效果图
-
1.只查询动车票

-
2.查询所有票
Github链接
代码链接为:https://github.com/happyte/tickets
接口设计
- 1.查询火车票,需要出发地点,目的点,日期和所乘列类型这几个参数,因此设计出的接口为
python3 tickets.py [-gdtkz],[-gdtkz]代表查询的火车类型,该参数可叠加,例如-gd代表查询所有的动车和高铁。 - 2.python的docopt模块可以解析命令行的参数,代码如下:
"""命令行火车票查看器
Usage:
tickets [-gdtkz]
Options:
-h,--help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets 北京 上海 2016-10-10
tickets -dg 成都 南京 2016-10-10
"""
from docopt import docent
def cli():
arguments = docopt(__doc__)
print(arguments)
if __name__ == '__main__':
cli()
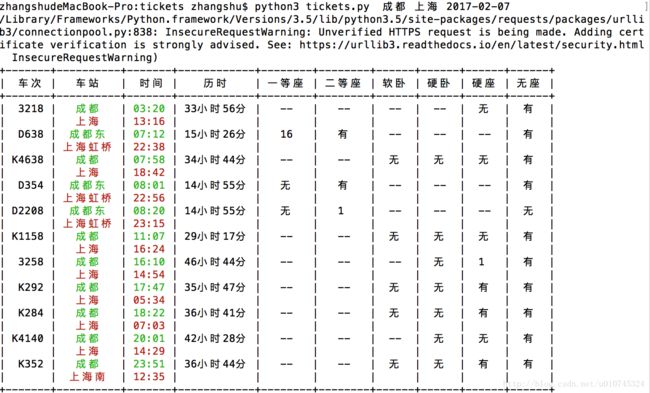
- 3.在命令行输入命令
python3 tickets.py -dg 成都 上海 2017-02-10输出的结果如下:
获取12306数据
-
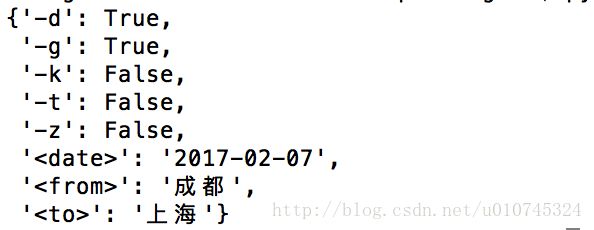
1.用谷歌的chrome浏览器抓取下网页的数据

从上图中发现请求的url后面跟了4个参数,分别为leftTicketDTO.train_date=2017-02-07、leftTicketDTO.from_station=CDW、leftTicketDTO.to_station=SHH、purpose_codes=ADULT四个参数。 -
2.再抓取下response,结果如下:
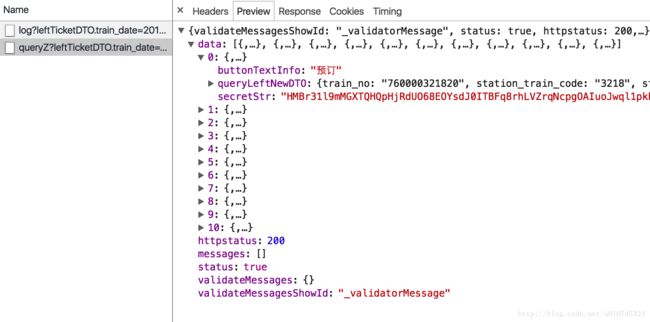
所有的车次信息都在data这个字典中,0-10这个分别包含了每趟车的所有信息。
-
3.在请求的url中出发点和目的地都是英文缩写,例如上面的
CDW和SHH,而我们在命令行中输入的是中文,那么需要通过中文查找到对应的英文缩写,这个用chrome抓取到的数据好像没找到。那么查看下网页源代码

点击进入第一个station_version=1.8994这个文件,进入之后看到该文件是所有车站对应的中文和英文缩写,但是只需要提取中文和英文的大写缩写,编写一个正则表达式提取。另外新建一个文件叫parse_station.py,代码如下:
# -*- coding:utf-8 -*-
import re
import requests
from pprint import print
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.8994'
response = requests.get(url, verify=False) # verify=False不验证证书
stations = re.findall(u'([\u4e00-\u9fa5]+)+\|([A-Z]+)', response.text)
pprint(dict(stations), indent=4) # indent代表缩进
- 4.在命令行执行
python3 parse_station.py > stations.py,就新建了一个stations.py文件里面生成了一个中文和英文缩写对应的字典,如下所示:
 这里写图片描述
这里写图片描述
获取需要的信息
- 1.构造url请求,导入上面生成的stations.py文件
from stations import stations
def cli():
arguments = docopt(__doc__)
from_station = stations.get(arguments[''])
to_staion = stations.get(arguments[''])
date = arguments['']
url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date={}&leftTicketDTO.' \
'from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.\
format(date, from_station, to_staion)
response = requests.get(url, verify=False)
- 2.得到请求的json应答,因为上面说了所有的列车信息都在data字典内部,因此需要的信息在
response.json()['data']中。 - 3.创建一个类用于分析需要的数据,
prettytable模块用于创建图形化表格,colorama模块用于给表格上色。
class TransCollection:
header = '车次 车站 时间 历时 一等座 二等座 软卧 硬卧 硬座 无座'.split()
def __init__(self, available_trains, options):
self.availavle_trains = available_trains
self.options = options
def _get_duration(self, train_data):
duration = train_data.get('lishi').replace(':', '小时')+'分'
if duration.startswith('00'):
return duration[4:]
if duration.startswith('0'):
return duration[1:]
return duration
@property
def trains(self):
for train in self.availavle_trains:
train_data = train['queryLeftNewDTO']
train_number = train_data['station_train_code'][0].lower() # 开头转换成小写
if not self.options or train_number in self.options:
train = [
train_data['station_train_code'], # 车次
'\n'.join([Fore.GREEN+train_data['from_station_name']+Fore.RESET, # 车站
Fore.RED+train_data['to_station_name']+Fore.RESET]),
'\n'.join([Fore.GREEN+train_data['start_time']+Fore.RESET, # 车站
Fore.RED+train_data['arrive_time']+Fore.RESET]),
self._get_duration(train_data), # 历时
train_data['zy_num'], # 一等座
train_data['ze_num'], # 二等座
train_data['rw_num'], # 软卧
train_data['yw_num'], # 硬卧
train_data['yz_num'], # 硬座
train_data['wz_num'], # 无座
]
yield train
def pretty_print(self):
pt = PrettyTable()
pt._set_field_names(self.header)
for train in self.trains:
pt.add_row(train)
print(pt)
- 4.创建一个上面类的对象,调用
pretty_print函数,在cli函数中添加
def cli():
arguments = docopt(__doc__)
from_station = stations.get(arguments[''])
to_staion = stations.get(arguments[''])
date = arguments['']
url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date={}&leftTicketDTO.' \
'from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.\
format(date, from_station, to_staion)
response = requests.get(url, verify=False)
options = ''.join([key for key, value in arguments.items() if value is True])
TransCollection(response.json()['data'], options).pretty_print()