RDD的概述
RDD是只读的、分区记录的集合,是Spark编程模型的最主要抽象,它是一种特殊的集合,支持多种数据源,有容错机制、衍生血缘关系、可被缓存、支持并行操作。
RDD的属性特征
1)分区(partition)
数据集的基本组成单位。包含一个数据分片列表,将数据进行切分,并决定并行的计算的粒度。其中分片的个数可由程序指定(默认值为程序分配的CPU数量)。每个分区分配的存储由BlockManager实现,分区都被逻辑映射成BlockManager的一个Block(Block被一个Task负责计算)。
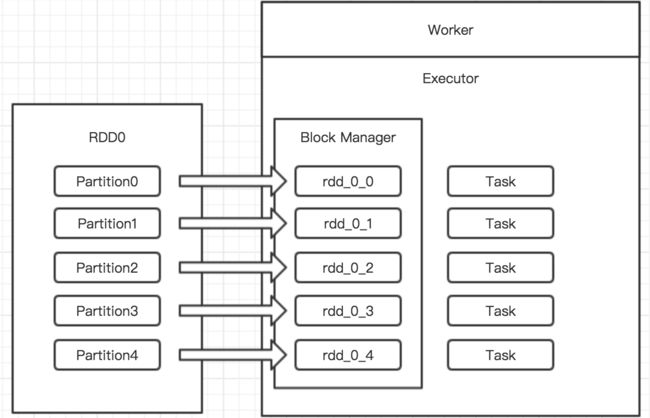
另外,从BlockManager的源码中可以看出,把分区的数据存储需要制定的几个参数:
blockId:块id
data:分区的数据buffer
level:rdd存储的持久化等级

2)函数(compute)
一个计算每个分区的函数,RDD的计算以分片为单位,每个RDD实现compute函数。通俗来说,compute用于计算每个分片,得出一个可遍历的结果,用于描述在父RDD上执行的计算。
3)依赖(dependency)
RDD的转换都会生成新的RDD,RDD之间形成子->父的依赖关系(源RDD没有依赖),通过依赖关系描述血缘关系(lineage),在部分分区数据丢失的,通过lineage重建丢失的分区数据,提升整体运算效率。
4)优先位置(preferred location)
每个分片的优先计算位置,Spark在进行任务调度的时候,会尽可能滴将计算任务分配到所需数据块的存储位置,满足“移动计算优先移动数据”的理念。
5)分区策略(Partitioner)
RDD分片函数,描述分区模式和数据分片粒度。Partitioner函数决定RDD本身的分片数据,同事决定了parent RDD Shuffle输出时的分片数据。
Spark实现两种类型的分片函数:基于哈希的HashPartitioner和基于范围的RangePartitioner。区别在于只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None的。
具体区别详看下一篇《Spark RDD分区策略》
RDD创建
细分来说,Spark有二种方式创建RDD
1、并行化已存在的Scala集合
scala> val data = Array(1,2,3,4,5)
data: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val distData = sc.parallelize(data) //这里关注slices参数,指定数据集切分成几个分区
distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at :29
scala> distData.reduce((a,b) => a + b)
res1: Int = 15
2、通过外部文件系统的数据集创建
SparkContext类中的textFile用于创建文本类型的RDD
def textFile(path:String, minPartitions: Int = defaultMinPartitions)
path参数:指定文件的URI地址(hdfs://、本地等等)
minPartitions参数:指定分片数
scala> val distFile = sc.textFile("/Users/irwin/zookeeper.out")
distFile: org.apache.spark.rdd.RDD[String] = /Users/irwin/zookeeper.out MapPartitionsRDD[4] at textFile at :27
scala> distFile.map(s => s.length).reduce((a, b) => (a+b))
res3: Int = 102295
当然SparkContext中包含其他创建RDD的方法,如:
def wholeTextFiles(path:String, minPartitions: Int = defaultMinPartitions)
defhadoopRDD[K,V](conf: JobConf, inputFormatClass:Class[_ <: InputFormat[K,V]], keyClass:Class[K], valueClass:Class[V], minPartitions: Int = defaultMinPartitions)
RDD操作
RDD包含一系列的转换(Transformation)与执行(Action)。
转换
所有转换操作都是惰性的,指定处理相互依赖关系,是数据集的逻辑操作,并未真正计算。
执行
该操作指定数据的形式,当发生Action操作时,Spark将Action之间的所有Transformation组成的Job会并行计算。
例如从上面例子可以看到,只有在distFile.map的时候,Job才会真正执行,且返回最后Action的结构。
这里有个关键点:当每个Job计算完成,其内部所有RDD会被清除。所以有RDD需要重复使用,则使用Persist(或Cache)的方法将RDD持久化,详见下文RDD缓存介绍。

通过上图RDD操作列表可以看到,有以下内容:
RDD的Transformation操作、Action操作(常用执行操作、存储执行操作)、缓存操作、checkpoint操作,具体用法及意义可以详见官方文档。
RDD缓存
Spark持久化指的是在不同Transformation过程中,将数据集缓存在内存中,实现快速重用、故障快速恢复。
主动持久化
程序主动通过persist()或cache()方法操作标记需被持久化的RDD,事实上cache()使用的是persist()的默认方法。下面我们来看看持久化的等级:

根据名称可以理解对应Level的意义,其中带“SER”表示将RDD序列化为Java对象,带“2”表示将每个分区赋值到两个集群节点。Persist持久化RDD,会修改原来RDD的 meta info 中的StorageLevel,可以看到最后返回的是this,说明返回的是修改的RDD对象本身,而非产生了新的RDD。

另外,从RDD类的源码中我们可以看到:

默认persist()使用内存存储,而cache()调用的是persist()默认实现。
自动持久化
指的是Spark自动保存一些Shuffle操作的中间结果。很容易理解,Spark为了表面Shuffle过程中出现异常的快速恢复。
再说一点,persist()后不一定说就不丢失,在内存不足的情况也是可能被删除。但是用户不用关心这块,RDD的容错机制保证了丢失也能计算正确执行。RDD通过 meta info 中的 Lineage 可以重算丢失的数据。
RDD依赖关系
Spark根据提交任务的计算逻辑(亦即是RDD的Transformation和Action)生成RDD之间的依赖关系,同时也生成逻辑上的DAG。这里说到的依赖关系指的是对父RDD依赖,这个关系包含两种类型:narrow dependency 和 wide dependency。
窄依赖(narrow dependency)
指每一个 parent RDD 的 Partition 最多被子RDD的一个Partition使用。从数据的角度来看,窄依赖的RDD整个操作都可以在同一个集群节点执行,以pinpeline的方式计算所有父分区,不会造成网络之间的数据混合。

宽依赖(wide dependency)
与窄依赖相反,指的是子RDD的Partition会依赖所有parent RDD的所有或多个Partition。宽依赖RDD会涉及数据混合,宽依赖需要首先计算好所有父分区的数据,然后在节点间进行Shuffle。

所有依赖的基类是traid Dependency[T],这是一个纯虚类:

其中rdd就是依赖的Parent RDD
对于窄依赖的实现是:

窄依赖有两种具体的实现
1、OneToOneDependency

2、RangeDependency

UnionRDD将多个RDD合成一个RDD,从上述分析,合成后的RDD每个parent RDD的partition的相对顺序是不会变。对于合并后的UnionRDD而言,每个parent RDD与其Partition的其实位置不同。
从RangeDependency类中可以看到,partitionId - outStart(UnionRDD起始位置) + inStart(parent RDD的起始位置),通过上述计算方式找到parent RDD对应的Partition。
对于宽依赖的实现是:

子RDD依赖parent RDD的所有Partition,因此需求shuffle过程。Shuffle过程由ShuffleManager控制,而宽依赖包含以下两种:基于Hash的HashShuffleManager以及基于排序的SortShuffleManager

DAG的构建
上述已经提到RDD通过一系列Transformation和Action形成了DAG,Spark根据DAG生成计算任务:
第一步:划分Stage
根据依赖关系的不同将DAG划分不同的阶段。对于窄依赖,由于Partition的去定型,窄依赖划分到同一个执行阶段;对于宽依赖,需等待parent RDD Shuffle处理完成,所以Spark根据宽依赖将DAG划分不同的Stage。
第二步:Stage内部分配Task
每个Partition都会分配一个计算Task(并行执行),Stage之间根据依赖关系编程一个粗粒度的DAG。
第三步:执行顺序
DAG的执行的顺序是从前往后,亦即是Stage只有其parent Stage执行完成后才执行(当然起始的stage不需要)。
Task的执行
上述提到,RDD的Transformation操作是惰性的,只有发生Action才会生成Job,而这个Job会映射成一个粗粒度的DAG,DAG执行每一个Stage会将Partition分配计算Task,这些Task会被提交到集群上执行计算,执行计算的逻辑部分为:Executor。
Spark的Task有两类:
org.apache.spark.scheduler.ShuffleMapTask与org.apache.spark.scheduler.ResultTask
回想一下,Transformation和Action的区别,Action会返回数据,而Transformation只进行RDD的转换。Spark的Task类型分别对应这两类,下面简单分析一下Task的执行过程。
org.apache.spark.scheduler.Task的run()方法开始执行Task

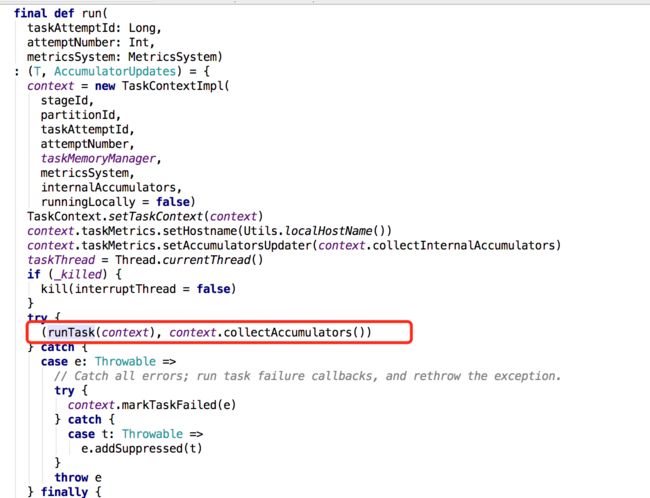

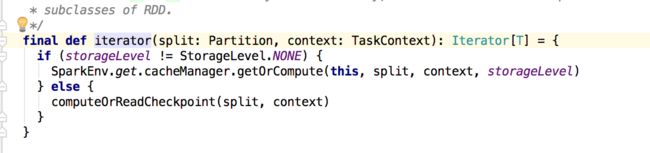
runTask最终调用RDD的iterator,Task的计算从这里开始。
小结
至此,RDD的实现分析已经介绍完毕,我们回顾一下:
RDD的属性特征:分区、函数、依赖、优先位置、分区策略;
RDD缓存:持久化等级、主动持久化、自动持久化
RDD的操作:Transformation、Action
RDD依赖:窄依赖、宽依赖
DAG与Task
RDD是Spark最基本、最根本的数据抽象。