一、Flink安装
1.1 二进制安装
在官网下载页面下载二进制包,下载的压缩包需要和服务器环境中的Hadoop、Scala版本相匹配,然后直接解压。
1.2源码编译
如果对Flink进行功能修改、或者为了支持特定版本的Hadoop,需要对Flink重新编译。在maven 3、jdk 8.0以上环境下编译,建议Maven3.0.x、3.1.x、 3.2.x。
源码下载
git clone https://github.com/apache/flink
hadoop版本
Flink有依赖于HDFS、Yarn,而这又依赖于Hadoop,如果版本号错误,可能程序执行过程会出异常。Flink镜像库中已经编译好的安装包通常对应的是Hadoop的主流版本,如果用户需要指定Hadoop版本编译安装包,可以在编译过程中使用-Dhadoop.version参数指定Hadoop版本,目前Flink支持2.4以上版本的Hadoop。如果用户使用的是供应商提供的Hadoop平台,如Cloudera的CDH等,则需要根据供应商的系统版本来编译Flink,可以指定-Pvendor-repos参数来激活类似于Cloudera的Maven Repositories,会在编译过程中下载依赖对应版本的包。
hadoop version

为了提高build速度,可以用-DskipTests -Dfast跳过tests、QA Plugins、JavsDocs等过程。
mvn clean install -DskipTests -Dfast -Pvendor-repos -Dhadoop.version=2.6.0-cdh5.14.0
cloudera的maven仓库已经在pom文件里配置过了,这样在打包时就能在仓库找到特定版本的jar包:
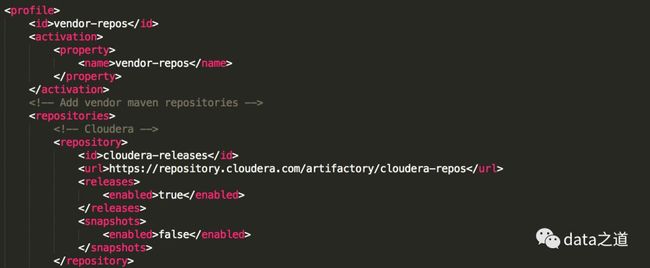
如果想在build flink发布版本里包括Hadoop lib,可以加-Pinclude-hadoop,
scala版本
如果用scala语言的Flink API、lib包,项目中scala版本需要和Flink中scala版本相匹配,因为scala版本不是严格向后兼容的,不同版本差异较大。flink1.8版本支持scala2.11、scala2.12,如果是纯java语言开发,可以忽略这项,默认的是2.11版本,但可以用-Pscala-2.12激活2.12版本:

mvn clean install -DskipTests -Dfast -Pscala-2.12 -Pinclude-hadoop -Pvendor-repos -Dhadoop.version=2.6.0-cdh5.14.0
pom文件里scala2.12版本的配置:

build后的二进制文件目录:
flink/flink-dist/target/flink-1.9-SNAPSHOT-bin/flink-1.9-SNAPSHOT
二、Flink部署
Flink压缩包在集群上解压缩后,可以修改conf/flink-conf.yaml配置flink集群,Flink支持多种部署模式,不同部署模式对应不同配置方式。
2.1 Standalone Cluster
standalone模式下的集群,包括至少一个JobManager、至少一个TaskManager,如果节点异常,master节点和work节点不会自动重启。当worker节点异常时,如果集群有足够可用的solt数,job还可以自动恢复;如果master节点异常,只有master配置了HA,job才能恢复执行。
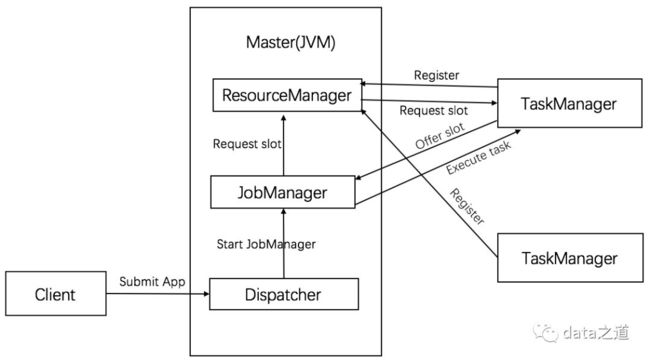
组件交互
配置
conf/flink-conf.yam是Flink集群的配置文件。
1. 系统配置
jobmanager.rpc.address:指定master节点IP地址
jobmanager.rpc.port:指定master端口号
env.java.opts:节点默认的JVM参数
env.java.opts.jobmanager:JM的JVM参数
env.java.opts.taskmanager:TM的JVM参数
2. 内存配置
jobmanager.heap.size:JM节点可分配的最大内存,master主要管理集群资源(RM)、协调应用程序执行(TM),所需资源不是很多;但是如果集群上了跑有很多应用或者一个应用有很多算子,就要考虑增加内存;默认1024m
taskmanager.heap.size:worker节点负责实际任务的执行并处理潜在的大量数据,而且当使用内存或文件格式的状态后端,也会占用JVM堆内存。默认1024m,根据实际应用情况适当调整。
On Yarn模式下,内存大小是被TM的Yarn资源容器自动分配的。
taskmanager.memory.size/taskmanager.memory.fraction:TaskManager为排序、hashtable、中间结果的缓存而分配的内存。taskmanager.memory.size配置绝对值、taskmanager.memory.fraction按照比例分配内存。如果内存不够
taskmanager.memory.off-heap:
3. work节点资源配置
taskmanager.numberOfTaskSlots:work进程可以同时运行的task数,即work节点的并发数。需要注意的是,flink不为每个task或solt指定分配内存,这样一个任务就可能消耗JVM大部分内存,这点在上篇文章里也有特别提到。通常是物理cpu的数量、或是其一半,默认1。
4. 网络配置
TaskManager的网络缓存区用于跨节点的数据交换(task接收、发送事件),是网络交换的关键组件。TaskManager在发送事件之前先把事件收集到缓存区、在接收到数据之后并把数据传递给应用之前缓存到缓冲区。这种方式有效的利用网络资源实现高吞吐。缓存区的总数量和任务之间的网络连接总数相同,比如通过分区或广播连接起来的两个算子,缓存区总数是发送和接收算子的并行度的乘积。网络缓存区在JVM堆外内存分配。
如果没有足够数量的缓存区,可能不能为同时建立的所有网络连接分配缓存区,会降低吞吐量。
taskmanager.network.memory.fraction:该参数配置TaskManager节点为网络缓冲区分配的总内存,默认占JVM堆内存10%
taskmanager.memory.segment-size:配置一个网络堆栈分配的内存大小,默认32k。
减少网络堆栈(一个网络数据交换管道的网络缓冲区)会增加网络缓冲区数量,但有可能降低整体的网络传输效率。
5. 应用并行度
parallelism.default:Flink应用默认并行度,即应用内每个算子的并行度,与整个集群的CPU数量有关,增加parallelism可以提高任务并行的计算的实例数,提升数据处理效率,但也会占用更多Slot。一个算子的并行度有多种配置方式,其优先级是:
配置文件配置的(parallelism.default) < 启动时-p参数指定 < 应用代码设置的并行度(env.setParallelism)<应用代码里为每个算子配的(setParallelism)
6. 磁盘配置
Flink在运行时会把临时数据写到本地文件系统,比如flink接收到的JAR文件、应用程序状态(当用RocksDB存储应用程序状态时),要避免目录里的数据被服务器自动清空,否则job重启时可能因找不到元数据导致恢复失败
io.tmp.dirs :指定默认的本地临时目录
7. checkpoint
state.backend:维护状态数据的状态后端,会影响应用程序的性能。可选的配置项是jobmanager(MemoryStateBackend), filesystem(FsStateBackend), rocksdb(RocksDBStateBackend)
state.backend.async:是否异步checkpoint
state.backend.incremental:是否创建增量checkpoint,增量checkpoint仅存储和之前checkpoint的差异,而不是完整的checkpoint。但不是所有的后端状态都支持异步和增量checkpoint。
state.checkpoints.dir:checkpoint存储数据文件、元数据的默认根目录,这个目录必须能被所有的进程、节点访问到
state.savepoints.dir:savepoint的根目录,用于状态存储写文件时使用(MemoryStateBackend, FsStateBackend, RocksDBStateBackend)
conf/slaves:配置集群中所有的工作节点
启动
在JM节点执行下面命令,完成的工作:本地启动JM、并通过SSH命令启动所有的work节点上的TM,work节点列表配置在slaves文件,要求JM节点可用免密码ssh到TM节点。:
bin/start-cluster.sh
也可以在集群的每个节点上单独执行命令,分别对JM、TM进行启动、停止操作:
bin/jobmanager.sh((start|start-foreground)[host][webui-port])|stop|stop-all
bin/taskmanager.sh start|start-foreground|stop|stop-all
默认JobManager配置Rest绑定的配置项rest.port(默认值8081),集群的JM、TM启动后,可以在JM的web页面上看到相关信息:
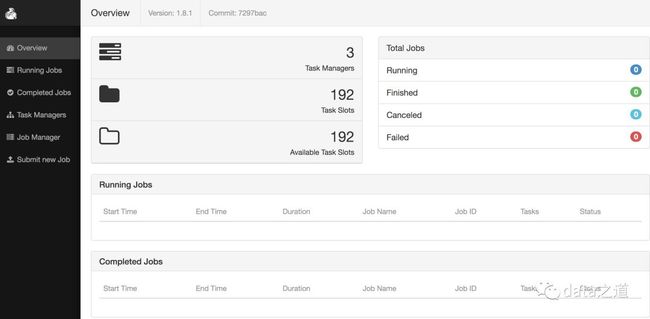
Run Example
执行内置的demo:
./flink run ../examples/batch/WordCount.jar
-m 指定DispatcherRestEndpoint的ip和端口,即master节点的WEB UI
这些默认配置项会在集群启动的时候加载到Flink集群中,当用户提交任务时,可以通过-D符号来动态设定系统参数,此时flink-conf.yaml配置文件中的参数就会被覆盖掉
2.2 on Yarn
yarn是Hadoop上的一个资源管理组件,管理集群上的计算资源,比如集群的CPU、内存,并把资源封装成container分配给应用。Flink在Yarn上两种运行模式:job模式、session模式,job模式是以单个job的方式启动Flink集群,一旦作业执行完毕,Flink集群就停止并释放所有资源;session模式在Yarn上启动一个长期运行的Flink集群,可以执行多个Job,但要手动管理集群的停止。不论是哪种on Yarn模式,当Flink TaskManager失败后,任务都会被自动转移到其他TM。
Yarn主要由ResourceManager、ApplicationMaster、NodeManager组成,RM是一个全局的资源管理器,负责整个系统的资源管理和分配;每个往Yarn上提交的应用程序都包含一个AM,主要是向RM请求资源,将获得的资源进一步分配给内部的任务,监控所有任务的运行状态并在任务失败时重新申请资源以重启任务;NM定时向RM汇报本节点上资源利用情况,接收并处理来自AM的任务启动、停止等各种请求;资源分配的单位被抽象成container。
环境前置条件:设置HADOOP_CLASSPATH环境变量,Flink依赖于hadoop lib,启动Flink组件(如Client、JM、TM),如果flink发布包里已经打包了hadoop lib,可不用再配置该变量;设置YARN_CONF_DIR或者HADOOP_CONF_DIR环境变量,以便可以读取yarn和hdfs的配置,如果启动的节点没有相应的配置文件,Flink在启动过程中无法正常连接到Yarn集群。需要注意的是,如果只是把hadoop相关配置文件(core-site.xml、yarn-site.xml等)放到flink配置文件目录下,是不起作用的。
配置
yarn.appmaster.vcores:Yarn ApplicationMaster分配的虚拟内核(vcores),默认1.
yarn.containers.vcores:Yarn containers分配的虚拟内核,默认情况下,虚拟内核数和TaskManager配置的slots数相同,默认是1.
2.2.1 Session Mode
当启动yarn session时,Yarn会为ApplicationMaster分配一个container,这个ApplicationMaster运行Flink JobManager;用户提交任务后,yarn session会向yarn申请资源container、启动Flink所有必须服务,比如JM、TM,即客户端直接向yarn session请求,而不是向Yarn进行交互,session会自动分配container,用于运行Task Manager(一个TM占用一个container)。Flink Session是长期运行的服务,可以同时运行多个flink 应用。
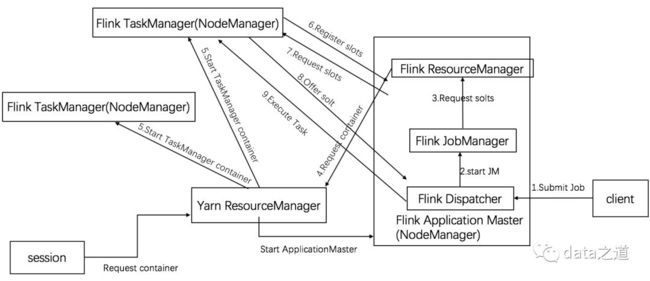
Start
./bin/yarn-session.sh-jm1024m-tm4096m
-jm:JobManager(Yarn Application Master)申请1G内存资源、-tm:TM分配4G内存
当session运行后,可在yarn管理界面上监控到,点击ApplicationMaster会打开JobManager页面:

-d参数:当Flink Yarn客户的把flink提交到yarn集群后,就自动停止。
停止Yarn session可以用yarn的命令行:yarn application -kill
Yarn session提交以后,就可以用flink命令提交job到集群。
Submit Job
提交程序到yarn集群上:
./flink run ../examples/batch/WordCount.jar --input hdfs:///xxxx --output hdfs:///xxx
可选参数:-yid :指定Flink yarn-session的Application ID
job提交后,因为并没有启动新的Yarn Application Maser,所以在在Yarn ResourceManager Web上监控不到,可以在Flink Web UI上看到。
2.2.2 Job Mode
Flink任务直接以单个应用提交到yarn上,每次提交的Flink任务都会启动独立的Yarn Aplication,每个任务都会有自己的JM、TM,所有的资源都独立使用。启动作业提交大致过程:客户端向Yarn RM提交应用,Yarn RM为该应用申请一定数量的container(container数是可配置的),并在相应的NM上启动应用程序的AM。每次提交任务时都会在Yarn上跑一个完整的Flink集群,这样任务之间相互独立、互不影响,任务跑完后创建的集群也随之关闭。
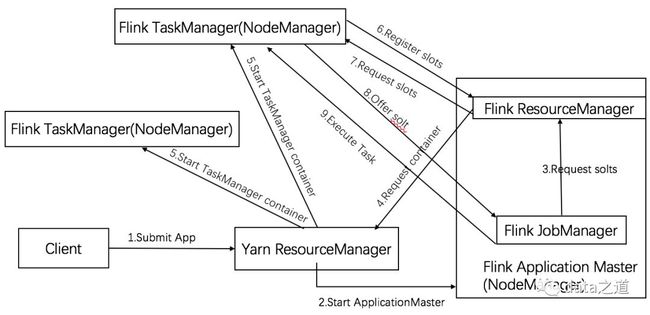
Submit Job
./bin/flink run-myarn-cluster ./examples/batch/WordCount.jar
在Yarn ResourceManager Web页面上,能看到启动了一个Flink类型的Application Master,当任务执行完成后,该Application Master也自动停止。
其他可选参数:
-yqu 指定Yarn资源队列
-yjm Flink Master(Yarn ApplicationMaster)分配一个资源container,-yjm指定该资源拥有的内存,怎么配置申请的资源虚拟内存?
-ytm 指定为每个Flink TaskManager分配的内存,即为每个TaskManager申请到的资源container内存
-ys 配置每个TaskManager上的solt数,默认一个solt占用一个虚拟内核。
-yn:任务启动的TM数。
-p 设置job的全局并行度,即使用Flink多少solt,默认并行度1