keystone四种token
keystone的四种token为:UUID token、PKI token、PKIZ token和Fernet token。
什么是token
通俗的讲,token 是用户的一种凭证,需拿正确的用户名/密码向 Keystone 申请才能得到。如果用户每次都采用用户名/密码访问 OpenStack API,容易泄露用户信息,带来安全隐患。所以 OpenStack 要求用户访问其 API 前,必须先获取 token,然后用 token 作为用户凭据访问 OpenStack API。
四种 Token 的由来
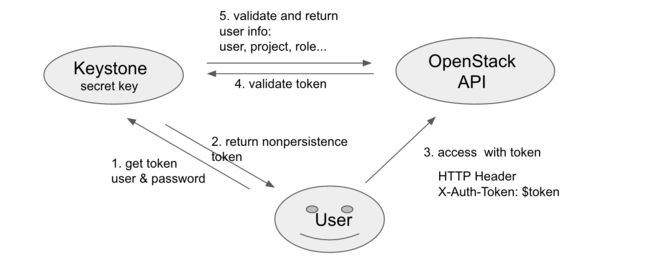
D 版本时,仅有 UUID 类型的 Token,UUID token 简单易用,却容易给 Keystone 带来性能问题。认证过程如下:

每当 OpenStack API 收到用户请求,都需要向 Keystone 验证该 token 是否有效。随着集群规模的扩大,Keystone 需处理大量验证 token 的请求,在高并发下容易出现性能问题。
于是 PKI(Public Key Infrastructrue) token 在 G 版本运用而生,和 UUID 相比,PKI token 携带更多用户信息的同时还附上了数字签名,以支持本地认证,从而避免了步骤 4。PKI的认证过程为:

因为 PKI token 携带了更多的信息,这些信息就包括 service catalog,随着 OpenStack 的 Region 数增多,service catalog 携带的 endpoint 数量越多,PKI token 也相应增大,很容易超出 HTTP Server 允许的最大 HTTP Header(默认为 8 KB),导致 HTTP 请求失败。
于是,PKIZ token随之出现,PKIZ toke就是 PKI token 的压缩版,认证过程为:

但PKIZ token的压缩效果有限,无法良好的处理 token size 过大问题。
前三种 token 都会持久性存于数据库,与日俱增积累的大量 token 引起数据库性能下降,所以用户需经常清理数据库的 token。为了避免该问题,社区提出了 Fernet token,它携带了少量的用户信息,大小约为 255 Byte,采用了对称加密,无需存于数据库中。认证过程为:
1、UUID
UUID token 是长度固定为 32 Byte 的随机字符串,由 uuid.uuid4().hex 生成。
def _get_token_id(self, token_data):
return uuid.uuid4().hex
但是因 UUID token 不携带其它信息,OpenStack API 收到该 token 后,既不能判断该 token 是否有效,更无法得知该 token 携带的用户信息,所以需经图一步骤 4 向 Keystone 校验 token,并获用户相关的信息。其样例如下:
144d8a99a42447379ac37f78bf0ef608
UUID token 简单美观,不携带其它信息,因此 Keystone 必须实现 token 的存储和认证,随着集群的规模增大,Keystone 将成为性能瓶颈。
2、PKI
在阐述 PKI(Public Key Infrastruction) token 前,让我们简单的回顾公开密钥加密(public-key cryptography)和数字签名。公开密钥加密,也称为非对称加密(asymmetric cryptography,加密密钥和解密密钥不相同),在这种密码学方法中,需要一对密钥,分别为公钥(Public Key)和私钥(Private Key),公钥是公开的,私钥是非公开的,需用户妥善保管。如果把加密和解密的流程当做函数 C(x) 和 D(x),P 和 S 分别代表公钥和私钥,对明文 A 和密文 B 而言,数学的角度上有以下公式:
B = C(A, S)
A = D(B, P)
其中加密函数 C(x), 解密函数 D(x) 以及公钥 P 均是公开的。采用公钥加密的密文只能用私钥解密,采用私钥加密的密文只能用公钥解密。非对称加密广泛运用在安全领域,诸如常见的 HTTPS,SSH 登录等。
数字签名又称为公钥数字签名,首先采用 Hash 函数对消息生成摘要,摘要经私钥加密后称为数字签名。接收方用公钥解密该数字签名,并与接收消息生成的摘要做对比,如果二者一致,便可以确认该消息的完整性和真实性。
PKI 的本质就是基于数字签名,Keystone 用私钥对 token 进行数字签名,各个 API server 用公钥在本地验证该 token。相关代码简化如下:
def _get_token_id(self, token_data):
try:
token_json = jsonutils.dumps(token_data, cls=utils.PKIEncoder)
token_id = str(cms.cms_sign_token(token_json,
CONF.signing.certfile,
CONF.signing.keyfile))
return token_id
token_data 经 cms.cms_sign_token 签名生成的 token_id 如下,共 1932 Byte:
MIIKoZIhvcNAQcCoIIFljCCBZICAQExDTALBglghkgBZQMEAgEwggPzBgkqhkiG9w0B
......
rhr0acV3bMKzmqvViHf-fPVnLDMJajOWSuhimqfLZHRdr+ck0WVQosB6+M6iAvrEF7v
3、PKIZ
PKIZ 在 PKI 的基础上做了压缩处理,但是压缩的效果极其有限,一般情况下,压缩后的大小为 PKI token 的 90 % 左右,所以 PKIZ 不能友好的解决 token size 太大问题。
def _get_token_id(self, token_data):
try:
token_json = jsonutils.dumps(token_data, cls=utils.PKIEncoder)
token_id = str(cms.pkiz_sign(token_json,
CONF.signing.certfile,
CONF.signing.keyfile))
return token_id
其中 cms.pkiz_sign() 中的以下代码调用 zlib 对签名后的消息进行压缩级别为 6 的压缩。
compressed = zlib.compress(token_id, compression_level=6)
PKIZ token 样例如下,共 1645 Byte,比 PKI token 减小 14.86 %:
PKIZ_eJytVcuOozgU3fMVs49aTXhUN0vAQEHFJiRg8IVHgn5OnA149JVaunNS3NYjoSU
......
W4fRaxrbNtinojheVICXYrEk0oPX6TSnP71IYj2e3nm4MLy7S84PtIPDz4_03IsOb2Q=
4、Fernet
用户可能会碰上这么一个问题,当集群运行较长一段时间后,访问其 API 会变得奇慢无比,究其原因在于 Keystone 数据库存储了大量的 token 导致性能太差,解决的办法是经常清理 token。为了避免上述问题,社区提出了Fernet token,它采用 cryptography 对称加密库(symmetric cryptography,加密密钥和解密密钥相同) 加密 token,具体由 AES-CBC 加密和散列函数 SHA256 签名。Fernet 是专为 API token 设计的一种轻量级安全消息格式,不需要存储于数据库,减少了磁盘的 IO,带来了一定的性能提升。为了提高安全性,需要采用 Key Rotation 更换密钥。
def create_token(self, user_id, expires_at, audit_ids, methods=None,
domain_id=None, project_id=None, trust_id=None,
federated_info=None):
"""Given a set of payload attributes, generate a Fernet token."""
if trust_id:
version = TrustScopedPayload.version
payload = TrustScopedPayload.assemble(
user_id,
methods,
project_id,
expires_at,
audit_ids,
trust_id)
...
versioned_payload = (version,) + payload
serialized_payload = msgpack.packb(versioned_payload)
token = self.pack(serialized_payload)
return token
以上代码表明,token 包含了 user_id,project_id,domain_id,methods,expires_at 等信息,重要的是,它没有 service_catalog,所以 region 的数量并不影响它的大小。self.pack() 最终调用如下代码对上述信息加密:
def crypto(self):
keys = utils.load_keys()
if not keys:
raise exception.KeysNotFound()
fernet_instances = [fernet.Fernet(key) for key in utils.load_keys()]
return fernet.MultiFernet(fernet_instances)
该 token 的大小一般在 200 多 Byte 左右,本例样式如下,大小为 186 Byte:
gAAAAABWfX8riU57aj0tkWdoIL6UdbViV-632pv0rw4zk9igCZXgC-sKwhVuVb-wyMVC9e5TFc
7uPfKwNlT6cnzLalb3Hj0K3bc1X9ZXhde9C2ghsSfVuudMhfR8rThNBnh55RzOB8YTyBnl9MoQ
XBO5UIFvC7wLTh_2klihb6hKuUqB6Sj3i_8
如何选择 Token
| Token类型 | UUID | PKI | PKIZ | Fernet |
|---|---|---|---|---|
| 大小 | 32 Byte | KB 级别 | KB 级别 | 约 255 Byte |
| 支持本地认证 | 不支持 | 支持 | 支持 | 不支持 |
| Keystone 负载 | 大 | 小 | 小 | 大 |
| 存储于数据库 | 是 | 是 | 是 | 否 |
| 携带信息 | 无 | user, catalog 等 | user, catalog 等 | user 等 |
| 涉及加密方式 | 无 | 非对称加密 | 非对称加密 | 对称加密(AES) |
| 是否压缩 | 否 | 否 | 是 | 否 |
| 版本支持 | D | G | J | K |
Token 类型的选择涉及多个因素,包括 Keystone server 的负载、region 数量、安全因素、维护成本以及 token 本身的成熟度。region 的数量影响 PKI/PKIZ token 的大小,从安全的角度上看,UUID 无需维护密钥,PKI 需要妥善保管 Keystone server 上的私钥,Fernet 需要周期性的更换密钥,因此从安全、维护成本和成熟度上看,UUID > PKI/PKIZ > Fernet 如果:
- Keystone server 负载低,region 少于 3 个,采用 UUID token。
- Keystone server 负载高,region 少于 3 个,采用 PKI/PKIZ token。
- Keystone server 负载低,region 大与或等于 3 个,采用 UUID token。
- Keystone server 负载高,region 大于或等于 3 个,K 版本及以上可考虑采用 Fernet token。
keystone 四个重要概念
openstack中region、cell、availability zone、host aggregate 几个概念都是对节点进行划分,具体有什么区别呢?
1、Region
更像是一个地理上的概念,每个region有自己独立的endpoint,regions之间完全隔离,但是多个regions之间共享同一个keystone和dashboard。
所以除了提供隔离的功能,region的设计更多侧重地理位置的概念,用户可以选择离自己更近的region来部署自己的服务。
2、Cells
在大规模部署的时候,API、Conductor等服务需要集中部署,并且比较容易扩展,因为它们是无状态的,或接近于无状态的,主要的压力在数据库上面。
Compute服务会部署在每个hypervisor节点,因为消息队列服务能够支持的规模在200个hypervisor左右,所以,Compute服务如何扩展是一个需要仔细考虑的问题。
此外,在上千台规模时,Scheduler可能会出现性能瓶颈。因为,目前Scheduler的实现方式不是很优雅,不能处理大规模、高并发的调度请求。
为了解决数据库和消息队列扩展的问题,nova项目引入了cell服务,通过cell服务可以将hypervisor节点分成若干个组,每组hypervisor节点使用不同的数据库和消息队列服务,从而解决数据库和消息队列的扩展问题。目前,nova cell有两个实现版本v1 和 v2,v1实现的架构如下:
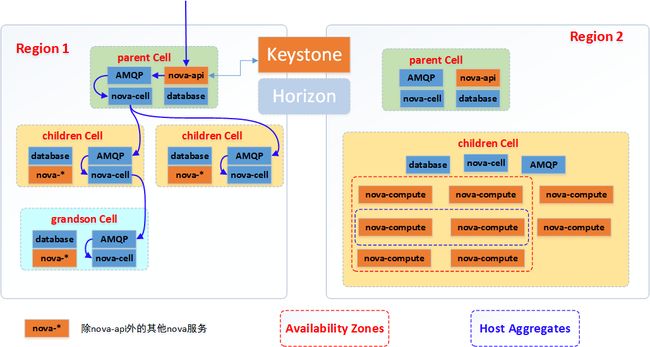
由于cell被实现为树形结构,自然而然引入了分级调度的概念。通过在每级cell引入nova-cell服务,实现了以下功能:
(1)Messages的路由,即父cell通过nova-cell将Messages路由到子cell的AMQP模块
(2)分级调度功能,即调度某个instances的时候先要进行cell的选择,目前只支持随机调度,后续会增加基于filter和weighing策略的调度。
(3)资源统计,子cell定时的将自己的资源信息上报给父cell,用来给分级调度策略提供决策数据和基于cell的资源监控
(4)cell之间的通信(通过rpc完成)
最后,所有的子cell公用底层cell的nova-api,子cell包含除了nova-api之外的其他nova服务,当然所有的cell都共用keystone服务。
(注:nova-*是指除了nova-api之外的其他nova服务,子cell + 父cell才构成了完整的nova服务)
3、Availability Zone
AZ可以简单理解为一组节点的集合,这组节点具有独立的电力供应设备,比如一个个独立供电的机房,一个个独立供电的机架都可以被划分成AZ。所以,AZ主要是通过冗余来解决可用性问题。
AZ是用户可见的一个概念,用户在创建instance的时候可以选择创建到哪些AZ中,以保证instance的可用性。
4、Host Aggregate
AZ是一个面向用户的概念和能力,而host aggregate是管理员用来根据硬件资源的某一属性来对硬件进行划分的功能,只对管理员可见,主要用来给nova-scheduler通过某一属性来进行instance的调度。其主要功能就是实现根据某一属性来划分物理机,比如按照地理位置,使用固态硬盘的机器,内存超过32G的机器,根据这些指标来构成一个host group。
/etc/nova/nova.conf:
scheduler_default_filters=AggregateInstanceExtraSpecsFilter,AvailabilityZoneFilter,RamFilter,ComputeFilter
$ nova aggregate-create fast-io nova
+----+---------+-------------------+-------+----------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+-------+----------+
| 1 | fast-io | nova | | |
+----+---------+-------------------+-------+----------+
$ nova aggregate-set-metadata 1 ssd=true
+----+---------+-------------------+-------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+-------+-------------------+
| 1 | fast-io | nova | [] | {u'ssd': u'true'} |
+----+---------+-------------------+-------+-------------------+
$ nova aggregate-add-host 1 node1
+----+---------+-------------------+-----------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+------------+-------------------+
| 1 | fast-io | nova | [u'node1'] | {u'ssd': u'true'} |
+----+---------+-------------------+------------+-------------------+
$ nova aggregate-add-host 1 node2
+----+---------+-------------------+---------------------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+----------------------+-------------------+
| 1 | fast-io | nova | [u'node1', u'node2'] | {u'ssd': u'true'} |
+----+---------+-------------------+----------------------+-------------------+
$ nova flavor-create ssd.large 6 8192 80 4
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
| ID | Name | Memory_MB | Disk | Ephemeral | Swap | VCPUs | RXTX_Factor | Is_Public | extra_specs |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
| 6 | ssd.large | 8192 | 80 | 0 | | 4 | 1 | True | {} |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+-------------+
# nova flavor-key set_key --name=ssd.large --key=ssd --value=true
$ nova flavor-show ssd.large
+----------------------------+-------------------+
| Property | Value |
+----------------------------+-------------------+
| OS-FLV-DISABLED:disabled | False |
| OS-FLV-EXT-DATA:ephemeral | 0 |
| disk | 80 |
| extra_specs | {u'ssd': u'true'} |
| id | 6 |
| name | ssd.large |
| os-flavor-access:is_public | True |
| ram | 8192 |
| rxtx_factor | 1.0 |
| swap | |
| vcpus | 4 |
+----------------------------+-------------------+
Now, when a user requests an instance with the ssd.large flavor, the scheduler only considers hosts with the ssd=true key-value pair. In this example, these are node1 and node2.
参考
Openstack中国社区
linuxsky的博客
crowns的