作者:许梦洁 (编译) (知乎 | | 码云)
Stata连享会 计量专题 || 精品课程 || 推文 || 公众号合集

2020寒假Stata现场班 (北京, 1月8-17日,连玉君-江艇主讲),「+助教招聘」

Source: Ashish Rajbhandari → Vector autoregression—simulation, estimation, and inference in Stata
Stata VAR 专题:
- Stata: VAR (向量自回归) 模型简介
- Stata: VAR - 模拟、估计和推断
- Stata: 协整还是伪回归?
-
help svarih// estimates structural VARs, identified through heteroskedasticity (IH), for three different methods: Bacchiocchi (2011), Bacciocchi/Fanelli (2012), and Lanne/Lutkepohl (2008).
VAR 是分析多维时间序列动态变化的利器,该模型设定为由一组时间序列组成的序列是其自己滞后项的函数。
1. 模拟
首先使用如下设定模拟双变量 VAR(2) :
其中 是在时间 的观测变量, 是一个 的截距项向量, 和 均为 的参数矩阵, 是不与时间相关的扰动项。我假设 服从分布 ,其中 是一个 的协方差矩阵。
设定样本量为 1000 ,并在 Stata 中生成需要的变量:
clear all
. set seed 2016
. local T = 1100
. set obs `T'
number of observations (_N) was 0, now 1,100
. gen time = _n
. tsset time
time variable: time, 1 to 1100
delta: 1 unit
. generate y1 = .
(1,100 missing values generated)
. generate y2 = .
(1,100 missing values generated)
. generate eps1 = .
(1,100 missing values generated)
. generate eps2 = .
(1,100 missing values generated)
在第 1-6 行,我设定了随机种子,将样本量设为 1000,并且生成了一个时间变量 time 。接下来,我生成了变量 y1 ,y2 , eps1 和 eps2 来存放观测序列和扰动项。
2. 设定系数值
我为本文的 VAR(2) 模型选择了如下的参数值:
. mata:
------------------------------------------------- mata (type end to exit) -----
: mu = (0.1\0.4)
: A1 = (0.6,-0.3\0.4,0.2)
: A2 = (0.2,0.3\-0.1,0.1)
: Sigma = (1,0.5\0.5,1)
: end
-------------------------------------------------------------------------------
在 Mata 中,我分别创建了矩阵 , , 和 来放置参数值。在模拟得到样本之前,我检查了由这些参数值是否会得到一个平稳的 VAR(2) 模型。令:
其中 是 的识别矩阵, 是一个每个元素均为 0 的 矩阵。如果矩阵 F 的所有特征根均小于 1 ,则此 VAR(2) 过程即为一个平稳过程。下面放上计算特征根的代码:
. mata:
------------------------------------------------- mata (type end to exit) -----
: K = p = 2 // K = number of variables; p = number of lags
: F = J(K*p,K*p,0)
: F[1..2,1..2] = A1
: F[1..2,3..4] = A2
: F[3..4,1..2] = I(K)
: X = L = .
: eigensystem(F,X,L)
: L'
1
+----------------------------+
1 | .858715598 |
2 | -.217760515 + .32727213i |
3 | -.217760515 - .32727213i |
4 | .376805431 |
+----------------------------+
: end
------------------------------------------------------------------------------
我根据之前的设定创建了矩阵 F 并使用函数 eigensystem( ) 计算其特征根。 矩阵 X 中存储了特征向量,L 中保存特征根。所有 L 中的特征根均小于 1 ,因此该 VAR(2) 过程是平稳的。在检验过是否平稳之后,接下来生成 VAR(2) 模型的扰动项。
连享会计量方法专题……
3. 由多维正态分布中生成扰动项
我从分布 中生成两个随机正态变量,并将它们分别赋值给变量 eps1 和 eps2。
. mata:
------------------------------------------------- mata (type end to exit) -----
: T = strtoreal(st_local("T"))
: u = rnormal(T,2,0,1)*cholesky(Sigma)
: epsmat = .
: st_view(epsmat,.,"eps1 eps2")
: epsmat[1..T,.] = u
: end
-------------------------------------------------------------------------------
我将样本规模(在 Stata 中定义为一个局部宏变量 T )赋值给一个 Mata 数值变量,这步将可以简化之后的工作。在 Mata 中,我使用了两个函数:st_local( ) 和 strtoreal( ) 来存储样本大小。第一个函数可以从 Stata 宏中获取文本值,第二个函数则可以将文本值转变为实数值。
第二行生成了一个 的正态扰动项矩阵,其每个元素都服从分布 。我使用函数 st_view( ) 将生成的正态扰动项存放到变量 eps1 和 eps2 中。这个函数会以目前 Stata 中的数据集创建一个矩阵。首先,我创建了一个空矩阵 epsmat ,然后将变量 eps1 和 eps2 填入到该矩阵中。最后,我使用矩阵 epsmat 的前 T 行位置来存储 u 中的数据。
3. 生成观测序列
沿用 Lütkepohl(2005) 的做法,我先生成了前两个观测值并使得它们的相关性与余下的样本一致。我假设前两项服从一个二维联合正态分布,其无条件期望为 ,其协方差矩阵满足:
其中 是一个计算矩阵列数的算子, 是一个 的识别矩阵,
是一个 的矩阵。观测的前两项于是被生成为:
其中 Q 是一个 的矩阵,满足 , 是 的矩阵,其每个元素为服从标准正态分布的扰动项, 则为 的期望矩阵。
下面的代码展示了如何生成前两个观测并给变量 y1 和 y2 赋值的过程:
. mata:
------------------------------------------------- mata (type end to exit) -----
: Sigma_e = J(K*p,K*p,0)
: Sigma_e[1..K,1..K] = Sigma
: Sigma_y = luinv(I((K*p)^2)-F#F)*vec(Sigma_e)
: Sigma_y = rowshape(Sigma_y,K*p)'
: theta = luinv(I(K)-A1-A2)*mu
: Q = cholesky(Sigma_y)*rnormal(K*p,1,0,1)
: data = .
: st_view(data,.,"y1 y2")
: data[1..p,.] = ((Q[3..4],Q[1..2]):+mu)'
: end
-------------------------------------------------------------------------------
生成前两个观测后,我们可以使用如下的代码生成余下的序列:
. forvalues i=3/`T' {
. qui {
. replace y1 = 0.1 + 0.6*l.y1 - 0.3*l.y2 + 0.2*l2.y1 + 0.3*l2.y2 + eps1 in `i'
. replace y2 = 0.4 + 0.4*l.y1 + 0.2*l.y2 - 0.1*l2.y1 + 0.1*l2.y2 + eps2 in `i'
. }
. }
. drop in 1/100
(100 observations deleted)
我在 replace 命令后加入了 quietly 选项来筛选掉不必要显示的输出结果。最后,我删掉了前 100 个观测来避免模拟效果受到初值的影响。
4. 估计
我使用 var 命令来拟合 VAR(2) 模型;
. var y1 y2
Vector autoregression
Sample: 103 - 1100 Number of obs = 998
Log likelihood = -2693.949 AIC = 5.418735
FPE = .7733536 HQIC = 5.43742
Det(Sigma_ml) = .7580097 SBIC = 5.467891
Equation Parms RMSE R-sq chi2 P>chi2
----------------------------------------------------------------
y1 5 1.14546 0.5261 1108.039 0.0000
y2 5 .865602 0.4794 919.1433 0.0000
----------------------------------------------------------------
------------------------------------------------------------------------------
| Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
y1 |
y1 |
L1. | .5510793 .0324494 16.98 0.000 .4874797 .614679
L2. | .2749983 .0367192 7.49 0.000 .20303 .3469667
|
y2 |
L1. | -.3080881 .046611 -6.61 0.000 -.3994439 -.2167323
L2. | .2551285 .0425803 5.99 0.000 .1716727 .3385844
|
_cons | .1285357 .0496933 2.59 0.010 .0311387 .2259327
-------------+----------------------------------------------------------------
y2 |
y1 |
L1. | .3890191 .0245214 15.86 0.000 .340958 .4370801
L2. | -.0190324 .027748 -0.69 0.493 -.0734175 .0353527
|
y2 |
L1. | .1944531 .035223 5.52 0.000 .1254172 .263489
L2. | .0459445 .0321771 1.43 0.153 -.0171215 .1090106
|
_cons | .4603854 .0375523 12.26 0.000 .3867843 .5339865
------------------------------------------------------------------------------
var 命令在估计模型系数时默认为两阶滞后,参数估计是显著的并且与用来生成两个序列的参数真实值接近。
5. 推断:脉冲响应函数
脉冲响应函数 (IRF) 可以用来分析 VAR 模型中的内生变量如何对扰动项的冲击进行反应。比如,在由通胀和利率组成的双变量 VAR 模型中,脉冲响应函数可以追踪来自通胀方程的外生冲击如何对利率造成影响。
考虑最开始提到的双变量模型,假如我想估计一单位 的变动对系统中的内生变量会造成怎样的冲击。我可以将 VAR(2) 过程通过数学变换变形为 MA() 过程:
其中 是 MA() 过程系数矩阵的的第 p 阶滞后。根据Lütkepohl(2005),MA 系数矩阵与 AR 过程的系数矩阵有如下联系:
也就是说,第 个变量在未来 期对第 个方程在时点 的单位冲击作出的反应为:
该式意味着第 个变量在未来 期对第 个方程在时点 的单位冲击作出的反应为 MA() 过程系数矩阵中第 行 列的元素值。对于 VAR(2) 过程,使用估计 AR 参数得到的前若干个反应值为:
对于 时 的响应使用类似的递归即可得到,第一个方程的冲击对第一个变量的影响为向量。我使用 irf create 命令来得到脉冲影响的结果:
. irf create firstirf, set(myirf)
(file myirf.irf created)
(file myirf.irf now active)
(file myirf.irf updated)
这个命令估计了 firstirf 模型中的脉冲响应函数和其他的统计量,并存储在文件 myirf.irf 中。选项 set( ) 将文件名为 myirf.irf 的文件激活。我可以在表格中列示来自同一方程扰动项的外生冲击对 的影响:
. irf table irf, impulse(y1) response(y1) noci
Results from firstirf
+--------------------+
| | (1) |
| step | irf |
|--------+-----------|
|0 | 1 |
|1 | .551079 |
|2 | .458835 |
|3 | .42016 |
|4 | .353356 |
|5 | .305343 |
|6 | .263868 |
|7 | .227355 |
|8 | .196142 |
+--------------------+
(1) irfname = firstirf, impulse = y1, and response = y1
默认的期数为 8 期,我加入 noci 选项选择不显示置信区间。注意 Stata 算出的前几期响应结果与我之前手动算的结果非常接近。带 95% 置信带的脉冲响应函数图如下:
. irf graph irf, impulse(y1) response(y1)
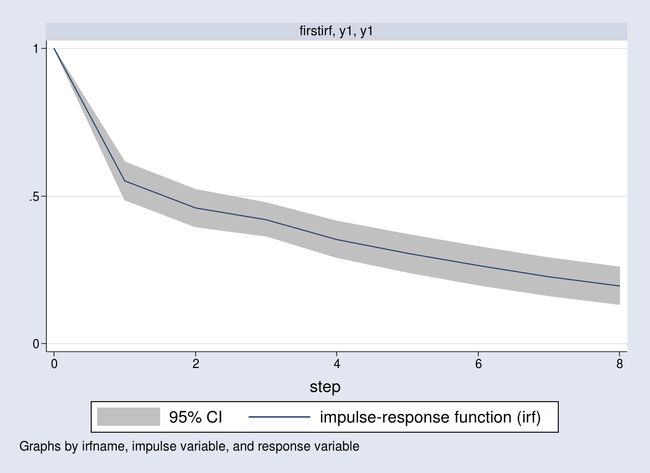
由上图可知,来自同一方程的一单位冲击将使 立即增加一个单位,然后在中长期随着时间逐渐衰减。
6. 正交化的脉冲响应函数
在前面的部分中,我展示了其他条件不变时,来自同一方程的一单位冲击对 造成的影响。然而,如下表所示,方差-协方差矩阵 显示了两个等式之间较强的正相关关系。
. matrix list e(Sigma)
symmetric e(Sigma)[2,2]
y1 y2
y1 1.3055041
y2 .4639629 .74551376
两个等式的估计协方差是正的,这意味着我不能假设一个扰动项变动而另一个扰动项保持不变。来自 方程的冲击会对 造成同期影响,反之亦然。
正交脉冲响应函数 (OIRF) 通过将估计方差-协方差矩阵 分解为一个下三角矩阵来解决此问题。这种类型的分解可以将来自同一方程的冲击对 的同期影响分离出来。然而,来自第一个方程的冲击依然会同期影响 。比如,如果 是通胀而 是利率,这个分解意味着通胀的冲击会同时影响通胀和利率,但是来自利率的冲击则只会影响利率。
为了估计 OIRFs,令 P 表示 的 Cholesky 分解,即满足 。令 表示一个 的向量使得 ,也即是 。 中的误差与构造不相关,因为 。这允许我们将 OIRFs 解读为来自 的一个标准差的外生冲击造成的影响。
重写以 向量表示的 MA() 过程:
OIRFs 则为 MA 过程的系数矩阵与下三角矩阵 P 的积:
通过以下代码得到 的估计:
. matrix Sigma_hat = e(Sigma)
. matrix P_hat = cholesky(Sigma_hat)
. matrix list P_hat
P_hat[2,2]
y1 y2
y1 1.1425866 0
y2 .40606367 .76198823
使用这个矩阵,我可以计算前若干期的响应:
我将所有的 OIRFs 列示在一个表格中并画出了 y1 的脉冲响应图:
. irf table oirf, noci
Results from firstirf
+--------------------------------------------------------+
| | (1) | (2) | (3) | (4) |
| step | oirf | oirf | oirf | oirf |
|--------+-----------+-----------+-----------+-----------|
|0 | 1.14259 | .406064 | 0 | .761988 |
|1 | .504552 | .523448 | -.23476 | .148171 |
|2 | .534588 | .294977 | .019384 | -.027504 |
|3 | .476019 | .279771 | -.0076 | .013468 |
|4 | .398398 | .242961 | -.010024 | -.00197 |
|5 | .346978 | .206023 | -.003571 | -.003519 |
|6 | .299284 | .178623 | -.004143 | -.001973 |
|7 | .257878 | .154023 | -.003555 | -.002089 |
|8 | .222533 | .13278 | -.002958 | -.001801 |
+--------------------------------------------------------+
(1) irfname = firstirf, impulse = y1, and response = y1
(2) irfname = firstirf, impulse = y1, and response = y2
(3) irfname = firstirf, impulse = y2, and response = y1
(4) irfname = firstirf, impulse = y2, and response = y2
irf table oirf 要求输出 OIRFs 的结果。注意前三行的估计结果与我们之前手算的结果相同。
. irf graph oirf, impulse(y1) response(y1)
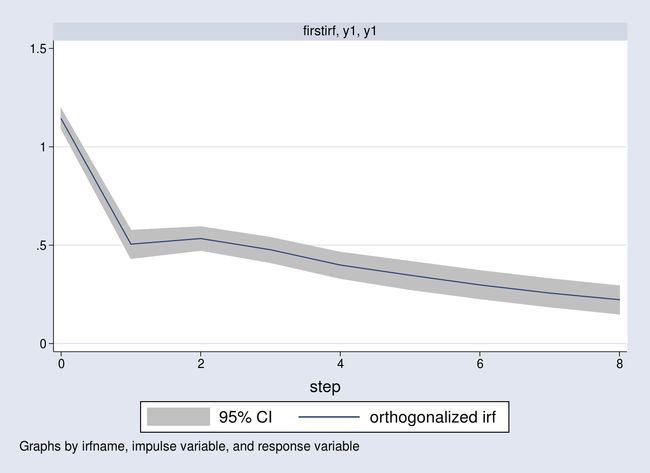
上图即为 y1 对来自同一个方程的一个单位的冲击的脉冲响应图。
结论
在这篇推文中,我展示了怎么模拟一个平稳的 VAR(2) 模型,使用 var 命令估计了这个模型的参数,展示了如何估计 IRFs 和 OIRFs ,其中 OIRFs 由对协方差矩阵的下三角分解得到。
参考文献
Lütkepohl, H. 2005. New Introduction to Multiple Time Series Analysis. New York: Springer.
关于我们
- Stata连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。
- 推文同步发布于 CSDN 、 和 知乎Stata专栏。可在百度中搜索关键词 「Stata连享会」查看往期推文。
- 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- 欢迎赐稿: 欢迎赐稿。录用稿件达 三篇 以上,即可 免费 获得一期 Stata 现场培训资格。
- E-mail: [email protected]
- 往期精彩推文:一网打尽
