背景
线上的业务数据和厂家数据不一致,差异很大。
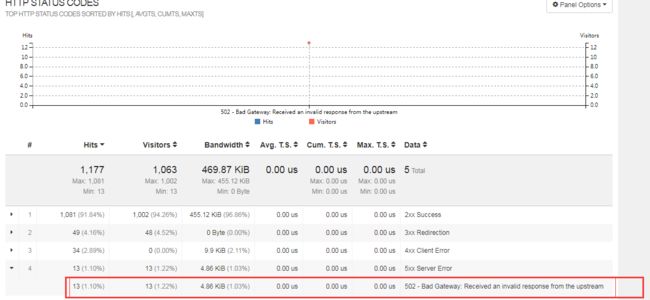
而且线上的业务收到了很多502的异常日志,第一时间反应是一脸懵逼!!其他业务量大的都没那么多的502问题,怎么突然新添加的这个服务那么多的问题呢t?
一开始以为是单独一个服务并发问题,后来迁移到多服务及负载均衡上,但是依然无果,从日志上看得到的还是很多的502!!!
按以往的经验来说,常用的尝试有:
定期的重启一下uwsgi进程
想来应该是可以解决问题,但是尝试多次添加也无果,而且当天业务量很多,但是仔细分析了一下,发现出现502的都主要集中一个“订购接口上”,这个有点匪夷所思啊!修改nginx与后端的超时时间,增大超时响应时常(可惜也无果)
问题排查:
1:查看nginx对于的服务的请求日志和错误的日志:
- 现象主要集中表现错误提示:
提示1)
upstream prematurely closed connection while reading response header from upstream
提示2)
upstream timed out (110: Connection timed out) while reading response header from upstream
补充关于Nginx报错:upstream timed out (110: Connection timed out)
网上的一些提供方案:
NGINX反向代理的超时报错,解决方法:
server {
listen 80;
server_name localhost;
large_client_header_buffers 4 16k;
client_max_body_size 300m;
client_body_buffer_size 128k;
proxy_connect_timeout 600;
proxy_read_timeout 600;
proxy_send_timeout 600;
proxy_buffer_size 64k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
#........................
}
提示3)
recv() failed (104: Connection reset by peer) while reading response header from upstream
- 尝试的解决方案:
1)修改nginx 服务的配置,在应用服务的配置上规制强制指定使用1.1协议。
location ^~ /xxxxxx/ {
...
proxy_http_version 1.1;
proxy_set_header Connection "";
...
}
可惜。后来发现多数的请求其实都是http1.1的,这个也方案无果!
2)修改nginx 服务的配置,增加时间。
proxy_connect_timeout 300;
proxy_read_timeout 300;
proxy_send_timeout 300;
proxy_buffer_size 64k;
可惜。方案无果!
3)修改修改uwsgi配置,添加buffer-size。
````
32768
````
可惜。方案无果!
4)修改修改ngixn应用服务配置,变为300
proxy_connect_timeout 300; #nginx跟后端服务器连接超时时间(代理连接超时)
proxy_send_timeout 300; #后端服务器数据回传时间(代理发送超时)
proxy_read_timeout 300; #连接成功后,后端服务器响应时间(代理接收超时)
可惜。方案无果!
5)修改修改uwsgi配置,添加
````
16
````
可惜。方案无果!
6)在ngixn 应用服务添加对应的
uwsgi_connect_timeout 600; # 指定连接到后端uWSGI的超时时间。
uwsgi_read_timeout 600; # 指定接收uWSGI应答的超时时间,完成握手后接收uWSGI应答的超时时间。
uwsgi_pass 127.0.0.1:10035;
location / {
include uwsgi_params;
uwsgi_param UWSGI_PYHOME /data/www/xxx;
uwsgi_param UWSGI_CHDIR /data/www/xxxx;
uwsgi_param UWSGI_SCRIPT main; # 对应main.py
uwsgi_send_timeout 600; # 指定向uWSGI传送请求的超时时间,完成握手后向uWSGI传送请求的超时时间。
uwsgi_connect_timeout 600; # 指定连接到后端uWSGI的超时时间。
uwsgi_read_timeout 600; # 指定接收uWSGI应答的超时时间,完成握手后接收uWSGI应答的超时时间。
uwsgi_pass 127.0.0.1:10035;
proxy_connect_timeout 600; #nginx跟后端服务器连接超时时间(代理连接超时)
proxy_send_timeout 600; #后端服务器数据回传时间(代理发送超时)
proxy_read_timeout 600; #连接成功后,后端服务器响应时间(代理接收超时)
}
可惜。方案无果!
7)修改修改uwsgi配置,添加
最终的uwsgi配置:
python35
127.0.0.1:10035
/data/www/xxxxx
2048
1024
128
96
8
2000
16
32768
60
20
/data/www/xxxxxxx
可惜。方案还是感觉没有多少的改变无果!
- 可能的问题:
1:数据量频繁的写入引发超时,因为当时业务量大,很多请求都直接写入了数据库,这样对数 据库写入很大,不知道是否会有影响?
2:是不是因为uwsgi的进程意外的经常挂掉了,然后重启没那么快,而后续的请求就直接的被丢弃了?
- 实施:
1:关闭统计API请求日志写入数据库的操作
2:添加定时重启uwsgi的进程机制
-
后期一直实时盯着日志打印看了一下发现了一个的问题:
 image.png
image.png
get error:("local variable 'fields' referenced before assignment",)
让后端人员排查了一下这个问题,发现是输入数据库的时候少了对应的字段信息,导致服务经常的异常!会不会就是这个地方经常引起服务异常,需要重启而导致的呢? 可是如果按这么说的 安利 应该是返回500内部错误的状态码的啊? 504的话 可以理解是可能后端请求超时了? 有点诧异!
- 修复get error:("local variable 'fields' referenced before assignment",)问题后:
在进行实时的观察数据看,嗯嗯!502的异常现在明显的少了!
后来回忆再分析了一下看看UWSGI的日志:
有这个:
参考思考地址:https://www.aliyun.com/jiaocheng/449723.html
SystemError: Objects/listobject.c:245: bad argument to internal function
PS:即便重启进程还是还是会继续报错!所以可能还是因为某个函数不当引发的错误信息日志!
改天实践一下看看!!
想来有可能真的就是这个问题引起的吧!
完整的一些日志信息:
Respawned uWSGI worker 5 (new pid: 22407)
SystemError: Objects/listobject.c:245: bad argument to internal function
WSGI app 0 (mountpoint='') ready in 0 seconds on interpreter 0x1c95660 pid: 22407 (default app)
/usr/local/lib/python3.5/site-packages/requests/packages/urllib3/connectionpool.py:852: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
...The work of process 22407 is done. Seeya!
worker 5 killed successfully (pid: 22407)
Respawned uWSGI worker 5 (new pid: 22576)
SystemError: Objects/listobject.c:245: bad argument to internal function
WSGI app 0 (mountpoint='') ready in 1 seconds on interpreter 0x1c95660 pid: 22232 (default app)
/usr/local/lib/python3.5/site-packages/requests/packages/urllib3/connectionpool.py:852: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
...The work of process 22232 is done. Seeya!
worker 1 killed successfully (pid: 22232)
Respawned uWSGI worker 1 (new pid: 22750)
SystemError: Objects/listobject.c:245: bad argument to internal function
WSGI app 0 (mountpoint='') ready in 0 seconds on interpreter 0x1c95660 pid: 22750 (default app)
workers have been inactive for more than 20 seconds (1523527358-1523527337)
SystemError: Objects/listobject.c:245: bad argument to internal function
SystemError: Objects/listobject.c:245: bad argument to internal function
WSGI app 0 (mountpoint='') ready in 1 seconds on interpreter 0x1c95660 pid: 22576 (default app)
...The work of process 22576 is done. Seeya!
WSGI app 0 (mountpoint='') ready in 1 seconds on interpreter 0x1c95660 pid: 21834 (default app)
...The work of process 21834 is done. Seeya!
问题修复后,502的错误少了很多了!不会像以前那样高频了!!:
不过还是有少量的502的错误:

暂时比较彻底杜绝502的问题,还不知道,不过相对以前已经明显少了,而且没其他那么多的错误了!