- JavaScript 中,深拷贝(Deep Copy)和浅拷贝(Shallow Copy)
跳房子的前端
前端面试javascript开发语言ecmascript
在JavaScript中,深拷贝(DeepCopy)和浅拷贝(ShallowCopy)是用于复制对象或数组的两种不同方法。了解它们的区别和应用场景对于避免潜在的bugs和高效地处理数据非常重要。以下是对深拷贝和浅拷贝的详细解释,包括它们的概念、用途、优缺点以及实现方式。1.浅拷贝(ShallowCopy)概念定义:浅拷贝是指创建一个新的对象或数组,其中包含了原对象或数组的基本数据类型的值和对引用数
- 深度学习-点击率预估-研究论文2024-09-14速读
sp_fyf_2024
深度学习人工智能
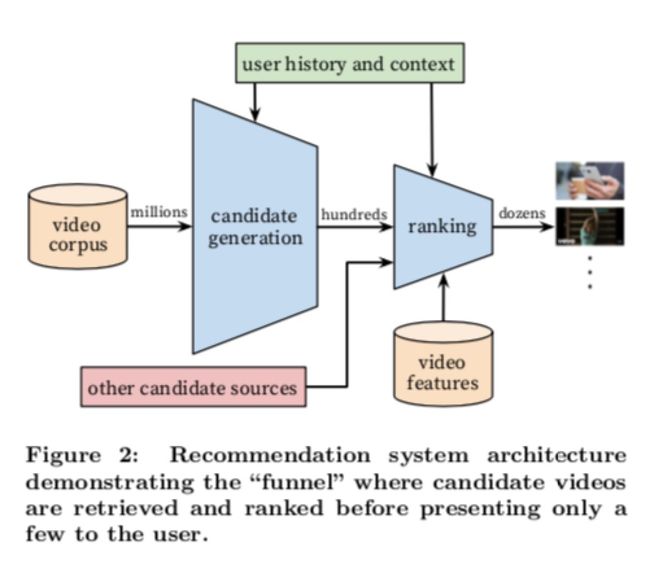
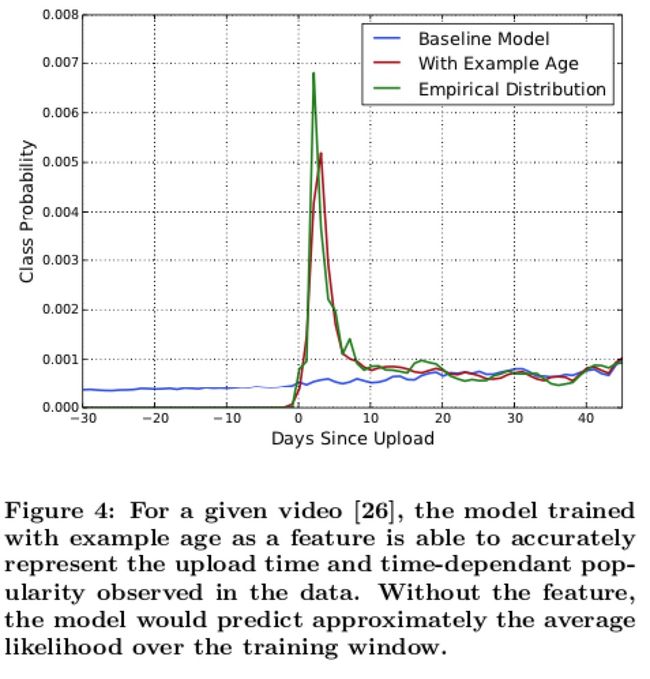
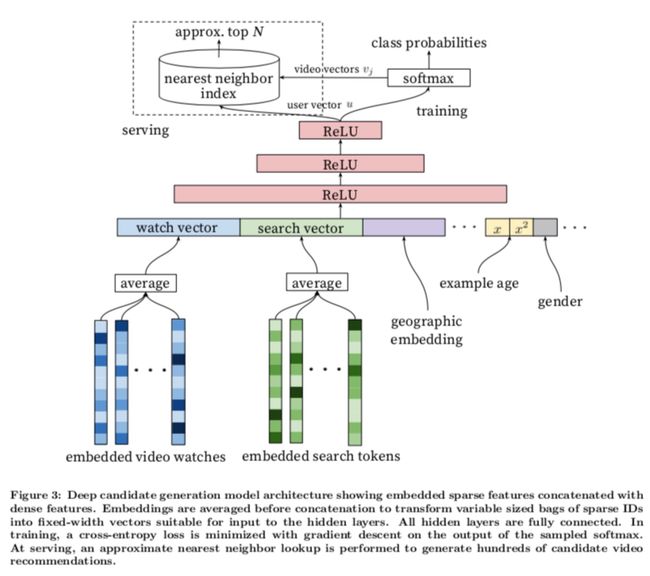
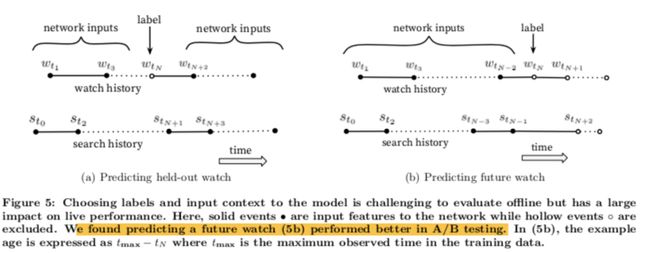
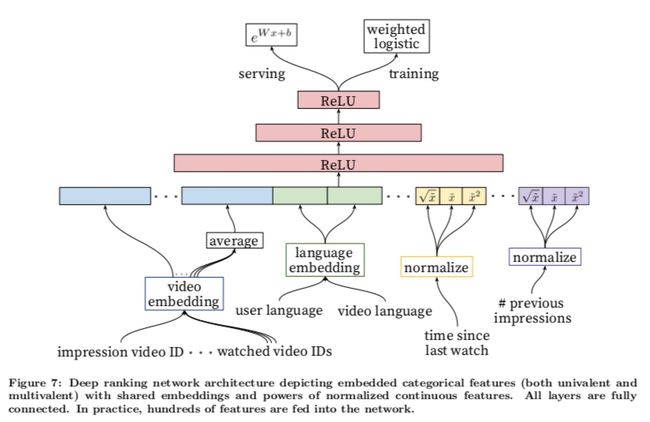
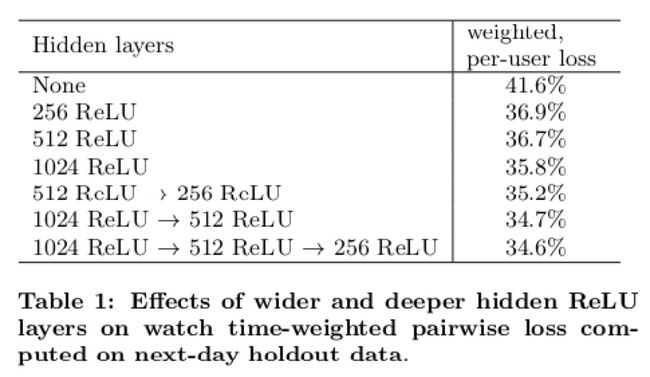
深度学习-点击率预估-研究论文2024-09-14速读1.DeepTargetSessionInterestNetworkforClick-ThroughRatePredictionHZhong,JMa,XDuan,SGu,JYao-2024InternationalJointConferenceonNeuralNetworks,2024深度目标会话兴趣网络用于点击率预测摘要:这篇文章提出了一种新
- 哪些网站用python开发
hakesashou
python基础知识python
国内的话,知乎,网易,腾讯,搜狐,金山,豆瓣这些属于用Python比较知名的。大型的项目的话,网易的许多游戏,腾讯的某些网站,搜狐的邮箱,金山的测试框架等等都是或多或少使用了Python。YouTube-视频分享网站,在某些功能上使用到python。Quora-社交问答网站。Google-谷歌在很多项目中用python作为网络应用的后端,如GoogleGroups、Gmail、GoogleMaps
- 探索未来,大规模分布式深度强化学习——深入解析IMPALA架构
汤萌妮Margaret
探索未来,大规模分布式深度强化学习——深入解析IMPALA架构scalable_agent项目地址:https://gitcode.com/gh_mirrors/sc/scalable_agent在当今的人工智能研究前沿,深度强化学习(DRL)因其在复杂任务中的卓越表现而备受瞩目。本文要介绍的是一个开源于GitHub的重量级项目:“ScalableDistributedDeep-RLwithImp
- 云服务业界动态简报-20180128
Captain7
一、青云青云QingCloud推出深度学习平台DeepLearningonQingCloud,包含了主流的深度学习框架及数据科学工具包,通过QingCloudAppCenter一键部署交付,可以让算法工程师和数据科学家快速构建深度学习开发环境,将更多的精力放在模型和算法调优。二、腾讯云1.腾讯云正式发布腾讯专有云TCE(TencentCloudEnterprise)矩阵,涵盖企业版、大数据版、AI
- 机器学习VS深度学习
nfgo
机器学习
机器学习(MachineLearning,ML)和深度学习(DeepLearning,DL)是人工智能(AI)的两个子领域,它们有许多相似之处,但在技术实现和应用范围上也有显著区别。下面从几个方面对两者进行区分:1.概念层面机器学习:是让计算机通过算法从数据中自动学习和改进的技术。它依赖于手动设计的特征和数学模型来进行学习,常用的模型有决策树、支持向量机、线性回归等。深度学习:是机器学习的一个子领
- 联邦学习 Federated learning Google I/O‘19 笔记
努力搬砖的星期五
笔记联邦学习机器学习机器学习tensorflow
FederatedLearning:MachineLearningonDecentralizeddatahttps://www.youtube.com/watch?v=89BGjQYA0uE文章目录FederatedLearning:MachineLearningonDecentralizeddata1.DecentralizeddataEdgedevicesGboard:mobilekeyboa
- 【NLP5-RNN模型、LSTM模型和GRU模型】
一蓑烟雨紫洛
nlprnnlstmgrunlp
RNN模型、LSTM模型和GRU模型1、什么是RNN模型RNN(RecurrentNeuralNetwork)中文称为循环神经网络,它一般以序列数据为输入,通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出RNN的循环机制使模型隐层上一时间步产生的结果,能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响2、R
- el-dialog高度设置
夏之小星星
前端vue.jselementuicss
el-dialog高度设置::v-deep.el-dialog{height:78vh;overflow:auto;}
- elementuiPlus取消el-input的边框
qq_39016177
elementui
elementuiPlus取消el-input的边框1.通常取消边框的方法设置border为none2.还有其他类似边框的例如outlinebox-shadow这两个属性都是会产生边框效果3.el-input需要更改的话–如下需要修改box-shadow为空即可上代码:deep(.el-input__wrapper){align-items:center;background-color:#F7F
- ExoPlayer简单使用
csdn_zxw
安卓视频播放android
ExoPlayerLibrary概述ExoPlayer是运行在YouTubeappAndroid版本上的视频播放器ExoPlayer是构建在Android低水平媒体API之上的一个应用层媒体播放器。和Android内置的媒体播放器相比,ExoPlayer有许多优点。ExoPlayer支持内置的媒体播放器支持的所有格式外加自适应格式DASH和SmoothStreaming。ExoPlayer可以被高
- 【双语新闻】AGI安全与对齐,DeepMind近期工作
曲奇人工智能安全
agi安全llama人工智能
我们想与AF社区分享我们最近的工作总结。以下是关于我们正在做什么,为什么会这么做以及我们认为它的意义所在的一些详细信息。我们希望这能帮助人们从我们的工作基础上继续发展,并了解他们的工作如何与我们相关联。byRohinShah,SebFarquhar,AncaDragan21stAug2024AIAlignmentForumWewantedtosharearecapofourrecentoutput
- 坚持自己,而不是被环境改变·115天(Youtube语言学习方法)
左撇子槿希
图片发自App1.Pleaseremovetheblackpart/bit.黒い(くろい)ところは取り除(とりのぞ)いてください。2.I’mlookingoraplacetostay.泊まる(とまる)所(ところ)を探(さが)しています。3.Doyouknowwhoisthatperson?あの人は誰(だれ)か知っていますか。4.Whichrestaurantischeap?レストランはどこが安い(
- 探索深度学习的奥秘:从理论到实践的奇幻之旅
小周不想卷
深度学习
目录引言:穿越智能的迷雾一、深度学习的奇幻起源:从感知机到神经网络1.1感知机的启蒙1.2神经网络的诞生与演进1.3深度学习的崛起二、深度学习的核心魔法:神经网络架构2.1前馈神经网络(FeedforwardNeuralNetwork,FNN)2.2卷积神经网络(CNN)2.3循环神经网络(RNN)及其变体(LSTM,GRU)2.4生成对抗网络(GAN)三、深度学习的魔法秘籍:算法与训练3.1损失
- CycleGAN学习:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
屎山搬运工
深度学习CycleGANGAN风格迁移
【导读】图像到图像的转换技术一般需要大量的成对数据,然而要收集这些数据异常耗时耗力。因此本文主要介绍了无需成对示例便能实现图像转换的CycleGAN图像转换技术。文章分为五部分,分别概述了:图像转换的问题;CycleGAN的非成对图像转换原理;CycleGAN的架构模型;CycleGAN的应用以及注意事项。图像到图像的转换涉及到生成给定图像的新的合成版本,并进行特定的修改,例如将夏季景观转换为冬季
- arXiv综述论文“Graph Neural Networks: A Review of Methods and Applications”
硅谷秋水
自动驾驶
arXiv于2019年7月10日上载的GNN综述论文“GraphNeuralNetworks:AReviewofMethodsandApplications“。摘要:许多学习任务需要处理图数据,该图数据包含元素之间的丰富关系信息。建模物理系统、学习分子指纹、预测蛋白质界面以及对疾病进行分类都需要一个模型从图输入学习。在其他如文本和图像之类非结构数据学习的领域中,对提取的结构推理,例如句子的依存关系
- C# 网口通信(通过Sockets类)
萨达大
c#服务器网络网口通讯上位机
文章目录1.引入Sockets2.定义TcpClient3.连接网口4.发送数据5.关闭连接1.引入SocketsusingSystem.Net.Sockets;2.定义TcpClientprivateTcpClienttcpClient;//TcpClient实例privateNetworkStreamstream;//网络流,用于与服务器通信3.连接网口tcpClient=newTcpClie
- TextCNN:文本卷积神经网络模型
一只天蝎
编程语言---Pythoncnn深度学习机器学习
目录什么是TextCNN定义TextCNN类初始化一个model实例输出model什么是TextCNNTextCNN(TextConvolutionalNeuralNetwork)是一种用于处理文本数据的卷积神经网(CNN)。通过在文本数据上应用卷积操作来提取局部特征,这些特征可以捕捉到文本中的局部模式,如n-gram(连续的n个单词或字符)。定义TextCNN类importtorch.nnasn
- 【Python百日进阶-Web开发-Peewee】Day295 - 查询示例(四)聚合1
岳涛@心馨电脑
Dashpython前端dash
文章目录14.6聚合14.6.1计算设施数量Countthenumberoffacilities14.6.2计算昂贵设施的数量Countthenumberofexpensivefacilities14.6.3计算每个成员提出的建议数量。Countthenumberofrecommendationseachmembermakes.14.6.4列出每个设施预订的总空位Listthetotalslots
- [Kaiming]Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
MTandHJ
neuralnetworks
文章目录概主要内容PReLUKaiming初始化ForwardcaseBackwardcaseHeK,ZhangX,RenS,etal.DelvingDeepintoRectifiers:SurpassingHuman-LevelPerformanceonImageNetClassification[C].internationalconferenceoncomputervision,2015:1
- 深度神经网络详解:原理、架构与应用
阿达C
活动dnn计算机网络人工智能神经网络机器学习深度学习
深度神经网络(DeepNeuralNetwork,DNN)是机器学习领域中最为重要和广泛应用的技术之一。它模仿人脑神经元的结构,通过多层神经元的连接和训练,能够处理复杂的非线性问题。在图像识别、自然语言处理、语音识别等领域,深度神经网络展示了强大的性能。本文将深入解析深度神经网络的基本原理、常见架构及其实际应用。一、深度神经网络的基本原理1.1神经元和感知器神经元是深度神经网络的基本组成单元。一个
- 前端开发需要了解的算法知识
史努比的大头
算法前端
手写深拷贝functiondeepClone(obj){//处理基础数据类型和函数if(obj===null||typeofobj!=='object'){returnobj;}//处理数组if(Array.isArray(obj)){returnobj.map(item=>deepClone(item));}//处理对象constclonedObj={};for(constkeyinobj){i
- 推荐开源项目:PyTorch-Metric-Learning
潘惟妍
推荐开源项目:PyTorch-Metric-Learningpytorch-metric-learningTheeasiestwaytousedeepmetriclearninginyourapplication.Modular,flexible,andextensible.WritteninPyTorch.项目地址:https://gitcode.com/gh_mirrors/py/pytorc
- Centos9 网卡配置文件
码哝小鱼
linux运维linux网络
1、Centosstream9网络介结Centos以前版本,NetworkManage以ifcfg格式存储网络配置文件在/etc/sysconfig/networkscripts/目录中。但是,Centossteam9现已弃用ifcfg格式,默认情况下,NetworkManage不再创建此格式的新配置文件。从Centossteam9开始采用密钥文件格式(基于INI文件),NetworkManage
- LLM系列(4):通义千问7B在Swift/DeepSpeed上微调秘诀与实战陷阱避坑指南
汀、人工智能
LLM工业级落地实践人工智能自然语言处理promptSwifiDeepSpeed通义千问Qwen
LLM系列(4):通义千问7B在Swift/DeepSpeed上微调秘诀与实战陷阱避坑指南阿里云于2023年8月3日开源通义千问70亿参数模型,包括通用模型Qwen-7B以及对话模型Qwen-7B-Chat,这也是国内首个开源自家大模型的大厂。在诸多权威大模型能力测评基准上,如MMLU、C-Eval、GSM8K、HumanEval、WMT22,通义千问7B均取得了同参数级别开源模型中的最好表现,
- 使用C++编写接口调用PyTorch模型,并生成DLL供.NET使用
编程日记✧
pytorch人工智能python.netc#c++
一、将PyTorch模型保存为TorchScript格式1)构造一个pytorch2TorchScript.py,示例代码如下:importtorchimporttorch.nnasnnimportargparsefromnetworks.seg_modelingimportmodelasViT_segfromnetworks.seg_modelingimportCONFIGSasCONFIGS_
- 深度学习算法在图算法中的应用(图卷积网络GCN和图自编码器GAE)
大嘤三喵军团
深度学习算法网络
深度学习算法在图算法中的应用1.图卷积网络(GraphConvolutionalNetworks,GCN)图卷积网络(GCN)是一种将卷积神经网络(ConvolutionalNeuralNetworks,CNN)推广到图结构数据的方法。GCN被广泛用于节点分类、图分类、链接预测等任务。优势和好处灵活性:GCN可以处理不规则和不均匀的数据结构,比如社交网络、分子结构、交通网络等。高效性:GCN使用局
- linux查看jupyter运行,在Linux服务器上运行Jupyter notebook server教程
天启大烁哥
在Linux服务器上运行Jupyternotebookserver教程很多deeplearning教程都推荐在jupyternotebook运行python代码,方便及时交互。但只在本地运行没有GPU环境,虽然googlecolab是个好办法,但发现保存模型后在云端找不到模型文件,且需要合理上网才能访问。于是想给实验室的服务器配置jupyternotebook,供本机远程访问。踩了不少坑,码一下教
- 加载pkl文件,Python报错AttributeError: Can‘t get attribute ‘DeepFM‘ on <module ‘__main__‘ from...>
Zerol_Yan
Python基础python
背景模型同学发过来的pkl格式的模型,在系统中加载的时候,报错AttributeError:module'__main__'hasnoattribute'LabelEncoderExt',尝试了很多种方式,最后终于解决了这个问题,记录一下,以后遇到类似的可以做参考。项目代码及结构app.pyfrominitimportappimportjsonfromflaskimportrequest@app.
- SDN系统方法 | 7. 叶棘网络
DeepNoMind
随着互联网和数据中心流量的爆炸式增长,SDN已经逐步取代静态路由交换设备成为构建网络的主流方式,本系列是免费电子书《Software-DefinedNetworks:ASystemsApproach》的中文版,完整介绍了SDN的概念、原理、架构和实现方式。原文:Software-DefinedNetworks:ASystemsApproach第7章叶棘网络(Leaf-SpineFabric)本章介
- xml解析
小猪猪08
xml
1、DOM解析的步奏
准备工作:
1.创建DocumentBuilderFactory的对象
2.创建DocumentBuilder对象
3.通过DocumentBuilder对象的parse(String fileName)方法解析xml文件
4.通过Document的getElem
- 每个开发人员都需要了解的一个SQL技巧
brotherlamp
linuxlinux视频linux教程linux自学linux资料
对于数据过滤而言CHECK约束已经算是相当不错了。然而它仍存在一些缺陷,比如说它们是应用到表上面的,但有的时候你可能希望指定一条约束,而它只在特定条件下才生效。
使用SQL标准的WITH CHECK OPTION子句就能完成这点,至少Oracle和SQL Server都实现了这个功能。下面是实现方式:
CREATE TABLE books (
id &
- Quartz——CronTrigger触发器
eksliang
quartzCronTrigger
转载请出自出处:http://eksliang.iteye.com/blog/2208295 一.概述
CronTrigger 能够提供比 SimpleTrigger 更有具体实际意义的调度方案,调度规则基于 Cron 表达式,CronTrigger 支持日历相关的重复时间间隔(比如每月第一个周一执行),而不是简单的周期时间间隔。 二.Cron表达式介绍 1)Cron表达式规则表
Quartz
- Informatica基础
18289753290
InformaticaMonitormanagerworkflowDesigner
1.
1)PowerCenter Designer:设计开发环境,定义源及目标数据结构;设计转换规则,生成ETL映射。
2)Workflow Manager:合理地实现复杂的ETL工作流,基于时间,事件的作业调度
3)Workflow Monitor:监控Workflow和Session运行情况,生成日志和报告
4)Repository Manager:
- linux下为程序创建启动和关闭的的sh文件,scrapyd为例
酷的飞上天空
scrapy
对于一些未提供service管理的程序 每次启动和关闭都要加上全部路径,想到可以做一个简单的启动和关闭控制的文件
下面以scrapy启动server为例,文件名为run.sh:
#端口号,根据此端口号确定PID
PORT=6800
#启动命令所在目录
HOME='/home/jmscra/scrapy/'
#查询出监听了PORT端口
- 人--自私与无私
永夜-极光
今天上毛概课,老师提出一个问题--人是自私的还是无私的,根源是什么?
从客观的角度来看,人有自私的行为,也有无私的
- Ubuntu安装NS-3 环境脚本
随便小屋
ubuntu
将附件下载下来之后解压,将解压后的文件ns3environment.sh复制到下载目录下(其实放在哪里都可以,就是为了和我下面的命令相统一)。输入命令:
sudo ./ns3environment.sh >>result
这样系统就自动安装ns3的环境,运行的结果在result文件中,如果提示
com
- 创业的简单感受
aijuans
创业的简单感受
2009年11月9日我进入a公司实习,2012年4月26日,我离开a公司,开始自己的创业之旅。
今天是2012年5月30日,我忽然很想谈谈自己创业一个月的感受。
当初离开边锋时,我就对自己说:“自己选择的路,就是跪着也要把他走完”,我也做好了心理准备,准备迎接一次次的困难。我这次走出来,不管成败
- 如何经营自己的独立人脉
aoyouzi
如何经营自己的独立人脉
独立人脉不是父母、亲戚的人脉,而是自己主动投入构造的人脉圈。“放长线,钓大鱼”,先行投入才能产生后续产出。 现在几乎做所有的事情都需要人脉。以银行柜员为例,需要拉储户,而其本质就是社会人脉,就是社交!很多人都说,人脉我不行,因为我爸不行、我妈不行、我姨不行、我舅不行……我谁谁谁都不行,怎么能建立人脉?我这里说的人脉,是你的独立人脉。 以一个普通的银行柜员
- JSP基础
百合不是茶
jsp注释隐式对象
1,JSP语句的声明
<%! 声明 %> 声明:这个就是提供java代码声明变量、方法等的场所。
表达式 <%= 表达式 %> 这个相当于赋值,可以在页面上显示表达式的结果,
程序代码段/小型指令 <% 程序代码片段 %>
2,JSP的注释
<!-- -->
- web.xml之session-config、mime-mapping
bijian1013
javaweb.xmlservletsession-configmime-mapping
session-config
1.定义:
<session-config>
<session-timeout>20</session-timeout>
</session-config>
2.作用:用于定义整个WEB站点session的有效期限,单位是分钟。
mime-mapping
1.定义:
<mime-m
- 互联网开放平台(1)
Bill_chen
互联网qq新浪微博百度腾讯
现在各互联网公司都推出了自己的开放平台供用户创造自己的应用,互联网的开放技术欣欣向荣,自己总结如下:
1.淘宝开放平台(TOP)
网址:http://open.taobao.com/
依赖淘宝强大的电子商务数据,将淘宝内部业务数据作为API开放出去,同时将外部ISV的应用引入进来。
目前TOP的三条主线:
TOP访问网站:open.taobao.com
ISV后台:my.open.ta
- 【MongoDB学习笔记九】MongoDB索引
bit1129
mongodb
索引
可以在任意列上建立索引
索引的构造和使用与传统关系型数据库几乎一样,适用于Oracle的索引优化技巧也适用于Mongodb
使用索引可以加快查询,但同时会降低修改,插入等的性能
内嵌文档照样可以建立使用索引
测试数据
var p1 = {
"name":"Jack",
"age&q
- JDBC常用API之外的总结
白糖_
jdbc
做JAVA的人玩JDBC肯定已经很熟练了,像DriverManager、Connection、ResultSet、Statement这些基本类大家肯定很常用啦,我不赘述那些诸如注册JDBC驱动、创建连接、获取数据集的API了,在这我介绍一些写框架时常用的API,大家共同学习吧。
ResultSetMetaData获取ResultSet对象的元数据信息
- apache VelocityEngine使用记录
bozch
VelocityEngine
VelocityEngine是一个模板引擎,能够基于模板生成指定的文件代码。
使用方法如下:
VelocityEngine engine = new VelocityEngine();// 定义模板引擎
Properties properties = new Properties();// 模板引擎属
- 编程之美-快速找出故障机器
bylijinnan
编程之美
package beautyOfCoding;
import java.util.Arrays;
public class TheLostID {
/*编程之美
假设一个机器仅存储一个标号为ID的记录,假设机器总量在10亿以下且ID是小于10亿的整数,假设每份数据保存两个备份,这样就有两个机器存储了同样的数据。
1.假设在某个时间得到一个数据文件ID的列表,是
- 关于Java中redirect与forward的区别
chenbowen00
javaservlet
在Servlet中两种实现:
forward方式:request.getRequestDispatcher(“/somePage.jsp”).forward(request, response);
redirect方式:response.sendRedirect(“/somePage.jsp”);
forward是服务器内部重定向,程序收到请求后重新定向到另一个程序,客户机并不知
- [信号与系统]人体最关键的两个信号节点
comsci
系统
如果把人体看做是一个带生物磁场的导体,那么这个导体有两个很重要的节点,第一个在头部,中医的名称叫做 百汇穴, 另外一个节点在腰部,中医的名称叫做 命门
如果要保护自己的脑部磁场不受到外界有害信号的攻击,最简单的
- oracle 存储过程执行权限
daizj
oracle存储过程权限执行者调用者
在数据库系统中存储过程是必不可少的利器,存储过程是预先编译好的为实现一个复杂功能的一段Sql语句集合。它的优点我就不多说了,说一下我碰到的问题吧。我在项目开发的过程中需要用存储过程来实现一个功能,其中涉及到判断一张表是否已经建立,没有建立就由存储过程来建立这张表。
CREATE OR REPLACE PROCEDURE TestProc
IS
fla
- 为mysql数据库建立索引
dengkane
mysql性能索引
前些时候,一位颇高级的程序员居然问我什么叫做索引,令我感到十分的惊奇,我想这绝不会是沧海一粟,因为有成千上万的开发者(可能大部分是使用MySQL的)都没有受过有关数据库的正规培训,尽管他们都为客户做过一些开发,但却对如何为数据库建立适当的索引所知较少,因此我起了写一篇相关文章的念头。 最普通的情况,是为出现在where子句的字段建一个索引。为方便讲述,我们先建立一个如下的表。
- 学习C语言常见误区 如何看懂一个程序 如何掌握一个程序以及几个小题目示例
dcj3sjt126com
c算法
如果看懂一个程序,分三步
1、流程
2、每个语句的功能
3、试数
如何学习一些小算法的程序
尝试自己去编程解决它,大部分人都自己无法解决
如果解决不了就看答案
关键是把答案看懂,这个是要花很大的精力,也是我们学习的重点
看懂之后尝试自己去修改程序,并且知道修改之后程序的不同输出结果的含义
照着答案去敲
调试错误
- centos6.3安装php5.4报错
dcj3sjt126com
centos6
报错内容如下:
Resolving Dependencies
--> Running transaction check
---> Package php54w.x86_64 0:5.4.38-1.w6 will be installed
--> Processing Dependency: php54w-common(x86-64) = 5.4.38-1.w6 for
- JSONP请求
flyer0126
jsonp
使用jsonp不能发起POST请求。
It is not possible to make a JSONP POST request.
JSONP works by creating a <script> tag that executes Javascript from a different domain; it is not pos
- Spring Security(03)——核心类简介
234390216
Authentication
核心类简介
目录
1.1 Authentication
1.2 SecurityContextHolder
1.3 AuthenticationManager和AuthenticationProvider
1.3.1 &nb
- 在CentOS上部署JAVA服务
java--hhf
javajdkcentosJava服务
本文将介绍如何在CentOS上运行Java Web服务,其中将包括如何搭建JAVA运行环境、如何开启端口号、如何使得服务在命令执行窗口关闭后依旧运行
第一步:卸载旧Linux自带的JDK
①查看本机JDK版本
java -version
结果如下
java version "1.6.0"
- oracle、sqlserver、mysql常用函数对比[to_char、to_number、to_date]
ldzyz007
oraclemysqlSQL Server
oracle &n
- 记Protocol Oriented Programming in Swift of WWDC 2015
ningandjin
protocolWWDC 2015Swift2.0
其实最先朋友让我就这个题目写篇文章的时候,我是拒绝的,因为觉得苹果就是在炒冷饭, 把已经流行了数十年的OOP中的“面向接口编程”还拿来讲,看完整个Session之后呢,虽然还是觉得在炒冷饭,但是毕竟还是加了蛋的,有些东西还是值得说说的。
通常谈到面向接口编程,其主要作用是把系统��设计和具体实现分离开,让系统的每个部分都可以在不影响别的部分的情况下,改变自身的具体实现。接口的设计就反映了系统
- 搭建 CentOS 6 服务器(15) - Keepalived、HAProxy、LVS
rensanning
keepalived
(一)Keepalived
(1)安装
# cd /usr/local/src
# wget http://www.keepalived.org/software/keepalived-1.2.15.tar.gz
# tar zxvf keepalived-1.2.15.tar.gz
# cd keepalived-1.2.15
# ./configure
# make &a
- ORACLE数据库SCN和时间的互相转换
tomcat_oracle
oraclesql
SCN(System Change Number 简称 SCN)是当Oracle数据库更新后,由DBMS自动维护去累积递增的一个数字,可以理解成ORACLE数据库的时间戳,从ORACLE 10G开始,提供了函数可以实现SCN和时间进行相互转换;
用途:在进行数据库的还原和利用数据库的闪回功能时,进行SCN和时间的转换就变的非常必要了;
操作方法: 1、通过dbms_f
- Spring MVC 方法注解拦截器
xp9802
spring mvc
应用场景,在方法级别对本次调用进行鉴权,如api接口中有个用户唯一标示accessToken,对于有accessToken的每次请求可以在方法加一个拦截器,获得本次请求的用户,存放到request或者session域。
python中,之前在python flask中可以使用装饰器来对方法进行预处理,进行权限处理
先看一个实例,使用@access_required拦截:
?