初识汇编
我们是逆向iOS系统上面的APP.那么我们知道,一个APP安装在手机上面的可执行文件本质上是二进制文件.因为iPhone手机本质上执行的指令是二进制.是由手机上的CPU执行的.所以静态分析是建立在分析二进制上面.静态分析的基础是汇编,可以说掌握汇编知识的多少,决定着在逆向以及安全的道路上你能走多远。
汇编语言的发展
机器语言
由0和1组成的机器指令.
- 加:0100 0000
- 减:0100 1000
- 乘:1111 0111 1110 0000
- 除:1111 0111 1111 0000
汇编语言(assembly language)
使用助记符代替机器语言
如:
- 加:INC EAX 通过编译器 0100 0000
- 减:DEC EAX 通过编译器 0100 1000
- 乘:MUL EAX 通过编译器 1111 0111 1110 0000
- 除:DIV EAX 通过编译器 1111 0111 1111 0000
高级语言(High-level programming language)
C\C++\Java\OC\Swift,更加接近人类的自然语言
比如C语言:
- 加:A+B 通过编译器 0100 0000
- 减:A-B 通过编译器 0100 1000
- 乘:A*B 通过编译器 1111 0111 1110 0000
- 除:A/B 通过编译器 1111 0111 1111 0000
代码在终端设备上执行的过程:
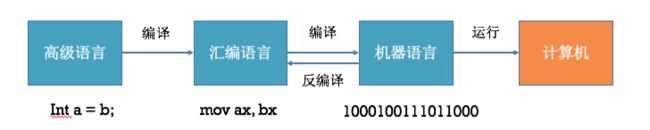
- 汇编语言与机器语言一一对应,每一条机器指令都有与之对应的汇编指令
- 汇编语言可以通过编译得到机器语言,机器语言可以通过反汇编得到汇编语言
- 高级语言可以通过编译得到汇编语言 \ 机器语言,但汇编语言\机器语言几乎不可能还原成高级语言
汇编语言的特点
可以直接访问、控制各种硬件设备,比如存储器、CPU等,能最大限度地发挥硬件的功能
能够不受编译器的限制,对生成的二进制代码进行完全的控制
目标代码简短,占用内存少,执行速度快
汇编指令是机器指令的助记符,同机器指令一一对应。每一种CPU都有自己的机器指令集\汇编指令集,所以汇编语言不具备可移植性
知识点过多,开发者需要对CPU等硬件结构有所了解,不易于编写、调试、维护
不区分大小写,比如mov和MOV是一样的
汇编的用途
编写驱动程序、操作系统(比如Linux内核的某些关键部分)
对性能要求极高的程序或者代码片段,可与高级语言混合使用(内联汇编)
-
软件安全
- 病毒分析与防治
2.逆向\加壳\脱壳\破解\外挂\免杀\加密解密\漏洞\黑客
理解整个计算机系统的最佳起点和最有效途径
为编写高效代码打下基础
弄清代码的本质
函数的本质究竟是什么?
++a + ++a + ++a 底层如何执行的?
3.编译器到底帮我们干了什么?
4.DEBUG模式和RELEASE模式有什么关键的地方被我们忽略
越底层越单纯!真正的程序员都需要了解的一门非常重要的语言,汇编!
汇编语言的种类
目前讨论比较多的汇编语言有
- 8086汇编(8086处理器是16bit的CPU)
- Win32汇编
- Win64汇编
- ARM汇编(嵌入式、Mac、iOS)
-
iPhone里面用到的是ARM汇编,但是不同的设备也有差异.因CPU的架构不同.
 iPhone架构
iPhone架构
几个必要的常识
- 要想学好汇编,首先需要了解CPU等硬件结构
- APP/程序的执行过程
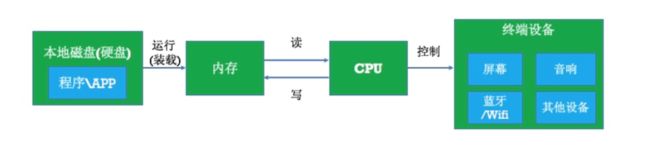
- 硬件相关最为重要是CPU/内存
- 在汇编中,大部分指令都是和CPU与内存相关的
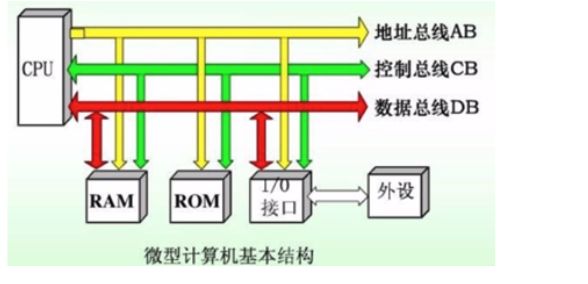
总线

- 每一个CPU芯片都有许多管脚,这些管脚和总线相连,CPU通过总线跟外部器件进行交互
- 总线:一根根导线的集合
- 总线的分类
- 地址总线
- 数据总线
- 控制总线
--地址总线
- 它的宽度决定了CPU的寻址能力 最大寻址值
32位 32根
inter有地址加法器 可以表达更高地址 - 8086的地址总线宽度是20,所以寻址能力是1M( 2的20次方 ),最大能表达1M( 2的20次方)
--数据总线
- 它的宽度决定了CPU的单次数据传送量,也就是数据传送速度
- 8086的数据总线宽度是16,所以单次最大传递2个字节的数据
cpu架构由数据总线来区分 arm32,arm64等等
控制总线
- 它的宽度决定了CPU对其他器件的控制能力、能有多少种控制
练习
一个CPU 的寻址能力为8K,那么它的地址总线的宽度为13;1k为10根
8080,8088,80286,80386 的地址总线宽度分别为16根,20根,24根,32根.那么他们的寻址能力分别为64K,1M,16M,4G。
8080,8088,8086,80286,80386 的数据总线宽度分别为8根,8根,16根,16根,32根.那么它们一次可以传输的数据为:1B,1B,2B,2B,4B;
从内存中读取1024字节的数据,8086至少要读512次,80386至少要读取256次.
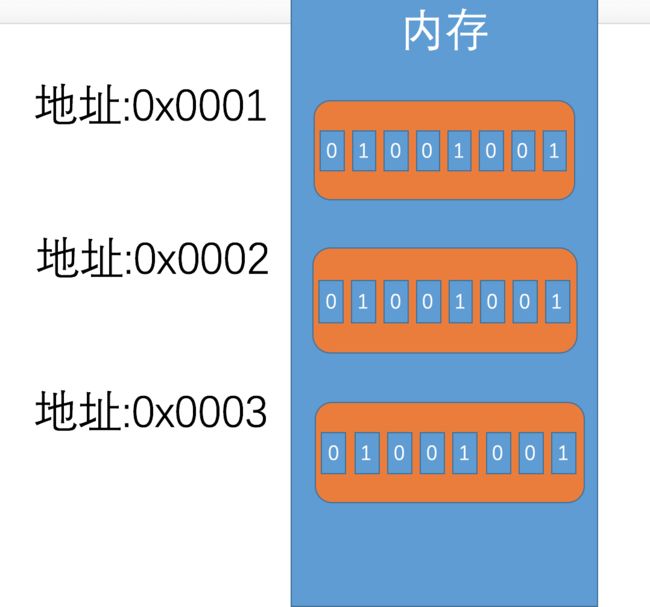
内存
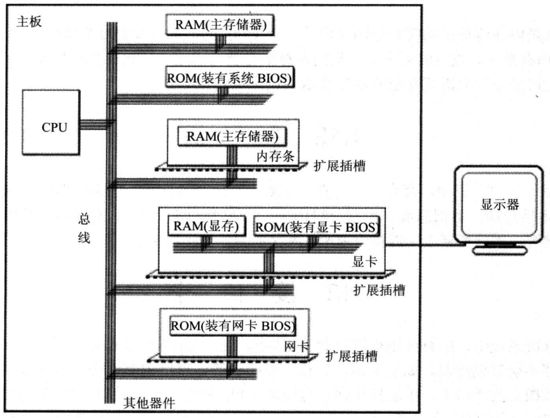
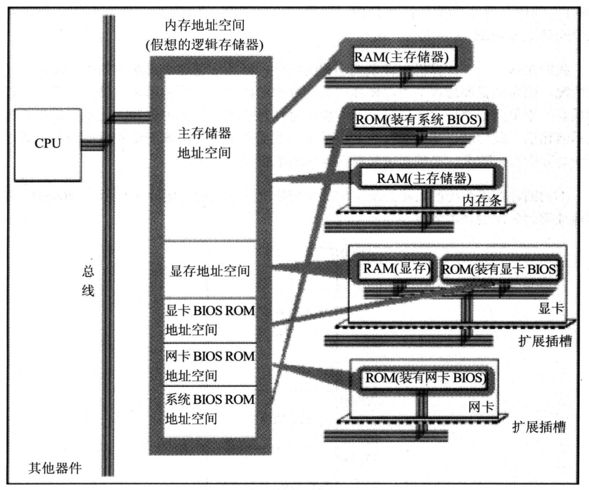

- 内存地址空间的大小受CPU地址总线宽度的限制。8086的地址总线宽度为20,可以定位220个不同的内存单元(内存地址范围0x00000~0xFFFFF),所以8086的内存空间大小为1MB
- 0x00000~0x9FFFF:主存储器。可读可写
- 0xA0000~0xBFFFF:向显存中写入数据,这些数据会被显卡输出到显示器。可读可写
- 0xC0000~0xFFFFF:存储各种硬件\系统信息。只读
堆:低往高写
栈:高往低写
写入和读取后,给定地址后,数据写入从低往高写。
进制
很多人学不好进制,原因是总以十进制为依托去考虑其他进制,需要运算的时候也总是先转换成十进制,这种学习方法是错误的.
我们为什么一定要转换十进制呢?仅仅是因为我们对十进制最熟悉,所以才转换.
每一种进制都是完美的,想学好进制首先要忘掉十进制,也要忘掉进制间的转换!
进制的定义
- 八进制由8个符号组成:0 1 2 3 4 5 6 7 逢八进一
- 十进制由10个符号组成:0 1 2 3 4 5 6 7 8 9逢十进一
- N进制就是由N个符号组成:逢N进一
自定义进制符号
十进制由10个符号组成: 0 1 3 2 8 A B E S 7 逢十进一 "0 1 3 2 8 A B E S 7 ",只是十个符号而已,自定义进制符号
自定义进制符号的用途
传统我们定义的十进制和自定义的十进制不一样.那么这10个符号如果我们不告诉别人这个符号表,别人是没办法拿到我们的具体数据的!用于加密!
十进制由十个符号组成,逢十进一,符号是可以自定义的!!
进制的运算
- 八进制加法表
0 1 2 3 4 5 6 7
10 11 12 13 14 15 16 17
20 21 22 23 24 25 26 27
...
1+1 = 2
1+2 = 3 2+2 = 4
1+3 = 4 2+3 = 5 3+3 = 6
1+4 = 5 2+4 = 6 3+4 = 7 4+4 = 10
1+5 = 6 2+5 = 7 3+5 = 10 4+5 = 11 5+5 = 12
1+6 = 7 2+6 = 10 3+6 = 11 4+6 = 12 5+6 = 13 6+6 = 14
1+7 = 10 2+7 = 11 3+7 = 12 4+7 = 13 5+7 = 14 6+7 = 15 7+7 = 16
- 八进制乘法表
0 1 2 3 4 5 6 7 10 11 12 13 14 15 16 17 20 21 22 23 24 25 26 27...
1x1 = 1
1x2 = 2 2x2 = 4
1x3 = 3 2x3 = 6 3x3 = 11
1x4 = 4 2x4 = 10 3x4 = 14 4x4 = 20
1x5 = 5 2x5 = 12 3x5 = 17 4x5 = 24 5x5 = 31
1x6 = 6 2x6 = 14 3x6 = 22 4x6 = 30 5x6 = 36 6x6 = 44
1x7 = 7 2x7 = 16 3x7 = 25 4x7 = 34 5x7 = 43 6x7 = 52 7x7 = 61
二进制的简写形式
二进制: 1 0 1 1 1 0 1 1 1 1 0 0
三个二进制一组: 101 110 111 100
八进制: 5 6 7 4
四个二进制一组: 1011 1011 1100
十六进制: b b c
二进制:从0 写到 1111
0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111
这种二进制使用起来太麻烦,改成更简单一点的符号:
0 1 2 3 4 5 6 7 8 9 A B C D E F 这就是十六进制了
自定义进制符号
现在有10进制数 10个符号分别是:2,9,1,7,6,5,4, 8,3 , A 逢10进1 那么: 计算123 + 234
十进制: 0 1 2 3 4 5 6 7 8 9
自定义: 2 9 1 7 6 5 4 8 3 A
92 99 91 97 96 95 94 98 93 9A
12 19 11 17 16 15 14 18 13 1A
72 79 71 77 76 75 74 78 73 7A
62 69 61 67 66 65 64 68 63 6A
52 59 51 57 56 55 54 58 53 5A
42 49 41 47 46 45 44 48 43 4A
82 89 81 87 86 85 84 88 83 8A
32 39 31 37 36 35 34 38 33 3A
922
那么刚才通过10进制运算可以转化10进制然后查表!但是如果是其他进制.我们就不能转换,要直接学会查表
- 现在有9进制数 9个符号分别是:2,9,1,7,6,5,4, 8,3 逢9进1 那么: 计算 123 + 234
十进制: 0 1 2 3 4 5 6 7 8
自定义: 2 9 1 7 6 5 4 8 3
92 99 91 97 96 95 94 98 93
12 19 11 17 16 15 14 18 13
72 79 71 77 76 75 74 78 73
62 69 61 67 66 65 64 68 63
52 59 51 57 56 55 54 58 53
42 49 41 47 46 45 44 48 43
82 89 81 87 86 85 84 88 83
32 39 31 37 36 35 34 38 33
922
数据的宽度
数学上的数字,是没有大小限制的,可以无限的大。但在计算机中,由于受硬件的制约,数据都是有长度限制的(我们称为数据宽度),超过最多宽度的数据会被丢弃。
#import
#import "AppDelegate.h"
int test(){
int cTemp = 0x1FFFFFFFF;
return cTemp;
}
int main(int argc, char * argv[]) {
printf("%x\n",test());
@autoreleasepool {
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
}
计算机中常见的数据宽度
- 位(Bit): 1个位就是1个二进制位.0或者1
- 字节(Byte): 1个字节由8个Bit组成(8位).内存中的最小单元Byte.
- 字(Word): 1个字由2个字节组成(16位),这2个字节分别称为高字节和低字节.
- 双字(Doubleword): 1个双字由两个字组成(32位)
那么计算机存储数据它会分为有符号数和无符号数.
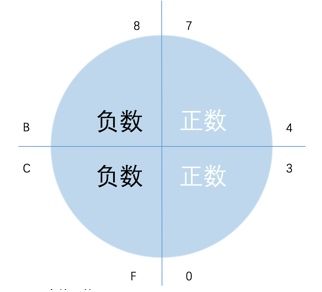
有符号:最大数据宽度的一半标示
无符号数,直接换算!
有符号数:
正数: 0 1 2 3 4 5 6 7
负数: F E D B C A 9 8
-1 -2 -3 -4 -5 -6 -7 -8
CPU&寄存器
内部部件之间由总线连接
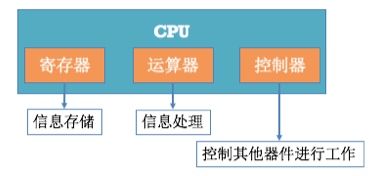
- CPU除了有控制器、运算器还有寄存器。其中寄存器的作用就是进行数据的临时存储。
CPU的运算速度是非常快的,为了性能CPU在内部开辟一小块临时存储区域,并在进行运算时先将数据从内存复制到这一小块临时存储区域中,运算时就在这一小快临时存储区域内进行。我们称这一小块临时存储区域为寄存器。
- 对于arm64系的CPU来说, 如果寄存器以x开头则表明的是一个64位的寄存器,如果以w开头则表明是一个32位的寄存器,在系统中没有提供16位和8位的寄存器供访问和使用。其中32位的寄存器是64位寄存器的低32位部分并不是独立存在的。
- 对程序员来说,CPU中最主要部件是寄存器,可以通过改变寄存器的内容来实现对CPU的控制
- 不同的CPU,寄存器的个数、结构是不相同的
浮点和向量寄存器
因为浮点数的存储以及其运算的特殊性,CPU中专门提供浮点数寄存器来处理浮点数
- 浮点寄存器 64位: D0 - D31 32位: S0 - S31
现在的CPU支持向量运算.(向量运算在图形处理相关的领域用得非常的多)为了支持向量计算系统了也提供了众多的向量寄存器.
- 向量寄存器 128位:V0-V31
浮点和向量寄存器
- 通用寄存器也称数据地址寄存器通常用来做数据计算的临时存储、做累加、计数、地址保存等功能。定义这些寄存器的作用主要是用于在CPU指令中保存操作数,在CPU中当做一些常规变量来使用。
- ARM64拥有有32个64位的通用寄存器 x0 到 x30,以及XZR(零寄存器),这些通用寄存器有时也有特定用途。
x0 - x30 fp lr
1.那么w0 到 w28 这些是32位的. 因为64位CPU可以兼容32位.所以可以只使用64位寄存器的低32位
2.比如 w0 就是 x0的低32位!

注意:
了解过8086汇编的同学知道,有一种特殊的寄存器段寄存器:CS,DS,SS,ES四个寄存器来保存这些段的基地址,这个属于Intel架构CPU中.在ARM中并没有
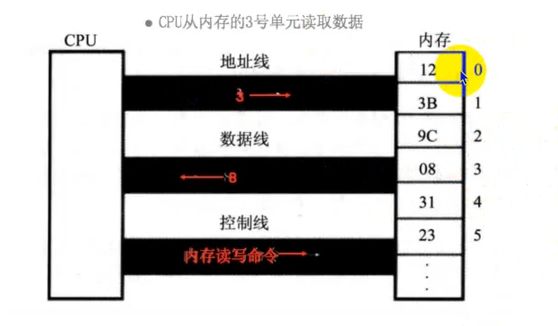
- 通常,CPU会先将内存中的数据存储到通用寄存器中,然后再对通用寄存器中的数据进行运算
- 假设内存中有块红色内存空间的值是3,现在想把它的值加1,并将结果存储到蓝色内存空间
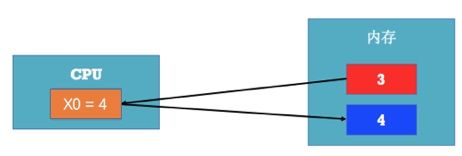
1.CPU首先会将红色内存空间的值放到X0寄存器中:mov X0,红色内存空间
2.然后让X0寄存器与1相加:add X0,1
3.最后将值赋值给内存空间:mov 蓝色内存空间,X0
pc寄存器(program counter)
- 为指令指针寄存器,它指示了CPU当前要读取指令的地址
- 在内存或者磁盘上,指令和数据没有任何区别,都是二进制信息
- CPU在工作的时候把有的信息看做指令,有的信息看做数据,为同样的信息赋予了不同的意义
1.比如 1110 0000 0000 0011 0000 1000 1010 1010
- 可以当做数据 0xE003008AA
- 也可以当做指令 mov x0, x8
- CPU根据什么将内存中的信息看做指令?
- CPU将pc指向的内存单元的内容看做指令
- 如果内存中的某段内容曾被CPU执行过,那么它所在的内存单元必然被pc指向过
cpu先读取内存,内存读取的速度决定代码读取执行速度,为了弥补这个短板,有了高速缓存
高速缓存
iPhoneX上搭载的ARM处理器A11它的1级缓存的容量是64KB,2级缓存的容量8M.
- CPU每执行一条指令前都需要从内存中将指令读取到CPU内并执行。而寄存器的运行速度相比内存读写要快很多,为了性能,CPU还集成了一个高速缓存存储区域.当程序在运行时,先将要执行的指令代码以及数据复制到高速缓存中去(由操作系统完成).CPU直接从高速缓存依次读取指令来执行.
1.系统将内存的指令保存到高速缓存中
2.建立内存地址到高速缓存的映射关系
3.操作系统先去高速缓存中寻找指令的映射,如果没有映射,触发系统再次加载代码到高速缓存区,执行1和2步骤,再次读取的数据和映射关系会覆盖原来的指令和映射关系。
查看pc寄存器
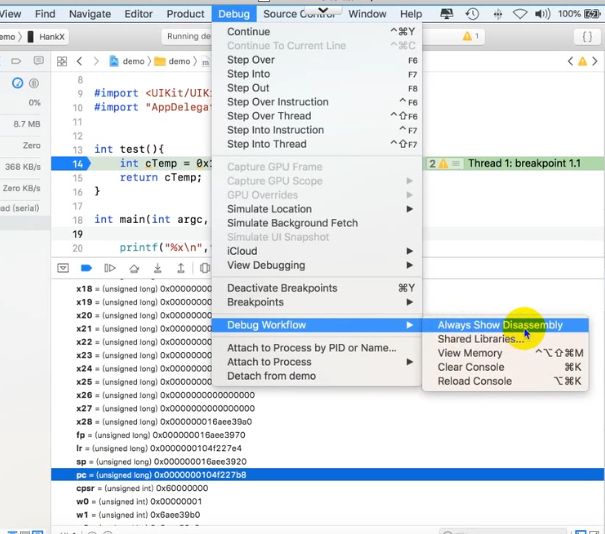
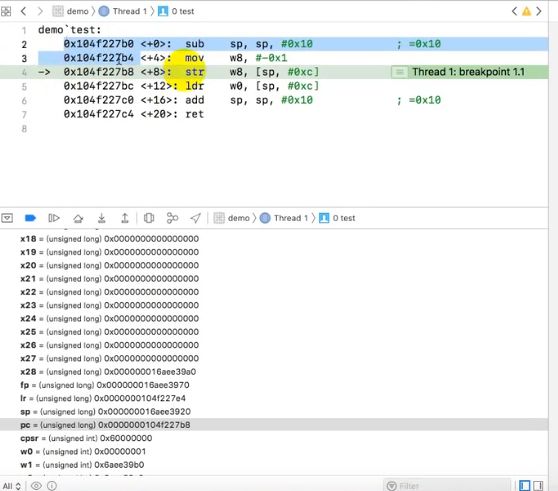
每一条指令4个字节,大于4个字节时溢出
标示常量
pc寄存器标示cpu接下来要执行的指令
修改pc地址后可修改代码执行顺序和逻辑
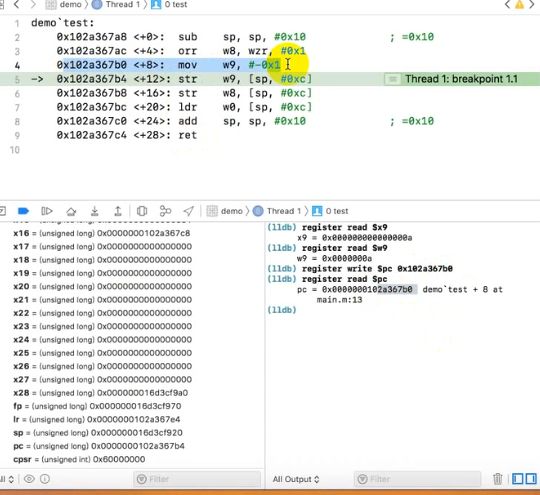
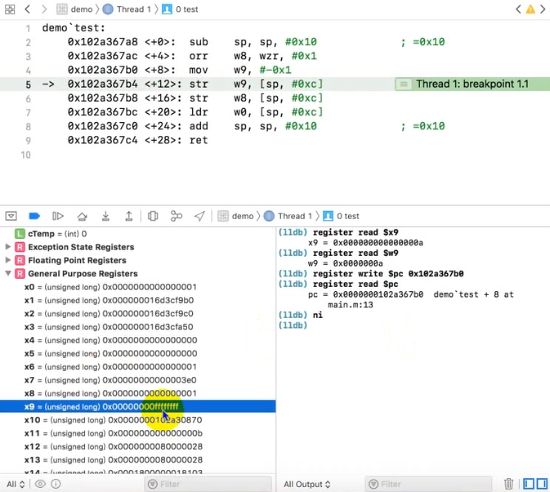
bl指令
- CPU从何处执行指令是由pc中的内容决定的,我们可以通过改变pc的内容来控制CPU执行目标指令
- ARM64提供了一个mov指令(传送指令),可以用来修改大部分寄存器的值,比如
mov x0,#10、mov x1,#20 - 但是,mov指令不能用于设置pc的值,ARM64没有提供这样的功能
- ARM64提供了另外的指令来修改PC的值,这些指令统称为转移指令,最简单的是bl指令
bl指令 -- 练习
新建汇编文件
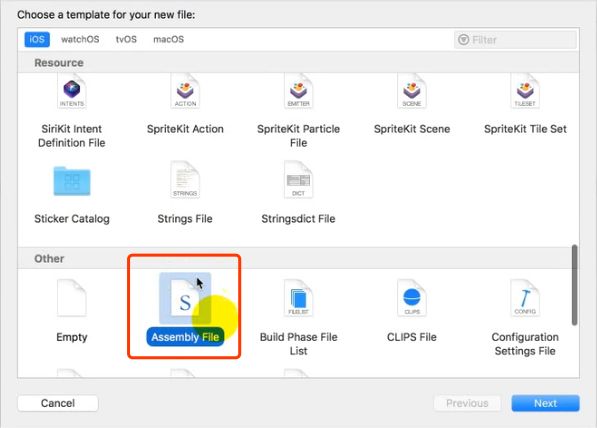
汇编文件参与编译
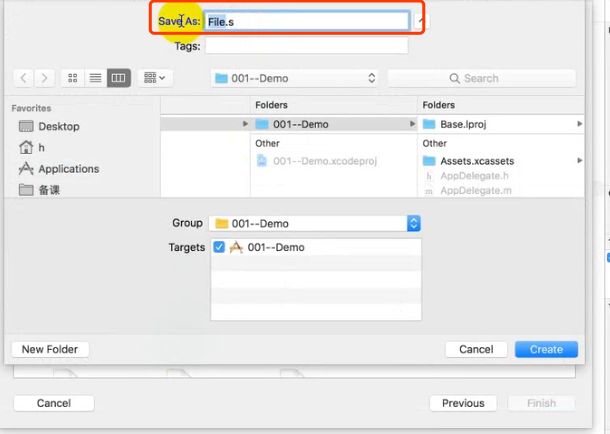
.text //macho 中text段
.global _A,_B // 全局标号 外部可以调用 相当于声明
_A:
mov x0,#0xa
mov x1,#0x00
add x1,x0,#0xff
MOV X0,x1
bl _B
mov x0,#0x00
ret
_B:
add x0,x0,#0x10
ret
调用
int A(void); //声明 成功链接
int main(int argc, char * argv[]) {
A();
@autoreleasepool {
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
}
汇编断点查看
- 在汇编文件中直接下断点无法查看
- 在函数调用处下断点
总结
汇编概述:
- 使用助记符代替机器指令的一种编程语言.
- 汇编和机器指令是一一对应的关系,拿到二进制就可以反汇编.
- 由于汇编和CPU的指令集是对应的,所以汇编不具备移植性
总线:是有一堆导线的集合
- 地址总线
地址总线的宽度决定了寻址能力 - 数据总线
数据总线的宽度决定了CPU数据的吞吐量
进制
- 任意进制,都是由对应个数的符号组成的.符号可以自定义
- 2\8\16 是相对完美的进制.他们之间的关系
1.3个2进制位 使用一个 8进制标识
2.4个2进制位 使用一个 16进制标识
3.两个16进制位可以标识一个字节 - 数量单位
1.1024 = 1K ; 1024K = 1M ; 1024 M = 1G - 容量单位
1.1024B = 1KB; 1024KB = 1MB; 1024MB = 1GB
2.B:byte(字节) 1B = 8bit
3.bit(比特):一个二进制位 - 数据的宽度
1.计算机中的数据是有宽度的,超过了就会溢出
寄存器:CPU为了性能,在内部开辟了一小块临时存储区域
- 浮点向量寄存器
- 异常状态寄存器
- 通用寄存器:除了存放数据有时候也有特殊的用途
1.ARM64拥有32个64位的通用寄存器 X0 -- X30 以及XZR(零寄存器)
2.为了兼容32位,所以ARM64拥有W0 -- W28 \ WZR 30个32位寄存器
3.32为寄存器并不是独立存在的,比如W0 是X0的低32位! - PC寄存器:指令指针寄存器
1.PC寄存器里面的值保存的就是CPU接下来需要执行的指令地址!
2.改变PC的值可以改变程序的执行流程!