https://www.cnblogs.com/juncaoit/category/1083950.html
1.背景
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进。
2.架构
单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。
此时,用于简化增删改查工作量的 数据访问框架(ORM) 是关键。
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。
此时,用于加速前端页面开发的 Web框架(MVC) 是关键。
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
此时,用于提高业务复用及整合的 分布式服务框架(RPC) 是关键。
流动计算架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
此时,用于提高机器利用率的 资源调度和治理中心(SOA) 是关键。
3.dubbox
dubbox是dubbo的扩展,主要在dubbo的基础上进行了一下的改进
1、支持REST风格远程调用(HTTP + JSON/XML):基于非常成熟的JBoss RestEasy框架,在dubbo中实现了REST风格(HTTP + JSON/XML)的远程调用,以显著简化企业内部的跨语言交互,同时显著简化企业对外的Open API、无线API甚至AJAX服务端等等的开发。事实上,这个REST调用也使得Dubbo可以对当今特别流行的“微服务”架构提供基础性支持。 另外,REST调用也达到了比较高的性能,在基准测试下,HTTP + JSON与Dubbo 2.x默认的RPC协议(即TCP + Hessian2二进制序列化)之间只有1.5倍左右的差距,详见文档中的基准测试报告。
2、支持基于Kryo和FST的Java高效序列化实现:基于当今比较知名的Kryo和FST高性能序列化库,为Dubbo默认的RPC协议添加新的序列化实现,并优化调整了其序列化体系,比较显著的提高了Dubbo RPC的性能,详见文档中的基准测试报告。
3、支持基于Jackson的JSON序列化:基于业界应用最广泛的Jackson序列化库,为Dubbo默认的RPC协议添加新的JSON序列化实现。
4、支持基于嵌入式Tomcat的HTTP remoting体系:基于嵌入式tomcat实现dubbo的HTTP remoting体系(即dubbo-remoting-http),用以逐步取代Dubbo中旧版本的嵌入式Jetty,可以显著的提高REST等的远程调用性能,并将Servlet API的支持从2.5升级到3.1。(注:除了REST,dubbo中的WebServices、Hessian、HTTP Invoker等协议都基于这个HTTP remoting体系)。
5、升级Spring:将dubbo中Spring由2.x升级到目前最常用的3.x版本,减少版本冲突带来的麻烦。
6、升级ZooKeeper客户端:将dubbo中的zookeeper客户端升级到最新的版本,以修正老版本中包含的bug。
7、支持完全基于Java代码的Dubbo配置:基于Spring的Java Config,实现完全无XML的纯Java代码方式来配置dubbo
8、调整Demo应用:暂时将dubbo的demo应用调整并改写以主要演示REST功能、Dubbo协议的新序列化方式、基于Java代码的Spring配置等等。
9、修正了dubbo的bug 包括配置、序列化、管理界面等等的bug。
4.Dubbo框架
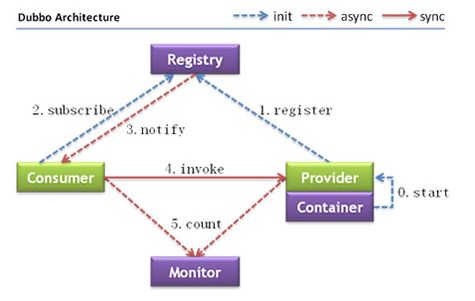
1、Provider:暴露服务的服务提供方。 Consumer: 调用远程服务的服务消费方。
2、Registry:服务注册与发现的注册中心。 Monitor: 统计服务的调用次调和调用时间的监控中心。
3、Container: 服务运行容器
5.Dubbo的调用关系
1、服务容器负责启动,加载,运行服务提供者。
2、服务提供者在启动时,向注册中心注册自己提供的服务。
3、服务消费者在启动时,向注册中心订阅自己所需的服务。
4、注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
5、服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
6、服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
6.Dubbo特点
http://www.cnblogs.com/juncaoit/p/7567657.html
7.Dubbo调用方式
- 异步调用
基于NIO的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小
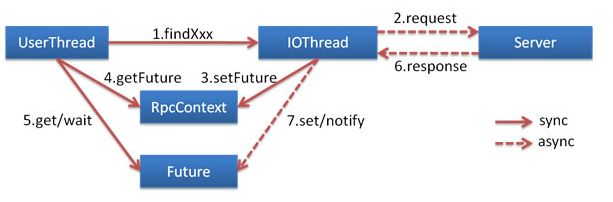
- 本地调用
本地调用,使用了Injvm协议,是一个伪协议,它不开启端口,不发起远程调用,只在JVM内直接关联,但执行Dubbo的Filter链。
Define injvm protocol:
Set default protocol:
Set service protocol:
Use injvm first:(服务暴露与服务引用都需要声明injvm=“true”)
8.Dubbo支持的注册中心
- Multicast注册中心
- Zookeeper注册中心
- Redis注册中心
- Simple注册中心
Multicast:不需要启动任何中心节点,只要广播地址一样,就可以互相发现组播受网络结构限制,只适合小规模应用或开发阶段使用。
组播地址段: 224.0.0.0 - 239.255.255.255
Zookeeper:是Apacahe Hadoop的子项目,是一个树型的目录服务,支持变更推送,适合作为Dubbo服务的注册中心,工业强度较高只需搭一个原生的Zookeeper服务器,
并将Provider和Consumer里的dubbo.properties中的dubbo.registry.addrss的值改为zookeeper://127.0.0.1:2181即可使用阿里内部并没有采用Zookeeper做为注册中心,而是使用自己实现的基于数据库的注册中心,即:Zookeeper注册中心并没有在阿里内部长时间运行的可靠性保障,其可靠性依赖于Zookeeper本身的可靠性。
ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower。当客户端Client连接到ZooKeeper集群,并且执行写请求时,这些请求会被发送到Leader节点上,然后Leader节点上数据变更会同步到集群中其他的Follower节点。
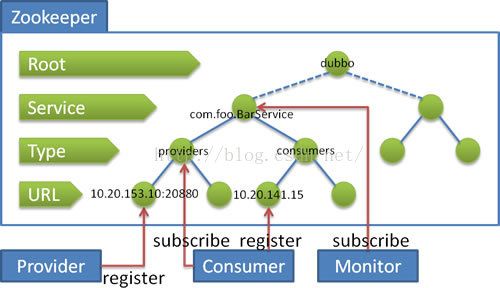
流程说明:
-
- 服务提供者启动时
- 向/dubbo/com.foo.BarService/providers目录下写入自己的URL地址。
- 服务消费者启动时
- 订阅/dubbo/com.foo.BarService/providers目录下的提供者URL地址。
- 并向/dubbo/com.foo.BarService/consumers目录下写入自己的URL地址。
- 监控中心启动时
- 订阅/dubbo/com.foo.BarService目录下的所有提供者和消费者URL地址。
- 服务提供者启动时
支持以下功能:
-
- 当提供者出现断电等异常停机时,注册中心能自动删除提供者信息。
- 当注册中心重启时,能自动恢复注册数据,以及订阅请求。
- 当会话过期时,能自动恢复注册数据,以及订阅请求。
- 当设置
- 可通过
- 可通过
- 支持号通配符
在provider和consumer中增加zookeeper客户端jar包依赖
支持zkclient和curator两种Zookeeper客户端实现
Simple注册中心:
注册中心本身就是一个普通的Dubbo服务,可以减少第三方依赖,使整体通讯方式一致。
9.Dubbo支持的远程通信协议
- Mina
- Netty
- Grizzly
10.Dubbo支持的远程调用协议
- Dubbo协议
- Hessian协议
- HTTP协议
- RMI协议
- WebService协议
- Thrift协议
- Memcached协议
- Redis协议
在通信过程中,不同的服务等级一般对应着不同的服务质量,那么选择合适的协议便是一件非常重要的事情。
11.Dubbo的容错
在集群调用失败时,Dubbo提供了多种容错方案,缺省为failover重试。
Failover Cluster
失败自动切换,当出现失败,重试其它服务器。(缺省)
通常用于读操作,但重试会带来更长延迟。
可通过retries=“2”来设置重试次数(不含第一次)。Failfast Cluster
快速失败,只发起一次调用,失败立即报错。
通常用于非幂等性的写操作,比如新增记录。Failsafe Cluster
失败安全,出现异常时,直接忽略。
通常用于写入审计日志等操作。Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。
通常用于消息通知操作。Forking Cluster
并行调用多个服务器,只要一个成功即返回。
通常用于实时性要求较高的读操作,但需要浪费更多服务资源。
可通过forks=“2”来设置最大并行数。Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。(2.1.0开始支持)
通常用于通知所有提供者更新缓存或日志等本地资源信息。
12.负载均衡
13.源码结构
各个模块之间的关系:
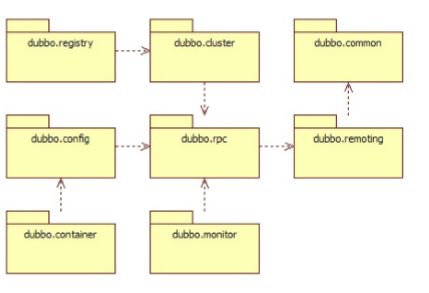
dubbo-common 公共逻辑模块,包括Util类和通用模型。
dubbo-remoting 远程通讯模块,相当于Dubbo协议的实现,如果RPC用RMI协议则不需要使用此包。
dubbo-rpc 远程调用模块,抽象各种协议,以及动态代理,只包含一对一的调用,不关心集群的管理。
dubbo-cluster 集群模块,将多个服务提供方伪装为一个提供方,包括:负载均衡、容错、路由等,集群的地址列表可以是静态配置的,也可以是由注册中心下发。
dubbo-registry 注册中心模块,基于注册中心下发地址的集群方式,以及对各种注册中心的抽象。
dubbo-monitor 监控模块,统计服务调用次数,调用时间的,调用链跟踪的服务。
dubbo-config 配置模块,是Dubbo对外的API,用户通过Config使用Dubbo,隐藏Dubbo所有细节。
dubbo-container 容器模块,是一个Standalone的容器,以简单的Main加载Spring启动,因为服务通常不需要Tomcat/JBoss等Web容器的特性,没必要用Web容器去加载服务。