with子句最有用的特性之一就是消除复杂的sql查询,当查询中包含大量的表和数据列时,想要搞清楚查询中的数据流就变得很困难。使用子查询因子化,只要一个个查询就可以将一些较复杂的部分移到主查询之外,从而使得查询更易于理解。
下面使用pivot运算符生成一个交叉数据分析报告。最里层的查询在sales表的关键列上创建了一系列的聚合,而接下来的最外层查询只是提供了在pivot运算符中出现的列的列名,从而生成了每种产品不同渠道和季度的最终销售值。
--没有进行子查询因子化的交叉数据分析查询
SELECT *
FROM (
SELECT /*+ gather_plan_statistics */
product,channel,quarter,country,quantity_sold
FROM (
SELECT pr.prod_name product,co.country_name country,sa.channel_id channel, Substr(t.calendar_quarter_desc,6,2) quarter,
SUM(sa.amount_sold) amount_sold,
SUM(sa.quantity_sold) quantity_sold
FROM sh.sales sa
JOIN sh.times t ON t.time_id=sa.time_id
JOIN sh.customers cu ON cu.cust_id=sa.cust_id
JOIN sh.countries co ON co.country_id=cu.country_id
JOIN sh.products pr ON pr.prod_id=sa.prod_id
GROUP BY
pr.prod_name,co.country_name,sa.channel_id,Substr(t.calendar_quarter_desc,6,2)
)
) PIVOT (
SUM(quantity_sold) FOR (channel,quarter) IN
(
(5,'02') AS catolog_q2,
(4,'01') AS internet_q1,
(4,'04') AS internet_q4,
(2,'02') AS partners_q2,
(9,'03') AS tele_q3
)
)
ORDER BY product,country;
使用with子句将这个查询分解为易于理解的字节级大小的块。使用with子句建立3个因子化子查询来进行了重写,分别命名为sales_countries、top_sales 、sales_rpt 子查询。sales_countries指的是销售所发生的国家,top_sales收集销售数据,而sales_rpt子查询对这些数据进行聚合。
--进行子查询因子化的交叉表
WITH sales_countries AS (
SELECT /*+ gather_plan_statistics */
cu.cust_id,co.country_name
FROM sh.countries co, sh.customers cu
WHERE cu.country_id=co.country_id
),
top_sales AS
(
SELECT p.prod_name,sc.country_name,sa.channel_id,
t.calendar_quarter_desc,sa.amount_sold,sa.quantity_sold
FROM sh.sales sa
JOIN sh.times t ON t.time_id=sa.time_id
JOIN sh.customers c ON c.cust_id = sa.cust_id
JOIN sales_countries sc ON sc.cust_id = c.cust_id
JOIN sh.products p ON p.prod_id = sa.prod_id
),
sales_rpt AS
(
SELECT ts.prod_name product,
ts.country_name country,
ts.channel_id channel,
SUBSTR(ts.calendar_quarter_desc,6,2) quarter,
SUM(amount_sold) amount_sold,
SUM(quantity_sold) quantity_sold
FROM top_sales ts
GROUP BY ts.prod_name,
ts.country_name,
ts.channel_id,
SUBSTR(ts.calendar_quarter_desc,6,2)
)
SELECT * FROM
(
SELECT product, channel,quarter,country,quantity_sold
FROM sales_rpt
) PIVOT (
SUM(quantity_sold)
FOR (channel,quarter) IN
(
(5,'02') AS catalog_q2,
(4,'01') AS internet_q1,
(4,'04') AS internet_q4,
(2,'02') AS partners_q2,
(9,'03') AS tele_q3
)
)
ORDER BY product,country;
用with定义PL/SQL函数
Oracle 12c中引入了一种特性,可以使用with子句声明并定义pl/sql函数和存储过程。在定义之后,可以在声明这个子句的查询中引用该pl/sql函数。
WITH
FUNCTION calc_markup(p_markup NUMBER,p_price NUMBER) RETURN NUMBER
IS
BEGIN
RETURN p_markup*p_price;
END;
SELECT t.prod_name,
t.prod_list_price cur_price,
calc_markup(.05,t.prod_list_price) mup5,
ROUND(t.prod_list_price+calc_markup(0.10,t.prod_list_price),2) new_price
FROM sh.products t;
/
SELECT prod_name,cur_price,mup5,new_price
FROM (
WITH
FUNCTION calc_markup(p_markup NUMBER,p_price NUMBER) RETURN NUMBER
IS
BEGIN
RETURN p_markup*p_price;
END;
SELECT t.prod_name,
t.prod_list_price cur_price,
calc_markup(.05,t.prod_list_price) mup5,
ROUND(t.prod_list_price+calc_markup(0.10,t.prod_list_price),2) new_price
FROM sh.products t
) WHERE cur_price<1000
AND new_price>1000;
SELECT /*+ WITH_PLSQL */ prod_name,cur_price,mup5,new_price
FROM (
WITH
FUNCTION calc_markup(p_markup NUMBER,p_price NUMBER) RETURN NUMBER
IS
BEGIN
RETURN p_markup*p_price;
END;
SELECT t.prod_name,
t.prod_list_price cur_price,
calc_markup(.05,t.prod_list_price) mup5,
ROUND(t.prod_list_price+calc_markup(0.10,t.prod_list_price),2) new_price
FROM sh.products t
) WHERE cur_price<1000
AND new_price>1000;
/
必须使用斜线/运行这个语名,类似执行一个匿名的PL/SQL块。
SQL优化
当一个SQL查询被设计或修改以利用子查询因子化时,在优化器为查询建立执行计划时,可能将因子化的子查询作为临时表来处理。
sqlplus scott/scott@orcl
命令行登陆语法
sqlplus username/password@servername as sysdba
set autotrace on显示计划信息和查询的数据
set autotrace traceonly只显示计划信息
SQL> set autotrace traceonly
SQL> --with和materialize
SQL> WITH cust AS (
2 SELECT /*+ materialize gather_plan_statistics */
3 t.cust_income_level,
4 a.country_name
5 FROM sh.customers t
6 JOIN sh.countries a ON a.country_id=t.country_id
7 )
8 SELECT c.country_name,cust_income_level,COUNT(c.country_name) country_cust_count
9 FROM cust c
10 HAVING COUNT(country_name) >
11 (
12 SELECT COUNT(*) * .01 FROM cust c2
13 )
14 OR COUNT(cust_income_level) >
15 (
16 SELECT MEDIAN(income_income_count)
17 FROM (
18 SELECT cust_income_level,COUNT(*)* .25 income_income_count
19 FROM cust
20 GROUP BY cust_income_level
21 )
22 )
23 GROUP BY country_name,cust_income_level
24 ORDER BY 1,2;
已选择35行。
执行计划
----------------------------------------------------------
Plan hash value: 3455850065
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20 | 620 | 499 (2)| 00:00:06 |
| 1 | TEMP TABLE TRANSFORMATION | | | | | |
| 2 | LOAD AS SELECT | | | | | |
|* 3 | HASH JOIN | | 55500 | 2222K| 410 (1)| 00:00:05 |
| 4 | TABLE ACCESS FULL | COUNTRIES | 23 | 345 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 1409K| 406 (1)| 00:00:05 |
|* 6 | FILTER | | | | | |
| 7 | SORT GROUP BY | | 20 | 620 | 89 (5)| 00:00:02 |
| 8 | VIEW | | 55500 | 1680K| 86 (2)| 00:00:02 |
| 9 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6607_61C9C4 | 55500 | 1680K| 86 (2)| 00:00:02 |
| 10 | SORT AGGREGATE | | 1 | | | |
| 11 | VIEW | | 55500 | | 86 (2)| 00:00:02 |
| 12 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6607_61C9C4 | 55500 | 1680K| 86 (2)| 00:00:02 |
| 13 | SORT GROUP BY | | 1 | 13 | | |
| 14 | VIEW | | 12 | 156 | 89 (5)| 00:00:02 |
| 15 | SORT GROUP BY | | 12 | 252 | 89 (5)| 00:00:02 |
| 16 | VIEW | | 55500 | 1138K| 86 (2)| 00:00:02 |
| 17 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6607_61C9C4 | 55500 | 1680K| 86 (2)| 00:00:02 |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("A"."COUNTRY_ID"="T"."COUNTRY_ID")
6 - filter(COUNT("COUNTRY_NAME")> (SELECT COUNT(*)*.01 FROM (SELECT /*+ CACHE_TEMP_TABLE
("T1") */ "C0" "CUST_INCOME_LEVEL","C1" "COUNTRY_NAME" FROM "SYS"."SYS_TEMP_0FD9D6607_61C9C4"
"T1") "C2") OR COUNT("CUST_INCOME_LEVEL")> (SELECT PERCENTILE_CONT(0.500000) WITHIN GROUP (
ORDER BY "INCOME_INCOME_COUNT") FROM (SELECT "CUST_INCOME_LEVEL"
"CUST_INCOME_LEVEL",COUNT(*)*.25 "INCOME_INCOME_COUNT" FROM (SELECT /*+ CACHE_TEMP_TABLE
("T1") */ "C0" "CUST_INCOME_LEVEL","C1" "COUNTRY_NAME" FROM "SYS"."SYS_TEMP_0FD9D6607_61C9C4"
"T1") "CUST" GROUP BY "CUST_INCOME_LEVEL") "from$_subquery$_006"))
统计信息
----------------------------------------------------------
4 recursive calls
314 db block gets
2382 consistent gets
303 physical reads
600 redo size
1916 bytes sent via SQL*Net to client
438 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
35 rows processed
需要测试才能得到最优查询性能可以通过一个管理层需要的报表说明。这个报告必须按照照国家和收入水平显示消费者的分布情况,并且只显示那些占总消费比例等于或超过1%的国家和收入水平的数据。如果某个收入水平范围的消费者数目等于或超过该收入水平范围的总消费者数的25%,这样的国家和收入水平也需要被收入到报告中。前一个查询中因子化的子查询cust被保留了下来,新的内容是having子句中的子查询,这是用来保证执行报告所规定的规则的。
执行这个sql语句时,所有一切都像你预想的那样。然后检查执行计划发现customers和countries表的联结经过了一个临时表转换(TEMP TABLE TRANSFORMATION ),接下来的查询都会用到这个临时表sys_temp_of。到止前为止,如果怀疑所选择的执行计划是不是合理,可以使用materialized和inline提示测试。
SQL> --with和inline
SQL> WITH cust AS (
2 SELECT /*+ inline gather_plan_statistics */
3 t.cust_income_level,
4 a.country_name
5 FROM sh.customers t
6 JOIN sh.countries a ON a.country_id=t.country_id
7 )
8 SELECT c.country_name,cust_income_level,COUNT(c.country_name) country_cust_count
9 FROM cust c
10 HAVING COUNT(country_name) >
11 (
12 SELECT COUNT(*) * .01 FROM cust c2
13 )
14 OR COUNT(cust_income_level) >
15 (
16 SELECT MEDIAN(income_income_count)
17 FROM (
18 SELECT cust_income_level,COUNT(*)* .25 income_income_count
19 FROM cust
20 GROUP BY cust_income_level
21 )
22 )
23 GROUP BY country_name,cust_income_level
24 ORDER BY 1,2;
已选择35行。
执行计划
----------------------------------------------------------
Plan hash value: 1412345716
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Tim
e |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20 | 820 | 413 (2)| 00:00:05 |
|* 1 | FILTER | | | | | |
| 2 | SORT GROUP BY | | 20 | 820 | 413 (2)| 00:00:05 |
|* 3 | HASH JOIN | | 55500 | 2222K| 410 (1)| 00:00:05 |
| 4 | TABLE ACCESS FULL | COUNTRIES | 23 | 345 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 1409K| 406 (1)| 00:00:05 |
| 6 | SORT AGGREGATE | | 1 | 10 | | |
|* 7 | HASH JOIN | | 55500 | 541K| 408 (1)| 00:00:05 |
| 8 | INDEX FULL SCAN | COUNTRIES_PK | 23 | 115 | 1 (0)| 00:00:01 |
| 9 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 270K| 406 (1)| 00:00:05 |
| 10 | SORT GROUP BY | | 1 | 13 | | |
| 11 | VIEW | | 12 | 156 | 411 (2)| 00:00:05 |
| 12 | SORT GROUP BY | | 12 | 372 | 411 (2)| 00:00:05 |
|* 13 | HASH JOIN | | 55500 | 1680K| 408 (1)| 00:00:05 |
| 14 | INDEX FULL SCAN | COUNTRIES_PK | 23 | 115 | 1 (0)| 00:00:01 |
| 15 | TABLE ACCESS FULL| CUSTOMERS | 55500 | 1409K| 406 (1)| 00:00:05 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(COUNT(*)> (SELECT COUNT(*)*.01 FROM "SH"."COUNTRIES"
"A","SH"."CUSTOMERS" "T" WHERE "A"."COUNTRY_ID"="T"."COUNTRY_ID") OR
COUNT("T"."CUST_INCOME_LEVEL")> (SELECT PERCENTILE_CONT(0.500000)WITHIN GROUP
( ORDER BY "INCOME_INCOME_COUNT") FROM (SELECT "T"."CUST_INCOME_LEVEL"
"CUST_INCOME_LEVEL",COUNT(*)*.25 "INCOME_INCOME_COUNT" FROM "SH"."COUNTRIES"
"A","SH"."CUSTOMERS" "T" WHERE "A"."COUNTRY_ID"="T"."COUNTRY_ID" GROUP BY
"T"."CUST_INCOME_LEVEL") "from$_subquery$_006"))
3 - access("A"."COUNTRY_ID"="T"."COUNTRY_ID")
7 - access("A"."COUNTRY_ID"="T"."COUNTRY_ID")
13 - access("A"."COUNTRY_ID"="T"."COUNTRY_ID")
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
4382 consistent gets
1 physical reads
0 redo size
1916 bytes sent via SQL*Net to client
438 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
35 rows processed
从执行计划中可以看出,对customers表进行了3次全扫描,对COUNTRIES进行了一次全扫描。两次执行cust子查询的只需要COUNTRIES_PK索引中的信息,因此对索引而不是表进行了1次全扫描,节省了少量的时间和资源。
清除共享池
alter system flush shared_pool;
清除缓冲区
alter system flush buffer_cache;
测试查询改变的影响
在前面,报告中需要的是任何国家一定收入层次的人员等于或超过该收入层次所有人员的25%。如果被要求如果某个收入层次的数目大于该收入层次总消费数的中间值,则将该收入层次也包括到报告中。
修改后的查询收入inline
SQL> WITH cust AS
2 (SELECT /*+ inline gather_plan_statistics */ --查询国家的收入等级及对应国家
3 t.cust_income_level, a.country_name
4 FROM sh.customers t
5 JOIN sh.countries a
6 ON a.country_id = t.country_id
7 ),
8 median_income_set AS
9 (SELECT /*+ inline */
10 cust_income_level, COUNT(*) income_level_count --某个收入层次的数目大于该收入层次的中间数
11 FROM cust
12 GROUP BY cust_income_level
13 HAVING COUNT(cust_income_level) > (SELECT MEDIAN(income_level_count) income_level_count
14 FROM (SELECT cust_income_level,
15 COUNT(*) income_level_count
16 FROM cust
17 GROUP BY cust_income_level)))
18 SELECT country_name,
19 cust_income_level,
20 COUNT(country_name) country_cust_count
21 FROM cust c
22 HAVING COUNT (country_name) > (SELECT COUNT(*) * .01 FROM cust c2) OR cust_income_level IN (SELECT mis.cust_income_level
23 FROM median_income_set mis)
24 GROUP BY country_name, cust_income_level;
已选择123行。
执行计划
----------------------------------------------------------
Plan hash value: 1635819209
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20 | 820 | 413 (2)| 00:00:05 |
|* 1 | FILTER | | | | | |
| 2 | HASH GROUP BY | | 20 | 820 | 413 (2)| 00:00:05 |
|* 3 | HASH JOIN | | 55500 | 2222K| 410 (1)| 00:00:05 |
| 4 | TABLE ACCESS FULL | COUNTRIES | 23 | 345 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 1409K| 406 (1)| 00:00:05 |
| 6 | SORT AGGREGATE | | 1 | 10 | | |
|* 7 | HASH JOIN | | 55500 | 541K| 408 (1)| 00:00:05 |
| 8 | INDEX FULL SCAN | COUNTRIES_PK | 23 | 115 | 1 (0)| 00:00:01 |
| 9 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 270K| 406 (1)| 00:00:05 |
|* 10 | FILTER | | | | | |
| 11 | HASH GROUP BY | | 1 | 31 | 411 (2)| 00:00:05 |
|* 12 | HASH JOIN | | 55500 | 1680K| 408 (1)| 00:00:05 |
| 13 | INDEX FULL SCAN | COUNTRIES_PK | 23 | 115 | 1 (0)| 00:00:01 |
| 14 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 1409K| 406 (1)| 00:00:05 |
| 15 | SORT GROUP BY | | 1 | 13 | | |
| 16 | VIEW | | 12 | 156 | 411 (2)| 00:00:05 |
| 17 | SORT GROUP BY | | 12 | 372 | 411 (2)| 00:00:05 |
|* 18 | HASH JOIN | | 55500 | 1680K| 408 (1)| 00:00:05 |
| 19 | INDEX FULL SCAN | COUNTRIES_PK | 23 | 115 | 1 (0)| 00:00:01 |
| 20 | TABLE ACCESS FULL| CUSTOMERS | 55500 | 1409K| 406 (1)| 00:00:05 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(COUNT(*)> (SELECT COUNT(*)*.01 FROM "SH"."COUNTRIES"
"A","SH"."CUSTOMERS" "T" WHERE "A"."COUNTRY_ID"="T"."COUNTRY_ID") OR EXISTS
(SELECT 0 FROM "SH"."COUNTRIES" "A","SH"."CUSTOMERS" "T" WHERE
"A"."COUNTRY_ID"="T"."COUNTRY_ID" GROUP BY "T"."CUST_INCOME_LEVEL" HAVING
"T"."CUST_INCOME_LEVEL"=:B1 AND COUNT("T"."CUST_INCOME_LEVEL")> (SELECT
PERCENTILE_CONT(0.500000) WITHIN GROUP ( ORDER BY "INCOME_LEVEL_COUNT") FROM
(SELECT "T"."CUST_INCOME_LEVEL" "CUST_INCOME_LEVEL",COUNT(*)
"INCOME_LEVEL_COUNT" FROM "SH"."COUNTRIES" "A","SH"."CUSTOMERS" "T" WHERE
"A"."COUNTRY_ID"="T"."COUNTRY_ID" GROUP BY "T"."CUST_INCOME_LEVEL")
"from$_subquery$_005")))
3 - access("A"."COUNTRY_ID"="T"."COUNTRY_ID")
7 - access("A"."COUNTRY_ID"="T"."COUNTRY_ID")
10 - filter("T"."CUST_INCOME_LEVEL"=:B1 AND COUNT("T"."CUST_INCOME_LEVEL")>
(SELECT PERCENTILE_CONT(0.500000) WITHIN GROUP ( ORDER BY "INCOME_LEVEL_COUNT")
FROM (SELECT "T"."CUST_INCOME_LEVEL" "CUST_INCOME_LEVEL",COUNT(*)
"INCOME_LEVEL_COUNT" FROM "SH"."COUNTRIES" "A","SH"."CUSTOMERS" "T" WHERE
"A"."COUNTRY_ID"="T"."COUNTRY_ID" GROUP BY "T"."CUST_INCOME_LEVEL")
"from$_subquery$_005"))
12 - access("A"."COUNTRY_ID"="T"."COUNTRY_ID")
18 - access("A"."COUNTRY_ID"="T"."COUNTRY_ID")
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
23362 consistent gets
0 physical reads
0 redo size
5460 bytes sent via SQL*Net to client
504 bytes received via SQL*Net from client
10 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
123 rows processed
SQL>
修改后的查询收入materialize
增加了1次全表扫描和索引扫描,下面是允许临时表转换查询的性能输出:
SQL> WITH cust AS
2 (SELECT /*+ materialize gather_plan_statistics */ --查询国家的收入等级及对应国家
3 t.cust_income_level, a.country_name
4 FROM sh.customers t
5 JOIN sh.countries a
6 ON a.country_id = t.country_id
7 ),
8 median_income_set AS
9 (SELECT /*+ inline */
10 cust_income_level, COUNT(*) income_level_count --某个收入层次的数目大于该收入层次的中间数
11 FROM cust
12 GROUP BY cust_income_level
13 HAVING COUNT(cust_income_level) > (SELECT MEDIAN(income_level_count) income_level_count
14 FROM (SELECT cust_income_level,
15 COUNT(*) income_level_count
16 FROM cust
17 GROUP BY cust_income_level)))
18 SELECT country_name,
19 cust_income_level,
20 COUNT(country_name) country_cust_count
21 FROM cust c
22 HAVING COUNT (country_name) > (SELECT COUNT(*) * .01 FROM cust c2) OR cust_income_level IN (SELECT mis.cust_income_level
23 FROM median_income_set mis)
24 GROUP BY country_name, cust_income_level;
已选择123行。
执行计划
----------------------------------------------------------
Plan hash value: 2452612
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |
Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20 | 620 | 499 (2)| 00:00:06 |
| 1 | TEMP TABLE TRANSFORMATION | | | | | |
| 2 | LOAD AS SELECT | | | | | |
|* 3 | HASH JOIN | | 55500 | 2222K| 410 (1)| 00:00:05 |
| 4 | TABLE ACCESS FULL | COUNTRIES | 23 | 345 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | CUSTOMERS | 55500 | 1409K| 406 (1)| 00:00:05 |
|* 6 | FILTER | | | | | |
| 7 | HASH GROUP BY | | 20 | 620 | 89 (5)| 00:00:02 |
| 8 | VIEW | | 55500 | 1680K| 86 (2)| 00:00:02 |
| 9 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6607_644975 | 55500 | 1680K| 86 (2)| 00:00:02 |
| 10 | SORT AGGREGATE | | 1 | | | |
| 11 | VIEW | | 55500 | | 86 (2)| 00:00:02 |
| 12 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6607_644975 | 55500 | 1680K| 86 (2)| 00:00:02 |
|* 13 | FILTER | | | | | |
| 14 | HASH GROUP BY | | 1 | 21 | 89 (5)| 00:00:02 |
| 15 | VIEW | | 55500 | 1138K| 86 (2)| 00:00:02 |
| 16 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6607_644975 | 55500 | 1680K| 86 (2)| 00:00:02 |
| 17 | SORT GROUP BY | | 1 | 13 | | |
| 18 | VIEW | | 12 | 156 | 89 (5)| 00:00:02 |
| 19 | SORT GROUP BY | | 12 | 252 | 89 (5)| 00:00:02 |
| 20 | VIEW | | 55500 | 1138K| 86 (2)| 00:00:02 |
| 21 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6607_644975 | 55500 | 1680K| 86 (2)| 00:00:02 |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("A"."COUNTRY_ID"="T"."COUNTRY_ID")
6 - filter(COUNT("COUNTRY_NAME")> (SELECT COUNT(*)*.01 FROM (SELECT /*+ CACH E_TEMP_TABLE
("T1") */ "C0" "CUST_INCOME_LEVEL","C1" "COUNTRY_NAME" FROM "SYS"."SYS_TEMP_0FD9D6607_644975"
"T1") "C2") OR EXISTS (SELECT 0 FROM (SELECT /*+ CACHE_TEMP_TABLE ("T1") */ "C0"
"CUST_INCOME_LEVEL","C1" "COUNTRY_NAME" FROM "SYS"."SYS_TEMP_0FD9D6607_644975" "T1") "CUST"
GROUP BY "CUST_INCOME_LEVEL" HAVING "CUST_INCOME_LEVEL"=:B1 AND COUNT("CUST_INCOME_LEVEL")>
(SELECT PERCENTILE_CONT(0.500000) WITHIN GROUP ( ORDER BY "INCOME_LEVEL_COUNT") FROM (SELECT
"CUST_INCOME_LEVEL" "CUST_INCOME_LEVEL",COUNT(*) "INCOME_LEVEL_COUNT" FROM (SELECT /*+
CACHE_TEMP_TABLE ("T1") */ "C0" "CUST_INCOME_LEVEL","C1" "COUNTRY_NAME" FROM
"SYS"."SYS_TEMP_0FD9D6607_644975" "T1") "CUST" GROUP BY "CUST_INCOME_LEVEL")
"from$_subquery$_005")))
13 - filter("CUST_INCOME_LEVEL"=:B1 AND COUNT("CUST_INCOME_LEVEL")> (SELECT
PERCENTILE_CONT(0.500000) WITHIN GROUP ( ORDER BY "INCOME_LEVEL_COUNT") FROM (SELECT
"CUST_INCOME_LEVEL" "CUST_INCOME_LEVEL",COUNT(*) "INCOME_LEVEL_COUNT" FROM (SELECT /*+
CACHE_TEMP_TABLE ("T1") */ "C0" "CUST_INCOME_LEVEL","C1" "COUNTRY_NAME" FROM
"SYS"."SYS_TEMP_0FD9D6607_644975" "T1") "CUST" GROUP BY "CUST_INCOME_LEVEL")
"from$_subquery$_005"))
统计信息
----------------------------------------------------------
138 recursive calls
317 db block gets
6379 consistent gets
303 physical reads
1520 redo size
5460 bytes sent via SQL*Net to client
504 bytes received via SQL*Net from client
10 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
123 rows processed
因为在查询修改后的版本中增加了扫描次数,逻辑IO的支出更明显了。在这个查询中允许oracle进行表转换,将散列联结的结果写入到磁盘中的一张临时表中然后在查询中多次重用的效率就明显更高。
寻找其他优化机会
计算产口各个销售渠道的成本找出2000年所生的每种产品的平均,最小和最大成本。但下面的查询不仅阅读起来困难并且难以修改,而且在某种程度上效率也是不高的。
SQL> --用来计算成本的老sql语句
SQL> SELECT /*+ gather_plan_statistics */
2 SUBSTR(prod_name,1,30) prod_name,
3 channel_desc,
4 (
5 SELECT AVG(c2.unit_cost) AS avg_cost FROM sh.costs c2
6 WHERE c2.prod_id=c.prod_id AND c2.channel_id=c.channel_id
7 AND c2.time_id BETWEEN to_date('01/01/2000','mm/dd/yyyy')
8 AND to_date('12/31/2000','mm/dd/yyyy')
9 ),
10 (
11 SELECT MIN(c2.unit_cost) AS min_cost FROM sh.costs c2
12 WHERE c2.prod_id=c.prod_id AND c2.channel_id=c.channel_id
13 AND c2.time_id BETWEEN to_date('01/01/2000','mm/dd/yyyy')
14 AND to_date('12/31/2000','mm/dd/yyyy')
15 ),
16 (
17 SELECT MAX(c2.unit_cost) AS max_cost FROM sh.costs c2
18 WHERE c2.prod_id=c.prod_id AND c2.channel_id=c.channel_id
19 AND c2.time_id BETWEEN to_date('01/01/2000','mm/dd/yyyy')
20 AND to_date('12/31/2000','mm/dd/yyyy')
21 )
22 FROM (
23 SELECT DISTINCT pr.prod_id,pr.prod_name,ch.channel_id,ch.channel_desc
24 FROM sh.channels ch,sh.products pr,sh.costs co
25 WHERE ch.channel_id=co.channel_id
26 AND co.prod_id=pr.prod_id
27 AND co.time_id BETWEEN to_date('01/01/2000','mm/dd/yyyy')
28 AND to_date('12/31/2000','mm/dd/yyyy')
29 ) c
30 ORDER BY prod_name,channel_desc;
已选择216行。
执行计划
----------------------------------------------------------
Plan hash value: 1877279774
------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20640 | 1310K| | 640 (1)| 00:00:08 | | |
| 1 | SORT AGGREGATE | | 1 | 20 | | | | | |
| 2 | PARTITION RANGE ITERATOR | | 96 | 1920 | | 17 (0)| 00:00:01 | 13 | 16 |
|* 3 | TABLE ACCESS BY LOCAL INDEX ROWID| COSTS | 96 | 1920 | | 17 (0)| 00:00:01 | 13 | 16 |
| 4 | BITMAP CONVERSION TO ROWIDS | | | | | | | | |
|* 5 | BITMAP INDEX SINGLE VALUE | COSTS_PROD_BIX | | | | | | 13 | 16 |
| 6 | SORT AGGREGATE | | 1 | 20 | | | | | |
| 7 | PARTITION RANGE ITERATOR | | 96 | 1920 | | 17 (0)| 00:00:01 | 13 | 16 |
|* 8 | TABLE ACCESS BY LOCAL INDEX ROWID| COSTS | 96 | 1920 | | 17 (0)| 00:00:01 | 13 | 16 |
| 9 | BITMAP CONVERSION TO ROWIDS | | | | | | | | |
|* 10 | BITMAP INDEX SINGLE VALUE | COSTS_PROD_BIX | | | | | | 13 | 16 |
| 11 | SORT AGGREGATE | | 1 | 20 | | | | | |
| 12 | PARTITION RANGE ITERATOR | | 96 | 1920 | | 17 (0)| 00:00:01 | 13 | 16 |
|* 13 | TABLE ACCESS BY LOCAL INDEX ROWID| COSTS | 96 | 1920 | | 17 (0)| 00:00:01 | 13 | 16 |
| 14 | BITMAP CONVERSION TO ROWIDS | | | | | | | | |
|* 15 | BITMAP INDEX SINGLE VALUE | COSTS_PROD_BIX | | | | | | 13 | 16 |
| 16 | SORT ORDER BY | | 20640 | 1310K|1632K| 640 (1)| 00:00:08 | | |
| 17 | VIEW | | 20640 | 1310K| | 316 (2)| 00:00:04 | | |
| 18 | HASH UNIQUE | | 20640 | 1169K|1384K| 316 (2)| 00:00:04 | | |
|* 19 | HASH JOIN | | 20640 | 1169K| | 25 (8)| 00:00:01 | | |
| 20 | TABLE ACCESS FULL | PRODUCTS | 72 | 2160 | | 3 (0)| 00:00:01 | | |
|* 21 | HASH JOIN | | 20640 | 564K| | 21 (5)| 00:00:01 | | |
| 22 | TABLE ACCESS FULL | CHANNELS | 5 | 65 | | 3 (0)| 00:00:01 | | |
| 23 | PARTITION RANGE ITERATOR | | 20640 | 302K| | 17 (0)| 00:00:01 | 13 | 16 |
|* 24 | TABLE ACCESS FULL | COSTS | 20640 | 302K| | 17 (0)| 00:00:01 | 13 | 16 |
------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("C2"."CHANNEL_ID"=:B1 AND "C2"."TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
5 - access("C2"."PROD_ID"=:B1)
8 - filter("C2"."CHANNEL_ID"=:B1 AND "C2"."TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
10 - access("C2"."PROD_ID"=:B1)
13 - filter("C2"."CHANNEL_ID"=:B1 AND "C2"."TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
15 - access("C2"."PROD_ID"=:B1)
19 - access("CO"."PROD_ID"="PR"."PROD_ID")
21 - access("CH"."CHANNEL_ID"="CO"."CHANNEL_ID")
24 - filter("CO"."TIME_ID"<=TO_DATE(' 2000-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
29642 consistent gets
0 physical reads
0 redo size
14092 bytes sent via SQL*Net to client
570 bytes received via SQL*Net from client
16 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
216 rows processed
将begin_date和end_date列放入单独的查询bookends 开始,只留下需要设定值的地方。产品的数据被放在prodmaster子查询中。尽管这几段sql语句放在子查询也可以实现其功能,但将它们移到因子化的子查询中大大地增强了sql语句整体的可读性。
平均、最大和最小成本的计算被一个称为cost_compare的子查询取代。最后,加入了联结prodmaster和cost_compare子查询的sql语句。
SQL> --使用with子句进行重构后的老sql语句
SQL> WITH bookends AS
2 (SELECT to_date('01/01/2000', 'mm/dd/yyyy') begin_date,
3 to_date('12/31/2000', 'mm/dd/yyyy') end_date
4 FROM dual),
5 prodmaster AS
6 (SELECT DISTINCT pr.prod_id, pr.prod_name, ch.channel_id, ch.channel_desc
7 FROM sh.channels ch, sh.products pr, sh.costs co
8 WHERE ch.channel_id = co.channel_id
9 AND co.prod_id = pr.prod_id
10 AND co.time_id BETWEEN (SELECT begin_date FROM bookends) AND
11 (SELECT end_date FROM bookends)),
12 cost_compare AS
13 (SELECT c2.prod_id,
14 c2.channel_id,
15 AVG(c2.unit_cost) avg_cost,
16 MIN(c2.unit_cost) min_cost,
17 MAX(c2.unit_cost) max_cost
18 FROM sh.costs c2
19 WHERE c2.time_id BETWEEN (SELECT begin_date FROM bookends) AND
20 (SELECT end_date FROM bookends)
21 GROUP BY c2.prod_id, c2.channel_id)
22 SELECT /*+ gather_plan_statistics */
23 SUBSTR(pm.prod_name, 1, 30) prod_name,
24 pm.channel_desc,
25 cc.avg_cost,
26 cc.min_cost,
27 cc.max_cost
28 FROM prodmaster pm
29 JOIN cost_compare cc
30 ON cc.prod_id = pm.prod_id
31 AND cc.channel_id = pm.channel_id
32 ORDER BY pm.prod_id, pm.channel_id;
已选择216行。
执行计划
----------------------------------------------------------
Plan hash value: 2361085328
----------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 138 | 12696 | 83 (5)| 00:00:01 | | |
| 1 | MERGE JOIN | | 138 | 12696 | 83 (5)| 00:00:01 | | |
| 2 | SORT JOIN | | 205 | 9430 | 44 (5)| 00:00:01 | | |
| 3 | VIEW | | 205 | 9430 | 44 (5)| 00:00:01 | | |
| 4 | HASH UNIQUE | | 205 | 11890 | 44 (5)| 00:00:01 | | |
|* 5 | HASH JOIN | | 205 | 11890 | 39 (3)| 00:00:01 | | |
| 6 | TABLE ACCESS FULL | PRODUCTS | 72 | 2160 | 3 (0)| 00:00:01 | | |
| 7 | MERGE JOIN | | 205 | 5740 | 36 (3)| 00:00:01 | | |
| 8 | TABLE ACCESS BY INDEX ROWID | CHANNELS | 5 |65 | 2 (0)| 00:00:01 | | |
| 9 | INDEX FULL SCAN | CHANNELS_PK | 5 | | 1 (0)| 00:00:01 | | |
|* 10 | SORT JOIN | | 205 | 3075 | 34 (3)| 00:00:01 | | |
| 11 | PARTITION RANGE ITERATOR | | 205 | 3075 | 33 (0)| 00:00:01 | KEY | KEY |
| 12 | TABLE ACCESS BY LOCAL INDEX ROWID| COSTS | 205 | 3075 | 33 (0)| 00:00:01 | KEY | KEY |
| 13 | BITMAP CONVERSION TO ROWIDS | | | | | | | |
|* 14 | BITMAP INDEX RANGE SCAN | COSTS_TIME_BIX | | | | | KEY | KEY |
| 15 | FAST DUAL | | 1 | | 2 (0)| 00:00:01 | | |
| 16 | FAST DUAL | | 1 | | 2 (0)| 00:00:01 | | |
|* 17 | SORT JOIN | | 145 | 6670 | 39 (6)| 00:00:01 | | |
| 18 | VIEW | | 145 | 6670 | 38 (3)| 00:00:01 | | |
| 19 | HASH GROUP BY | | 145 | 2900 | 38 (3)| 00:00:01 | | |
| 20 | PARTITION RANGE ITERATOR | | 205 | 4100 | 33 (0)| 00:00:01 | KEY | KEY |
| 21 | TABLE ACCESS BY LOCAL INDEX ROWID | COSTS | 205 | 4100 | 33 (0)| 00:00:01 | KEY | KEY |
| 22 | BITMAP CONVERSION TO ROWIDS | | | | | | | |
|* 23 | BITMAP INDEX RANGE SCAN | COSTS_TIME_BIX | | | | | KEY | KEY |
| 24 | FAST DUAL | | 1 | | 2 (0)| 00:00:01 | | |
| 25 | FAST DUAL | | 1 | | 2 (0)| 00:00:01 | | |
----------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("CO"."PROD_ID"="PR"."PROD_ID")
10 - access("CH"."CHANNEL_ID"="CO"."CHANNEL_ID")
filter("CH"."CHANNEL_ID"="CO"."CHANNEL_ID")
14 - access("CO"."TIME_ID">= (SELECT TO_DATE(' 2000-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') FROM "SYS"."DUAL"
"DUAL") AND "CO"."TIME_ID"<= (SELECT TO_DATE(' 2000-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss') FROM "SYS"."DUAL"
"DUAL"))
17 - access("CC"."PROD_ID"="PM"."PROD_ID" AND "CC"."CHANNEL_ID"="PM"."CHANNEL_ID")
filter("CC"."CHANNEL_ID"="PM"."CHANNEL_ID" AND "CC"."PROD_ID"="PM"."PROD_ID")
23 - access("C2"."TIME_ID">= (SELECT TO_DATE(' 2000-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') FROM "SYS"."DUAL"
"DUAL") AND "C2"."TIME_ID"<= (SELECT TO_DATE(' 2000-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss') FROM "SYS"."DUAL"
"DUAL"))
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
7436 consistent gets
0 physical reads
0 redo size
13596 bytes sent via SQL*Net to client
570 bytes received via SQL*Net from client
16 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
216 rows processed
将子查询因子化应用到pl/sql中
例子:
- 只列出至少在3个不同的年份中都采购了产品的消费者
- 按照产品类别分组统计每个消费者的购买总额
用常规的pl/sql获取所需的数据
查询满足标准的所有消费者并将他们的ID保存在一张临时表中
然后在新保存的消费者ID中执行循环并找到他们,加起来,将这些信息插入到另一张临时表中。然后再将得到的结果与customers和products表联结以生成报告。
--用PL/SQL生成消费者报告
BEGIN
EXECUTE IMMEDIATE 'drop table cust3year';
EXECUTE IMMEDIATE 'drop table sales3year';
EXCEPTION
WHEN OTHERS THEN
NULL;
END;
/
create global temporary table cust3year(cust_id number);
CREATE GLOBAL TEMPORARY TABLE sales3year(
cust_id NUMBER,
prod_category VARCHAR2(50),
total_sale NUMBER
)
/
BEGIN
EXECUTE IMMEDIATE 'truncate table cust3year';
EXECUTE IMMEDIATE 'truncate table sales3year';
INSERT INTO cust3year
SELECT cust_id--,count(cust_years) year_count
FROM (
SELECT DISTINCT cust_id,TRUNC(time_id,'YEAR') cust_years
FROM sh.sales
)
GROUP BY cust_id
HAVING COUNT(cust_years)>=3;
--SELECT * FROM cust3year;
FOR crec IN (SELECT cust_id FROM cust3year)
LOOP
INSERT INTO sales3year
SELECT sa.cust_id,p.prod_category,SUM(co.unit_cost*sa.quantity_sold)
FROM sh.sales sa
JOIN sh.products p ON p.prod_id=sa.prod_id
JOIN sh.costs co ON co.prod_id=sa.prod_id AND co.time_id=sa.time_id
JOIN sh.customers cu ON cu.cust_id=sa.cust_id
WHERE crec.cust_id=sa.cust_id
GROUP BY sa.cust_id,p.prod_category;
END LOOP;
END;
/
SELECT c3.cust_id,c.cust_last_name,c.cust_first_name,s3.prod_category,s3.total_sale FROM sales3year s3
JOIN cust3year c3 ON s3.cust_id=c3.cust_id
JOIN sh.customers c ON c.cust_id=s3.cust_id
ORDER BY 1,4;
上面是一段很好的PL/SQL程序块,如果考虑子查询因子化,还可以改进。首先将消费者ID的部分放到with子句中,接下来再利用子查询的结果生成报告所需的销售,产品和消费者信息就可以了。
--使用with子句生成消费者报告
WITH cust3year AS(
SELECT cust_id
FROM (
SELECT DISTINCT cust_id,TRUNC(time_id,'YEAR') cust_years
FROM sh.sales
)
GROUP BY cust_id
HAVING COUNT(cust_years)>=3
),
sales3year AS (
SELECT sa.cust_id,p.prod_category,SUM(co.unit_cost*sa.quantity_sold) AS total_sale
FROM sh.sales sa
JOIN sh.products p ON p.prod_id=sa.prod_id
JOIN sh.costs co ON co.prod_id=sa.prod_id AND co.time_id=sa.time_id
JOIN sh.customers cu ON cu.cust_id=sa.cust_id
WHERE sa.cust_id IN (SELECT cust_id FROM cust3year)
GROUP BY sa.cust_id,p.prod_category
)
SELECT c3.cust_id,c.cust_last_name,c.cust_first_name,s3.prod_category,s3.total_sale FROM sales3year s3
JOIN cust3year c3 ON s3.cust_id=c3.cust_id
JOIN sh.customers c ON c.cust_id=s3.cust_id
ORDER BY 1,4;
WITH custyear AS
(SELECT sa.cust_id, EXTRACT(YEAR FROM time_id) sales_year
FROM sh.sales sa
WHERE EXTRACT(YEAR FROM time_id) BETWEEN 1998 AND 2002
GROUP BY sa.cust_id, EXTRACT(YEAR FROM time_id)),
cust3year AS
(SELECT DISTINCT c3.cust_id
FROM (SELECT cust_id, COUNT(*) OVER(PARTITION BY cust_id) year_count
FROM custyear) c3
WHERE c3.year_count >= 3)
SELECT c.cust_id,
c.cust_last_name,
c.cust_first_name,
p.prod_category,
SUM(co.unit_price * sa.quantity_sold) AS total_sale
FROM cust3year c3
JOIN sh.sales sa
ON sa.cust_id = c3.cust_id
JOIN sh.products p
ON p.prod_id = sa.prod_id
JOIN sh.costs co
ON co.prod_id = sa.prod_id
AND co.time_id = sa.time_id
JOIN sh.customers c
ON c.cust_id = c3.cust_id
GROUP BY c.cust_id, c.cust_last_name, c.cust_first_name, p.prod_category
ORDER BY c.cust_id;
extract()函数将年份从日期中提取出来并转化为整形值以简化年份的比较
子查询因子化可以用来更好地组织一些查询,在某些情况下甚至可以用来作为性能调优的工具。学会使用它就等于在你的oracle工具箱中添加了一个新工具。
递归子查询
递归子查询因子化 recursive subquery factoring RSF
--基本的connect by
SELECT LPAD(' ', LEVEL * 2 - 1, ' ') || emp.emp_last_name emp_last_name,
emp.emp_first_name,
emp.employee_id,
emp.mgr_last_name,
emp.mgr_first_name,
emp.manager_id,
emp.department_name
FROM (SELECT /*+ inline gather_plan_statistics */
e.last_name emp_last_name,
e.first_name emp_first_name,
e.employee_id,
d.department_id,
e.manager_id,
d.department_name,
es.last_name mgr_last_name,
es.first_name mgr_first_name
FROM hr.employees e
LEFT OUTER JOIN hr.departments d
ON e.department_id = d.department_id
LEFT OUTER JOIN hr.employees es
ON es.employee_id = e.manager_id) emp
CONNECT BY PRIOR emp.employee_id = emp.manager_id
START WITH emp.manager_id IS NULL
ORDER SIBLINGS BY emp.emp_last_name;
内嵌视图emp用来与employee和department表进行联结,然后将一个数据集提供给select ... connect by语句。用prior运算符来将当前的employee_id与另一行中的manager_id列值匹配。反复的这么做就建立了一个递归查询。
start with子句是用来指引从manager_id为空的那一行开始。level伪列保存了递归的深度值,使得可以通过一个简单的方法来输出进行缩进,从而可以直观地看出组织层次结构。
RSF示例
--基本的递归子查询因子化
WITH emp AS
(SELECT /*+ inline gather_plan_statistics */
e.last_name, e.first_name, e.employee_id, e.manager_id, d.department_name
FROM hr.employees e
LEFT OUTER JOIN hr.departments d
ON e.department_id = d.department_id),
emp_recurse(last_name,
first_name,
employee_id,
manager_id,
department_name,
lvl) AS
(SELECT e.last_name AS last_name,
e.first_name AS first_name,
e.employee_id AS employee_id,
e.manager_id AS manager_id,
e.department_name AS department_name,
1 AS lvl
FROM emp e
WHERE e.manager_id IS NULL
UNION ALL
SELECT emp.last_name AS last_name,
emp.first_name AS first_name,
emp.employee_id AS employee_id,
emp.manager_id AS manager_id,
emp.department_name AS department_name,
empr.lvl + 1 AS lvl
FROM emp
JOIN emp_recurse empr
ON empr.employee_id = emp.manager_id)
search DEPTH FIRST BY last_name SET order1
SELECT LPAD(' ', lvl * 2 - 1, ' ') || er.last_name last_name,
er.first_name,
er.department_name
FROM emp_recurse er;
递归的with子句需要两个查询块:定位点成员和递归成员。这两个子查询块必须通过集合运算符union all结合到一起。定位点成员是union all之前的查询,而递归成员是其后面的查询。递归子查询必须引用定义子查询,这样就进行了递归。
RSF的限制条件
RSF的使用比connect by要灵活得多,但是,它的使用也有一些限制:
- distinct关键字或group by子句
- model子句
- 聚合函数,但在select列表中可以使用分析函数
- 引用query_name的子查询
- 引用query_name作为右表的外联结
与connect by的不同点
与connect by相比较,rsf查询返回的列必须在查询暄义中声明,如emp_recurse(last_name,first_name,employee_id,manager_id,department_name,lvl)
search depth first,默认的搜索是breadth first,这通常不是一个层级型查询所想要的输出。breadth first搜索在返回任何子数据行之前返回每一层级上的兄弟数据行。指定search depth first将会按照层级的顺序返回数据行。search子句中的set order1部分将order1伪列的值设置为数据行返回的顺序值。
| 类型 | 名称 | 用途 |
|---|---|---|
| 函数 | sys_connect_by_path | 返回当前数据行的所有祖先 |
| 运算符 | connect_by_root | 返回根数据行的值 |
| 运算符 | prior | 用来表明层级型查询,在递归子查询中不需要 |
| 伪列 | connect_by_iscycle | 在层级中检测循环 |
| 参数 | nocycle | connect by的参数,与connect_by_iscycle一起使用 |
| 伪列 | connect_by_isleaf | 标识叶子数据行 |
| 伪列 | level | 用来表明层级中的深度 |
level伪列
--level伪列
SELECT LPAD(' ', LEVEL * 2 - 1, ' ') || e.last_name last_name, LEVEL
FROM hr.employees e
CONNECT BY PRIOR e.employee_id = e.manager_id
START WITH e.manager_id IS NULL
ORDER SIBLINGS BY e.last_name;
在层级型查询中经常被用来实现输出缩进,使得层级看起来很直观。;
--创建lvl列
WITH emp_recurse(employee_id,manager_id,last_name,lvl) AS (
SELECT e.employee_id,NULL,e.last_name,1 AS lvl
FROM hr.employees e
WHERE e.manager_id IS NULL
UNION ALL
SELECT e1.employee_id,e1.manager_id,e1.last_name,e2.lvl+1 AS lvl
FROM hr.employees e1
JOIN emp_recurse e2 ON e2.employee_id=e1.manager_id
)
search DEPTH FIRST BY last_name SET last_time_order
SELECT LPAD(' ', r.lvl * 2 - 1, ' ') || r.last_name last_name,r.lvl
FROM emp_recurse r
ORDER BY last_time_order;
sys_connect_by_path函数
用来返回组成层级的直到当前的行的值。下面的列子用sys_connect_by_path函数用来建立一个冒号分隔的从根到节点的层级。
--sys_connect_by_path
SELECT LPAD(' ', 2 * (LEVEL - 1)) || e.last_name AS last_name,
sys_connect_by_path(last_name, ':') path
FROM hr.employees e
START WITH e.manager_id IS NULL
CONNECT BY PRIOR e.employee_id = e.manager_id
ORDER SIBLINGS BY e.last_name;
尽管sys_connect_by_path函数不能在RSF查询中使用,你可以使用与重新产生的level伪列几乎相同的方法来复制这个函数的功能。现在不用使用计算器来计数,而是附加一个字符串值。
--建立你自己的sys_connect_by_path函数
WITH emp_recurse(employee_id,manager_id,last_name,lvl,PATH) AS (
SELECT e.employee_id,NULL,e.last_name,1 AS lvl,':'||to_char(e.last_name) AS path
FROM hr.employees e
WHERE e.manager_id IS NULL
UNION ALL
SELECT e1.employee_id,e1.manager_id,e1.last_name,e2.lvl+1 AS lvl,e2.path||':'||to_char(e1.last_name) AS path
FROM hr.employees e1
JOIN emp_recurse e2 ON e2.employee_id=e1.manager_id
)
search DEPTH FIRST BY last_name SET last_time_order
SELECT LPAD(' ', r.lvl * 2 - 1, ' ') || r.last_name last_name,r.path
FROM emp_recurse r
ORDER BY last_time_order;

如果你需要将层级显示为逗号分隔的列表,sys_connect_by_path无法做到,因为sys_connect_by_path函数的问题在于输出中的第一个字符必须是冒号。
--RSF逗号分隔的路径
WITH emp_recurse(employee_id,manager_id,last_name,lvl,PATH) AS (
SELECT e.employee_id,NULL,e.last_name,1 AS lvl,to_char(e.last_name) AS path
FROM hr.employees e
WHERE e.manager_id IS NULL
UNION ALL
SELECT e1.employee_id,e1.manager_id,e1.last_name,e2.lvl+1 AS lvl,e2.path||','||to_char(e1.last_name) AS path
FROM hr.employees e1
JOIN emp_recurse e2 ON e2.employee_id=e1.manager_id
)
search DEPTH FIRST BY last_name SET last_time_order
SELECT LPAD(' ', r.lvl * 2 - 1, ' ') || r.last_name last_name,r.path
FROM emp_recurse r
ORDER BY last_time_order;
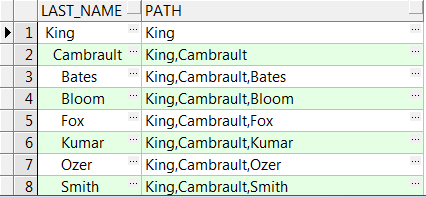
connect_by_root运算符
这个运算符强化了connect by语法,使得它可以返回当前行的根节点。
--connect_by_root
UPDATE hr.employees SET manager_id=NULL WHERE last_name='Kochhar';
SELECT /*+ inline gather_plan_statistics */
LEVEL,LPAD(' ',2*(LEVEL-1))||last_name last_name,first_name,
connect_by_root last_name AS root,
sys_connect_by_path(last_name,':') PATH
FROM hr.employees
WHERE connect_by_root last_name='Kochhar'
CONNECT BY PRIOR employee_id=manager_id
START WITH manager_id IS NULL;
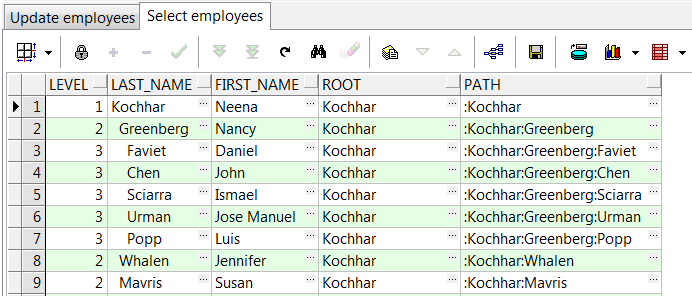
--复制connect_by_root运算符功能
WITH emp_recurse(employee_id,manager_id,last_name,lvl,path) AS (
SELECT /*+ gather_plan_statistics */
e.employee_id,NULL AS manager_id,
e.last_name,1 AS lvl,
':'||e.last_name||':' AS path
FROM hr.employees e
WHERE e.manager_id IS NULL
UNION ALL
SELECT
e.employee_id,e.manager_id,
e.last_name,er.lvl+1 AS lvl,
er.path||e.last_name||':' AS path
FROM hr.employees e
JOIN emp_recurse er ON er.employee_id=e.manager_id
JOIN hr.employees e2 ON e2.employee_id=e.manager_id
)
search DEPTH FIRST BY last_name SET order1,
emps AS (
SELECT lvl,last_name,path,SUBSTR(path,2,INSTR(path,':',2)-2) root
FROM emp_recurse
)
SELECT lvl,LPAD(' ',2*(lvl-1))|| last_name last_name,
root,path FROM emps
WHERE root='Kochhar';
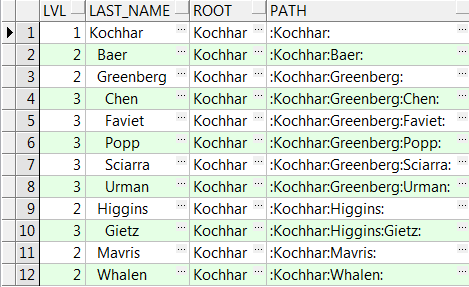
connect_by_iscycle伪列和nocycle参数
connect_by_iscycle伪列使得在层级中检测循环变得很容易。
这里将smith设置为king的经理来故意引入了一个错误,这将导致connect by中出现错误。
--connect by中的循环错误
SELECT * FROM hr.employees WHERE employee_id IN (100,171);
--将Smith设置为King的经理
UPDATE hr.employees SET manager_id=171 WHERE employee_id=100;
SELECT LPAD(' ',2*(LEVEL-1))|| last_name last_name,
first_name,employee_id,LEVEL
FROM hr.employees
START WITH employee_id=100
CONNECT BY PRIOR employee_id=manager_id;
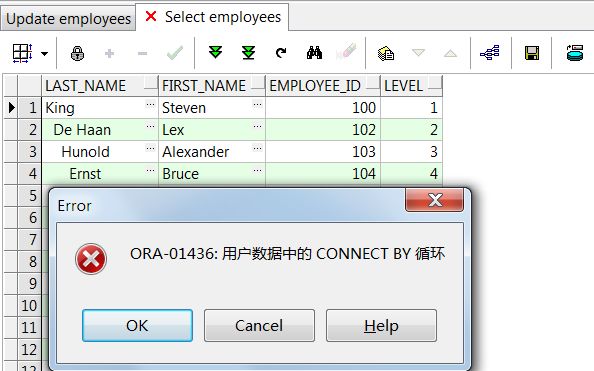
nocycle和connect_by_iscycle可以用来检测层级中的循环。nocycle参数可以阻止发ora-1436错误,使得所有行都要以输出。connect_by_iscycle运算符使得你可以很容易地找到导致错误发生的行。
--通过connect_by_iscycle检测循环
SELECT LPAD(' ',2*(LEVEL-1))|| last_name last_name,
first_name,employee_id,LEVEL,
connect_by_iscycle
FROM hr.employees
START WITH employee_id=100
CONNECT BY NOCYCLE PRIOR employee_id=manager_id;
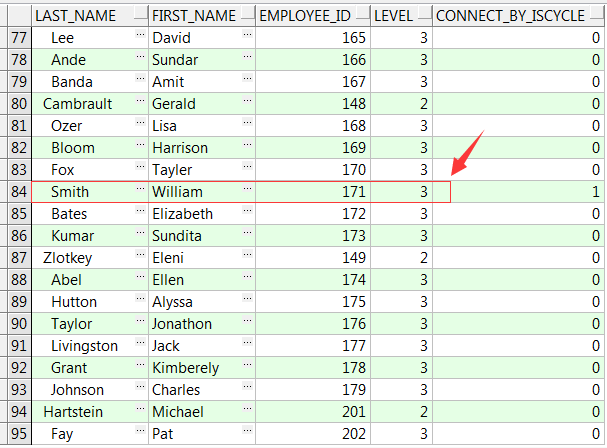
connect_by_iscycle的值为1,表示smith的那一行数据导致了错误。接下来查询Smith的数据,所有一切看上去都很正常。最后,你再以Smith的员工ID寻找他所管理的所有员工,错误就是公司总裁没有经理。因此解决办法不是将这一行的manager_id设置回空值。
SELECT e.last_name, e.first_name, e.employee_id, e.manager_id
FROM hr.employees e
WHERE e.employee_id = 171
OR e.manager_id = 171;

--在递归查询中检测循环
WITH emp(employee_id,manager_id,last_name,first_name,lvl) AS (
SELECT e.employee_id,NULL AS manager_id,e.last_name,e.first_name,1 AS lvl
FROM hr.employees e
WHERE e.employee_id=100
UNION ALL
SELECT e.employee_id,e.manager_id,e.last_name,e.first_name,emp.lvl+1 AS lvl
FROM hr.employees e
JOIN emp ON emp.employee_id=e.manager_id
)
search DEPTH FIRST BY last_name SET order1
CYCLE employee_id SET is_cycle TO '1' DEFAULT '0'
SELECT LPAD(' ',2*(lvl-1))||last_name last_name,first_name,employee_id,lvl,is_cycle
FROM emp ORDER BY order1;
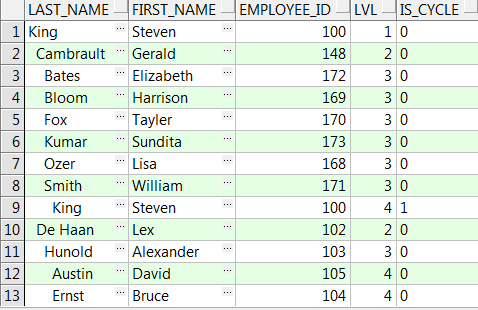
注意: cycle子句让你将is_cycle列值设置为0或1的。这里只允许单值字符。这一列的名称同样是用户自定义的。检查输出,可以看到RSF中的cycle子句在指明导致数据循环的行时做得更好。出现错误的数据行很清楚地标记为King那一行,因此可以查询那一行并迅速确定错误所在。
connect_by_isleaf伪列
connect_by_isleaf用来在层级数据中识别叶子节点。
--connect_by_isleaf伪列
SELECT LPAD(' ',2*(LEVEL-1))|| e.last_name last_name,connect_by_isleaf
FROM hr.employees e
START WITH e.manager_id IS NULL
CONNECT BY PRIOR e.employee_id=e.manager_id
ORDER SIBLINGS BY e.last_name;

RSF中要复制这一点还比较困难的。你需要在员工层级中标识出叶子节点,从定义上来说,叶子节点都不是经理。所有不是经理的行就是叶子节点。
--在递归查询中找出叶子节点
WITH leaves AS (
SELECT e.employee_id FROM hr.employees e
WHERE e.employee_id NOT IN (
SELECT manager_id FROM hr.employees WHERE manager_id IS NOT NULL
)
),
emp(manager_id,employee_id,last_name,lvl,isleaf) AS (
SELECT e.manager_id,e.employee_id,e.last_name,1 AS lvl,0 AS isleaf
FROM hr.employees e
WHERE e.manager_id IS NULL
UNION ALL
SELECT e.manager_id,nvl(e.employee_id,NULL),e.last_name,emp.lvl+1 AS lvl, DECODE(l.employee_id,NULL,0,1) AS isleaf
FROM hr.employees e
JOIN emp ON emp.employee_id=e.manager_id
LEFT OUTER JOIN leaves l ON l.employee_id=e.employee_id
)
search DEPTH FIRST BY last_name SET order1
SELECT LPAD(' ',2*(lvl-1))||last_name last_name, isleaf
FROM emp;
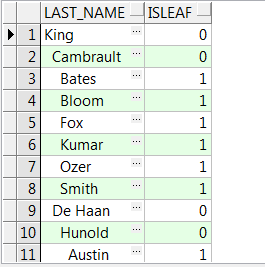
leaves子查询被用来寻找叶子节点,然后将结果与employees表进行左外联结。leaves.employee_id列的值表时当前行是否是叶子。
别一种方法利用分析函数lead()使用lvl列的值来确定数据行是否为叶子节点。lead()函数依赖seach子句中所定的last_name_order列的值。
--使用lead()寻找叶子节点
WITH emp(manager_id,employee_id,last_name,lvl) AS (
SELECT e.manager_id,e.employee_id,e.last_name,1 AS lvl
FROM hr.employees e
WHERE e.manager_id IS NULL
UNION ALL
SELECT e.manager_id,nvl(e.employee_id,NULL),e.last_name,emp.lvl+1 AS lvl
FROM hr.employees e
JOIN emp ON emp.employee_id=e.manager_id
)
search DEPTH FIRST BY last_name SET last_name_order
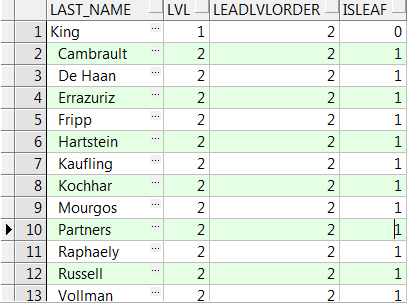
SELECT LPAD(' ',2*(lvl-1))||last_name last_name,lvl,
LEAD(lvl) OVER(ORDER BY last_name_order) leadlvlorder,
CASE
WHEN (lvl-LEAD(lvl) OVER (ORDER BY last_name_order))<0
THEN
0
ELSE 1
END isleaf
FROM emp;
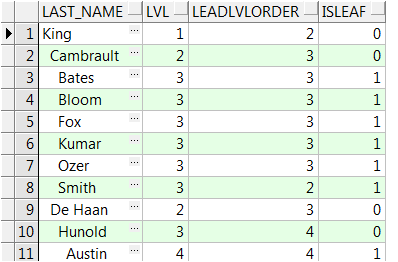
如果search子从depth first改为breadth first,它因为依赖数据的顺序而显得有点脆弱,这样的输出有可能是不正确的,如下的运行:
--使用breadth first的lead()
WITH emp(manager_id,employee_id,last_name,lvl) AS (
SELECT e.manager_id,e.employee_id,e.last_name,1 AS lvl
FROM hr.employees e
WHERE e.manager_id IS NULL
UNION ALL
SELECT e.manager_id,nvl(e.employee_id,NULL),e.last_name,emp.lvl+1 AS lvl
FROM hr.employees e
JOIN emp ON emp.employee_id=e.manager_id
)
search breadth FIRST BY last_name SET last_name_order
SELECT LPAD(' ',2*(lvl-1))||last_name last_name,lvl,
LEAD(lvl) OVER(ORDER BY last_name_order) leadlvlorder,
CASE
WHEN (lvl-LEAD(lvl) OVER (ORDER BY last_name_order))<0
THEN
0
ELSE 1
END isleaf
FROM emp;
尽管在大多数据实践中你都可以使用在递归因子化子查询中复制connect by的功能,但很多情况下,全用connect by语法更简单,在RSF中做同样的事件在多数情况下需要更多的SQL代码。connect by可以产生比RSF更好的执行计划,铖是对于相对简单的查询。