本文git地址,转载请注明,感谢
1.接收数据
用spark streaming流式处理kafka中的数据,第一步当然是先把数据接收过来,转换为spark streaming中的数据结构Dstream。接收数据的方式有两种:1.利用Receiver接收数据,2.直接从kafka读取数据。
1.1基于Receiver的方式
这种方式利用接收器(Receiver)来接收kafka中的数据,其最基本是使用Kafka高阶用户API接口。对于所有的接收器,从kafka接收来的数据会存储在spark的executor中,之后spark streaming提交的job会处理这些数据。如下图:
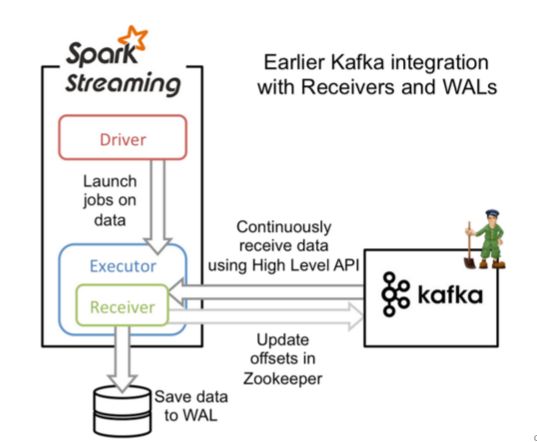
- 在Receiver的方式中,Spark中的partition和kafka中的partition并不是相关的,所以如果我们加大每个topic的partition数量,仅仅是增加线程来处理由单一Receiver消费的主题。但是这并没有增加Spark在处理数据上的并行度。
- 对于不同的Group和topic我们可以使用多个Receiver创建不同的Dstream来并行接收数据,之后可以利用union来统一成一个Dstream。
- 如果我们启用了Write Ahead Logs复制到文件系统如HDFS,那么storage level需要设置成 StorageLevel.MEMORY_AND_DISK_SER
1.2直接读取方式
在spark1.3之后,引入了Direct方式。不同于Receiver的方式,Direct方式没有receiver这一层,其会周期性的获取Kafka中每个topic的每个partition中的最新offsets,之后根据设定的maxRatePerPartition来处理每个batch。其形式如下图:
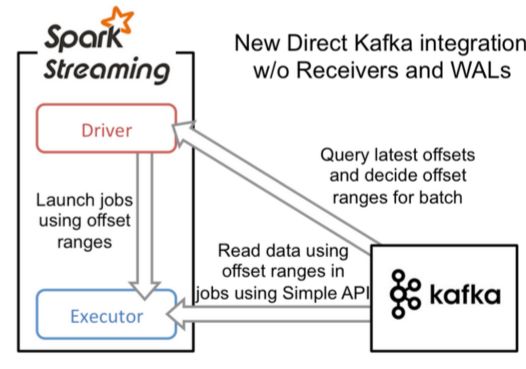
- 简化的并行:在Receiver的方式中我们提到创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
- 高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。
- 精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。
2.offset存储问题
2.1 背景
spark streaming + kafka 是很常见的分布式流处理组合。spark streaming 消费kafka有两种方式:Receiver DStream方式和Direct DStream的方式,前者不需要自己管理offset,但是比较迂回会产生大量数据冗余到hdfs,后者比较直接,但是如果程序出现问题导致需要重启,那么offset的存储就可以避免重复消费或者丢失数据,所以Direct DStream的offset 需要自己管理。
2.2 方式
在官网文档上我们可以看到三种存储offset的方式。
2.2.1 Checkpoints
这种方式使用简单,直接利用spark streaming的checkpoint机制把offset存到hdfs里,但是比较坑的是,除了offset,还有spark streaming的很多字节数据都备份了,所以修改了代码就不能再从checkpoint启动了。
you cannot recover from a checkpoint if your application code has changed.
官网说可以新旧代码一起运行一段时间……
2.2.2 Kafka itself
kafka会自动将offset存到另一个topic,注意 enable.auto.commit 要设置为false,不然默认是定期自动存储,会出问题。想用这种方式的话官网文档有示例。
The benefit as compared to checkpoints is that Kafka is a durable store regardless of changes to your application code. However, Kafka is not transactional, so your outputs must still be idempotent.
这段话最后一句however后我不知道怎么翻译合适,不过感觉这种方式……emmm,程序的宕机是因为kafka自己挂了的话怎么办……
2.2.3 Your own data store .
第三种方式是自己DIY,可以存到mysql、hbase、zookeeper等等。
之前用过存储到hbase,目前组内好像spark和hbase不是通的。
offset存储到zk的方式,网上也有很多可用的代码,但是对于spark2.x和kafka 10的组合,并没有找到可用的代码,相比于旧版本,api的更改还是很多的。
2.3 offset存储到zookeeper
版本:spark-streaming-kafka-0-10_2.11-2.2.0.jar 和 kafka_2.11-0.10.0.1.jar
调用示例:createDStream(ssc,"test0418","test_spark_streaming_group","localhost:2181","localhost:9092",kafkaParams)
/**
* 创建DStream,会读取zk上存储的offset,没有的话就直接创建一个
* @param ssc
* @param topics
* @param group
* @param ZKservice
* @param broker
* @param kafkaParams
* @return
*/
def createDStream(ssc:StreamingContext, topics:Set[String], group:String, ZKservice:String,broker:String, kafkaParams:Map[String, Object]):InputDStream[ConsumerRecord[String, String]] ={
val zkClient = new ZkClient(ZKservice)
var kafkaStream : InputDStream[ConsumerRecord[String, String]] = null
var fromOffsets: Map[TopicPartition, Long] = Map()
for(topic <-topics){
//创建一个 ZKGroupTopicDirs 对象
val topicDirs = new ZKGroupTopicDirs(group, topic)
// 获取 zookeeper 中的路径,这里会变成 /consumers/test_spark_streaming_group/offsets/topic_name
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
//查询该路径下是否字节点(默认有字节点为我们自己保存不同 partition 时生成的)
val children = zkClient.countChildren(s"${topicDirs.consumerOffsetDir}")
//如果 zookeeper 中有保存 offset,我们会利用这个 offset 作为 kafkaStream 的起始位置
val leaders = getLeaders(topic,broker)
if (children > 0) {
//如果保存过 offset,这里更好的做法,还应该和 kafka 上最小的 offset 做对比,不然会报 OutOfRange 的错误
for (i <- 0 until children) {
val partitionOffset = zkClient.readData[String](s"${topicDirs.consumerOffsetDir}/${i}")
val tp = new TopicPartition(topic, i)
val tap = TopicAndPartition(topic, i)
//比较最早的offset
val requestMin = OffsetRequest(Map(tap -> PartitionOffsetRequestInfo(OffsetRequest.EarliestTime, 1)))
val consumerMin = new SimpleConsumer(leaders.get(i).get, 9092, 10000, 10000, "getMinOffset")
val curOffsets = consumerMin.getOffsetsBefore(requestMin).partitionErrorAndOffsets(tap).offsets
var nextOffset = partitionOffset.toLong
if (curOffsets.length > 0 && nextOffset < curOffsets.head) { // 通过比较从 kafka 上该 partition 的最小 offset 和 zk 上保存的 offset,进行选择
nextOffset = curOffsets.head
}
fromOffsets += (tp -> nextOffset)
// println("@@@@@@ topic[" + topic + "] partition[" + i + "] offset[" + partitionOffset + "] @@@@@@")
}
}
}
if(fromOffsets.isEmpty){
//没有存储过,第一次创建
kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
}else{
kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Assign[String, String](fromOffsets.keys.toList, kafkaParams, fromOffsets)
)
}
kafkaStream
}
/**
* 处理完成后将from offset写入zk
* 注意是from offset 不是 until offset
* 为了保证数据不丢失,重启时可能有一个betch数据重复提交
* @param group
* @param ZKservice
* @param kafkaStream
*/
def updateZKOffsets(group:String, ZKservice:String, kafkaStream:InputDStream[ConsumerRecord[String, String]]): Unit = {
val zkClient = new ZkClient(ZKservice)
var offsetRanges = Array[OffsetRange]()
kafkaStream.transform{ rdd =>
//得到该 rdd 对应 kafka 的消息的 offset
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}.map(msg => msg.value()).foreachRDD { rdd =>
for (o <- offsetRanges) {
//不同的topic对应不同的目录
val topicDirs = new ZKGroupTopicDirs(group, o.topic)
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
//将该 partition 的 offset 保存到 zookeeper
new ZkUtils(zkClient,new ZkConnection(ZKservice),false).updatePersistentPath(zkPath, o.fromOffset.toString)
// println(s"@@@@@@ topic ${o.topic} partition ${o.partition} fromoffset ${o.fromOffset} untiloffset ${o.untilOffset} #######")
}
}
}
/**
* 根据任意一台kafka机器ip获取 topich的partition和机器的对应关系
* @param topic_name
* @param broker
* @return
*/
def getLeaders(topic_name:String,broker:String): Map[Int,String] ={
val topic2 = List(topic_name)
val req = new TopicMetadataRequest(topic2, 0)
val getLeaderConsumer = new SimpleConsumer(broker, 9092, 10000, 10000, "OffsetLookup")
val res = getLeaderConsumer.send(req)
val topicMetaOption = res.topicsMetadata.headOption
// 将结果转化为 partition -> leader 的映射关系
val partitions = topicMetaOption match {
case Some(tm) =>
tm.partitionsMetadata.map(pm => (pm.partitionId, pm.leader.get.host)).toMap[Int, String]
case None =>
Map[Int, String]()
}
partitions
}
测试代码如下:
var ssc = new StreamingContext(sc, Seconds(30))
val servers = "broker1.test-bus-kafka.data.m.com:9092,broker2.test-bus-kafka.data.m.com:9092,broker3.test-bus-kafka.data.m.com:9092"
val topic = "antispam.test.ly,antispam.test.ly2"
val path = "/home/hadoopuser/ly/"
val broker = "broker1.test-bus-kafka.data.m.com"
val ZKservice = "zk1.test-inf-zk.data.m.com:2181,zk2.test-inf-zk.data.m.com:2181,zk3.test-inf-zk.data.m.com:2181"
val group = "test_spark_streaming_group"
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> servers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "test",
"auto.offset.reset" -> "earliest"
)
val topics = topic.split(",").toSet
// val topic = "antispam.test.ly2"
val DStream = createDStream(ssc,topics,group,ZKservice,broker,kafkaParams)
DStream.foreachRDD { recored =>
recored.saveAsTextFile(path)
recored.foreachPartition(
message => {
while (message.hasNext) {
println(s"@^_^@ [" + message.next() + "] @^_^@")
}
}
)
}
updateZKOffsets(group,ZKservice,DStream)
ssc.start()
3.调优
Spark streaming+Kafka的使用中,当数据量较小,很多时候默认配置和使用便能够满足情况,但是当数据量大的时候,就需要进行一定的调整和优化,而这种调整和优化本身也是不同的场景需要不同的配置。
3.1合理的批处理时间(batchDuration)
几乎所有的Spark Streaming调优文档都会提及批处理时间的调整,在StreamingContext初始化的时候,有一个参数便是批处理时间的设定。
如果这个值设置的过短,即个batchDuration所产生的Job并不能在这期间完成处理,那么就会造成数据不断堆积,最终导致Spark Streaming发生阻塞。
一般对于batchDuration的设置不会小于500ms,因为过小会导致SparkStreaming频繁的提交作业,对整个streaming造成额外的负担。在平时的应用中,根据不同的应用场景和硬件配置。
3.2合理的Kafka拉取量(maxRatePerPartition重要)
对于Spark Streaming消费kafka中数据的应用场景,这个配置是非常关键的。 配置参数为:spark.streaming.kafka.maxRatePerPartition。
这个参数默认是没有上线的,即kafka当中有多少数据它就会直接全部拉出。而根据生产者写入Kafka的速率以及消费者本身处理数据的速度,同时这个参数需要结合上面的batchDuration,使得每个partition拉取在每个batchDuration期间拉取的数据能够顺利的处理完毕,做到尽可能高的吞吐量。
3.3缓存反复使用的Dstream(RDD)
Spark中的RDD和SparkStreaming中的Dstream,如果被反复的使用,最好利用cache(),将该数据流缓存起来,防止过度的调度资源造成的网络开销
3.4 设置合理的CPU资源数
CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例如,很常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高.
3.5 设置合理的parallelism
在SparkStreaming+kafka的使用中,我们采用了Direct连接方式,前文阐述过Spark中的partition和Kafka中的Partition是一一对应的,我们一般默认设置为Kafka中Partition的数量。