
本文以一款阿里云市场历史天气查询产品为例,为你逐步介绍如何用 Python 调用 API 收集、分析与可视化数据。希望你举一反三,轻松应对今后的 API 数据收集与分析任务。
雷同
上周的研究生课,学生分组展示实践环节第二次作业,主题是利用 API 获取、分析与可视化数据。
大家做的内容,确实五花八门。
例如这个组,调查对象是动画片《小猪佩奇》(英文名 “Peppa Pig”,又译作《粉红猪小妹》)。这部片子据说最近很火。
猜猜看,下面这一组调查对象是什么?
没错,是《权力的游戏》(Game of Thrones)。一部很好看的美剧。
主题丰富多彩,做得有声有色。
作为老师,我在下面,应该很开心吧?
不,我简直哭笑不得。
14个组中,有一多半都和他们一样,做的是维基百科页面访问量分析。
为什么会这样呢?
因为我在布置作业的时候,很贴心地给了一个样例,是我之前写的一篇教程《如何用R和API免费获取Web数据?》。

于是,他们就都用 R 语言,来分析维基百科页面访问量了。
这些同学是不是太懒惰了?
听了他们的讲述,我发觉,其中不少同学,是非常想做些新东西的。
他们找了国内若干个云市场,去找 API 产品。
其中要价过高的 API ,被他们自动过滤了。
可即适合练手的低价或免费 API ,也不少。
问题是,他们花了很长时间,也没能搞定。
考虑到作业展示日程迫近,他们只好按照我的教程,去用 R 分析维基百科了。
于是,多组作业,都雷同。
讲到这里,他们一副不好意思的表情。
我却发觉,这里蕴藏着一个问题。
几乎所有国内云市场的 API 产品,都有丰富的文档。不少还干脆给出了各种编程语言对应调用代码。
既然示例代码都有了,为什么你还做不出来呢?
下课后,我让有疑问的同学留下,我带着他们实际测试了一款 API 产品,尝试找到让他们遭遇困境的原因。
市场
我们尝试的,是他们找到的阿里云市场的一款 API 产品,提供天气数据。
它来自于易源数据,链接在这里。
这是一款收费 API ,100次调用的价格为1分钱。
作为作业练习,100次调用已经足够了。
这价格,他们表示可以接受。
我自己走了一遍流程。
点击“立即购买”按钮。
你会被引领到付费页面。如果你没有登录,可以根据提示用淘宝账号登录。
支付1分钱以后,你会看到如下的成功提示。
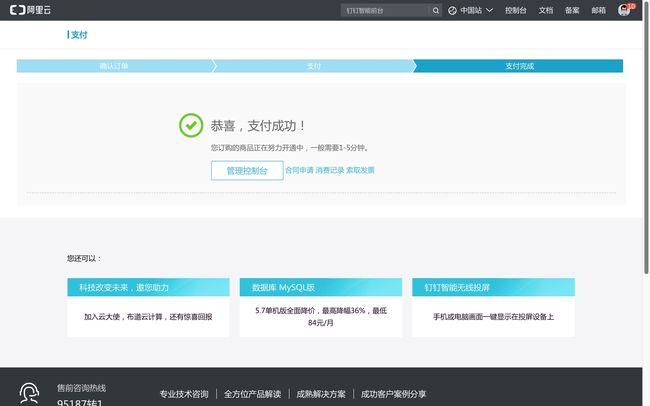
之后,系统会提示给你一些非常重要的信息。
注意上图中标红的字段。
这是你的AppCode,是后面你调用 API 接口获取数据,最为重要的身份认证手段,请点击“复制”按钮把它存储下来。
点击上图中的商品名称链接,回到产品介绍的页面。
这个产品的 API 接口,提供多种数据获取功能。
学生们尝试利用的,是其中“利用id或地名查询历史天气”一项。

请注意这张图里,有几样重要信息:
- 调用地址:这是我们访问 API 的基本信息。就好像你要去见朋友,总得知道见面的地址在哪里;
- 请求方式:本例中的 GET ,是利用 HTTP 协议请求传递数据的主要形式之一;
- 请求参数:这里你要提供两个信息给 API 接口,一是“地区名称”或者“地区id”(二选一),二是月份数据。需注意格式和可供选择的时间范围。
我们往下翻页,会看到请求示例。
默认的请求示例,是最简单的 curl 。
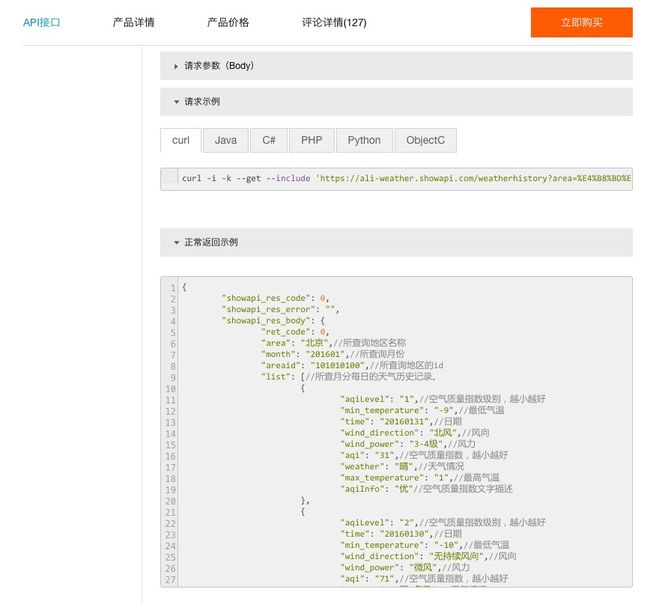
如果你的操作系统里面已经安装了 curl (没有安装的话,可以点击这个链接,寻找对应的操作系统版本下载安装),尝试把上图中 curl 开头的那一行代码拷贝下来,复制到文本编辑器里面。
就像这样:
curl -i -k --get --include 'https://ali-weather.showapi.com/weatherhistory?area=%E4%B8%BD%E6%B1%9F&areaid=101291401&month=201601' -H 'Authorization:APPCODE 你自己的AppCode'
然后,一定要把其中的“你自己的AppCode”这个字符串,替换为你真实的 AppCode 。
把替换好的语句复制粘贴到终端窗口里面运行。
运行结果,如下图所示:
看见窗口下方包含中文的数据了吗?
利用 API 获取数据,就是这么简单。
既然终端执行一条命令就可以,那我们干嘛还要编程呢?
好问题!
因为我们需要的数据,可能不是一次调用就能全部获得。
你需要重复多次调用 API ,而且还得不断变化参数,积累获得数据。
每次若是都这样手动执行命令,效率就太低了。
API 的提供方,会为用户提供详细的文档与说明,甚至还包括样例。
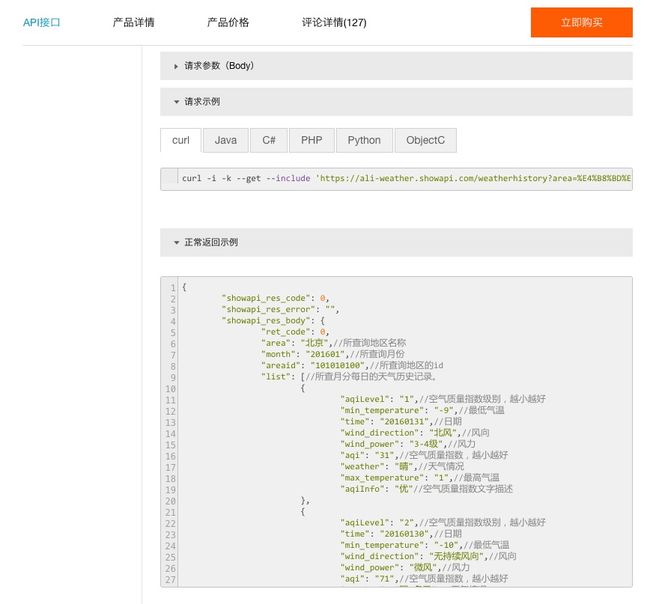
上图中,除了刚才我们使用的 curl ,还包括以下语言访问 API 接口的样例说明:
- Java
- C#
- PHP
- Python
- Object C
我们以 Python 作为例子,点开标签页看看。

你只需要把样例代码全部拷贝下来,用文本编辑器保存为“.py”为扩展名的 Python 脚本文件,例如 demo.py 。
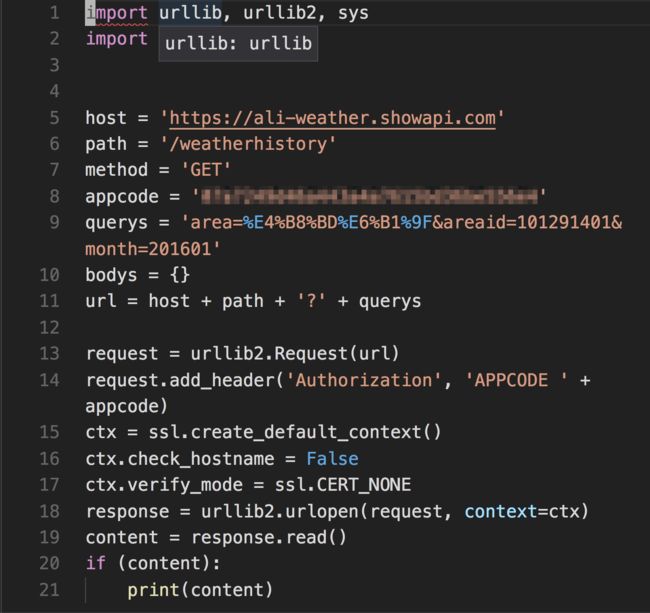
再次提醒,别忘了,把其中“你自己的AppCode”这个字符串,替换为你真实的 AppCode,然后保存。
在终端下,执行:
python demo.py
如果你用的是 2.7 版本的 Python ,就立即可以正确获得结果了。
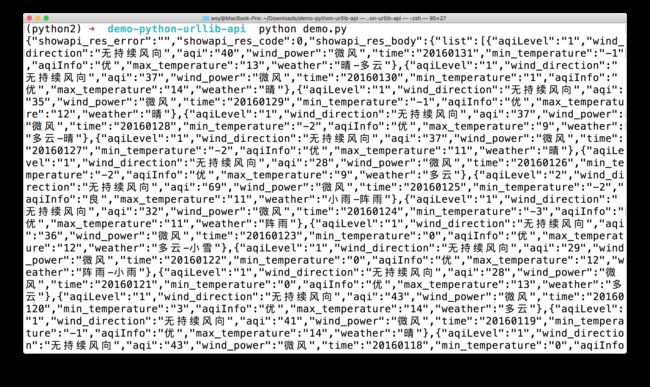
为什么许多学生做不出来结果呢?
我让他们实际跑了一下,发现确实有的学生粗心大意,忘了替换自己的 AppCode 。
但是大部分同学,由于安装最新版本的 Anaconda (Python 3.6版),都遇到了下面的问题:
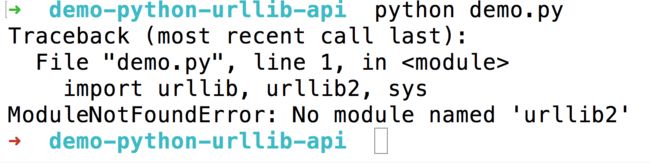
你可能会认为这是因为没有正确安装 urllib2 模块,于是执行
pip install urllib2
你可能会看到下面的报错提示:

你也许尝试去掉版本号,只安装 urllib,即:
pip install urllib
但是结果依然不美妙:

有些 Python 开发者看到这里,可能会嘲笑我们:Python 3版本里面,urllib 被拆分了啊!地球人都知道,你应该……
请保持一颗同理心。
想想一个普通用户,凭什么要了解不同版本 Python 之间的语句差异?凭什么要对这种版本转换的解决方式心里有数?
在他们看来,官方网站提供的样例,就应该是可以运行的。报了错,又不能通过自己的软件包安装“三板斧”来解决,就会慌乱和焦虑。
更进一步,他们也不太了解 JSON 格式。
虽然,JSON已是一种非常清晰的、人机皆可通读的数据存储方式了。
他们想了解的,是怎么把问题迁移到自己能够解决的范围内。
例如说,能否把 JSON 转换成 Excel 形式的数据框?
如果可以,他们就可以调用熟悉的 Excel 命令,来进行数据筛选、分析与绘图了。
他们还会想,假如 Python 本身,能一站式完成数据读取、整理、分析和可视化全流程,那自然更好。
但是,样例,样例在哪里呢?
在我《Python编程遇问题,文科生怎么办?》一文中,我曾经提到过,这种样例,对于普通用户的重要性。
没有“葫芦”,他们又如何“照葫芦画瓢”呢?
既然这个例子中,官方文档没有提供如此详细的代码和讲解样例,那我就来为你绘制个“葫芦”吧。
下面,我给你逐步展示,如何在 Python 3 下,调用该 API 接口,读取、分析数据,和绘制图形。
环境
首先我们来看看代码运行环境。
前面提到过,如果样例代码的运行环境,和你本地的运行环境不一,计时代码本身没问题,也无法正常执行。
所以,我为你构建一个云端代码运行环境。(如果你对这个代码运行环境的构建过程感兴趣,欢迎阅读我的《如何用iPad运行Python代码?》一文。)
请点击这个链接(http://t.cn/R3us4Ao),直接进入咱们的实验环境。
你不需要在本地计算机安装任何软件包。只要有一个现代化浏览器(包括Google Chrome, Firefox, Safari和Microsoft Edge等)就可以了。全部的依赖软件,我都已经为你准备好了。
打开链接之后,你会看见这个页面。
这个界面来自 Jupyter Lab。
图中左侧分栏,是工作目录下的全部文件。
右侧打开的,是咱们要使用的ipynb文件。
根据我的讲解,请你逐条执行,并仔细观察运行结果。
本例中,我们主要会用到以下两个新的软件包。
首先是号称“给人用”(for humans)的HTTP工具包requests。
这款工具,不仅符合人类的认知与使用习惯,而且对 Python 3 更加友好。作者 Kenneth Reitz 甚至在敦促所有的 Python 2 用户,赶紧转移到 Python 3 版本。
The use of Python 3 is highly preferred over Python 2. Consider upgrading your applications and infrastructure if you find yourself still using Python 2 in production today. If you are using Python 3, congratulations — you are indeed a person of excellent taste. —Kenneth Reitz
我们将用到的一款绘图工具,叫做 plotnine 。
它实际上本不是 Python 平台上的绘图工具,而是从 R 平台的 ggplot2 移植过来的。
要知道,此时 Python 平台上,已经有了 matplotlib, seaborn, bokeh, plotly 等一系列优秀的绘图软件包。
那为什么还要费时费力地,移植 ggplot2 过来呢?
因为 ggplot2 的作者,是大名鼎鼎的 R 语言大师级人物 Hadley Wickham 。
他创造 ggplot2,并非为 R 提供另一种绘图工具,而是提供另一种绘图方式。
ggplot2 完全遵守并且实现了 Leland Wilkinson 提出的“绘图语法”(Grammar of Graphics),图像的绘制,从原本的部件拆分,变成了层级拆分。
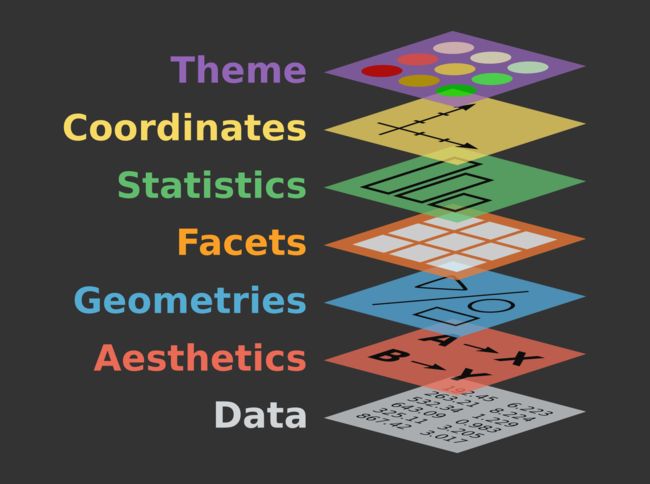
这样一来,数据可视化变得前所未有地简单易学,且功能强大。
我会在后文的“代码”部分,用详细的叙述,为你展示如何使用这两个软件包。
我建议你先完全按照教程跑一遍,运行出结果。
如果一切正常,再将其中的数据,替换为你自己感兴趣的内容。
之后,尝试打开一个空白 ipynb 文件,根据教程和文档,自己敲代码,并且尝试做调整。
这样会有助于你理解工作流程和工具使用方法。
下面我们来看代码。
代码
首先,读入HTTP工具包requests。
import requests
第二句里面,有“Your AppCode here”字样,请把它替换为你自己的AppCode,否则下面运行会报错。
appcode = 'Your AppCode here'
我们尝试获取丽江5月份的天气信息。
在API信息页面上,有城市和代码对应的表格。
位置比较隐蔽,在公司简介的上方。

我把这个 Excel 文档的网址放在了这里(http://t.cn/R3T7e39),你可以直接点击下载。
下载该 Excel 文件后打开,根据表格查询,我们知道“101291401”是丽江的城市代码。

我们将其写入areaid变量。
日期我们选择本文写作的月份,即2018年5月。
areaid = "101291401"
month = "201805"
下面我们就设置一下 API 接口调用相关的信息。
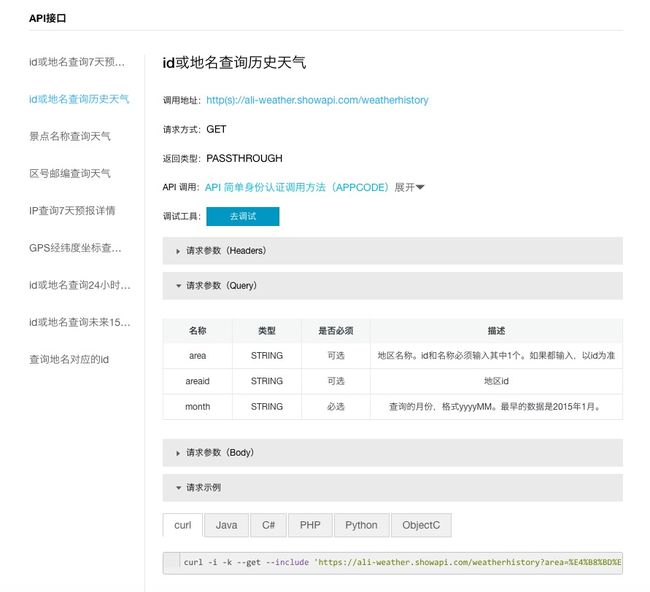
根据API信息页面上的提示,我们的要访问的网址为:https://ali-weather.showapi.com/weatherhistory,需要输入的两个参数,就是刚才已经设置的areaid和month。
另外,我们需要验证身份,证明自己已经付费了。
点击上图中蓝色的“API 简单身份认证调用方法(APPCODE)”,你会看到以下示例页面。

看来我们需要在HTTP数据头(header)中,加入 AppCode。
我们依次把这些信息都写好。
url = 'https://ali-weather.showapi.com/weatherhistory'
payload = {'areaid': areaid, 'month': month}
headers = {'Authorization': 'APPCODE {}'.format(appcode)}
下面,我们就该用 requests 包来工作了。
requests 的语法非常简洁,只需要指定4样内容:
- 调用方法为“GET”
- 访问地址 url
- url中需要附带的参数,即 payload (包含
areaid和month的取值) - HTTP数据头(header)信息,即 AppCode
r = requests.get(url, params=payload, headers=headers)
执行后,好像……什么也没有发生啊!
我们来查看一下:
r
Python 告诉我们:
返回码“200”的含义为访问成功。
回顾一下,《如何用R和API免费获取Web数据?》一文中,我们提到过:
以2开头的状态编码是最好的结果,意味着一切顺利;如果状态值的开头是数字4或者5,那就有问题了,你需要排查错误。
既然调用成功,我们看看 API 接口返回的具体数据内容吧。
调用返回值的 content 属性:
r.content
这一屏幕,密密麻麻的。
其中许多字符,甚至都不能正常显示。这可怎么好?
没关系,从 API 信息页上,我们得知返回的数据,是 JSON 格式。

那就好办了,我们调用 Python 自带的 json 包。
import json
用 json 包的字符串处理功能(loads)解析返回内容,结果存入 content_json。
content_json = json.loads(r.content)
看看 content_json 结果:
content_json
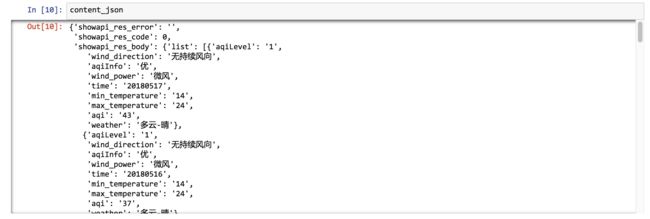
可以看到,返回的信息很完整。而且刚刚无法正常显示的中文,此时也都显现了庐山真面目。
下一步很关键。
我们把真正关心的数据提取出来。
我们不需要返回结果中的错误码等内容。
我们要的,是包含每一天天气信息的列表。
观察发现,这一部分的数据,存储在 'list' 中,而 'list' ,又存储在 'showapi_res_body' 里面
所以,为选定列表,我们需要指定其中的路径:
content_json['showapi_res_body']['list']
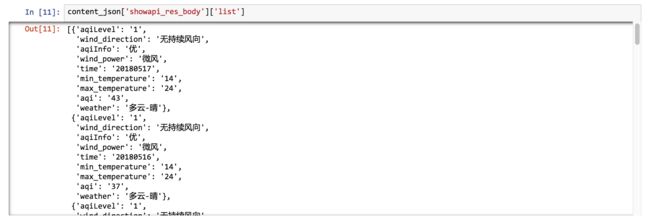
冗余信息都被去掉了,只剩下我们想要的列表。
但是对着一个列表操作,不够方便与灵活。
我们希望将列表转换为数据框。这样分析和可视化就简单多了。
大不了,我们还可以把数据框直接导出为 Excel 文件,扔到熟悉的 Excel 环境里面,去绘制图形。
读入 Python 数据框工具 pandas 。
import pandas as pd
我们让 Pandas 将刚刚保留下来的列表,转换为数据框,存入 df 。
df = pd.DataFrame(content_json['showapi_res_body']['list'])
看看内容:
df
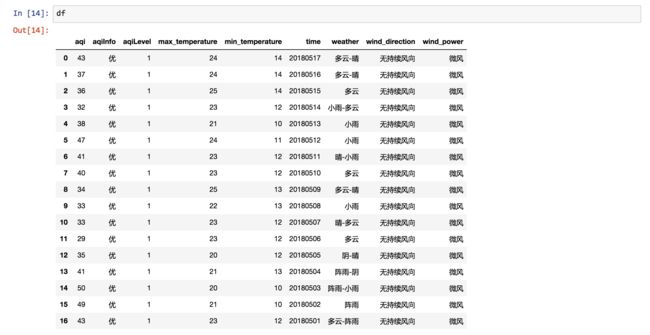
此时,数据显示格式非常工整,各项信息一目了然。
写到这里,你基本上搞懂了,如何读取某个城市、某个月份的数据,并且整理到 Pandas 数据框中。
但是,我们要做分析,显然不能局限在单一月份与单一城市。
每次加入一组数据,如果都得从头这样做一遍,会很辛苦。而且语句多了,执行起来,难免顾此失彼,出现错误。
所以,我们需要把刚刚的代码语句整合起来,将其模块化,形成函数。
这样,我们只需要在调用函数的时候,传入不同的参数,例如不同的城市名、月份等信息,就能获得想要的结果了。
综合上述语句,我们定义一个传入城市和月份信息,获得数据框的完整函数。
def get_df(areaid, areaname_dict, month, appcode):
url = 'https://ali-weather.showapi.com/weatherhistory'
payload = {'areaid': areaid, 'month': month}
headers = {'Authorization': 'APPCODE {}'.format(appcode)}
r = requests.get(url, params=payload, headers=headers)
content_json = json.loads(r.content)
df = pd.DataFrame(content_json['showapi_res_body']['list'])
df['areaname'] = areaname_dict[areaid]
return df
注意除了刚才用到的语句外,我们为函数增加了一个输入参数,即areaname_dict。
它是一个字典,每一项分别包括城市代码,和对应的城市名称。
根据我们输入的城市代码,函数就可以自动在结果数据框中添加一个列,注明对应的是哪个城市。
当我们获取多个城市的数据时,某一行的数据说的是哪个城市,就可以一目了然。
反之,如果只给你看城市代码,你很快就会眼花缭乱,不知所云了。
但是,只有上面这一个函数,还是不够高效。
毕竟我们可能需要查询若干月、若干城市的信息。如果每次都调用上面的函数,也够累的。
所以,我们下面再编写一个函数,帮我们自动处理这些脏活儿累活儿。
def get_dfs(areaname_dict, months, appcode):
dfs = []
for areaid in areaname_dict:
dfs_times = []
for month in months:
temp_df = get_df(areaid, areaname_dict, month, appcode)
dfs_times.append(temp_df)
area_df = pd.concat(dfs_times)
dfs.append(area_df)
return dfs
说明一下,这个函数接受的输入,包括城市代码-名称字典、一系列的月份,以及我们的 AppCode。
它的处理方式,很简单,就是个双重循环。
外层循环负责遍历所有要求查询的城市,内层循环遍历全部指定的时间范围。
它返回的内容,是一个列表。
列表中的每一项,都分别是某个城市一段时间(可能包含若干个月)的天气信息数据框。
我们先用单一城市、单一月份来试试看。
还是2018年5月的丽江。
areaname_dict = {"101291401":"丽江"}
months = ["201805"]
我们将上述信息,传入 get_dfs 函数。
dfs = get_dfs(areaname_dict, months, appcode)
看看结果:
dfs
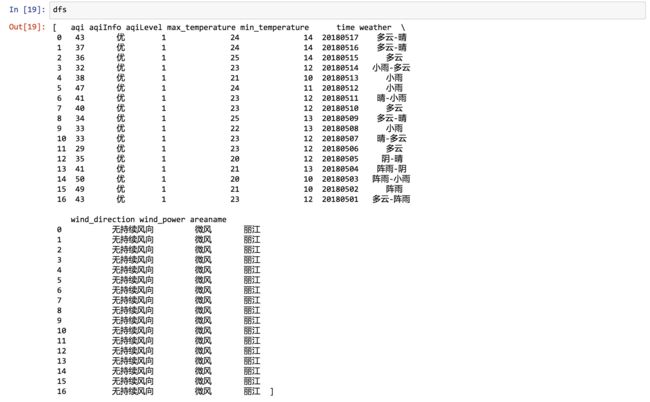
返回的是一个列表。
因为列表里面只有一个城市,所以我们只让它返回第一项即可。
dfs[0]
这次显示的,就是数据框了:
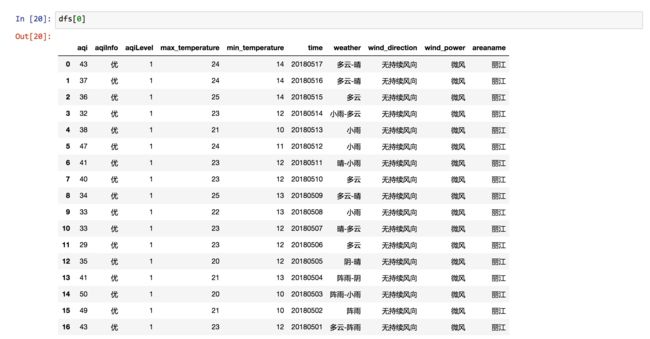
测试通过,下面我们趁热打铁,把天津、上海、丽江2018年初至今所有数据都读取出来。
先设定城市:
areaname_dict = {"101030100":"天津", "101020100":"上海", "101291401":"丽江"}
再设定时间范围:
months = ["201801", "201802", "201803", "201804", "201805"]
咱们再次执行 get_dfs 函数。
dfs = get_dfs(areaname_dict, months, appcode)
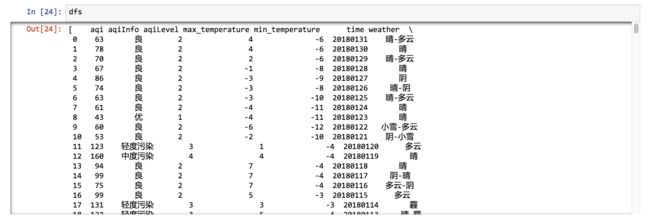
看看这次的结果:
dfs
结果还是一个列表。
列表中的每一项,对应某个城市2018年年初到5月份本文写作时,这一段时间范围天气数据。
假设我们要综合分析几个城市的天气信息,那么就可以把这几个数据框整合在一起。
用到的方法,是 Pandas 内置的 concat 函数。
它接收一个数据框列表,把其中每一个个数据框沿着纵轴(默认)连接在一起。
df = pd.concat(dfs)
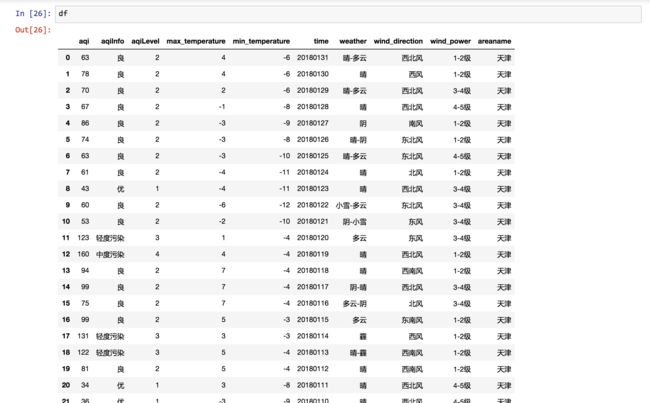
看看此时的总数据框效果:
df
这是开头部分:
这是结尾部分:
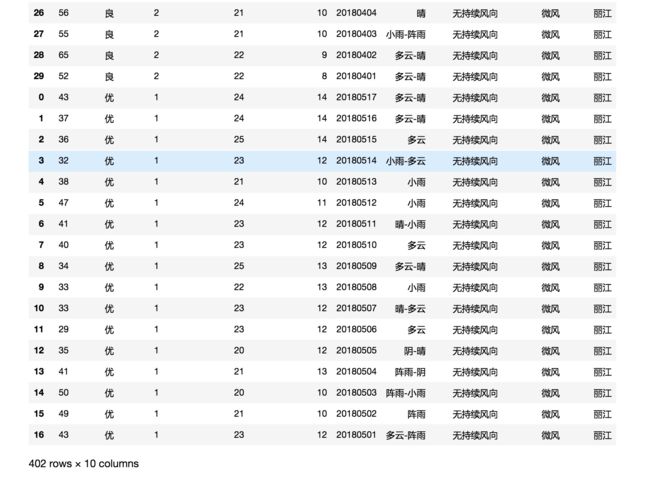
3个城市,4个多月的数据都正确读取和整合了。
下面我们尝试做分析。
首先,我们得搞清楚数据框中的每一项,都是什么格式:
df.dtypes
aqi object
aqiInfo object
aqiLevel object
max_temperature object
min_temperature object
time object
weather object
wind_direction object
wind_power object
areaname object
dtype: object
所有的列,全都是按照 object 处理的。
什么叫 object ?
在这个语境里,你可以将它理解为字符串类型。
但是,咱们不能把它们都当成字符串来处理啊。
例如日期,应该按照日期类型来看待,否则怎么做时间序列可视化?
AQI的取值,如果看作字符串,那怎么比较大小呢?
所以我们需要转换一下数据类型。
先转换日期列:
df.time = pd.to_datetime(df.time)
再转换 AQI 数值列:
df.aqi = pd.to_numeric(df.aqi)
看看此时 df 的数据类型:
df.dtypes
aqi int64
aqiInfo object
aqiLevel object
max_temperature object
min_temperature object
time datetime64[ns]
weather object
wind_direction object
wind_power object
areaname object
dtype: object
这次就对了,日期和 AQI 都分别变成了我们需要的类型。其他数据,暂时保持原样。
有的是因为本来就该是字符串,例如城市名称。
另一些,是因为我们暂时不会用到。
下面我们绘制一个简单的时间序列对比图形。
读入绘图工具包 plotnine 。
注意我们同时读入了 date_breaks,用来指定图形绘制时,时间标注的间隔。
import matplotlib.pyplot as plt
%matplotlib inline
from plotnine import *
from mizani.breaks import date_breaks
正式绘图:
(ggplot(df, aes(x='time', y='aqi', color='factor(areaname)')) + geom_line() +
scale_x_datetime(breaks=date_breaks('2 weeks')) +
xlab('日期') +
theme_matplotlib() +
theme(axis_text_x=element_text(rotation=45, hjust=1)) +
theme(text=element_text(family='WenQuanYi Micro Hei'))
)
我们指定横轴为时间序列,纵轴为 AQI,用不同颜色的线来区分城市。
绘制时间的时候,以“2周”作为间隔周期,标注时间上的数据统计量信息。
我们修改横轴的标记为中文的“日期”。
因为时间显示起来比较长,如果按照默认样式,会堆叠在一起,不好看,所以我们让它旋转45度角,这样避免重叠,一目了然。
为了让图中的中文正常显示,我们需要指定中文字体,这里我们选择的是开源的“文泉驿微米黑”。
数据可视化结果,如下图所示。
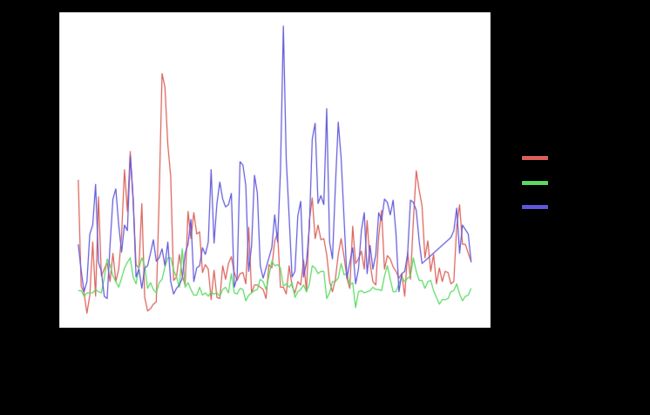
怎么样,这张对比图,绘制得还像模像样吧?
从图中,你可以分析出什么结果呢?
反正我看完这张图,很想去丽江。
小结
读过本教程,希望你已经掌握了以下知识:
- 如何在 API 云市场上,根据提示选购自己感兴趣的产品;
- 如何获取你的身份验证信息 AppCode ;
- 如何用最简单的命令行 curl 方式,直接调用 API 接口,获得结果数据;
- 如何使用 Python 3 和更人性化的 HTTP 工具包 requests 调用 API 获得数据;
- 如何用 JSON 工具包解析处理获得的字符串数据;
- 如何用 Pandas 转换 JSON 列表为数据框;
- 如何将测试通过后的简单 Python 语句打包成函数,以反复调用,提高效率;
- 如何用 plotnine (ggplot2的克隆)绘制时间序列折线图,对比不同城市 AQI 历史走势;
- 如何在云环境中运行本样例,并且照葫芦画瓢,自行修改。
希望这份样例代码,可以帮你建立信心,尝试自己去搜集与尝试 API 数据获取,为自己的科研工作添砖加瓦。
如果你希望在本地,而非云端运行本样例,请使用这个链接(http://t.cn/R3usDi9)下载本文用到的全部源代码和运行环境配置文件(Pipenv)压缩包。
如果你知道如何使用github,也欢迎用这个链接(http://t.cn/R3usEti)访问对应的github repo,进行clone或者fork等操作。
当然,要是能给我的repo加一颗星,就更好了。
讨论
你之前尝试过用 Python 和 API 获取数据吗?你使用了哪些更好用的软件包进行数据获取、处理、分析与可视化呢?你还使用过哪些其他的数据产品市场?欢迎留言,把你的经验和思考分享给大家,我们一起交流讨论。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。