改元素会影响到原始切片的对应元素。
d := []byte{'r', 'o', 'a', 'd'}
e := d[2:]
// e == []byte{'a', 'd'}
e[1] = 'm'
// e == []byte{'a', 'm'}
// d == []byte{'r', 'o', 'a', 'm'}
- 前面创建的切片 s长度小于它的容量。我们可以增长切片的长度为它的容量:
s = s[:cap(s)]
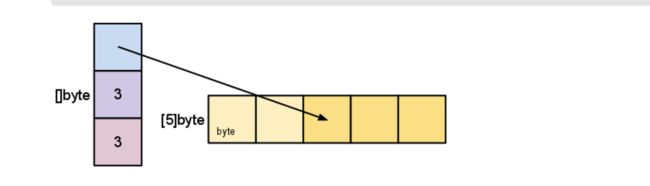
- 切片增长不能超出其容量。增长超出切片容量将会导致运行时异常,就像切片或数组的索引超 出范围引起异常一样。同样,不能使用小于零的索引去访问切片之前的元素。
切片的生长(copy and append 函数)
- 要增加切片的容量必须创建一个新的、更大容量的切片,然后将原有切片的内容复制到新的切片。 整个技术是一些支持动态数组语言的常见实现。下面的例子将切片 s容量翻倍,先创建一个2倍 容量的新切片 t,复制 s的元素到 t,然后将 t赋值给 s:
t := make([]byte, len(s), (cap(s)+1)*2) // +1 in case cap(s) == 0
for i := range s {
t[i] = s[i]
}
s = t
- 循环中复制的操作可以由 copy 内置函数替代。copy 函数将源切片的元素复制到目的切片。 它返回复制元素的数目。
func copy(dst, src []T) int
-
copy函数支持不同长度的切片之间的复制(它只复制较短切片的长度个元素)。 此外,copy函数可以正确处理源和目的切片有重叠的情况。 - 使用 copy函数,我们可以简化上面的代码片段:
t := make([]byte, len(s), (cap(s)+1)*2)
copy(t, s)
s = t
- 一个常见的操作是将数据追加到切片的尾部。下面的函数将元素追加到切片尾部, 必要的话会增加切片的容量,最后返回更新的切片:
func AppendByte(slice []byte, data ...byte) []byte {
m := len(slice)
n := m + len(data)
if n > cap(slice) { // if necessary, reallocate
// allocate double what's needed, for future growth.
newSlice := make([]byte, (n+1)*2)
copy(newSlice, slice) slice = newSlice
}
slice = slice[0:n]
copy(slice[m:n], data)
return slice
}
- 下面是 AppendByte的一种用法:
p := []byte{2, 3, 5}
p = AppendByte(p, 7, 11, 13)
// p == []byte{2, 3, 5, 7, 11, 13}
- 类似 AppendByte的函数比较实用,因为它提供了切片容量增长的完全控制。 根据程序的特点,可能希望分配较小的活较大的块,或则是超过某个大小再分配。
- 但大多数程序不需要完全的控制,因此Go提供了一个内置函数 append, 用于大多数场合;它的函数签名:
func append(s []T, x ...T) []T
- append函数将 x追加到切片 s的末尾,并且在必要的时候增加容量。
a := make([]int, 1)
// a == []int{0}
a = append(a, 1, 2, 3)
// a == []int{0, 1, 2, 3}
- 如果是要将一个切片追加到另一个切片尾部,需要使用 ...语法将第2个参数展开为参数列表。
a := []string{"John", "Paul"}
b := []string{"George", "Ringo", "Pete"}
a = append(a, b...) // equivalent to "append(a, b[0], b[1], b[2])"
// a == []string{"John", "Paul", "George", "Ringo", "Pete"}
- 由于切片的零值 nil用起来就像一个长度为零的切片,我们可以声明一个切片变量然后在循环 中向它追加数据:
// Filter returns a new slice holding only
// the elements of s that satisfy f()
func Filter(s []int, fn func(int) bool) []int {
var p []int // == nil
for _, v := range s {
if fn(v) { p = append(p, v)
}
}
return p
}
可能的“陷阱”
- 正如前面所说,切片操作并不会复制底层的数组。整个数组将被保存在内存中,直到它不再被引用。 有时候可能会因为一个小的内存引用导致保存所有的数据。
- 例如,
FindDigits函数加载整个文件到内存,然后搜索第一个连续的数字,最后结果以切片方式返回。
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
- 这段代码的行为和描述类似,返回的
[]byte指向保存整个文件的数组。因为切片引用了原始的数组, 导致 GC 不能释放数组的空间;只用到少数几个字节却导致整个文件的内容都一直保存在内存里。 - 要修复整个问题,可以将感兴趣的数据复制到一个新的切片中:
func CopyDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
copy(c, b) return c
}
- 可以使用 append实现一个更简洁的版本。这留给读者作为练习。
延伸阅读
- 实效 Go 编程 包含了对 切片和 数组更深入的探讨; Go 编程语言规范对 切片类型和 数组类型 以及操作他们的内建函数(len/cap, make和 copy/append) 进行了定义。
- 本文由 Go-zh 项目组 翻译,转载请注明出处。
13.range
- for循环的 range格式可以对 slice 或者 map 进行迭代循环。
- 当使用 for循环遍历一个 slice 时,每次迭代 range将返回两个值。 第一个是当前下标(序号),第二个是该下标所对应元素的一个拷贝。
package main
import "fmt"
var pow = []int{1, 2, 4, 8, 16, 32, 64, 128}
func main() {
for i, v := range pow {
fmt.Printf("2**%d = %d\n", i, v)
}
}
- 结果
2**0 = 1
2**1 = 2
2**2 = 4
2**3 = 8
2**4 = 16
2**5 = 32
2**6 = 64
2**7 = 128
14.range(续)
- 可以通过赋值给 _来忽略序号和值。
- 如果只需要索引值,去掉 “ , value ” 的部分即可。
package main
import "fmt"
func main() {
pow := make([]int, 10)
for i := range pow {
pow[i] = 1 << uint(i)
}
for _, value := range pow {
fmt.Printf("%d\n", value)
}
}
- 结果
1
2
4
8
16
32
64
128
256
512
15.map
- map 映射键到值。
- map 在使用之前必须用 make来创建;值为 nil的 map 是空的,并且不能对其赋值。
package main
import "fmt"
type Vertex struct {
Lat, Long float64
}
var m map[string]Vertex
func main() {
m = make(map[string]Vertex)
m["Bell Labs"] = Vertex{
40.68433, -74.39967,
}
fmt.Println(m["Bell Labs"])
}
- 结果
{40.68433 -74.39967}
16.map 的文法
- map 的文法跟结构体文法相似,不过必须有键名
package main
import "fmt"
type Vertex struct {
Lat, Long float64
}
var m = map[string]Vertex{
"Bell Labs": Vertex{
40.68433, -74.39967,
},
"Google": Vertex{
37.42202, -122.08408,
},
}
func main() {
fmt.Println(m)
}
- 结果
map[Bell Labs:{40.68433 -74.39967} Google:{37.42202 -122.08408}]
17.map 的文法(续)
- 若顶级类型只是一个类型名,你可以在文法的元素中省略它。
package main
import "fmt"
type Vertex struct {
Lat, Long float64
}
var m = map[string]Vertex{
"Bell Labs": {40.68433, -74.39967},
"Google": {37.42202, -122.08408},
}
func main() {
fmt.Println(m)
}
- 结果
map[Bell Labs:{40.68433 -74.39967} Google:{37.42202 -122.08408}]
18.修改 map
- 在 map m中插入或修改一个元素:
m[key] = elem
- 获得元素:
elem = m[key]
- 删除元素:
delete(m, key)
- 通过双赋值检测某个键存在:
elem, ok = m[key]
- 如果 key在 m中, ok为 true。否则, ok为 false,并且 elem是 map 的元素类型的零值。
- 同样的,当从 map 中读取某个不存在的键时,结果是 map 的元素类型的零值。
package main
import "fmt"
func main() {
m := make(map[string]int)
m["Answer"] = 42
fmt.Println("The value:", m["Answer"])
m["Answer"] = 48
fmt.Println("The value:", m["Answer"])
delete(m, "Answer")
fmt.Println("The value:", m["Answer"])
v, ok := m["Answer"]
fmt.Println("The value:", v, "Present?", ok)
}
- 结果
The value: 42
The value: 48
The value: 0
The value: 0 Present? false
19.函数值
- 函数也是值。他们可以像其他值一样传递,比如,函数值可以作为函数的参数或者返回值。
package main
import (
"fmt"
"math"
)
func compute(fn func(float64, float64) float64) float64 {
return fn(3, 4)
}
func main() {
hypot := func(x, y float64) float64 {
return math.Sqrt(x*x + y*y)
}
fmt.Println(hypot(5, 12))
fmt.Println(compute(hypot))
fmt.Println(compute(math.Pow))
}
- 结果
13
5
81
20.函数的闭包
- Go 函数可以是一个闭包。闭包是一个函数值,它引用了函数体之外的变量。 这个函数可以对这个引用的变量进行访问和赋值;换句话说这个函数被“绑定”在这个变量上。
- 例如,函数
adder返回一个闭包。每个返回的闭包都被绑定到其各自的sum变量上。
package main
import "fmt"
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
pos, neg := adder(), adder()
for i := 0; i < 10; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
}
- 结果
1 -2
3 -6
6 -12
10 -20
15 -30
21 -42
28 -56
36 -72
45 -90
方法和接口
- 学习如何为类型定义方法;如何定义接口;可以用它们来定义对象和其行为。
1.方法
- Go 没有类。然而,仍然可以在结构体类型上定义方法。
- 方法接收者 出现在 func关键字和方法名之间的参数中。
package main
import (
"fmt"
"math"
)
type Vertex struct {
X, Y float64
}
func (v *Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func main() {
v := &Vertex{3, 4}
fmt.Println(v.Abs())
}
- 结果:
5
2.方法(续)
- 你可以对包中的 任意 类型定义任意方法,而不仅仅是针对结构体。
- 但是,不能对来自其他包的类型或基础类型定义方法。
package main
import (
"fmt"
"math"
)
type MyFloat float64
func (f MyFloat) Abs() float64 {
if f < 0 {
return float64(-f)
}
return float64(f)
}
func main() {
f := MyFloat(-math.Sqrt2)
fmt.Println(f.Abs())
}
- 结果:
1.4142135623730951
3.接收者为指针的方法
- 方法可以与命名类型或命名类型的指针关联。
- 刚刚看到的两个 Abs方法。一个是在
*Vertex指针类型上,而另一个在MyFloat值类型上。 有两个原因需要使用指针接收者。首先避免在每个方法调用中拷贝值(如果值类型是大的结构体的话会更有效率)。其次,方法可以修改接收者指向的值。 - 尝试修改 Abs的定义,同时
Scale方法使用Vertex代替*Vertex作为接收者。 - 当 v是
Vertex的时候Scale方法没有任何作用。Scale修改 v。当 v是一个值(非指针),方法看到的是 Vertex的副本,并且无法修改原始值。 - Abs的工作方式是一样的。只不过,仅仅读取 v。所以读取的是原始值(通过指针)还是那个值的副本并没有关系。
package main
import (
"fmt"
"math"
)
type Vertex struct {
X, Y float64
}
func (v *Vertex) Scale(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
func (v *Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func main() {
v := &Vertex{3, 4}
fmt.Printf("Before scaling: %+v, Abs: %v\n", v, v.Abs())
v.Scale(5)
fmt.Printf("After scaling: %+v, Abs: %v\n", v, v.Abs())
}
- 结果:
Before scaling: &{X:3 Y:4}, Abs: 5
After scaling: &{X:15 Y:20}, Abs: 25
4.接口
- 接口类型是由一组方法定义的集合。
- 接口类型的值可以存放实现这些方法的任何值。
- 注意: 示例代码的 22 行存在一个错误。 由于 Abs只定义在
*Vertex(指针类型)上, 所以Vertex(值类型)不满足 Abser。
package main
import (
"fmt"
"math"
)
type Abser interface {
Abs() float64
}
func main() {
var a Abser
f := MyFloat(-math.Sqrt2)
v := Vertex{3, 4}
a = f // a MyFloat 实现了 Abser
a = &v // a *Vertex 实现了 Abser
// 下面一行,v 是一个 Vertex(而不是 *Vertex)
// 所以没有实现 Abser。
a = v
fmt.Println(a.Abs())
}
type MyFloat float64
func (f MyFloat) Abs() float64 {
if f < 0 {
return float64(-f)
}
return float64(f)
}
type Vertex struct {
X, Y float64
}
func (v *Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
- 结果:
5
5.隐式接口
- 类型通过实现那些方法来实现接口。 没有显式声明的必要;所以也就没有关键字“implements“。
- 隐式接口解藕了实现接口的包和定义接口的包:互不依赖。
- 因此,也就无需在每一个实现上增加新的接口名称,这样同时也鼓励了明确的接口定义。
- 包 io 定义了 Reader
和 Writer;其实不一定要这么做。
package main
import (
"fmt"
"os"
)
type Reader interface {
Read(b []byte) (n int, err error)
}
type Writer interface {
Write(b []byte) (n int, err error)
}
type ReadWriter interface {
Reader
Writer
}
func main() {
var w Writer
// os.Stdout 实现了 Writer
w = os.Stdout
fmt.Fprintf(w, "hello, writer\n")
}
- 结果:
hello, writer
6.Stringers
- 一个普遍存在的接口是 fmt
包中定义的 Stringer
。
type Stringer interface {
String() string
}
- Stringer是一个可以用字符串描述自己的类型。
fmt包 (还有许多其他包)使用这个来进行输出。
package main
import "fmt"
type Person struct {
Name string
Age int
}
func (p Person) String() string {
return fmt.Sprintf("%v (%v years)", p.Name, p.Age)
}
func main() {
a := Person{"Arthur Dent", 42}
z := Person{"Zaphod Beeblebrox", 9001}
fmt.Println(a, z)
}
- 结果:
Arthur Dent (42 years) Zaphod Beeblebrox (9001 years)
7.错误
- Go 程序使用 error值来表示错误状态。
- 与 fmt.Stringer类似, error类型是一个内建接口:
type error interface {
Error() string
}
- (与 fmt.Stringer类似,fmt包在输出时也会试图匹配 error。)
- 通常函数会返回一个 error值,调用的它的代码应当判断这个错误是否等于 nil, 来进行错误处理。
i, err := strconv.Atoi("42")
if err != nil {
fmt.Printf("couldn't convert number: %v\n", err)
return}
fmt.Println("Converted integer:", i)
- error 为 nil 时表示成功;非 nil 的 error表示错误。
package main
import (
"fmt"
"time"
)
type MyError struct {
When time.Time
What string
}
func (e *MyError) Error() string {
return fmt.Sprintf("at %v, %s",
e.When, e.What)
}
func run() error {
return &MyError{
time.Now(),
"it didn't work",
}
}
func main() {
if err := run(); err != nil {
fmt.Println(err)
}
}
- 结果:
at 2009-11-10 23:00:00 +0000 UTC, it didn't work
8.Readers
- io包指定了 io.Reader接口, 它表示从数据流结尾读取。
- Go 标准库包含了这个接口的许多实现, 包括文件、网络连接、压缩、加密等等。
- io.Reader接口有一个 Read方法:
func (T) Read(b []byte) (n int, err error)
- Read用数据填充指定的字节 slice,并且返回填充的字节数和错误信息。 在遇到数据流结尾时,返回 io.EOF错误。
- 例子代码创建了一个 strings.Reader。 并且以每次 8 字节的速度读取它的输出。
package main
import (
"fmt"
"io"
"strings"
)
func main() {
r := strings.NewReader("Hello, Reader!")
b := make([]byte, 8)
for {
n, err := r.Read(b)
fmt.Printf("n = %v err = %v b = %v\n", n, err, b)
fmt.Printf("b[:n] = %q\n", b[:n])
if err == io.EOF {
break
}
}
}
- 结果:
n = 8 err = b = [72 101 108 108 111 44 32 82]
b[:n] = "Hello, R"
n = 6 err = b = [101 97 100 101 114 33 32 82]
b[:n] = "eader!"
n = 0 err = EOF b = [101 97 100 101 114 33 32 82]
b[:n] = ""
9.Web 服务器
- 包 http 通过任何实现了 http.Handler
的值来响应 HTTP 请求:
package http
type Handler interface {
ServeHTTP(w ResponseWriter, r *Request)
}
- 在这个例子中,类型 Hello实现了 http.Handler。
- 访问 http://localhost:4000/ 会看到来自程序的问候。
- 注意: 这个例子无法在基于 web 的指南用户界面运行。为了尝试编写 web 服务器,可能需要安装 Go。
package main
import (
"fmt"
"log"
"net/http"
)
type Hello struct{}
func (h Hello) ServeHTTP(
w http.ResponseWriter,
r *http.Request) {
fmt.Fprint(w, "Hello!")
}
func main() {
var h Hello
err := http.ListenAndServe("localhost:4000", h)
if err != nil {
log.Fatal(err)
}
}
- 结果:
2009/11/10 23:00:00 listen tcp: Protocol not available
10.图片
- Package image 定义了 Image
接口:
package image
type Image interface {
ColorModel() color.Model
Bounds() Rectangle
At(x, y int) color.Color
}
- 注意:Bounds方法的 Rectangle返回值实际上是一个 image.Rectangle, 其定义在 image包中。
- (参阅文档了解全部信息。)
- color.Color和 color.Model也是接口,但是通常因为直接使用预定义的实现 image.RGBA和 image.RGBAModel而被忽视了。这些接口和类型由image/color包定义。
package main
import (
"fmt"
"image"
)
func main() {
m := image.NewRGBA(image.Rect(0, 0, 100, 100))
fmt.Println(m.Bounds())
fmt.Println(m.At(0, 0).RGBA())
}
- 结果:
(0,0)-(100,100)
0 0 0 0
并发
- 作为语言的核心部分,Go 提供了并发的特性。
- 这一部分概览了 goroutine 和 channel,以及如何使用它们来实现不同的并发模式。
- Go 将并发作为语言的核心构成。
1.goroutine
- goroutine 是由 Go 运行时环境管理的轻量级线程。
go f(x, y, z)
- 开启一个新的 goroutine 执行
f(x, y, z)
- f,x,y和 z是当前 goroutine 中定义的,但是在新的 goroutine 中运行 f。
- goroutine 在相同的地址空间中运行,因此访问共享内存必须进行同步。sync 提供了这种可能,不过在 Go 中并不经常用到,因为有其他的办法。(在接下来的内容中会涉及到。)
package main
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
}
- 结果:
hello
hello
world
world
hello
hello
world
world
hello
2.channel
- channel 是有类型的管道,可以用 channel 操作符 <-对其发送或者接收值。
ch <- v // 将 v 送入 channel ch。
v := <-ch // 从 ch 接收,并且赋值给 v。
- (“箭头”就是数据流的方向。)
- 和 map 与 slice 一样,channel 使用前必须创建:
ch := make(chan int)
- 默认情况下,在另一端准备好之前,发送和接收都会阻塞。这使得 goroutine 可以在没有明确的锁或竞态变量的情况下进行同步
package main
import "fmt"
func sum(a []int, c chan int) {
sum := 0
for _, v := range a {
sum += v
}
c <- sum // 将和送入 c
}
func main() {
a := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(a[:len(a)/2], c)
go sum(a[len(a)/2:], c)
x, y := <-c, <-c // 从 c 中获取
fmt.Println(x, y, x+y)
}
- 结果:
-5 17 12
3.缓冲 channel
- channel 可以是 带缓冲的。为 make提供第二个参数作为缓冲长度来初始化一个缓冲 channel:
ch := make(chan int, 100)
- 向带缓冲的 channel 发送数据的时候,只有在缓冲区满的时候才会阻塞。 而当缓冲区为空的时候接收操作会阻塞。
- 修改例子使得缓冲区被填满,然后看看会发生什么
package main
import "fmt"
func main() {
ch := make(chan int, 2)
ch <- 1
ch <- 2
fmt.Println(<-ch)
fmt.Println(<-ch)
}
- 结果:
1
2
-----------------
-----------------
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
/tmp/sandbox156608315/main.go:9 +0x100
4.range 和 close
- 发送者可以 close一个 channel 来表示再没有值会被发送了。接收者可以通过赋值语句的第二参数来测试 channel 是否被关闭:当没有值可以接收并且 channel 已经被关闭,那么经过
v, ok := <-ch
- 之后 ok会被设置为 false。
- 循环
for i := range c会不断从 channel 接收值,直到它被关闭。 - 注意: 只有发送者才能关闭 channel,而不是接收者。向一个已经关闭的 channel 发送数据会引起 panic。 还要注意: channel 与文件不同;通常情况下无需关闭它们。只有在需要告诉接收者没有更多的数据的时候才有必要进行关闭,例如中断一个 range。
package main
import (
"fmt"
)
func fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x+y
}
close(c)
}
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
for i := range c {
fmt.Println(i)
}
}
- 结果:
0
1
1
2
3
5
8
13
21
34
5.select
- select语句使得一个 goroutine 在多个通讯操作上等待。
- select会阻塞,直到条件分支中的某个可以继续执行,这时就会执行那个条件分支。当多个都准备好的时候,会随机选择一个
package main
import "fmt"
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
- 结果:
0
1
1
2
3
5
8
13
21
34
quit
6.默认选择
- 当 select中的其他条件分支都没有准备好的时候,default分支会被执行。
- 为了非阻塞的发送或者接收,可使用 default分支:
select {
case i := <-c:
// 使用 idefault:
// 从 c 读取会阻塞
}
package main
import (
"fmt"
"time"
)
func main() {
tick := time.Tick(100 * time.Millisecond)
boom := time.After(500 * time.Millisecond)
for {
select {
case <-tick:
fmt.Println("tick.")
case <-boom:
fmt.Println("BOOM!")
return
default:
fmt.Println(" .")
time.Sleep(50 * time.Millisecond)
}
}
}
- 结果:
.
.
tick.
.
.
tick.
.
.
tick.
.
.
tick.
.
.
tick.
BOOM!
7.sync.Mutex
我们已经看到 channel用来在各个 goroutine 间进行通信是非常合适的了。
但是如果我们并不需要通信呢?比如说,如果我们只是想保证在每个时刻,只有一个 goroutine 能访问一个共享的变量从而避免冲突?
这里涉及的概念叫做 互斥,通常使用 互斥锁(mutex)_来提供这个限制。
-
Go 标准库中提供了 sync.Mutex 类型及其两个方法:
- Lock
- Unlock
我们可以通过在代码前调用 Lock方法,在代码后调用 Unlock方法来保证一段代码的互斥执行。 参见 Inc方法。
我们也可以用 defer语句来保证互斥锁一定会被解锁。参见 Value方法。
package main
import (
"fmt"
"sync"
"time"
)
// SafeCounter 的并发使用是安全的。
type SafeCounter struct {
v map[string]int
mux sync.Mutex
}
// Inc 增加给定 key 的计数器的值。
func (c *SafeCounter) Inc(key string) {
c.mux.Lock()
// Lock 之后同一时刻只有一个 goroutine 能访问 c.v
c.v[key]++
c.mux.Unlock()
}
// Value 返回给定 key 的计数器的当前值。
func (c *SafeCounter) Value(key string) int {
c.mux.Lock()
// Lock 之后同一时刻只有一个 goroutine 能访问 c.v
defer c.mux.Unlock()
return c.v[key]
}
func main() {
c := SafeCounter{v: make(map[string]int)}
for i := 0; i < 1000; i++ {
go c.Inc("somekey")
}
time.Sleep(time.Second)
fmt.Println(c.Value("somekey"))
}
- 结果:
1000
8.练习:Web 爬虫
- 在这个练习中,将会使用 Go 的并发特性来并行执行 web 爬虫。
- 修改 Crawl函数来并行的抓取 URLs,并且保证不重复。
- 提示:你可以用一个 map 来缓存已经获取的 URL,但是需要注意 map 本身并不是并发安全的!
package main
import (
"fmt"
)
type Fetcher interface {
// Fetch 返回 URL 的 body 内容,并且将在这个页面上找到的 URL 放到一个 slice 中。
Fetch(url string) (body string, urls []string, err error)
}
// Crawl 使用 fetcher 从某个 URL 开始递归的爬取页面,直到达到最大深度。
func Crawl(url string, depth int, fetcher Fetcher) {
// TODO: 并行的抓取 URL。
// TODO: 不重复抓取页面。
// 下面并没有实现上面两种情况:
if depth <= 0 {
return
}
body, urls, err := fetcher.Fetch(url)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("found: %s %q\n", url, body)
for _, u := range urls {
Crawl(u, depth-1, fetcher)
}
return
}
func main() {
Crawl("http://golang.org/", 4, fetcher)
}
// fakeFetcher 是返回若干结果的 Fetcher。
type fakeFetcher map[string]*fakeResult
type fakeResult struct {
body string
urls []string
}
func (f fakeFetcher) Fetch(url string) (string, []string, error) {
if res, ok := f[url]; ok {
return res.body, res.urls, nil
}
return "", nil, fmt.Errorf("not found: %s", url)
}
// fetcher 是填充后的 fakeFetcher。
var fetcher = fakeFetcher{
"http://golang.org/": &fakeResult{
"The Go Programming Language",
[]string{
"http://golang.org/pkg/",
"http://golang.org/cmd/",
},
},
"http://golang.org/pkg/": &fakeResult{
"Packages",
[]string{
"http://golang.org/",
"http://golang.org/cmd/",
"http://golang.org/pkg/fmt/",
"http://golang.org/pkg/os/",
},
},
"http://golang.org/pkg/fmt/": &fakeResult{
"Package fmt",
[]string{
"http://golang.org/",
"http://golang.org/pkg/",
},
},
"http://golang.org/pkg/os/": &fakeResult{
"Package os",
[]string{
"http://golang.org/",
"http://golang.org/pkg/",
},
},
}
- 结果:
found: http://golang.org/ "The Go Programming Language"
found: http://golang.org/pkg/ "Packages"
found: http://golang.org/ "The Go Programming Language"
found: http://golang.org/pkg/ "Packages"
not found: http://golang.org/cmd/
not found: http://golang.org/cmd/
found: http://golang.org/pkg/fmt/ "Package fmt"
found: http://golang.org/ "The Go Programming Language"
found: http://golang.org/pkg/ "Packages"
found: http://golang.org/pkg/os/ "Package os"
found: http://golang.org/ "The Go Programming Language"
found: http://golang.org/pkg/ "Packages"
not found: http://golang.org/cmd/