第一课Hadoop生态圈与Zookeeper应用实践
一)相关原理以及知识点
1.什么是分布式系统
《分布式系统概念与设计》一书定义分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间通过消息传递进行通信和协调的系统
[if !supportLists]2.[endif]脑裂
集群整体提供服务,但是由于各种网络原因,分裂成小单元提供同样的服务。
3.Zookeeper简介
一个开源的针对大型分布式系统的可靠协调系统,将复杂且容易出错的分布式式一致性服务,封装起来,构成一个高效可靠的原语集,并以简单易用的接口提供给用户使用。
4.Zookeeper特性
最终一致性
保证最终数据能够达到一致,这是Zookeeper最重要的功能。
Ø顺序性
从同一个客户端发起的事务请求,最终会严格地按照其发送顺序被应用到Zookeeper中。
Ø可靠性
一旦服务器成功的应用一个事务,并完成了客户端的响应,那么该事
务所引起的服务端状态变更将会被一直保留下去。
实时性
Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
原子性:
一次数据更新要么成功,要么失败。
Ø 单一视图:
无论客户端连接到哪个服务器,看到的数据模型都是一致的。
[if !supportLists]5.[endif]zookeeper角色
Leader更新系统状态,处理事务请求,负责进行投票的发起和决议
Leaner Follower处理客户端非事务请求并向客户端返回结果,将写事务请求转发给Leader,同步Leader的状态,选主过程中参与投票。
Observer接收客户端读请求,将客户端写请求转发给Leader,不参与投票过程,只同步Leader的状态。目的是为了扩展系统,提高读取速度。
Client请求发起方。
6.Zookeeper写入
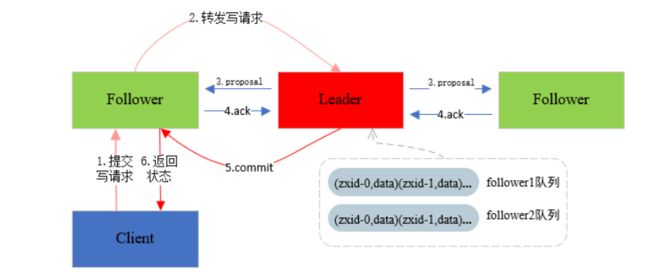
当集群中的任何一个follower节点接收到客户端的事务请求,都会转发给leader,也就是说整个集群只有leader可以处理事务请求,其它角色的节点都不能处理,当leader处理事务请求的时候,就要向整个集群广播一个提议,这个提议就是告诉follower你们要创建/修改/删除一个znode,然后follower接收到leader的提议之后,就会做相应的操作,操作完成告诉leader完成了。当leader接收到集群中的大多数follower的成功操作的回复之后,这里的大多数指的是超过集群机器数量的一半,当收到大多数follower的回复之后,leader就认为这次事务被成功处理了,然后再向集群通知所有的follower提交事务,最后会返回给客户端一个事务被成功处理的状态。如果有落后的follower,这些落后的follower也会从leader同步状态,保持与leader的状态一致。
7.Zookeeper选举
服务器四种状态:
•LOOKING:寻找Leader状态,处于该状态需要进入选举流程
•LEADING:领导者状态,表明当前服务角色为Leader
•FOLLOWING:跟随者状态,Leader已经选举出来,表明当前服务角色为Follower
•OBSERVER:观察者状态,表明当前服务角色Observer事务ID:用ZXID表示,是一个64位的数字,由Leader统一分配,全局唯一,不断递增。
8.关于全新启动期间的leader选举过程

在前zk1和zk2启动的时候,两个节点都会发出广播当leader,他们发出的广播信息内容是(myid,ZXID),由于是全新启动期ZXID是0
zk1的myid是1,zk2的myid是2,所以zk1和zk2发出的广播消息分别是(1,0)和(2,0),在zk1和zk2分别接受到对方发出的选举广播消息的时候,首先对比消息中的ZXID,谁的ZXID大谁就优先作为leader,由于全新启动期间ZXID都是0,继续进行下一步比较,比较myid,谁的myid大谁优先作为laeder,很明显zk2的myid大,所以zk1会重新发出选举的信息选zk2作为leader,然后zk2自己也选自己作为leader,集群中已经有两个选了zk2作为leader,所以zk2当选为leader,都选出zk2是leader了,zk3再启动的时候发现zk2已经是leader了,那zk3自认为自己就是follower
9.Zookeeper选举(运行期间)
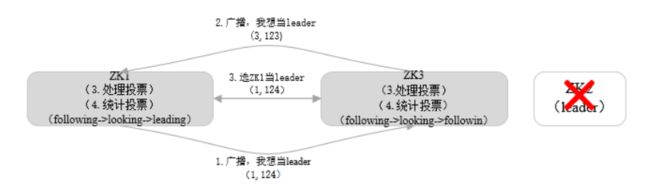
当集群中的leader zk2挂掉之后,所有的follower将自己的状态调整为looking状态,集群进入选举阶段。先比较ZXID。如图所示zk1和zk3发出广播。Zk1的ZXID大于zk3,zk3会选zk1为leader,然后zk1自己也选自己作为leader.所以zk1为leader
10.数据模型Znode
•Zookeeper特有的数据节点Znode,视图结构类似
Linux文件系统,没有目录和文件的概念
•Znode是Zookeeper中数据的最小单元
•Znode上可以保存数据,通过挂载子节点构成一个
树状的层次化命名空间
•Znode树的根由“/”斜杠开始
11.znode版本
版本类型
•dataVersion:当前数据节点数据内容的版本号
•cVersion:当前数据节点子节点的版本号
•aVersion:当前数据节点ACL权限变更版本号
如何保证分布式数据原子性操作
• 悲观锁
• 乐观锁
• 使用version实现乐观锁机制中的“写入校验”
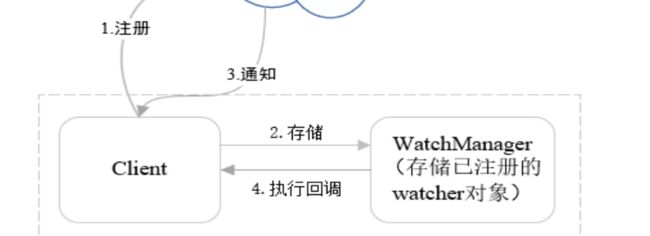
12.Znode - Watcher机制
二.其它的重点
1. znode是zookeeper中的一个数据节点,znode下还可以创建子znode,可以理解为文件夹的构造,一个文件夹下可以有子文件夹或者子文件。
2.心跳的意思是从节点周期性的向leader发送消息,比如2秒钟发送一次消息,这种有规律的通信就叫做心跳
3.临时节点下是不能创建子节点
4.znode不对应机器
5.zookeeper提供了一种存储系统。这个存储系统里存储的是znode的树形结构
6.每一个znode就是一个数据节点,znode可以存数据,也可以实现类似文件夹的功能,就是znode下可以创建子znode
7.leader和follower分别在单独的机器上部署。
8.整个集群会选举出一个leader,这个leader负责处理客户端的事务请求,事务请求包括znode的创建、修改、删除等,follower负责处理客户端的读请求。
11整个zookeeper集群只有一个leader负责事务处理,每次接收到一个事务处理请求,就会生成一个全局唯一,自动递增的事务ID
三)Zookeeper搭建与常用操作
1)安装过程
1.安装zookeeper-3.4.10.tar.gz
2.root创建软连接,修改zookeeper软链接属主为hadoop
ln -s /home/hadoop/apps/zookeeper-3.4.10 /usr/local/zookeeper
chown -R hadoop:hadoop /usr/local/zookeeper
3.root编辑环境变量
vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin
4.重新编译环境变量
source /etc/profile
5.切换到addop用户
su hadoop
6..修改zookeeper配置文件
cd /usr/local/zookeeper/conf
拷贝样例配置文件并重命名zoo.cfg
cp zoo_sample.cfg zoo.cfg

编辑zoo.cfg文件
vim zoo.cfg
添加内容
dataDir=/usr/local/zookeeper/data #快照文件存储目录
dataLogDir=/usr/local/zookeeper/log #事务日志文件目录
#注意node01、node02、node03是安装zookeeper的主机名,根据自己的虚拟机自行修改
server.1=node01:2888:3888 (主机名,心跳端口、数据端口)
server.2=node02:2888:3888
server.3=node03:2888:3888
7.创建data、log目录,只有hadoop用户具有写权限
在/usr/local/zookeeper目录下创建
mkdir -m 755 data
mkdir -m 755 log
8.在data文件夹下新建myid文件,myid的文件内容为该节点的编号
cd data
创建myid文件
touch myid
添加编号1
echo 1 > myid
9.通过scp将安装包拷贝到其他两个节点hadoop02和hadoop03的/home/hadoop/apps目录下scp -r /home/hadoop/apps/zookeeper-3.4.10 hadoop@hadoop02:/home/hadoop/apps
scp -r /home/hadoop/apps/zookeeper-3.4.10 hadoop@hadoop03:/home/hadoop/apps
分别创软链接并且添加环境变量,注意要配置SSH免密码登录
10.修改其他节点的myid
hadoop02的myid文件内容是2
hadoop03的myid文件内容是3
11.启动
/usr/local/zookeeper/bin/zkServer.sh start

Hadoop01
/usr/local/zookeeper/bin/zkServer.sh start

Hadoop02
/usr/local/zookeeper/bin/zkServer.sh start

Hadoop03
查看zk状态
zkServer.sh status

Hadoop01
zkServer.sh status

Hadoop02
zkServer.sh status

Hadoop03
关闭命令
/usr/local/zookeeper/bin/zkServer.sh stop
2)注意事项
1.用root创建软连接时,要修改软链接属主为hadoop用户,避免后边hadoop没有权限
2.ssh免密码登入(root和haddop用户)注意用切换到hadoop用户的时候拷贝到其它的节点,也要用hadoop用户启动,注意用户权限。
Root用户在/root/.ssh下执行ssh-keygen -t rsa
Hadoop用户(普通用户)/home/hadoop/.ssh下执行ssh-keygen -t rsa
通过ssh-copy-id命令将hadoo01这台机器root用户的公钥文件(id_rsa.pub)文件内容拷贝到hadoop02和hadoo03两台机器