摘要:随着深度学习网络规模的增大,计算复杂度随之增高,严重限制了其在手机等智能设备上的应用。如何使用深度学习来对模型进行压缩和加速,并且保持几乎一样的精度?本文将为大家详细介绍两种模型压缩算法,并展示了阿里巴巴模型压缩平台和前向推理工具。
本次直播视频精彩回顾,戳这里!
本次直播PDF下载,戳这里!
演讲嘉宾简介:
李昊(花名:辽玥),阿里巴巴机器智能技术实验室高级算法专家,毕业于中科院,拥有工学博士学位,致力于深度学习基础技术研究以及在各个行业的应用。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本文将围绕一下几个方面进行介绍:
1. 深度学习模型压缩与加速
Extremely Low Bit Neural Networks
Extremely Sparse Network
2. 训练平台
3. 高效前向推理工具
一. 深度学习模型压缩与加速
随着深度学习网络规模的增大,计算复杂度随之增高,严重限制了其在手机等智能设备上的应用。例如下图一展示的VGGNet和图二的残差网络,如此大规模的复杂网络模型在端设备上使用并不现实。
因此需要采用深度学习模型来进行压缩和加速,下面介绍两种压缩算法。
1. Extremely Low Bit Neural Networks
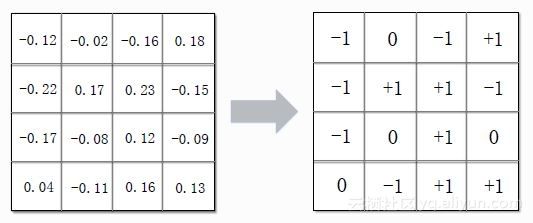
Low Bit模型是指将连续的权重压缩成离散的低精度权重。如下图所示,原始深度学习的网络参数为float型,需要32bit存储空间,将其转化成只有三值(0,+1,-1)的状态,存储只需要2bit,极大地压缩存储空间,同时也可以避免乘法运算,只是符号位的变化和加减操作,从而提升计算速度。
这里为大家提供一篇对Low Bit模型详细介绍的参考文章Extremely Low Bit Neural Networks: Squeeze the Last Bit Out with ADMM。
接下来以二值网络为例讲解上述的压缩过程。首先假设原始神经网络的优化目标函数为f(w),限制条件为深度学习网络的参数包含在C内,如果C为{-1,1},则该网络便为二值网络,如下所示:

这里引入了一种解决分布式优化和约束优化的常用方法ADMM(Alternating Direction Method of Multipliers),来求解以上离散非凸约束优化问题,其形式如下:
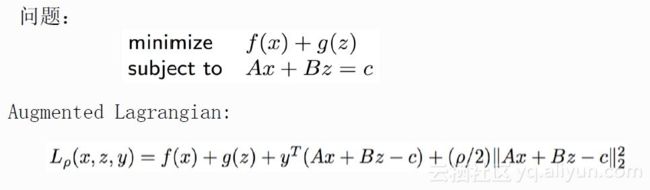
ADMM用于解决当目标函数为f(x)+g(z),其中限制条件是Ax+Bz=c的优化。首先写出增广拉格朗日函数,然后将上述问题转化成求解如下所示的xyz:

即先求解xz的极小值,然后得到y的更新。上述即为ADMM标准解法,接下来,如何将Low Bit Neural Networks问题转化成ADMM问题呢?
首先需要引入指示函数,形式如下所示:
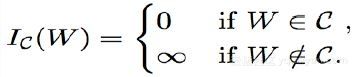
此时二值神经网络的目标函数等价于优化目标函数和指示函数之和:
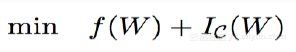
这意味着,当指示函数属于C时,优化目标即为初始目标,没有变化;当指示函数不属于C时,指示函数为正无穷,此时会首先优化指示函数。
然后需要引入一致性约束,这里引入辅助变量G,并约束W=G,则目标函数等价于:

加入辅助变量后,就可以将二值神经网络的优化问题转化为ADMM标准问题。接下来,写出上式增广拉格朗日公式,使用ADMM算法求解完成优化目标,如下所示:
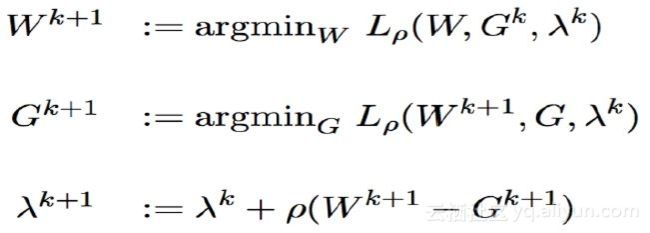
除上述二值网络外,还有以下几种常用的参数空间:

参数空间中加入2、4、8等值后,仍然不需要乘法运算,只需进行移位操作。因此,通过这种方法将神经网络中的乘法操作全部替换为移位和加操作。
将上述Low Bit模型应用至ImageNet进行分类,最终的优化结果如下表所示:

表一展示了该算法在AlexNet和VGG-16的应用结果,可以发现该算法在二值和三值网络中的效果明显优于原始范围的应用,并且三值网络中的分类结果与全精度的分类结果相比,几乎是无损的。表二是该算法在ResNet-18和ResNet-50中的应用,结果也与表一中类似。
在检测方面,该算法仍具有较高的可用性。如下表所示:

本次实验的数据集为Pascal VOC 2007。根据上表中数据可知,三值空间内的检测结果精度与全精度参数空间相比,误差几乎可以忽略不计。
2. Extremely Sparse Networks
稀疏神经网络适用于网络中大部分参数为零的情况,存储参数可以通过简单的压缩算法,例如游程编码,极大的减小参数存储空间,并且由于0可不参与计算,从而节约大量的计算空间,提升计算速度。稀疏网络中,优化目标仍然和上述相同,限制条件改为如下所示:

对f(W)求梯度下降值(Gradient Descent),将其进行迭代,每迭代一次,就进行一次连接剪枝(Connection Pruning),裁剪的标准是,W的参数越小,重要性越低,将比较小的参数置零,从而保证稀疏度。

但上述解法存在一个明显的问题是,如下图所示:
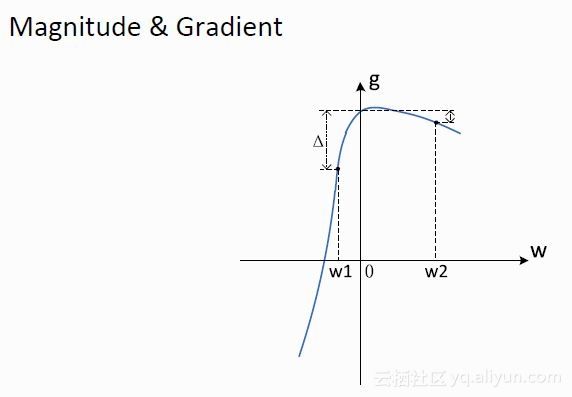
w1与w2相比,w1与0更近,但若将w1置零,对函数的损失更大,因此在决定w的重要性时,必须同时考虑w本身大小和斜率。只有在w值和斜率都比较小时,才可以将其置零。基于上述标准,完成了对Alexnet和GoogleNet的稀少度实验,如下图所示:

由上图结果可知,无论是纯卷积网络,还是包含全连接层网络,都可以达到90%以上的稀疏度。
3. 实验结果对比
上文中介绍了稀疏和量化两种方法,实验一将这两种方法同时作用于Alexnet,结果如下所示:

由上图可以得知,在3Bits,稀疏度为90%以上时,精度损失几乎可以忽略不计,此时压缩率可以达到82倍以上。
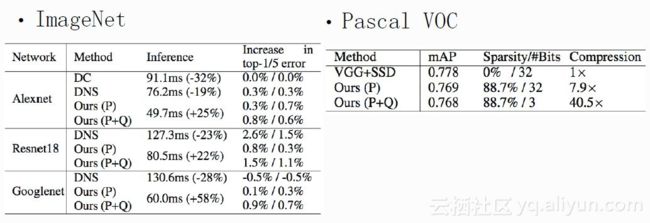
实验二中,将两种方法作用于InageNet和Pascal VOC,其中P是稀疏,Q是量化,由图中结果可知,实验过程精度损失极小,并且InageNet中inference的速度有明显提升,Pascal VOC可以达到稀疏度88.7%,量化为3bits,40倍的压缩率下,相对于全精度网络mAP只有1点的下降幅度。
二. 训练平台
基于上述两种方法,建立起Gauss训练平台。目前Gauss训练平台支持多种常见训练任务(例如人脸、ocr、分类、监测等)和模型(例如CNN、LSTM等),并且支持多机训练,能够以尽可能少的参数设置,减少用户使用成本。

同时Gauss训练平台支持两种模型训练工具:Data-dependent和Data-independent。Data-dependent模型训练工具需要用户提供训练数据,训练时间较长,适合压缩和加速要求较高的场景。Data-independent模型训练工具无需用户提供任何训练数据,一键式处理,处理时间在秒级。
三. 高效前向推理工具
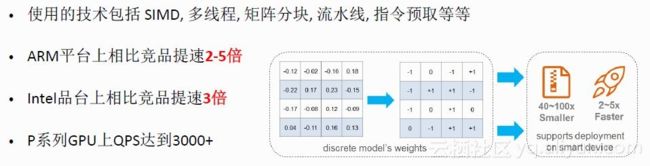
建立起训练平台之后,模型的真正运用还需要高效的前向推理工具。基于低精度矩阵计算工具AliNN&BNN,快速实现低比特矩阵乘法计算。实现后的推理工具在ARM平台上相比竞品提速2-5倍,Intel平台上提速3倍。
详情请阅读原文