今天是2016年6月9日,也是农历的端午节。
难得的小长假,转眼就到学期末,忙了一学期大概大家或回家过端午或在宿舍休息调养吧,8点25到实验室的时候只有一个从广西大学来学院进修的教授已经开始了一天的工作。自己是觉得没什么特别,所有的节日能让人开心就好,即使没有粽子吃。
Anyway, 还是想说一声:端午节快乐~~
最近实习还一直没有着落,周一的面试是已经gg了,然后又开始投简历以求暑假有个去处,而不至于落单无事可做,尽管自己口头上一直说着无所谓。
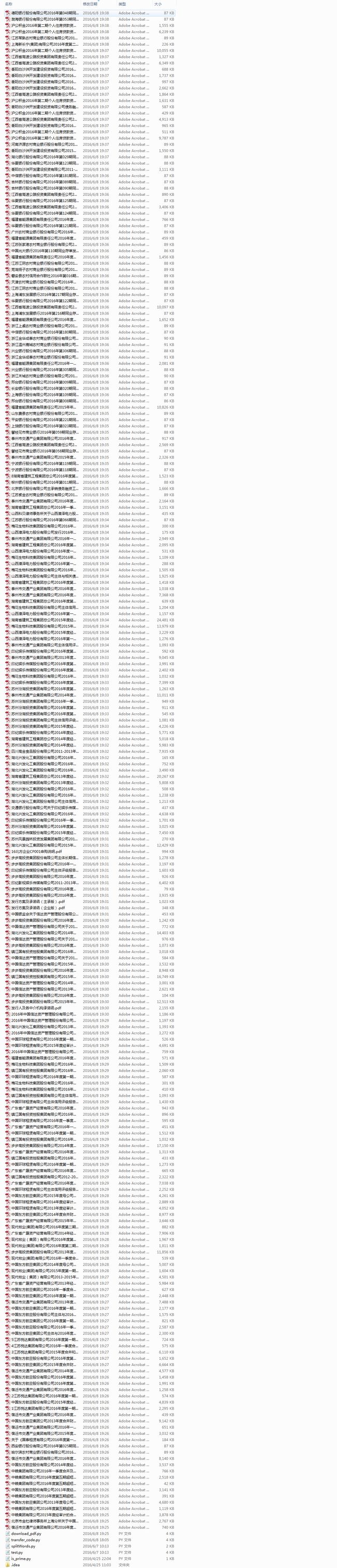
这次的任务是下载上海清算网( http://www.shclearing.com/xxpl/fxpl/ )上前五页中的pdf附件。自己大约琢磨了两天才搞定,最开始以为可以像下载常规的pdf文件文件一样,直接获得pdf文件的链接地址然后用retrieve函数即可完成,但是发现pdf文件的路径是有javascript脚本控制的,你根本拿不到文件的链接地址。
于是开始看能不能构造路径,发现还是行不通,再用fiddler去监控点击下载时发生了什么,这时才有了一点眉目:在点击pdf下载时,是有提交post请求的,传入的了两个参数分别是filename和descname。这时才恍然大悟,像这种点击下载的文件,你要模拟这个点击行为,一般应该就是一个post请求。
再说一下知道是提交post请求后实际操作时有几点要注意:
1.提交到post请求中的参数,通过查看源码后发现是可以用BesutifulSoup配合正则表达式从源码中来直接提取的,正则表达式一般就用re.search(),或者re.findall()
2.提交的filename和descname参数必须先转成URL编码,这是通过fiddler截取到的form表单中发现的,所以又引入urllib库中的parse,再使用parse.quote(text)函数来实现将两个参数转化为URL编码。(自己操作时quote()函数的用法是采用的python3中的语法,若是在python2.x版本中则是直接用urllib.quote(text)即可,但是,但是python2.x版本关于中文编码真的有很多问题,动不动就报错,所以果断没有用python2.x版本)
3.在上述基础上提交了filename和descname参数,如何将pdf保存下来,由于pdf文件比较大,有的达到10M,因此这里会用到 Response.iter_content()的使用,有固定的用法,实现的功能是以流的形式保存较大的文件。具体可以参考。
( http://stackoverflow.com/questions/16694907/how-to-download-large-file-in-python-with-requests-py )
4.要再说一点的就是有时候用requests.get()去请求网址时,加上headers虽说是为了伪装成浏览器进行访问,但有时反而会没有反应,去掉headers后反而就直接出了结果,这是自己不解的地方。
最后贴上代码和抓取结果(243个pdf文件,最大有24M),如下:
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
import requests
from bs4 import BeautifulSoup
from urllib import parse
import re
import time
from multiprocessing import Pool
headers={
'Host': 'www.shclearing.com',
'Connection': 'keep-alive',
'Content-Length': '478',
'Cache-Control': 'max-age=0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Origin': 'http://www.shclearing.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cookie': '_ga=GA1.2.1076225437.1465265795; JSESSIONID=24XcXXCb1bkkKWnKn1LLNBqGTR8qnfmcmf3p5T2pw2TwpNCytnfp!301927905; HDSESSIONID=fhwLXXLPrBqXwsvCyqKL1lCbp5QmGDxxGJ4wd8vrfhr2ksgJcpvf!1660475047; Hm_lvt_d885bd65f967ea9372fc7200bc83fa81=1465223724; Hm_lpvt_d885bd65f967ea9372fc7200bc83fa81=1465354426'
}
url1='http://www.shclearing.com/xxpl/fxpl/index.html'
url2=['http://www.shclearing.com/xxpl/fxpl/index_{}.html'.format(str(i)) for i in range(1,5,1)]
url2.insert(0,url1)
links=[]
host='http://www.shclearing.com/xxpl/fxpl/'
def get_link_list(url):
for item in url:
web_data=requests.get(item)
soup=BeautifulSoup(web_data.text,'lxml')
list=soup.select('ul.list li a')
for item in list:
link=host+item.get('href').split('./')[1]
links.append(link)
FileName=[]
DownName=[]
DownName1=[] #DownName1用于存放转码后的名称
def get_contents(link):
web_data=requests.get(link)
soup=BeautifulSoup(web_data.text,'lxml')
contents=soup.select('#content > div.attachments > script')[0].get_text()
a=str(re.findall(r"fileNames = '(.*?)'",contents,re.M)[0])
b=str(re.findall(r"descNames = '(.*?)'",contents,re.M)[0])
FileName=a.replace('./','').split(';;')
DownName=b.split(';;') #先用正则表达式提取出后面post中要用到的两个参数,但是要将中文转化为对应的URL编码
for item in DownName:
a=parse.quote(item)
DownName1.append(a)
print(FileName,'\\n',DownName,'\\n',DownName1)
for i,j,k in zip(FileName,DownName1,DownName):
download_file(i,j,k)
# link='http://www.shclearing.com/xxpl/fxpl/cp/201606/t20160608_159680.html'
# get_contents(link)
# print('The pdf have been downloaded successfully !')
def download_file(a,b,c):
data={
'FileName':a,
'DownName':b }
local_filename = c
post_url='http://www.shclearing.com/wcm/shch/pages/client/download/download.jsp'
time.sleep(0.5) #限制下载的频次速度,以免被封
# NOTE the stream=True parameter
r = requests.post(post_url, data=data, headers=headers, stream=True)
with open(local_filename, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024): # 1024 是一个比较随意的数,表示分几个片段传输数据。
if chunk: # filter out keep-alive new chunks
f.write(chunk)
f.flush() #刷新也很重要,实时保证一点点的写入。
return local_filename
if __name__=='__main__':
get_link_list(url2)
pool=Pool()
pool.map(get_contents,links)
print('The documents have been downloaded successfully !')
如果要将下载下来的文档的保存的路径存入mysql中,需要再加上下面的语句:
#conn=pymysql.connect(host='localhost',user='root',passwd='root',db='mysql',charset='utf8')
#cursor = conn.cursor()
#cursor.execute('CREATE TABLE root (id int auto_increment primary key,content varchar(100))')
以及在download_file(a,b,c)函数中的return local_filename语句前加上:
cursor.execute('insert into root(content) values (%s)',local_filename)