1. Stack
stack的准则:last in first out。创建stack的class如下:
class StackException(Exception):
def __init__(self, message):
self.message = message
class Stack:
def __init__(self):
self._data = []
def peek_at_top(self):
#因为stack是后入先出的,所以查看最顶上的元素是最后加入的
if not self._data:
raise StackException('Stack is empty')
return self._data[-1]
def pop(self):
if not self._data:
raise StackException('Stack is empty')
return self._data.pop()
def push(self, datum):
return self._data.append(datum)
def is_empty(self):
return self._data == []
1.1 Stack Exercise1
检查数学表达式的括号是否匹配。因为括号都是逐对匹配,且内侧括号优先级高于外侧,后输入的括号先匹配,所以适合用stack完成。
Stack的使用原则非常重要,遇到实际问题时,判断问题的解决顺讯,如果符合后进先出,则可以使用Stack。
def check_well_balanced(expression):
stack = Stack()
parentheses = {')': '(', ']': '[', '}': '{'}
#将需要匹配的括号创建一个key-value字典,方便判断
for e in expression:
if e in '([{':
stack.push(e)
#所有遇见的左括号都压入栈中
elif e in parentheses:
try:
if stack.pop() != parentheses[e]:
raise StackException('')
#无论是否匹配,stack.pop()都已经弹出了栈中最外面的括号,不匹配自动报错,匹配则继续
except StackException as e:
return False
#如果不匹配,则返回False,并不抛出Exception的message
return stack.is_empty()
#最后还要判断栈是否为空,如果不为空结果依然是False
1.2 Stack Exercise2
在进行数学表达式运算时,括号的处理对计算机不友好,所以创建了一种postfix operation的方式来让计算机清楚要进行的运算。例如:
(2 + 3) * 5,写成postfix operation是2 3 + 5 *;2 * (3 + 5),写成postfix operation是2 3 5 + *
因为是后置运算,内侧括号优先级高,和Exercise1的分析一样,依然适合stack的应用。
def evaluate_postfix_expression(expression):
stack = Stack()
operators = {'+': lambda x, y: x + y,
'-': lambda x, y: y - x,
'*': lambda x, y: x * y,
'/': lambda x, y: y // x}
#创建operator的方法,key对应的value是一个function,因为栈是后进先出,所以要注意减法除法的顺序,同时除法要注意使用//,不然可能会把int转变为float。
in_number = False
#因为expression是逐个读取的,所以数字不能完整转译成需要的值,比如234,先读入的是2,然后是3,所以要判断当前数字是否在一个数字中,default是不在
for e in expression:
if e.isdigit():
if not in_number:
stack.push(int(e))
#因为后续要做数字运算,所以要不输入的string类型转变为int
in_number = True
else:
stack.push(stack.pop() * 10 + int(e))
#如果前面已经有数字,则把前面的数字从栈中推出,10倍后加上当前数字,再压入栈中。
else:
in_number = False
if e in operators:
try:
arg_1 = stack.pop()
arg_2 = stack.pop()
stack.push(operators[e](arg_1, arg_2))
except StackException as e:
raise e
try:
value = stack.pop()
if not stack.is_empty():
raise StackExcpetion('Expression is not correct')
return value
except StackException as e:
raise e
1.3 Stack Exercise3
算法中Depth First Search和stack非常契合,优先解决一条路径上所有可能性,在当下路径下发现的新加入的节点会优先搜索。
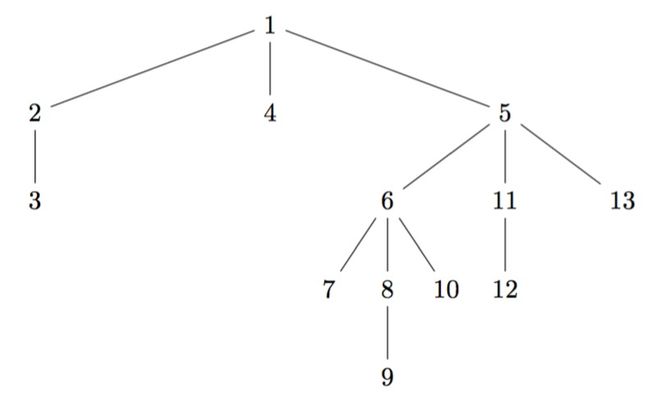
上图的搜索流程如下,注意压栈的顺序是从右向左:
No. 1 2 3 4 5 6 ...
Stack 1 2 3 4 5 6 ...
4 4 5 11 ...
5 5 13 ...
Operation push1 pop1 pop2 pop3 pop4 pop5 ...
push5 push3 push13
push4 push11
push2 push6
DFS的代码实现基于Stack的方式如下:
T = {1: [2, 4, 5], 2: [3], 5: [6, 11, 13], 6: [7, 8, 10], 8: [9], 11: [12]}
def depth_fisrt_search():
stack = Stack()
stack.push([1])
#将Tree root先压入栈中
while not stack.is_empty:
path = stack.pop()
#将一个节点的值从栈中取出并显示
print(path)
if path[-1] in T:
for child in reversed(T[path[-1]]):
stack.push(list(path) + [child])
#如果该节点有child,则按照逆序方法把child压入栈中,不同的是压入的时候把前面做过的路径也储存了进来
depth_first_exploration()
>>>
[1]
[1, 2]
[1, 2, 3]
[1, 4]
[1, 5]
[1, 5, 6]
[1, 5, 6, 7]
[1, 5, 6, 8]
[1, 5, 6, 8, 9]
[1, 5, 6, 10]
[1, 5, 11]
[1, 5, 11, 12]
[1, 5, 13]
上述代码手动输入了一个tree T,写成自动代码是:
from collections import defaultdict
def tree():
return defaultdict(tree)
#以tree作为type反复调用生成一个tree,数据结构是defaultdict
T = tree()
T[1][2][3] = None
T[1][4] = None
T[1][5][6][7] = None
T[1][5][6][8][9] = None
T[1][5][6][10] = None
T[1][5][11][12] = None
T[1][5][13] = None
#以每一条可以连通的路径作为tree的生成过程,最终形成一个tree
T
>>>
defaultdict(,
{1: defaultdict(,
{2: defaultdict(, {3: None}),
4: None,
5: defaultdict(,
{6: defaultdict(,
{7: None,
8: defaultdict(,
{9: None}),
10: None}),
11: defaultdict(,
{12: None}),
13: None})})})
基于tree的结构update DFS的代码如下:
def depth_first_exploration():
stack = Stack()
stack.push(([1], T[1]))
#将tree root和后续的tree压入栈中
while not stack.is_empty():
path, tree = stack.pop()
#path指向当前节点的值,tree指向当前节点后续的tree
print(path)
if tree:
for child in reversed(list(tree)):
stack.push((list(path) + [child], tree[child]))
#只要当前节点后面还有枝叶,则将其压入栈中
#压入方法和前面一致,把concatenate之前path的child,和该节点后续的tree的defaultdict做成一个tuple压入栈中。
2. Fractal(分形)
引用Wikipedia的解释:“分形(英语:Fractal),又称碎形、残形,通常被定义为“一个粗糙或零碎的几何形状,可以分成数个部分,且每一部分都(至少近似地)是整体缩小后的形状”,即具有自相似的性质。”
通过定义一个规则使得后续的复制能够继续,自然界最常见的分形比如树叶和海岸线。
规则举例:

(1)原图案各边都缩小到原来的1/2
(2)以左下方为坐标原点,输出第1个新图案到和原图案相同的坐标点
(3)以左下方为坐标原点,输出第2个新图案到横坐标的1/2纵坐标不变的坐标点
(4)以左下方为坐标原点,输出第3个新图案到横坐标的1/4纵坐标向上移动1/2的坐标点
每次对图中所有原图案都执行同样的操作,就形成了上述的图片。
最终的图案只体现规则,而不以最初的图案改变,比如同样的规则下会形成下图:

3. Queue
queue的准则:first in first out,顺序与stack相比是反的。因为queue只需要不断改变两头的数据,所以linkedlist是适合queue的数据结构,创建queue的class如下:
class Node:
def __init__(self, value):
self.value = value
self.next_node = None
class QueueException(Exception):
def __init__(self, message):
self.message = message
class Queue:
def __init__(self):
self.head = None
self.tail = None
#Queue只对头尾操作,所以initiation只需要定义head和tail
def enqueue(self, value):
new_node = Node(value)
if not self.tail:
self.tail = new_node
self.head = self.tail
return
#判断如果queue为空,tail指向新加入的点,head与其相同
self.tail.next_node = new_node
self.tail = new_node
#在linkedlist尾端增加一个点,比如a - > b,加入新点c,这个时候先让b的next等于c,然后tail指向c
def dequeue(self):
if not self.head:
raise QueueException('Queue is empty)
value = self.head.value
self.head = self.head.next_node
if not self.head:
self.tail = None
#每次从队列中取走一个点,head后移一位,如果head是None,那么tail是None,否则tail的指向不变
return value
def is_empty(self):
return self.head is None
3.1 Queue Exercise
广度优先搜索是先进入的先处理,符合queue的思路。
上图的搜索流程如下,注意压栈的顺序是从右向左:
No. 1 2 3 4 5 6 ...
Queue 1 2 4 5 3 6 ...
4 5 3 6 11 ...
5 3 11 13 ...
13
Operation push1 pop1 pop2 pop4 pop5 pop3 ...
push2 push3 push6
push4 push11
push5 push13