
day06.Hadoop快速入门&云服务三种模式IaaS,PaaS和SaaS【大数据教程】
1. HADOOP背景介绍
1.1 什么是HADOOP
1). HADOOP是apache旗下的一套开源软件平台
2). HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
3). HADOOP的核心组件有
A. HDFS(分布式文件系统)
B. YARN(运算资源调度系统)
C. MAPREDUCE(分布式运算编程框架)
4).广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
1.2 HADOOP产生背景
1). HADOOP最早起源于Nutch。
Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2). 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3). Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
1.3 HADOOP在大数据、云计算中的位置和关系
1).云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
2).现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3).而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
1.4 国内外HADOOP应用案例介绍
1).HADOOP应用于数据服务基础平台建设
2).HADOOP用于用户画像

3).HADOOP用于网站点击流日志数据挖掘

1.5 国内HADOOP的就业情况分析
1).HADOOP就业整体情况
A.大数据产业已纳入国家十三五规划
B.各大城市都在进行智慧城市项目建设,而智慧城市的根基就是大数据综合平台
C.互联网时代数据的种类,增长都呈现爆发式增长,各行业对数据的价值日益重视
D.相对于传统JAVAEE技术领域来说,大数据领域的人才相对稀缺
E.随着现代社会的发展,数据处理和数据挖掘的重要性只会增不会减,因此,大数据技术是一个尚在蓬勃发展且具有长远前景的领域
2).HADOOP就业职位要求
大数据是个复合专业,包括应用开发、软件平台、算法、数据挖掘等,因此,大数据技术领域的就业选择是多样的,但就HADOOP而言,通常都需要具备以下技能或知识:
A. HADOOP分布式集群的平台搭建
B. HADOOP分布式文件系统HDFS的原理理解及使用
C. HADOOP分布式运算框架MAPREDUCE的原理理解及编程
D. Hive数据仓库工具的熟练应用
E. Flume、sqoop、oozie等辅助工具的熟练使用
F. Shell/python等脚本语言的开发能力
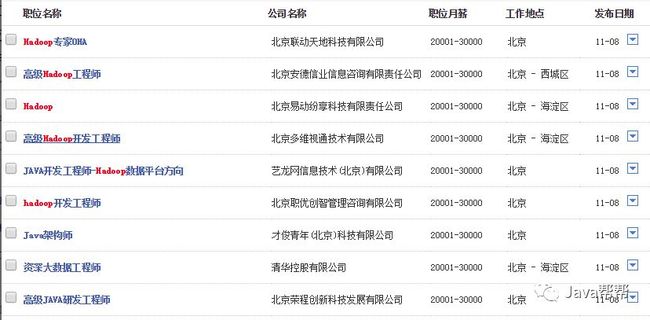
3).HADOOP相关职位的薪资水平
大数据技术或具体到HADOOP的就业需求目前主要集中在北上广深一线城市,薪资待遇普遍高于传统JAVAEE开发人员,以北京为例:
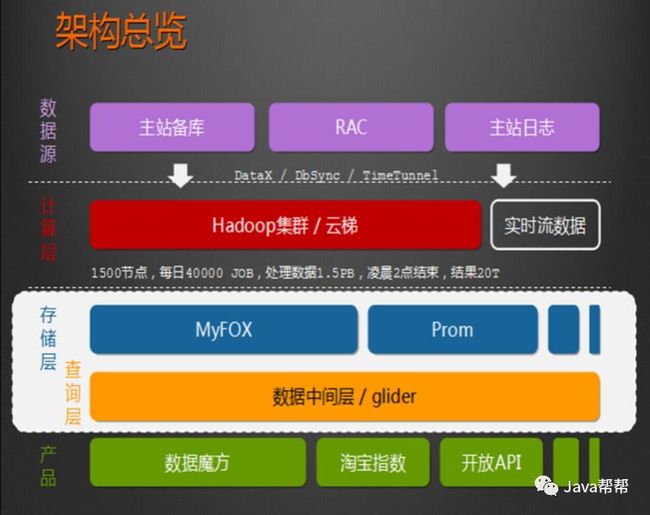
1.6 HADOOP生态圈以及各组成部分的简介
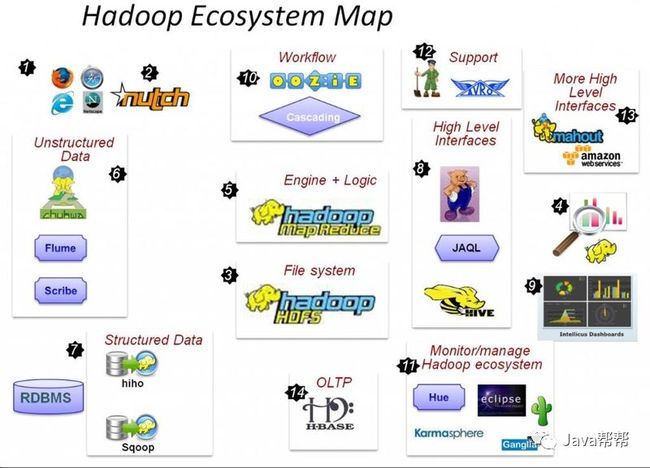
各组件简介
HADOOP(hdfs、MAPREDUCE、yarn)元老级大数据处理技术框架,擅长离线数据分析
Zookeeper分布式协调服务基础组件
Hbase 分布式海量数据库,离线分析和在线业务通吃
Hive sql数据仓库工具,使用方便,功能丰富,基于MR延迟大
Sqoop数据导入导出工具
Flume数据采集框架
重点组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
2 分布式系统概述
注:由于大数据技术领域的各类技术框架基本上都是分布式系统,因此,理解hadoop、storm、spark等技术框架,都需要具备基本的分布式系统概念
2.1 分布式软件系统(Distributed Software Systems)
该软件系统会划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能
比如分布式操作系统、分布式程序设计语言及其编译(解释)系统、分布式文件系统和分布式数据库系统等。
2.2 分布式软件系统举例:solrcloud
A.一个solrcloud集群通常有多台solr服务器
B.每一个solr服务器节点负责存储整个索引库的若干个shard(数据分片)
C.每一个shard又有多台服务器存放若干个副本互为主备用
D.索引的建立和查询会在整个集群的各个节点上并发执行
E. solrcloud集群作为整体对外服务,而其内部细节可对客户端透明
总结:利用多个节点共同协作完成一项或多项具体业务功能的系统就是分布式系统。
2.3 分布式应用系统模拟开发
需求:可以实现由主节点将运算任务发往从节点,并将各从节点上的任务启动;
程序清单:
AppMaster
AppSlave/APPSlaveThread
Task
程序运行逻辑流程:

3. 离线数据分析流程介绍
注:本环节主要感受数据分析系统的宏观概念及处理流程,初步理解hadoop等框架在其中的应用环节,不用过于关注代码细节
一个应用广泛的数据分析系统:“web日志数据挖掘”

3.1 需求分析
3.1.1 案例名称
“网站或APP点击流日志数据挖掘系统”。
一般中型的网站(10W的PV以上),每天会产生1G以上Web日志文件。大型或超大型的网站,可能每小时就会产生10G的数据量。
具体来说,比如某电子商务网站,在线团购业务。每日PV数100w,独立IP数5w。用户通常在工作日上午10:00-12:00和下午15:00-18:00访问量最大。日间主要是通过PC端浏览器访问,休息日及夜间通过移动设备访问较多。网站搜索浏量占整个网站的80%,PC用户不足1%的用户会消费,移动用户有5%会消费。
对于日志的这种规模的数据,用HADOOP进行日志分析,是最适合不过的了。
3.1.2 案例需求描述
“Web点击流日志”包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率、访客的来源信息,访客的终端信息等。
3.1.3 数据来源
本案例的数据主要由用户的点击行为记录
获取方式:在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。
形如:
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
3.2 数据处理流程
3.2.1 流程图解析
本案例跟典型的BI系统极其类似,整体流程如下:
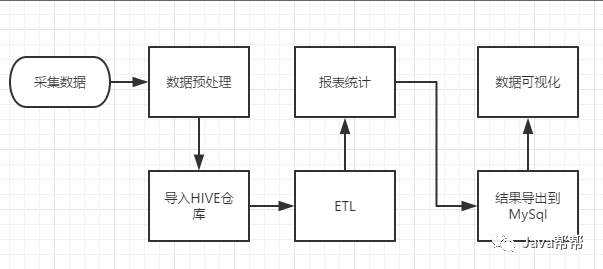
但是,由于本案例的前提是处理海量数据,因而,流程中各环节所使用的技术则跟传统BI完全不同,后续课程都会一一讲解:
1)数据采集:定制开发采集程序,或使用开源框架FLUME
2)数据预处理:定制开发mapreduce程序运行于hadoop集群
3)数据仓库技术:基于hadoop之上的Hive
4)数据导出:基于hadoop的sqoop数据导入导出工具
5)数据可视化:定制开发web程序或使用kettle等产品
6)整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
3.2.2 项目技术架构图
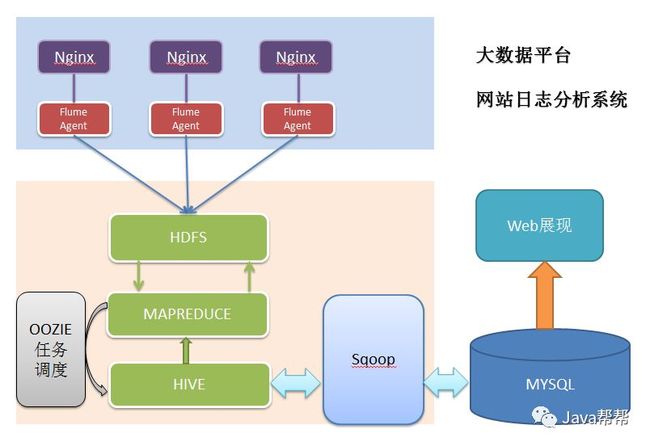
3.2.3 项目相关截图(感性认识,欣赏即可)
a) Mapreudce程序运行
b)在Hive中查询数据

c)将统计结果导入mysql
./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03
3.3 项目最终效果
经过完整的数据处理流程后,会周期性输出各类统计指标的报表,在生产实践中,最终需要将这些报表数据以可视化的形式展现出来,本案例采用web程序来实现数据可视化
效果如下所示:

4. 集群搭建
4.1 HADOOP集群搭建
4.1.1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
本集群搭建案例,以5节点为例进行搭建,角色分配如下:
hdp-node-01 NameNode SecondaryNameNode
hdp-node-02 ResourceManager
hdp-node-03 DataNode NodeManager
hdp-node-04 DataNode NodeManager
hdp-node-05 DataNode NodeManager
部署图如下:

4.1.2服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
Vmware 11.0
Centos 6.5 64bit
4.1.3网络环境准备
采用NAT方式联网
网关地址:192.168.33.1
3个服务器节点IP地址:192.168.33.101、192.168.33.102、192.168.33.103
子网掩码:255.255.255.0
4.1.4服务器系统设置
添加HADOOP用户
为HADOOP用户分配sudoer权限
同步时间
设置主机名
hdp-node-01
hdp-node-02
hdp-node-03
配置内网域名映射:
192.168.33.101 hdp-node-01
192.168.33.102 hdp-node-02
192.168.33.103 hdp-node-03
配置ssh免密登陆
配置防火墙
4.1.5 Jdk环境安装
上传jdk安装包
规划安装目录 /home/hadoop/apps/jdk_1.7.65
解压安装包
配置环境变量 /etc/profile
4.1.6 HADOOP安装部署
上传HADOOP安装包
规划安装目录 /home/hadoop/apps/hadoop-2.6.1
解压安装包
修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/home/hadoop/apps/jdk1.7.0_51
vi core-site.xml
fs.defaultFS
hdfs://hdp-node-01:9000
hadoop.tmp.dir
/home/HADOOP/apps/hadoop-2.6.1/tmp
vi hdfs-site.xml
dfs.namenode.name.dir
/home/hadoop/data/name
dfs.datanode.data.dir
/home/hadoop/data/data
dfs.replication
3
dfs.secondary.http.address
hdp-node-01:50090
vi mapred-site.xml
mapreduce.framework.name
yarn
vi yarn-site.xml
yarn.resourcemanager.hostname
hadoop01
yarn.nodemanager.aux-services
mapreduce_shuffle
vi salves
hdp-node-01
hdp-node-02
hdp-node-03
4.1.7 启动集群
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
4.1.8 测试
1.上传文件到HDFS
从本地上传一个文本文件到hdfs的/wordcount/input目录下
[HADOOP@hdp-node-01 ~]$ HADOOP fs -mkdir -p /wordcount/input
[HADOOP@hdp-node-01 ~]$ HADOOP fs -put /home/HADOOP/somewords.txt /wordcount/input
2.运行一个mapreduce程序
在HADOOP安装目录下,运行一个示例mr程序
cd $HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar mapredcue-example-2.6.1.jar wordcount /wordcount/input /wordcount/output
5 集群使用初步
5.1 HDFS使用
1).查看集群状态
命令: hdfs dfsadmin –report

可以看出,集群共有3个datanode可用
也可打开web控制台查看HDFS集群信息,在浏览器打开http://hdp-node-01:50070/

2).上传文件到HDFS
查看HDFS中的目录信息
命令: hadoop fs –ls /
上传文件
命令: hadoop fs -put ./ scala-2.10.6.tgz to /

从HDFS下载文件
命令: hadoop fs -get /yarn-site.xml

5.2 MAPREDUCE使用
mapreduce是hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序
5.2.1 Demo开发——wordcount
1.需求
从大量(比如T级别)文本文件中,统计出每一个单词出现的总次数
2.mapreduce实现思路
Map阶段:
a) 从HDFS的源数据文件中逐行读取数据
b) 将每一行数据切分出单词
c) 为每一个单词构造一个键值对(单词,1)
d) 将键值对发送给reduce
Reduce阶段:
a) 接收map阶段输出的单词键值对
b) 将相同单词的键值对汇聚成一组
c) 对每一组,遍历组中的所有“值”,累加求和,即得到每一个单词的总次数
d) 将(单词,总次数)输出到HDFS的文件中
3.具体编码实现
(1)定义一个mapper类
//首先要定义四个泛型的类型
//keyin: LongWritable valuein: Text
//keyout: Text valueout:IntWritable
public class WordCountMapper extends Mapper{
//map方法的生命周期: 框架每传一行数据就被调用一次
//key :这一行的起始点在文件中的偏移量
//value: 这一行的内容
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
(2)定义一个reducer类
//生命周期:框架每传递进来一个kv 组,reduce方法被调用一次
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历这一组kv的所有v,累加到count中
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
(3)定义一个主类,用来描述job并提交job
public class WordCountRunner {
//把业务逻辑相关的信息(哪个是mapper,哪个是reducer,要处理的数据在哪里,输出的结果放哪里。。。。。。)描述成一个job对象
//把这个描述好的job提交给集群去运行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
//指定我这个job所在的jar包
// wcjob.setJar("/home/hadoop/wordcount.jar");
wcjob.setJarByClass(WordCountRunner.class);
wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
//设置我们的业务逻辑Mapper类的输出key和value的数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//设置我们的业务逻辑Reducer类的输出key和value的数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class);
//指定要处理的数据所在的位置
FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt");
//指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/"));
//向yarn集群提交这个job
boolean res = wcjob.waitForCompletion(true);
System.exit(res?0:1);
}
5.2.2 程序打包运行
1. 将程序打包
2. 准备输入数据
vi /home/hadoop/test.txt
Hello tom
Hello jim
Hello ketty
Hello world
Ketty tom
在hdfs上创建输入数据文件夹:
hadoop fs mkdir -p /wordcount/input
将words.txt上传到hdfs上
hadoop fs –put /home/hadoop/words.txt /wordcount/input

3. 将程序jar包上传到集群的任意一台服务器上
4. 使用命令启动执行wordcount程序jar包
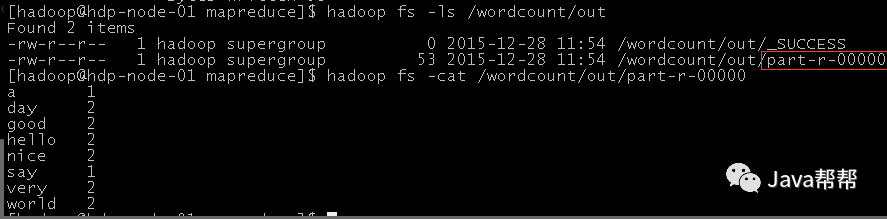
$ hadoop jar wordcount.jar cn.itcast.bigdata.mrsimple.WordCountDriver /wordcount/input /wordcount/out
5. 查看执行结果
$ hadoop fs –cat /wordcount/out/part-r-00000
扩展:
云计算的三种服务模式:IaaS,PaaS和SaaS(公司普遍软件服务模式)
”云服务”现在已经快成了一个家喻户晓的词了。如果你不知道PaaS, IaaS 和SaaS的区别,那么也没啥,因为很多人确实不知道。“云”其实是互联网的一个隐喻,“云计算”其实就是使用互联网来接入存储或者运行在远程服务器端的应用,数据,或者服务。 任何一个使用基于互联网的方法来计算,存储和开发的公司,都可以从技术上叫做从事云的公司。然而,不是所有的云公司都一样。不是所有人都是CTO,所以有时候看到云技术背后的一些词可能会比较头疼。
云也是分层的
任何一个在互联网上提供其服务的公司都可以叫做云计算公司。其实云计算分几层的,分别是
Infrastructure(基础设施)-as-a-Service,
Platform(平台)-as-a-Service,
Software(软件)-as-a-Service。
基础设施在最下端,平台在中间,软件在顶端。别的一些“软”的层可以在这些层上面添加。

IaaS: Infrastructure-as-a-Service(基础设施即服务)
第一层叫做IaaS,有时候也叫做Hardware-as-a-Service,几年前如果你想在办公室或者公司的网站上运行一些企业应用,你需要去买服务器,或者别的高昂的硬件来控制本地应用,让你的业务运行起来。 但是现在有IaaS,你可以将硬件外包到别的地方去。IaaS公司会提供场外服务器,存储和网络硬件,你可以租用。节省了维护成本和办公场地,公司可以在任何时候利用这些硬件来运行其应用。 一些大的IaaS公司包括Amazon, Microsoft, VMWare, Rackspace和Red Hat.不过这些公司又都有自己的专长,比如Amazon和微软给你提供的不只是IaaS,他们还会将其计算能力出租给你来host你的网站。
PaaS: Platform-as-a-Service(平台即服务)
第二层就是所谓的PaaS,某些时候也叫做中间件。你公司所有的开发都可以在这一层进行,节省了时间和资源。PaaS公司在网上提供各种开发和分发应用的解决方案,比如虚拟服务器和操作系统。这节省了你在硬件上的费用,也让分散的工作室之间的合作变得更加容易。网页应用管理,应用设计,应用虚拟主机,存储,安全以及应用开发协作工具等。 一些大的PaaS提供者有Google App Engine,Microsoft Azure,Force.com,Heroku,Engine Yard。最近兴起的公司有AppFog, Mendix和 Standing Cloud
SaaS: Software-as-a-Service(软件即服务)
第三层也就是所谓SaaS。这一层是和你的生活每天接触的一层,大多是通过网页浏览器来接入。任何一个远程服务器上的应用都可以通过网络来运行,就是SaaS了。 你消费的服务完全是从网页如Netflix, MOG, Google Apps, Box.net, Dropbox或者苹果的iCloud那里进入这些分类。尽管这些网页服务是用作商务和娱乐或者两者都有,但这也算是云技术的一部分。 一些用作商务的SaaS应用包括Citrix的GoToMeeting,Cisco的WebEx,Salesforce的CRM,ADP,Workday和SuccessFactors。
Iaas和Paas之间的比较
PaaS的主要作用是将一个开发和运行平台作为服务提供给用户,而IaaS的主要作用是提供虚拟机或者其他资源作为服务提供给用户。接下来,将在七个方面对PaaS和IaaS进行比较:
1) 开发环境:PaaS基本都会给开发者提供一整套包括IDE在内的开发和测试环境,而IaaS方面用户主要还是沿用之前比较熟悉那套开发环境,但是因为之前那套开发环境在和云的整合方面比较欠缺,所以使用起来不是很方便。 2) 支持的应用:因为IaaS主要是提供虚拟机,而且普通的虚拟机能支持多种操作系统,所以IaaS支持的应用的范围是非常广泛的。但如果要让一个应用能跑在某个PaaS平台不是一件轻松的事,因为不仅需要确保这个应用是基于这个平台所支持的语言,而且也要确保这个应用只能调用这个平台所支持的API,如果这个应用调用了平台所不支持的API,那么就需要对这个应用进行修改。3) 开放标准:虽然很多IaaS平台都存在一定的私有功能,但是由于OVF等协议的存在,使得IaaS在跨平台和避免被供应商锁定这两面是稳步前进的。而PaaS平台的情况则不容乐观,因为不论是Google的App Engine,还是Salesforce的Force.com都存在一定的私有API。 4) 可伸缩性:PaaS平台会自动调整资源来帮助运行于其上的应用更好地应对突发流量。而IaaS平台则需要开发人员手动对资源进行调整才能应对。 5) 整合率和经济性:PaaS平台整合率是非常高,比如PaaS的代表Google App Engine能在一台服务器上承载成千上万的应用,而普通的IaaS平台的整合率最多也不会超过100,而且普遍在10左右,使得IaaS的经济性不如PaaS。 6) 计费和监管:因为PaaS平台在计费和监管这两方面不仅达到了IaaS平台所能企及的操作系统层面,比如,CPU和内存的使用量等,而且还能做到应用层面,比如,应用的反应时间(Response Time)或者应用所消耗的事务多少等,这将提高计费和管理的精确性。 7) 学习难度:因为在IaaS上面开发和管理应用和现有的方式比较接近,而PaaS上面开发则有可能需要学一门新的语言或者新的框架,所以IaaS学习难度更低。
PaaSIaaS
开发环境完善普通
支持的应用有限广
通用性欠缺稍好
可伸缩性自动伸缩手动伸缩
整合率和经济性高整合率,更经济低整合率
计费和监管精细简单
学习难度略难低
表1. PaaS和IaaS之间的比较
未来的PK
在当今云计算环境当中,IaaS是非常主流的,无论是Amazon EC2还是Linode或者Joyent等,都占有一席之地,但是随着Google的App Engine,Salesforce的Force.com还是微软的Windows Azure等PaaS平台的推出,使得PaaS也开始崭露头角。谈到这两者的未来,特别是这两者之间的竞争关系,我个人认为,短期而言,因为IaaS模式在支持的应用和学习难度这两方面的优势,使得IaaS将会在短期之内会成为开发者的首选,但是从长期而言,因为PaaS模式的高整合率所带来经济型使得如果PaaS能解决诸如通用性和支持的应用等方面的挑战,它将会替代IaaS成为开发者的“新宠”。
