geoman模型基于编解码网络及分层注意力机制设计而成,可以对多源时间序列进行预测。在编码端,引入局部及全局注意力,并将传感器之间的距离作为全局注意力的一部分;在解码端,引入时间注意力,用于挖掘时间上的依赖关系。该模型相关代码可以在github上找到,但是缺少数据处理的部分,本文介绍其数据处理部分,数据集下载地址为http://urban-computing.com/index-40.htm。相关代码如下:
# load data of beijing
data_path = './data'
air_quality_data = pd.read_csv('{}/airquality.csv'.format(data_path), nrows=278023)
# remove data from 1022 that with lot of null data
air_quality_data = air_quality_data[air_quality_data['station_id'] != 1022]
columns = ['PM25_Concentration', 'PM10_Concentration',
'NO2_Concentration', 'CO_Concentration',
'O3_Concentration', 'SO2_Concentration']
# pivot the data
pivot_air_data = air_quality_data.pivot(index='time', columns='station_id', values=columns)
# linear interpolate to fill the loss value
pivot_air_data1 = pivot_air_data.interpolate(method='linear').dropna()
air_quality_data = pivot_air_data1.stack(level=1).reset_index().sort_values(by=['station_id', 'time'])
# feature normalization
temp_data = air_quality_data.values
temp_data1 = temp_data[:, 2:].astype('float32')
scaler = MinMaxScaler(feature_range=(0, 1))
scaled = scaler.fit_transform(temp_data1)
temp_data[:, 2:] = scaled
air_quality_data = pd.DataFrame(temp_data, columns=['time', 'station_id'] + columns)
# select the 1001 point as the local input
local_input = air_quality_data[air_quality_data.station_id == 1001].drop(['station_id', 'time'], axis=1).values
# transform time series to supervised
time_length = local_input.shape[0]
local_data = []
label = []
for i in range(hps.n_steps_encoder, time_length - hps.n_steps_decoder):
local_data.append(scaled[i - hps.n_steps_encoder:i, :])
label.append(scaled[i:i + hps.n_steps_decoder, 0]) # take pm2.5 as the target series
local_data = np.array(local_data)
label = np.array(label)
length = local_data.shape[0]
global_attn_index = np.arange(0, length, 1)
global_inp_index = np.arange(0, length, 1)
split_ratio = int(length / 10)
# split the data into train/valid/test with the ratio of 8:1:1
training_data = [local_data[:8 * split_ratio],
global_attn_index[:8 * split_ratio],
global_inp_index[:8 * split_ratio],
label.reshape(label.shape[0], label.shape[1], 1)[:8 * split_ratio],
label[:8 * split_ratio]]
valid_data = [local_data[8 * split_ratio:9 * split_ratio],
global_attn_index[8 * split_ratio:9 * split_ratio],
global_inp_index[8 * split_ratio:9 * split_ratio],
label.reshape(label.shape[0], label.shape[1], 1)[8 * split_ratio:9 * split_ratio],
label[8 * split_ratio:9 * split_ratio]]
test_data = [local_data[9 * split_ratio:],
global_attn_index[9 * split_ratio:],
global_inp_index[9 * split_ratio:],
label.reshape(label.shape[0], label.shape[1], 1)[9 * split_ratio:],
label[9 * split_ratio:]]
# construct global_input data
pivot_df = air_quality_data.pivot(index='time', columns='station_id', values=columns)
global_inputs = pivot_df['PM25_Concentration'].values.astype('float32')
points = np.arange(1001, 1037, 1).tolist()
points.remove(1022)
global_attn_states = []
for station_id in points:
id_df = air_quality_data[air_quality_data.station_id == station_id].drop(['station_id', 'time'], axis=1)
factor_agg = []
for factor in columns:
id_fac_df = id_df[factor]
lags, cols = list(), list()
for i in range(hps.n_steps_encoder - 1, -1, -1):
lags.append(id_fac_df.shift(i))
cols.append('{}(t-{})'.format(factor, i))
agg = pd.concat(lags, axis=1).dropna()
agg.columns = cols
factor_agg.append(agg)
global_attn_states.append(pd.concat(factor_agg, axis=1).values)
global_attn_states = np.concatenate(global_attn_states, axis=1)
time_len = global_attn_states.shape[0]
global_attn_states = global_attn_states.reshape(time_len, len(points), 6, hps.n_steps_encoder)
# measure sensor geospatial similarity
sensors = pd.read_csv('{}/station.csv'.format(data_path), nrows=36).drop(index=21)
# lat and lng of sensors
lat = sensors['latitude'].values
lng = sensors['longitude'].values
end_lats, start_lngs = np.meshgrid(lat, lng)
start_lats = end_lats.T
end_lngs = start_lngs.T
distance = get_distance_hav(start_lngs, start_lats, end_lngs, end_lats)
sensor_sim = 1 / (distance + 1)
# normalization
min_sim = np.min(sensor_sim)
max_sim = np.max(sensor_sim)
sensor_sim_nor = (sensor_sim - min_sim) / (max_sim - min_sim)
sensor_sim_nor = sensor_sim_nor[0, :]
模型结果如下:
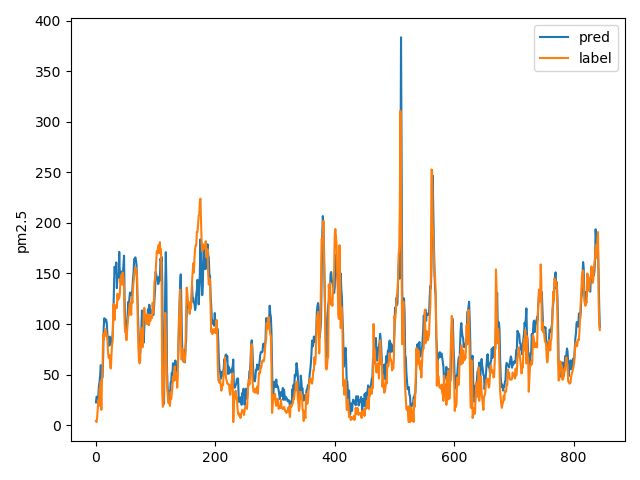
rmse=23.8