整体套路
Mysql数据库数据通过canal-server canal-client将bin-log日志或者处理后的canal.entry传输至kafka,进行一定的处理,可以处理成jdbcTemplate可以执行的sql语句然后进行数据库更新。Hbase中我们可以借助Hive,对于mysql中的一张表,我在Hive中建了两张表,一张用于与Hbase关联,一张用于提供update delete这种事务处理的功能。定时执行
insert overwrite table_1 select * from table table_2;来导入,我这里并不考虑很高的实时性,如果非要强调实时性,我觉得es,redis(搞个集群)更适合一点
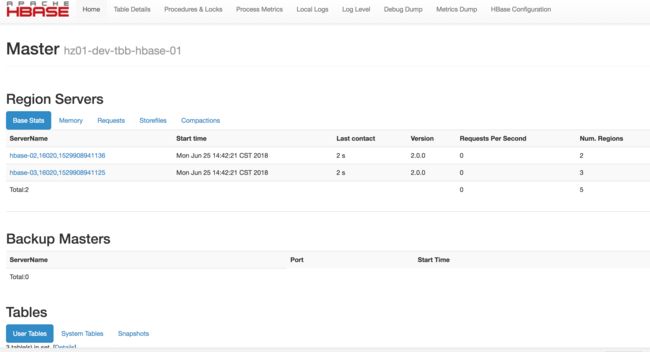
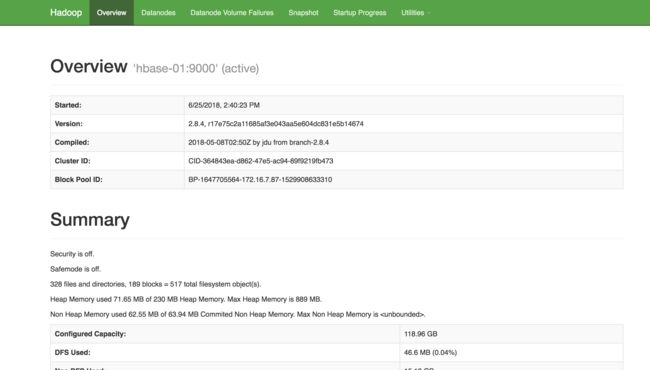
准备工作,安装hadoop,hive,hbase,kafka集群,zookeeper集群,canal-server,安装这些东西就百度或者google下吧,都是体力活。
我的环境是hbase 2.0.0 hadoop 2.8.4
 Screen Shot 2018-06-26 at 4.46.16 PM.png
Screen Shot 2018-06-26 at 4.46.16 PM.png
 Screen Shot 2018-06-26 at 4.46.02 PM.png
Screen Shot 2018-06-26 at 4.46.02 PM.png
kafka zookeeper如果公司内网有就直接用现成的好了,没有的话就自个儿装下。
我的canal版本是1.0.25,canal-client里面CanalEntry.Entry这个类是关键类,我直接把它序列化以后扔到kafka里面
public class EntryDeserializer implements Deserializer {
@Override
public void configure(Map configs, boolean isKey) {
}
@Override
public CanalEntry.Entry deserialize(String topic, byte[] data) {
try {
return CanalEntry.Entry.parseFrom(data);
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
return null;
}
}
@Override
public void close() {
}
}
public class EntrySerializer implements Serializer {
@Override
public void configure(Map configs, boolean isKey) {
}
@Override
public byte[] serialize(String topic, CanalEntry.Entry data) {
return data.toByteArray();
}
@Override
public void close() {
}
}
我对canal的demo中样例代码进行了一些改造
running = true;
while (running) {
try {
MDC.put("destination", canalProperties.getDestination());
connector.connect();
connector.subscribe();
connector.rollback();
log.info("connected {} {}", connector);
while (running) {
Message message = connector.getWithoutAck(blockSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
} else {
//printSummary(message, batchId, size);
//printEntries(message.getEntries());
for (CanalEntry.Entry entry : message.getEntries()) {
if (entry.getEntryType() == CanalEntry.EntryType.ROWDATA) {
Optional.ofNullable(applicationContext)
.ifPresent(context -> {
log.info("push event {} {}", entry, context);
kafkaTemplate.send("ca", entry);
});
}
}
}
/**
* 提交确认
*/
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
try {
Thread.sleep(3000);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
}
在另外一个应用内部订阅kafka传输CanalEntry.Entry的topic
@KafkaListener(topics = {"ca"})
public void receiveKafkaTopics(ConsumerRecord record) {
log.info("receive kafka message {}", record);
CanalEntry.Entry entry = record.value();
CanalEntry.Header header = entry.getHeader();
String dbName = header.getSchemaName();
String tableName = header.getTableName();
CanalEntry.RowChange rowChange = getRowChangeFromEntry(entry);
log.info("dbName:{} tableName:{} {}", dbName, tableName, rowChange.getEventType());
final CanalEntry.EventType eventType = rowChange.getEventType();
/**
* 处理canal entry 并将数据同步到目标数据库
*/
handleRowChange(rowChange, tableName, dbName, eventType);
}
然后接下来要做的事情就是从CanalEntry.Entry里面把插入更新删除这几种操作以及更新的数据还有主键,更新前更新后都提取出来,我自己拼装成了一个hive的sql语句然后通过JdbcTemplate进行执行。
String primaryKey = null;
String primaryKeyValue = "";
for (CanalEntry.Column column : columns) {
if (column.getIsKey()) {
primaryKey = column.getName();
primaryKeyValue = column.getValue();
break;
}
}
String sql = "";
if (CanalEntry.EventType.UPDATE.equals(eventType)) {
StringBuilder updateStr = new StringBuilder();
isFirst = true;
for (CanalEntry.Column column : columns) {
if (column.hasUpdated() && !column.getIsNull() && !column.getIsKey()) {
if (!isFirst) {
updateStr.append(",");
}
updateStr.append(column.getName());
updateStr.append("=");
updateStr.append("'");
updateStr.append(column.getValue());
updateStr.append("'");
isFirst = false;
}
}
sql = String.format("UPDATE %s.%s SET %s WHERE %s='%s'", dbName, tableName,
updateStr, primaryKey, primaryKeyValue);
log.info("update sql {}", sql);
jdbcTemplate.execute(sql);
} else if (CanalEntry.EventType.INSERT.equals(eventType)) {
StringBuilder columnStr = new StringBuilder();
StringBuilder valuesStr = new StringBuilder();
isFirst = true;
for (CanalEntry.Column column : columns) {
if (!column.getIsNull()) {
if (!isFirst) {
columnStr.append(",");
valuesStr.append(",");
}
isFirst = false;
columnStr.append(column.getName());
valuesStr.append("'");
valuesStr.append(column.getValue());
valuesStr.append("'");
}
}
sql = String.format("INSERT INTO TABLE %s.%s (%s) VALUES (%s)",
dbName, tableName, columnStr.toString(), valuesStr.toString());
log.info("insert sql: {}", sql);
jdbcTemplate.execute(sql);
}
Hive中需要做的工作
建两张表 tt(用于支持数据更新) tth(用于关联hbase)
CREATE TABLE tt (foo INT, bar STRING)
clustered by (foo) into 2 buckets stored as orc
TBLPROPERTIES('transactional'='true');
-------------------------------------
CREATE TABLE tth(foo INT, bar STRING)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,cf1:val')
TBLPROPERTIES ('hbase.table.name' = 'tth');
第一张表支持更新操作(hive需要进行一些相应额外的配置用来支持ACID,比如update操作,百度下就知道了), 第二张表用于将数据同步到Hbase。
@Autowired
@Qualifier("hiveJdbcTemplate")
JdbcTemplate jdbcTemplate;
@Scheduled(fixedRate = 3600 * 12)
public void updateHbase(){
jdbcTemplate.execute("INSERT OVERWRITE " +
"TABLE tt_h SELECT * FROM tt");
}
间隔一段时间更新一下,大致思路就是这样。
当然也可以把mysql的update语句改造成hive的insert overwrite 这样的话一张表就够了
INSERT OVERWRITE tth VALUES (1, '0');
jdbc尽量用批处理效果会好很多,更新完成以后手动消费掉kafka的消息
eventExecutor.execute(new Runnable() {
@Override
public void run() {
String[] batches = handleRowChange(rowChange, tableName, dbName, eventType);
jdbcTemplate.batchUpdate(batches);
log.info("info batch update {}", batches);
ack.acknowledge();
}
});
其实跟mysql同步到普通mysql数据库 postgresql或者redis整体套路差不多,就是CanalEntry.Entry处理和Hive这边建表会麻烦一点,记得要事先把ddl在hive中执行好,同步到Hbase的话,容量啥的就无所谓,Hive的执行引擎其实也可以换成tez或者spark加速一下。