首个为AI设置的“IQ测试”:玩游戏、解魔方、考SAT全面评估
作者:牛婉杨
自从计算机问世,人们对于机器便开始了永无止境的探索,如何让机器更聪明。
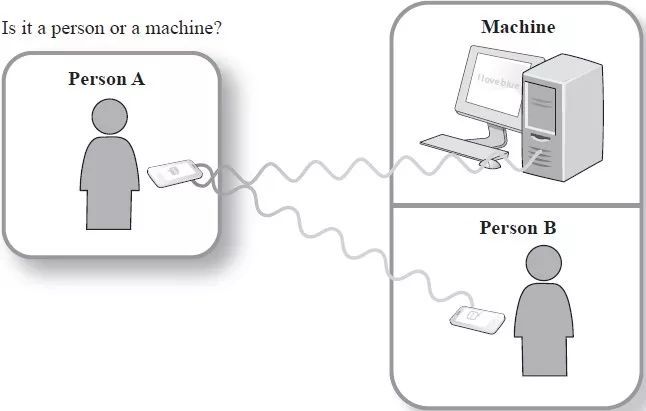
那么怎么判断机器的“聪明程度”呢?最经典的方法当然是“图灵测试”。
早在 1950 年,图灵发表了一篇划时代的论文,他表示机器也可以拥有智能,像人一样会“思考”,并且提出了图灵测试:测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。进行多次测试后,如果机器让平均每个参与者做出超过 30% 的误判,那么这台机器就通过了测试,并被认为具有人类智能。
2015 年 11 月,《Science》杂志封面刊登了一篇重磅研究:人工智能终于能像人类一样学习,并通过了图灵测试。这个系统能够迅速学会写陌生的文字,同时还能识别出非本质特征(也就是那些因书写造成的轻微变异),通过了图灵测试,这也是人工智能领域的一大进步。
因为易于理解又简单可控,这一测试方法自诞生起,一直被看作测试人工智能是否智能的重要方式。但是随着 AI 系统的快速发展,其复杂性正在迅速上升,而这些年,各种新的人工智能“智能”测试方法正层出不穷的涌现。
近期,华盛顿州立大学电子工程与计算机科学学院的教授 Larry Holder 表示,“以前,测量 AI 系统智能与否的研究大多是理论性的,没有在未知的新环境中测试 AI 系统的实际性能,也没有考虑到任务的复杂性。”

Larry Holder
Holder 和他的团队正在为 AI 系统创建首个“IQ 测试”,以了解它们学习和适应新环境的能力,测试根据 AI 系统所能解决问题的难度对其进行评分,评分还将考虑系统的准确性、耗时以及所需的数据量。该研究的主要内容之一就是创建对问题难度进行排名的方法。
Holder 表示,“我们专注于测试和改进那些更具通用性的系统,比如可以帮助你完成许多日常任务的机器人助手。”
研究人员主要关注的是,他们测试的 AI 系统能否很好地将它们从一个任务中学到的知识应用到另一个全新的,未知的任务上。例如,你可能想在下象棋之前先学习跳棋,因为可以很容易地把跳棋的知识转移到象棋。
一名与 Holder 一起做暑期研究的本科生帮助他设计了一个评估环境,用于测试 AI 系统需要完成的任务,比如玩视频游戏、解答 SAT 考试的相关问题和解魔方。

可根据 AI 系统学习和玩新的视频游戏(例如 Vizdoom)的能力来评估 AI 系统
Holder 目前在维护一个 AI 系统可以进行“IQ 测试”和排行的网站。他希望大家都可以使用它来测试自己的 AI 系统,同时在这个过程中为研究人员提供更多的数据。
要想测试,需要先创建一个 AIQ 帐户,然后在 AIQ 的后端提交分数。AIQ 是一个开源测试框架,用于评估 AI 系统的“智商”。有关运行 AIQ 框架的详细教程及代码都在 Github 上,感兴趣的同学可以上手测一下~

AIQ 网站地址:https://portal.eecs.wsu.edu/aiq/
研究人员希望利用这一框架,为人工智能评估提供一个开放的度量标准。另外,他们还将利用这一框架来确定人工智能领域的发展情况,以及在实现通用智能方面是否取得了进展。

Github 教程:
https://github.com/Christopher-P/AIQ#tutorial
一、DeepMind 曾为 AI 定制一套 IQ 测试题
Holder 教授不是第一个想突破图灵测试、为 AI 测智商的人。去年,DeepMind 就动过为 AI 测智商的念头~ 先来看下面这张图,有没有熟悉的感觉!这种图形推理题,考过公务员的同学一定都不陌生~它能够用来考察我们的观察与逻辑推理能力,也是 IQ 测试题的一种。

去年,DeepMind 发表了一篇论文,想要用这些推理题来测试神经网络的抽象推理能力。 论文链接:http://proceedings.mlr.press/v80/santoro18a/santoro18a.pdf 研究人员将抽象推理定义为在概念层次上检测模型和解决问题的能力,因此他们构建了一个涉及一系列抽象因素的题目生成器,以此来测试和训练机器学习。

在测试中,大多数模型都表现良好。研究人员发现,模型准确性与推断任务底层抽象概念的能力密切相关。“有些模型学会了解决复杂的视觉推理问题,”该团队写道,“为此,他们需要从原始像素输入中引入并检测抽象概念的存在,并将这些原则应用于从未观察到的刺激。“
对于我们来说,考试前大家往往都会大量“刷题”,所以如果受试者准备太多,这样的测试也可能无效,因为我们学到了特定于测试的启发式方法,从而缩短了对推理的需求。研究人员也表示, “这对神经网络而言可能更严重,因为它们具有惊人的记忆能力。”
最终的研究结果表明,想得出关于泛化的普遍结论可能是无益的:研究人员测试的神经网络在某些泛化方案中表现良好,而在其他方面表现很差。该团队在一篇博客文章中写道,“它们的成功是由一系列因素决定的,包括所用模型的架构以及该模型是否经过培训等等。”
虽然实验结果可能是一个“大杂烩”,但研究人员还没有放弃,他们计划改进泛化策略,并探索在未来的模型中使用“结构丰富,但普遍适用”的归纳偏差。
二、AI 研究之路艰辛漫长,“IQ 测试”或许来的有点早
创造能够在新环境中自主学习和行动的智能机器,仍然是人工智能研究者们追求的方向,也是目前所面临的挑战。
Holder 和他的团队建立这样一个测试系统,旨在测试和改进那些更具通用性的系统,比如可以完成许多日常任务的机器人助手。这是一个很好的研究方向,但实际上,要想实现“通用人工智能”,还有很长一段路要走。
现在的人工智能技术,虽然在一些特定的领域以及实际应用上具备超人的能力了,但是它还需要大量的数据来进行训练。这种人工智能也被称为面向特定任务的“窄人工智能”,例如人脸检测、语音识别。 未来希望能够达到“通用人工智能”,即具备人一样的智能,能够不断的自主学习,在更广的范围内提升整个机器的智能。
 IBM 副总裁、IBM 大中华区首席技术官谢东曾在演讲中表示,“通用人工智能可能还需要一段时间才能实现,我们经常说可能是 2050 年以后吧。”(划重点:可能)
IBM 副总裁、IBM 大中华区首席技术官谢东曾在演讲中表示,“通用人工智能可能还需要一段时间才能实现,我们经常说可能是 2050 年以后吧。”(划重点:可能)
那么现在,研究人员们正在努力把“窄人工智能”变成“宽人工智能”,所谓宽是什么?在学习的基础上加入一些推理的能力,这样就可以支持多任务、多领域、多模态的学习。
美国哥伦比亚大学创意机器实验室总监、工程学教授 Hod Lipson 与团队研究出一款可以自我学习的机器人。它只有一个“手臂”,不像我们拥有眼睛可以看到自己,研究人员也没有告诉它它是什么,而是让它自己去感受,在自我想象中学习。
一开始它像婴儿般疯狂的甩着手臂,在感知自己的形态,感知这个世界。过了大概一天,它就可以开始做一些简单的任务了。
这样简单的任务完全可以通过编程让它达到,但是这个机器人在它自己的模拟中学会了这项任务,这是人类迈向建造具备自我学习能力的机器人的重要一步。
最后不得不说,在人工智能不断发展的同时,我们必须要确保是“可信的人工智能”,因为要把人工智能进行大规模应用的话,一定要保证它是可信的。
相关报道:https://news.wsu.edu/2019/12/12/iq-test-artificial-intelligence-systems/