记得以前做题库的时候 根据 学校 学年 学期 学科 根据分库 分表 解决不同分类 的题库 增删改 从关系型数据库中维护数据 汇合的业务json数据 同步到 nosql 比如mogodb 读取从mogodb读取 减轻查的负载
若单纯从关系型数据库 设计架构
当涉及到分库来支撑高并发的请求,大量分表保证每个表的数据量别太大,读写分离实现主库和从库按需扩容
结合自己公司的业务和项目来考虑自己的系统如何做分库分表应该怎么做
具体的分库分表落地的时候,需要借助数据库中间件来实现分库分表和读写分离
对于日单量50万的订单表 从单表结构设计上 没有好的方法能解决
问题的本质 需要如何看待要描述嗯问题 而不局限于那一点上 如何解决问题
对于订单 单表数据量越来越大 若 每天单表新增50万条数据,一个月就多1500万条数据,一年下来单表会达到上亿条数据。
在高峰期请求现在是每秒1万 系统可以做微服务集群部署 解决平均每台机器每秒支撑一千以内的请求
数据库层面 如何解决呢
到数据库层面每秒上万的并发请求应该如何来支撑?
单从单表字段结构设计想是死胡同 应该从数据库并发 负载量考虑问题 怎么实现数据分流 才是正路
对于普通服务器 一般让其每秒请求支撑 控制在2000 左右 负载相对合理
解决 方案如下
首先第一步,就是在上万并发请求的场景下,部署个5台服务器,每台服务器上都部署一个数据库实例。
然后每个数据库实例里,都创建一个一样的库,比如说订单库。
此时在5台服务器上都有一个订单库,名字可以类似为:db_order_01,db_order_02,等等
然后每个订单库里,都有一个相同的表 那么此时5个订单库里都有一个订单信息表。
比如db_order_01库里就有一个tb_order_01表,db_order_02库里就有一个tb_order_02表。
这就实现了一个基本的分库分表的思路,原来的一台数据库服务器支撑变成了5台数据库服务器,原来的一个库变成了5个库,原来的一张表变成了5个表。
然后你在写入数据的时候,需要借助数据库中间件,比如sharding-jdbc,或者是mycat,都可以。
可以根据比如订单id来hash后按5个库取模,比如每天订单表新增50万数据,此时其中10万条数据会落入db_order_01库的tb_order_01表,另外10万条数据会落入db_order_02库的tb_order_02表,以此类推。
这样就可以把数据均匀分散在5台服务器上了,查询的时候,也可以通过订单id来hash取模,去对应的服务器上的数据库里,从对应的表里查询那条数据出来。
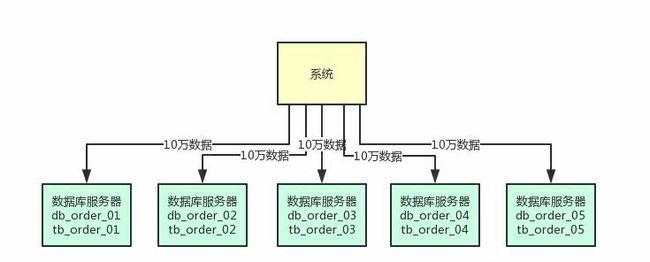
原来比如订单表就一张表,这个时候不就成了5张表了么,那么每个表的数据就变成1/5了。
假设订单表一年有1亿条数据,此时5张表里每张表一年就2000万数据了
每天新增50万数据的话,那么每个表才新增10万数据,这样初步缓解了单表数据量过大 带来的性能问题
最后 回来原先来问题 每秒1万请求到5台数据库上,每台数据库就承载每秒2000请求
若一年一亿的量 ,每个库还是有两千万 还是数据量太大
还应该继续分表,大量分表。
比如可以把订单表动态创建拆分为1024张表,这样1亿数据量的话,分散到每个表里也就才10万量级的数据量,然后这上千张表分散在5台数据库里就可以了。
在写入数据的时候,需要做两次路由,先对订单id hash后对数据库的数量取模,可以路由到一台数据库上,然后再对那台数据库上的表数量取模,就可以路由到数据库上的一个表里了
通过这个步骤,就可以让每个表里的数据量非常小,每年1亿数据增长,但是到每个表里才10万条数据增长,这个系统运行10年,每个表里可能才百万级的数据量
这样可以一次性为系统未来的运行做好充足的准备

大量分表的策略保证可能未来10年,每个表的数据量都不会太大,这可以保证单表内的SQL执行效率和性能。
然后多台数据库的拆分方式,可以保证每台数据库服务器承载一部分的读写请求,降低每台服务器的负载。
不得不考虑一个问题 假如说每台数据库服务器承载每秒2000的请求,然后其中400请求是写入,1600请求是查询。
增删改的SQL才占到了20%的比例,80%的请求是查询。
这时候 数据库一般都支持读写分离,也就是做主从架构。
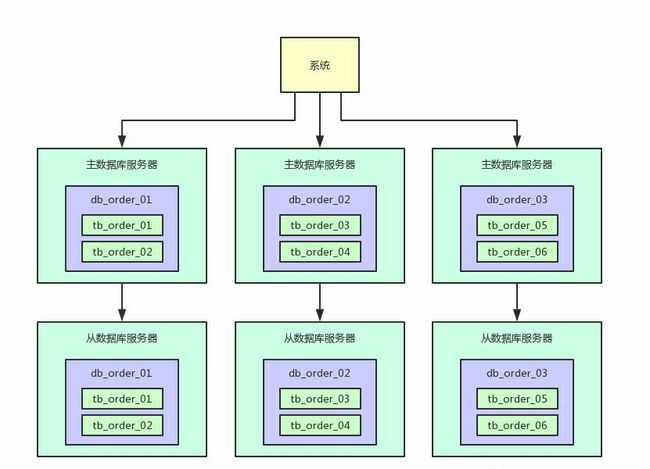
写入的时候写入主数据库服务器,查询的时候读取从数据库服务器,就可以让一个表的读写请求分开落地到不同的数据库上去执行。
这样的话,假如写入主库的请求是每秒400,查询从库的请求是每秒1600
写入主库的时候,会自动同步数据到从库上去,保证主库和从库数据一致。
然后查询的时候都是走从库去查询的,这就通过数据库的主从架构实现了读写分离的效果了
现在的好处就是,假如说现在主库写请求增加到800,这个无所谓,不需要扩容。然后从库的读请求增加到了3200,需要扩容了。
这时,你直接给主库再挂载一个新的从库就可以了,两个从库,每个从库支撑1600的读请求,不需要因为读请求增长来扩容主库。
实际上线上生产你会发现,读请求的增长速度远远高于写请求,所以读写分离之后,大部分时候就是扩容从库支撑更高的读请求就可以了
对同一个表,如果你既写入数据(涉及加锁),还从该表查询数据,可能会牵扯到锁冲突等问题
所以一旦读写分离之后,对主库的表就仅仅是写入,没任何查询会影响他,对从库的表就仅仅是查询。