
前言
- 习惯用
Json、XML数据存储格式的你们,相信大多都没听过Protocol Buffer -
Protocol Buffer其实 是Google出品的一种轻量 & 高效的结构化数据存储格式,性能比Json、XML真的强!太!多!
由于
Protocol Buffer已经具备足够的吸引力
- 今天,我将详细介绍
Protocol Buffer的语法 & 如何去构建Protocol Buffer的消息模型
阅读本文前请先阅读:
- 快来看看Google出品的Protocol Buffer,别只会用Json和XML了
- 手把手教你如何安装Protocol Buffer
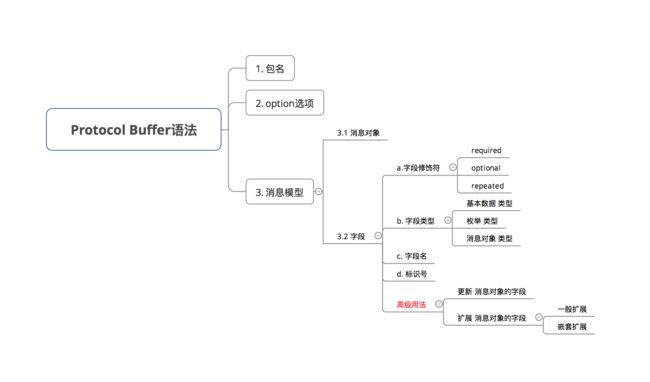
目录
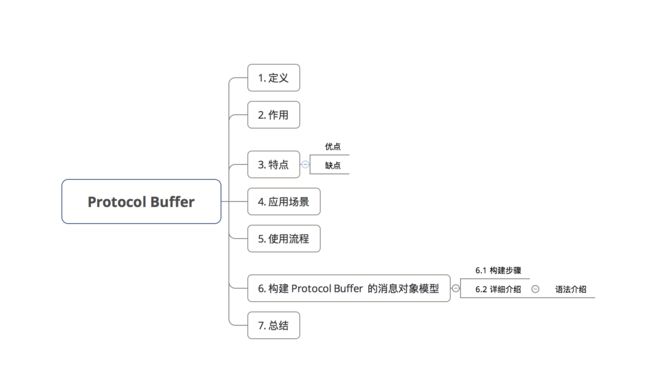
1. 定义
一种 结构化数据 的数据存储格式(类似于 XML、Json )
Protocol Buffer目前有两个版本:proto2和proto3- 因为
proto3还是beta 版,所以本次讲解是proto2
2. 作用
通过将 结构化的数据 进行 串行化(序列化),从而实现 数据存储 / RPC 数据交换的功能
- 序列化: 将 数据结构或对象 转换成 二进制串 的过程
- 反序列化:将在序列化过程中所生成的二进制串 转换成 数据结构或者对象 的过程
3. 特点
- 对比于 常见的
XML、Json数据存储格式,Protocol Buffer有如下特点:

4. 应用场景
传输数据量大 & 网络环境不稳定 的数据存储、RPC 数据交换 的需求场景
如 即时IM (QQ、微信)的需求场景
总结
在 传输数据量较大的需求场景下,Protocol Buffer比XML、Json 更小、更快、使用 & 维护更简单!
5. 使用流程
- 使用
Protocol Buffer的流程如下:
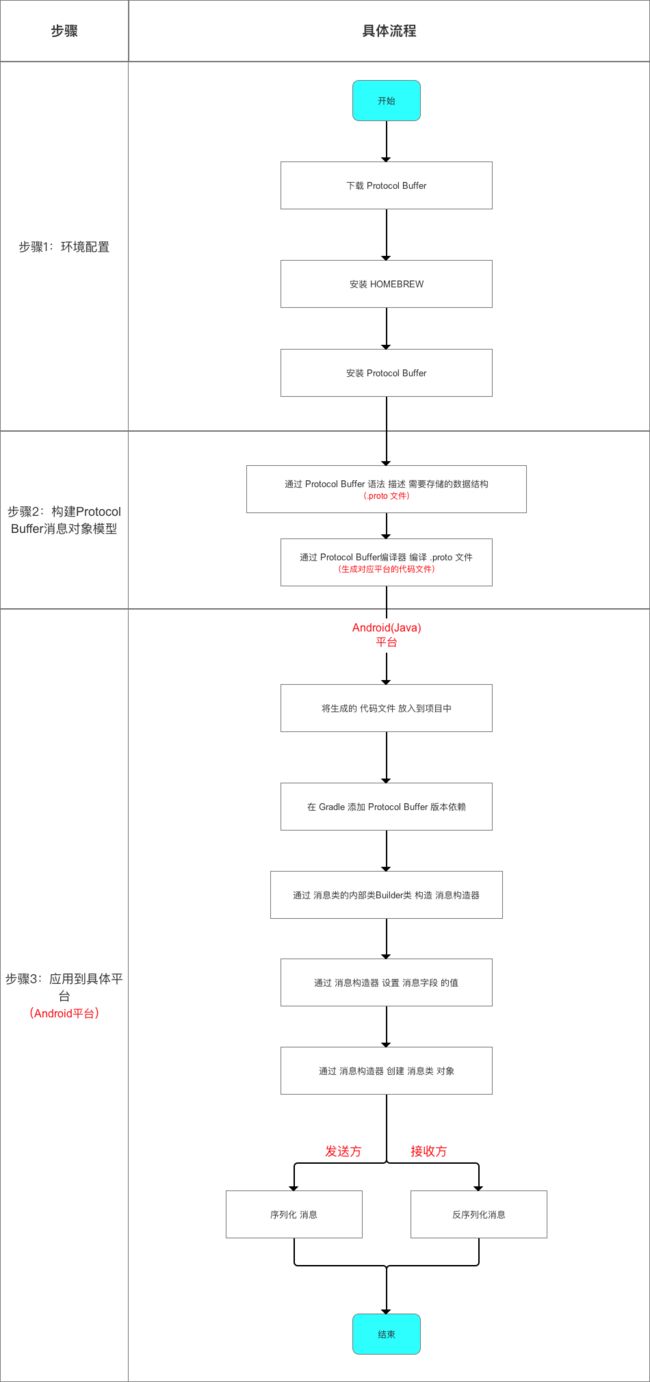
- 今天主要讲解该如何构建
Protocol Buffer的消息对象模型,即详细讲解Protocol Buffer的语法
6. 构建Protocol Buffer 的消息对象模型
6.1 构建步骤
下面将通过一个实例(Android(Java) 平台为例)详细介绍每个步骤。
6.2 详细介绍
- 实例说明:构建一个
Person类的数据结构,包含成员变量name、id、email等等
// Java类
public class Person
{
private String name;
private Int id;
private String email;
...
}
- 平台使用:以
Android(Java)平台为例来进行演示
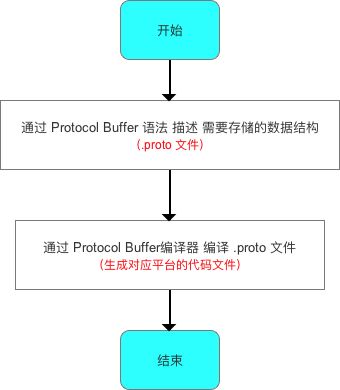
步骤1:通过 Protocol Buffer 语法 描述 需要存储的数据结构
- 新建一个文件,命名规则为:文件名 = 类名,后缀为
.proto
此处叫
Demo.proto

- 根据上述数据结构的需求,在
Demo.proto里 通过Protocol Buffer语法写入对应.proto对象模型的代码,如下:
package protocobuff_Demo;
// 关注1:包名
option java_package = "com.carson.proto";
option java_outer_classname = "Demo";
// 关注2:option选项
// 关注3:消息模型
// 下面详细说明
// 生成 Person 消息对象(包含多个字段,下面详细说明)
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}
- 下面将结合 上述例子 对
Protocol Buffer语法 进行详细介绍
关注1:包名
package protocobuff_Demo;
// 关注1:包名
- 作用:防止不同
.proto项目间命名 发生冲突 -
Protocol buffer包的解析过程如下:-
Protocol buffer的类型名称解析与C++一致:从 最内部 开始查找,依次 向外 进行
-
每个包会被看作是其父类包的内部类
-
Protocol buffer编译器会解析.proto文件中定义的所有类型名 - 生成器会根据 不同语言 生成 对应语言 的代码文件
a. 即对 不同语言 使用了 不同的规则 进行处理
b.Protoco Buffer提供C++、Java、Python三种语言的 API
关注2:Option选项
option java_package = "com.carson.proto";
option java_outer_classname = "Demo";
// 关注2:option选项
- 作用:影响 特定环境下 的处理方式
但不改变整个文件声明的含义
- 常用Option选项如下:
option java_package = "com.carson.proto";
// 定义:Java包名
// 作用:指定生成的类应该放在什么Java包名下
// 注:如不显式指定,默认包名为:按照应用名称倒序方式进行排序
option java_outer_classname = "Demo";
// 定义:类名
// 作用:生成对应.java 文件的类名(不能跟下面message的类名相同)
// 注:如不显式指定,则默认为把.proto文件名转换为首字母大写来生成
// 如.proto文件名="my_proto.proto",默认情况下,将使用 "MyProto" 做为类名
option optimize_for = ***;
// 作用:影响 C++ & java 代码的生成
// ***参数如下:
// 1. SPEED (默认)::protocol buffer编译器将通过在消息类型上执行序列化、语法分析及其他通用的操作。(最优方式)
// 2. CODE_SIZE::编译器将会产生最少量的类,通过共享或基于反射的代码来实现序列化、语法分析及各种其它操作。
// 特点:采用该方式产生的代码将比SPEED要少很多, 但是效率较低;
// 使用场景:常用在 包含大量.proto文件 但 不追求效率 的应用中。
//3. LITE_RUNTIME::编译器依赖于运行时 核心类库 来生成代码(即采用libprotobuf-lite 替代libprotobuf)。
// 特点:这种核心类库要比全类库小得多(忽略了 一些描述符及反射 );编译器采用该模式产生的方法实现与SPEED模式不相上下,产生的类通过实现 MessageLite接口,但它仅仅是Messager接口的一个子集。
// 应用场景:移动手机平台应用
option cc_generic_services = false;
option java_generic_services = false;
option py_generic_services = false;
// 作用:定义在C++、java、python中,protocol buffer编译器是否应该 基于服务定义 产生 抽象服务代码(2.3.0版本前该值默认 = true)
// 自2.3.0版本以来,官方认为通过提供 代码生成器插件 来对 RPC实现 更可取,而不是依赖于“抽象”服务
optional repeated int32 samples = 4 [packed=true];
// 如果该选项在一个整型基本类型上被设置为真,则采用更紧凑的编码方式(不会对数值造成损失)
// 在2.3.0版本前,解析器将会忽略 非期望的包装值。因此,它不可能在 不破坏现有框架的兼容性上 而 改变压缩格式。
// 在2.3.0之后,这种改变将是安全的,解析器能够接受上述两种格式。
optional int32 old_field = 6 [deprecated=true];
// 作用:判断该字段是否已经被弃用
// 作用同 在java中的注解@Deprecated
- 在
ProtocolBuffers中允许 自定义选项 并 使用 - 该功能属于高级特性,使用频率很低,此处不过多描述。有兴趣可查看官方文档
关注3:消息模型
- 作用:真正用于描述 数据结构
// 消息对象用message修饰
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}
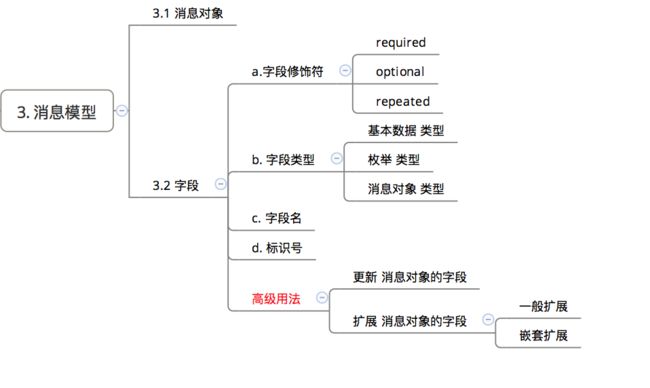
- 组成:在
ProtocolBuffers中:- 一个
.proto消息模型 = 一个.proto文件 = 消息对象 + 字段 - 一个消息对象(
Message) = 一个 结构化数据 - 消息对象(
Message)里的 字段 = 结构化数据 里的成员变量
- 一个

下面会详细介绍 .proto 消息模型里的 消息对象 & 字段
1. 消息对象
在 ProtocolBuffers 中:
- 一个消息对象(
Message) = 一个 结构化数据 - 消息对象用 修饰符
message修饰 - 消息对象 含有 字段:消息对象(
Message)里的 字段 = 结构化数据 里的成员变量
特别注意:
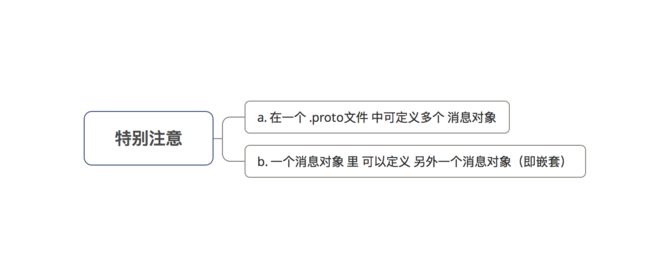
a. 添加:在一个 .proto文件 中可定义多个 消息对象
- 应用场景:尽可能将与 某一消息类型 对应的响应消息格式 定义到相同的
.proto文件 中 - 实例:
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page = 3;
}
// 与SearchRequest消息类型 对应的 响应消息类型SearchResponse
message SearchResponse {
…
}
b. 一个消息对象 里 可以定义 另外一个消息对象(即嵌套)
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
// 该消息类型 定义在 Person消息类型的内部
// 即Person消息类型 是 PhoneNumber消息类型的父消息类型
message PhoneNumber {
required string number = 1;
}
}
<-- 多重嵌套 -->
message Outer { // Level 0
message MiddleAA { // Level 1
message Inner { // Level 2
required int64 ival = 1;
optional bool booly = 2;
}
}
}
2. 字段
- 消息对象的字段 组成主要是:字段 = 字段修饰符 + 字段类型 +字段名 +标识号
- 下面将对每一项详细介绍
a. 字段修饰符
- 作用:设置该字段解析时的规则
- 具体类型如下:

b. 字段类型
字段类型主要有 三 类:
- 基本数据 类型
- 枚举 类型
- 消息对象 类型
message Person {
// 基本数据类型 字段
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
optional PhoneType type = 2 [default = HOME];
// 枚举类型 字段
}
repeated PhoneNumber phone = 4;
// 消息类型 字段
}
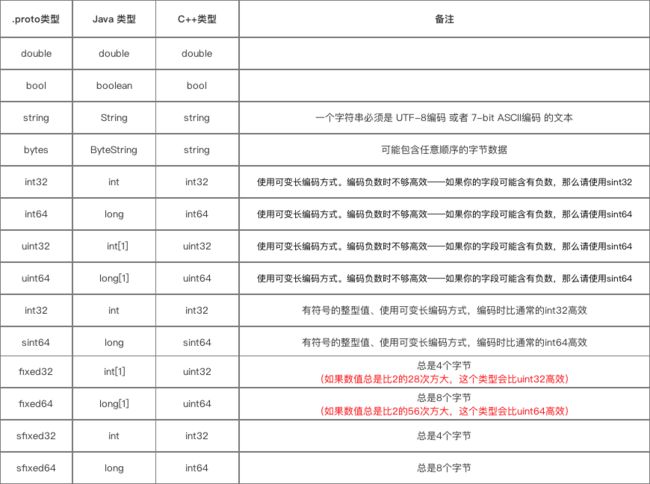
1. 基本数据类型
.proto基本数据类型 对应于 各平台的基本数据类型如下:
2. 枚举类型
- 作用:为字段指定一个 可能取值的字段集合
该字段只能从 该指定的字段集合里 取值
- 说明:如下面例子,电话号码 可能是手机号、家庭电话号或工作电话号的其中一个,那么就将
PhoneType定义为枚举类型,并将加入电话的集合(MOBILE、HOME、WORK)
// 枚举类型需要先定义才能进行使用
// 枚举类型 定义
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
// 电话类型字段 只能从 这个集合里 取值
}
// 特别注意:
// 1. 枚举类型的定义可在一个消息对象的内部或外部
// 2. 都可以在 同一.proto文件 中的任何消息对象里使用
// 3. 当枚举类型是在一消息内部定义,希望在 另一个消息中 使用时,需要采用MessageType.EnumType的语法格式
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
// 使用枚举类型的字段(设置了默认值)
}
// 特别注意:
// 1. 枚举常量必须在32位整型值的范围内
// 2. 不推荐在enum中使用负数:因为enum值是使用可变编码方式的,对负数不够高
额外说明
当对一个 使用了枚举类型的.proto文件 使用 Protocol Buffer编译器编译时,生成的代码文件中:
- 对
Java 或 C++来说,将有一个对应的enum文件 - 对
Python来说,有一个特殊的EnumDescriptor类
被用来在运行时生成的类中创建一系列的整型值符号常量(symbolic constants)
3. 消息对象 类型
一个消息对象 可以将 其他消息对象类型 用作字段类型,情况如下:

3.1 使用同一个 .proto 文件里的消息类型
a. 使用 内部消息类型
- 目的:先在 消息类型 中定义 其他消息类型 ,然后再使用
即嵌套,需要 用作字段类型的 消息类型 定义在 该消息类型里
- 实例:
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
// 该消息类型 定义在 Person消息类型的内部
// 即Person消息类型 是 PhoneNumber消息类型的父消息类型
message PhoneNumber {
required string number = 1;
}
repeated PhoneNumber phone = 4;
// 直接使用内部消息类型
}
b. 使用 外部消息类型
即外部重用,需要 用作字段类型的消息类型 定义在 该消息类型外部
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
}
message AddressBook {
repeated Person person = 1;
// 直接使用了 Person消息类型作为消息字段
}
c. 使用 外部消息的内部消息类型
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
// PhoneNumber消息类型 是 Person消息类型的内部消息类型
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
}
// 若父消息类型外部的消息类型需要重用该内部消息类型
// 需要以 Parent.Type 的形式去使用
// Parent = 需要使用消息类型的父消息类型,Type = 需要使用的消息类型
// PhoneNumber父消息类型Person 的外部 OtherMessage消息类型 需要使用 PhoneNumber消息类型
message OtherMessage {
optional Person.PhoneNumber phonenumber = 1;
// 以 Parent.Type = Person.PhoneNumber 的形式去使用
}
3.2 使用不同 .proto 文件里的消息类型
- 目的:需要在
A.proto文件 使用B.proto文件里的消息类型 - 解决方案:在
A.proto文件 通过导入(import)B.proto文件中来使用B.proto文件 里的消息类型
import "myproject/other_protos.proto"
// 在A.proto 文件中添加 B.proto文件路径的导入声明
// ProtocolBuffer编译器 会在 该目录中 查找需要被导入的 .proto文件
// 如果不提供参数,编译器就在 其调用的目录下 查找
当然,在使用 不同 .proto 文件里的消息类型 时 也会存在想 使用同一个 .proto 文件消息类型的情况,但使用都是一样,此处不作过多描述。
3.3 将 消息对象类型 用在 RPC(远程方法调用)系统
- 解决方案:在
.proto文件中定义一个RPC服务接口,Protocol Buffer编译器会根据所选择的不同语言平台 生成服务接口代码 - 由于使用得不多,此处不作过多描述,具体请看该文档
c. 字段名
该字段的名称,此处不作过多描述。
d. 标识号
- 作用:通过二进制格式唯一标识每个字段
- 一旦开始使用就不能够再改变
- 标识号使用范围:[1,2的29次方 - 1]
- 不可使用 [19000-19999] 标识号, 因为
Protobuf协议实现中对这些标识号进行了预留。假若使用,则会报错
-
编码占有内存规则:
每个字段在进行编码时都会占用内存,而 占用内存大小 取决于 标识号:- 范围 [1,15] 标识号的字段 在编码时占用1个字节;
- 范围 [16,2047] 标识号的字段 在编码时占用2个字节
-
使用建议
- 为频繁出现的 消息字段 保留 [1,15] 的标识号
- 为将来有可能添加的、频繁出现的 消息字段预留 [1,15] 标识号
关于 字段 的高级用法

1. 更新消息对象 的字段
- 目的:为了满足新需求,需要更新 消息类型 而不破坏已有消息类型代码
即新、老版本需要兼容
- 更新字段时,需要符合下列规则:
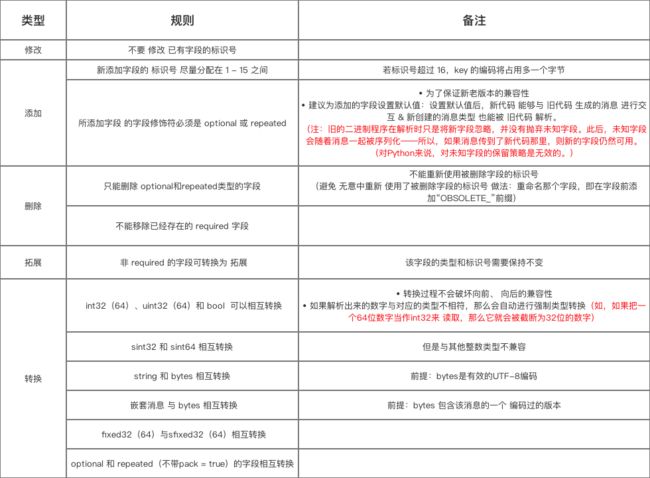
2. 扩展消息对象 的字段
- 作用:使得其他人可以在自己的
.proto文件中为 该消息对象 声明新的字段而不必去编辑原始文件
- 注:扩展 可以是消息类型也可以是字段类型
- 以下以 扩展 消息类型 为例
A.proto
message Request {
…
extensions 100 to 199;
// 将一个范围内的标识号 声明为 可被第三方扩展所用
// 在消息Request中,范围 [100,199] 的标识号被保留为扩展用
// 如果标识号需要很大的数量时,可以将可扩展标符号的范围扩大至max
// 其中max是2的29次方 - 1(536,870,911)。
message Request {
extensions 1000 to max;
// 注:请避开[19000-19999] 的标识号,因为已被Protocol Buffers实现中预留
}
现在,其他人 就可以在自己的 .proto文件中 添加新字段到Request里。如下:
B.proto
extend Request {
optional int32 bar = 126;
// 添加字段的 标识号必须要在指定的范围内
// 消息Request 现在有一个名为 bar 的 optional int32 字段
// 当Request消息被编码时,数据的传输格式与在Request里定义新字段的效果是完全一样的
// 注:在同一个消息类型中一定要确保不会扩展新增相同的标识号,否则会导致数据不一致;可以通过为新项目定义一个可扩展标识号规则来防止该情况的发生
}
- 要访问 扩展字段 的方法与 访问普通的字段 不同:使用专门的扩展访问函数
- 实例:
// 如何在C++中设置 bar 值
Request request;
request.SetExtension(bar, 15);
// 类似的模板函数 HasExtension(),ClearExtension(),GetExtension(),MutableExtension(),以及 AddExtension()
// 与对应的普通字段的访问函数相符
嵌套的扩展
可以在另一个 消息对象里 声明扩展,如:
message Carson {
extend Request {
optional int32 bar = 126;
}
…
}
// 访问此扩展的C++代码:
Request request;
request.SetExtension(Baz::bar, 15);
- 对于嵌套的使用,一般的做法是:在扩展的字段类型的范围内定义该扩展
- 实例:一个 Request 消息对象需要扩展(扩展的字段类型是Car 消息类型),那么,该扩展就定义在 Car消息类型 里:
message Car {
extend Request {
optional Car request_ext = 127;
// 注:二者并没有子类、父类的关系
}
}
- 至此,
Protoco Buffer的语法已经讲解完毕 - 关于如何根据需求 通过
Protoco Buffer语法 去构建 数据结构 相信大家已经非常熟悉了。 - 在将
.proto文件保存后,进入下一个步骤
步骤2:通过 Protocol Buffer 编译器 编译 .proto 文件
- 作用:将
.proto文件 转换成 对应平台的代码文件
Protoco Buffer提供C++、Java、Python三种开发语言的 API
- 具体生成文件与平台有关:

- 编译指令说明
// 在 终端 输入下列命令进行编译
protoc -I=$SRC_DIR --xxx_out=$DST_DIR $SRC_DIR/addressbook.proto
// 参数说明
// 1. $SRC_DIR:指定需要编译的.proto文件目录 (如没有提供则使用当前目录)
// 2. --xxx_out:xxx根据需要生成代码的类型进行设置
// 对于 Java ,xxx = java ,即 -- java_out
// 对于 C++ ,xxx = cpp ,即 --cpp_out
// 对于 Python,xxx = python,即 --python_out
// 3. $DST_DIR :编译后代码生成的目录 (通常设置与$SRC_DIR相同)
// 4. 最后的路径参数:需要编译的.proto 文件的具体路径
// 编译通过后,Protoco Buffer会根据不同平台生成对应的代码文件
- 具体实例
// 编译说明
// 1. 生成Java代码
// 2. 需要编译的.proto文件在桌面,希望编译后生成的代码也放在桌面
protoc -I=/Users/Carson_Ho/Desktop --java_out=/Users/Carson_Ho/Desktop /Users/Carson_Ho/Desktop/Demo.proto
// 编译通过后,Protoco Buffer会按照标准Java风格,生成Java类及目录结构
在指定的目录能看到一个Demo的包文件(含 java类文件)
编译功能的拓展
a. 使用Android Studio插件进行编译
- 需求场景:每次手动执行
Protocol Buffer编译器将.proto文件转换为Java文件 操作不方便 - 解决方案:使用
Android Studio的gradle插件protobuf-gradle-plugin,以便于在项目编译时 自动执行Protocol Buffers 编译器
关于protobuf-gradle-plugin插件有兴趣的读者可自行了解,但个人还是建议使用 命令行,毕竟太过折腾插件没必要
b. 动态编译
- 需求场景:某些情况下,人们无法预先知道 .proto 文件,他们需要动态处理一些未知的 .proto 文件
如一个通用的消息转发中间件,它无法预先知道需要处理什么类型的数据结构消息
- 解决方案:动态编译
.proto文件
由于使用得不多,此处不作过多描述,具体请看官方文档
c. 编写新的 .proto 编译器
- 需求场景:
Protocol Buffer仅支持C++、java 和 Python三种开发语言,一旦超出该三种开发语言,Protocol Buffer将无法使用 - 解决方案:使用
Protocol Buffer的Compiler包 开发出支持其他语言的新的.proto编译器
由于使用得不多,此处不作过多描述,具体请看官方文档
7. 总结
- 看完本文,你应该非常了解
Protocol Buffer的语法 & 如何去构建Protocol Buffer的消息模型 - 关于
Protocol Buffer的系列文章请看:- 手把手教你如何安装Protocol Buffer
- 这是一份很有诚意的 Protocol Buffer 语法详解
- 快来看看Google出品的Protocol Buffer,别只会用Json和XML了
- Protocol Buffer 序列化原理大揭秘 - 为什么Protocol Buffer性能这么好?
- Android:手把手带你分析 Protocol Buffer使用 源码
- 下一篇文章我将对
Protocol Buffer的源码进行详细分析,感兴趣的同学可以继续关注本人运营的Wechat Public Account: - 我想给你们介绍一个与众不同的Android微信公众号(福利回赠)
- 我想邀请您和我一起写Android(福利回赠)
请点赞!因为你的鼓励是我写作的最大动力!
相关文章阅读
Android开发:最全面、最易懂的Android屏幕适配解决方案
Android事件分发机制详解:史上最全面、最易懂
Android开发:史上最全的Android消息推送解决方案
Android开发:最全面、最易懂的Webview详解
Android开发:JSON简介及最全面解析方法!
Android四大组件:Service服务史上最全面解析
Android四大组件:BroadcastReceiver史上最全面解析
欢迎关注Carson_Ho的!
不定期分享关于安卓开发的干货,追求短、平、快,但却不缺深度。
