PS:该文章仅供个人学习交流之用,学识浅薄,不当之处,还请指出!
HashMap简介
- HashMap使用哈希表来存储的。哈希表为解决冲突,可以采用开放地址法和链地址法等来解决问题,Java中HashMap采用了链地址法。链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上
- HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
- HashMap 的实现不是同步的,这意味着它不是线程安全的,它的key、value都可以为null,此外,HashMap中的映射不是有序的。
数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
哈希表
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
分析源码之前先看一张图,HashMap的结构

构造函数
jdk1.8中,HashMap共有四种构造函数:
/**
* Constructs an empty HashMap with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY) {
initialCapacity = MAXIMUM_CAPACITY;
} else if (initialCapacity < DEFAULT_INITIAL_CAPACITY) {
initialCapacity = DEFAULT_INITIAL_CAPACITY;
}
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Android-Note: We always use the default load factor of 0.75f.
// This might appear wrong but it's just awkward design. We always call
// inflateTable() when table == EMPTY_TABLE. That method will take "threshold"
// to mean "capacity" and then replace it with the real threshold (i.e, multiplied with
// the load factor).
threshold = initialCapacity;
init();
}
/**
* Constructs an empty HashMap with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs a new HashMap with the same mappings as the
* specified Map. The HashMap is created with
* default load factor (0.75) and an initial capacity sufficient to
* hold the mappings in the specified Map.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap(Map m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);
putAllForCreate(m);
}
几个重要的参数
int threshold; // 所能容纳的key-value对极限
final float loadFactor; // 负载因子
int modCount;
int size;
- Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold = length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
- threshold就是在此Load factor和length(数组长度)对应下允许的最大元素数目,超过这个数目就重新resize(扩容),扩容后的HashMap容量是之前容量的两倍。默认的负载因子0.75是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
- size这个字段其实很好理解,就是HashMap中实际存在的键值对数量。注意和table的长度length、容纳最大键值对数量threshold的区别。而modCount字段主要用来记录HashMap内部结构发生变化的次数,主要用于迭代的快速失败。强调一点,内部结构发生变化指的是结构发生变化,例如put新键值对,但是某个key对应的value值被覆盖不属于结构变化。
put函数实现
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
int i = indexFor(hash, table.length);
for (HashMapEntry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
/**
* Offloaded version of put for null keys
*/
private V putForNullKey(V value) {
for (HashMapEntry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
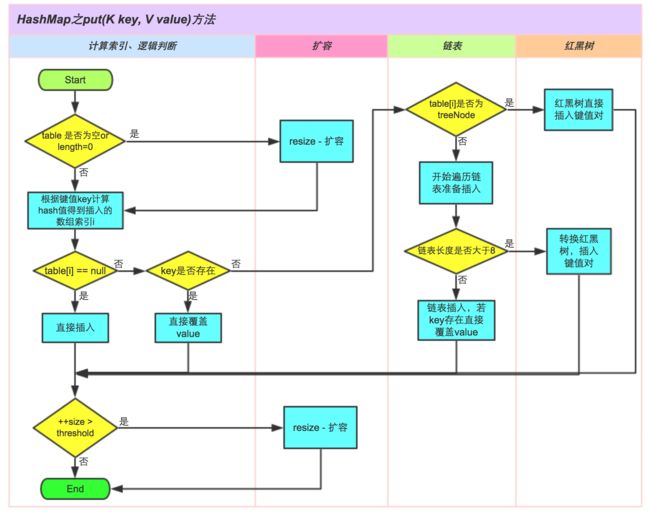
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
插入新Entry数据:
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
如果Entry数组的bucketIndex上已经有Entry存在,就把新的Entry放在bucketIndex位置,原Entry移到新Entry的next指向的位置———在链表头部插入数据,如果bucketIndex位置上没有Entry存在,新插入的Entry的next指向null。
链表设计——可以看得出这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。**
HashMap使用链表来解决碰撞问题,当两个key的hashcode值一样时,即发生碰撞时,存放在链表的下一个节点中。
get函数实现
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 直接命中
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 未命中
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
-
- bucket里的第一个节点,直接命中;
-
- 如果有冲突,则通过key.equals(k)去查找对应的entry
若为树,则在树中通过key.equals(k)查找,O(logn);
若为链表,则在链表中通过key.equals(k)查找,O(n)。
- 如果有冲突,则通过key.equals(k)去查找对应的entry
扩容机制
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
1 final Node[] resize() {
2 Node[] oldTab = table;
3 int oldCap = (oldTab == null) ? 0 : oldTab.length;
4 int oldThr = threshold;
5 int newCap, newThr = 0;
6 if (oldCap > 0) {
7 // 超过最大值就不再扩充了,就只好随你碰撞去吧
8 if (oldCap >= MAXIMUM_CAPACITY) {
9 threshold = Integer.MAX_VALUE;
10 return oldTab;
11 }
12 // 没超过最大值,就扩充为原来的2倍
13 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
14 oldCap >= DEFAULT_INITIAL_CAPACITY)
15 newThr = oldThr << 1; // double threshold
16 }
17 else if (oldThr > 0) // initial capacity was placed in threshold
18 newCap = oldThr;
19 else { // zero initial threshold signifies using defaults
20 newCap = DEFAULT_INITIAL_CAPACITY;
21 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
22 }
23 // 计算新的resize上限
24 if (newThr == 0) {
25
26 float ft = (float)newCap * loadFactor;
27 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
28 (int)ft : Integer.MAX_VALUE);
29 }
30 threshold = newThr;
31 @SuppressWarnings({"rawtypes","unchecked"})
32 Node[] newTab = (Node[])new Node[newCap];
33 table = newTab;
34 if (oldTab != null) {
35 // 把每个bucket都移动到新的buckets中
36 for (int j = 0; j < oldCap; ++j) {
37 Node e;
38 if ((e = oldTab[j]) != null) {
39 oldTab[j] = null;
40 if (e.next == null)
41 newTab[e.hash & (newCap - 1)] = e;
42 else if (e instanceof TreeNode)
43 ((TreeNode)e).split(this, newTab, j, oldCap);
44 else { // 链表优化重hash的代码块
45 Node loHead = null, loTail = null;
46 Node hiHead = null, hiTail = null;
47 Node next;
48 do {
49 next = e.next;
50 // 原索引
51 if ((e.hash & oldCap) == 0) {
52 if (loTail == null)
53 loHead = e;
54 else
55 loTail.next = e;
56 loTail = e;
57 }
58 // 原索引+oldCap
59 else {
60 if (hiTail == null)
61 hiHead = e;
62 else
63 hiTail.next = e;
64 hiTail = e;
65 }
66 } while ((e = next) != null);
67 // 原索引放到bucket里
68 if (loTail != null) {
69 loTail.next = null;
70 newTab[j] = loHead;
71 }
72 // 原索引+oldCap放到bucket里
73 if (hiTail != null) {
74 hiTail.next = null;
75 newTab[j + oldCap] = hiHead;
76 }
77 }
78 }
79 }
80 }
81 return newTab;
82 }
同时实现Map接口的还有 HashMap、Hashtable、LinkedHashMap和TreeMap,类继承关系如下图所示:
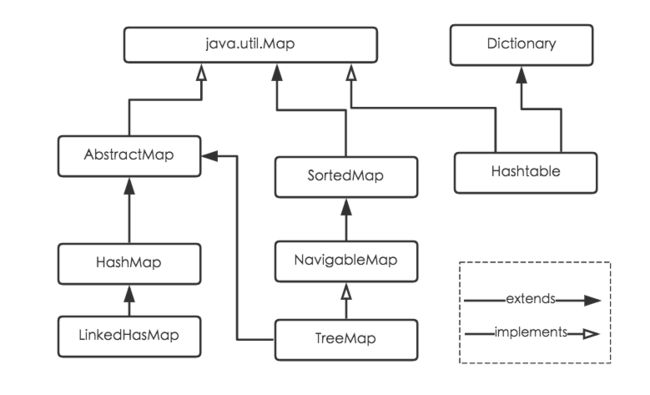
(1) HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
(2) Hashtable:Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
(3) LinkedHashMap:LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
(4) TreeMap:TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
总结:
HashMap的工作原理:
运用hash的方法,通过put和get存储和获取对象。存储对象时,我们将K/V传给put方法时,它调用hashCode计算hash从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量(超过Load Facotr则resize为原来的2倍)。获取对象时,我们将K传给get,它调用hashCode计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。如果发生碰撞的时候,Hashmap通过链表将产生碰撞冲突的元素组织起来,在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度。
参考
ConcurrentHashMap实现原理及源码分析
Java 8系列之重新认识HashMap
Java HashMap工作原理及实现
HashMap的工作原理--重点----数据结构示意图的理解