IndexR是由舜飞科技研发的实时OLAP系统。于 2017 年 1 月初正式开源,目前已经更新至 0.6.1 版本,其作者认为IndexR具有以下特点:
超大数据集,低查询延时(超大数据集由HDFS保证,查询低延迟由MPP架构的Drill和IndexR专门设计的存储格式保证)
准实时 (和Druid实时摄入的思路类似,从Kafka实时摄入数据)
高可用,易扩展(架构设计简单,只有一种节点,可以轻易横向扩展)
易维护(支持Schema在线更新)
SQL支持 (由Drill支持,实际上Drill也是利用Calcite实现的)
与Hadoop生态整合(Hive,Kafka,Spark, Zookeeper, HDFS)
Why IndexR
IndexR的作者认为现有的各类OLAP系统均存在各种缺点,无法满足其公司实际的OLAP需求,所以开发了IndexR。
Mysql,PostgreSQL等关系型数据库:无法满足超大规模数据集。
ES等搜索系统:对OLAP场景没有特殊优化,在大数据量场景下内存和磁盘压力比较大。
Druid,Pinot等时序数据库:在查询条件命中大量数据情况下可能会有性能问题,而且排序、聚合等能力普遍不太好,从IndexR作者的使用经验来看运维比较困难,灵活性和扩展性不够,比如缺乏Join、子查询等。
Infobright,ClickHose等列式数据库: 不是基于Hadoop生态的。
Kylin:查询灵活性不足,无法进行探索式分析。
Impala,Presto,SparkSQL,Drill等计算引擎 + Parquet等存储引擎:这也是IndexR的架构。IndexR的优势是更有效的索引设计,并且支持数据实时摄入。
IndexR Architecture
IndexR中只有一种节点IndexR Node,现在IndexR作为Drill插件嵌入了Drillbit进程,下图是IndexR的服务部署图:
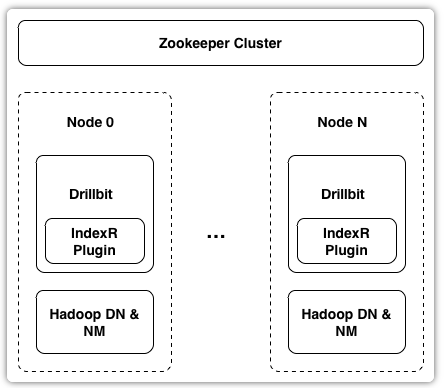
Drill是一个类似Presto的MPP数据库,Drillbit是一个类似Presto Work节点的常驻进程,和Hadoop的DN进程混部,可以利用HDFS的短路读的特性。Zookeeper主要用来存储表和segment的一些元信息。IndexR的架构图如下:
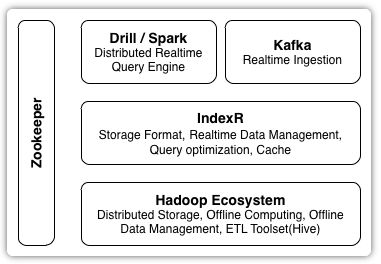
IndexR支持从Kafka实时读取数据。IndexR支持通过Drill,Hive,Spark查询数据,不过Hive,Spark只能查询历史数据,Drill可以同时查询实时数据和历史数据。
IndexR Storage
1、基本概念
Table:表是对用户可见的概念,用户的查询需要指定Table。
Segment:1个Table由多个Segment组成,Segment自解释,自带索引,是实时数据和离线数据转换的纽带,实时的segment和离线的segment具体结构稍有不同。
Column: IndexR是列式存储的,即某一列的数据会集中存放在一起。某一列的索引和数据是存放在一起的。
Pack: 列数据在内部会进一步细分为Pack,每个Pack有65536行记录,Pack是基本的IO和索引单位。
Row: 表示一行数据。实时数据摄入和离线导入的时候数据都是以行为单位加入一个segment的。
2、离线Segment的存储格式
IndexR 在HDFS存储的一个文件是一个Segment,一个Segment保存一个表的部分行,包含所有的列。

Segment 文件由4部分组成:版本号,Segment的元数据,所有Column 和 Pack的倒排索引。
Segment的元数据包括:行数,列数,每列的MAX和MIN值,每列的name, type,每列的各种索引的偏移量等。
Column包含多个Pack,每个Pack由DataPackNode,PackRSIndex,PackExtIndex,DataPack4部分组成,但是存储的时候是先存储所有Pack的索引数据,再存储所有Pack的实际数据,这样的好处是可以通过只读取索引文件来快读过滤掉不必要的Pack,来减少随机IO。
图中DataPack是实际的数据;
DataPackNode是Pack元数据信息,包括索引文件的大小和偏移等;
PackRSIndex是Pack的Rough Set索引;
PackExtIndex是Pack的内索引,包括equal,in, greater, between, like 5种。
图中的outerIndex是Pack级别的倒排索引,主要用于Pack之间的精准过滤。
3、实时Segment
实时Segment存储在实时节点 本机的文件系统,和离线Segment的主要区别是每个Column的数据,元数据,索引都是单独一个文件。
实时节点会定期的对本机的实时Segment进行merge,将多个segment合并为一个segment,并将所有Column写入一个segment文件中。 基本原理和Druid类似,Durid(一): 原理架构

IndexR Index
IndexR的3层索引,依次是Rough Set Index(粗糙集索引), Inverted Index(倒排索引),PackExtIndex(内索引),如下图

1、Rough Set Index
RSIndex的思路和Bloomfilter一样,可以快速判断某个值是否在某个Pack中。RSIndex的构建过程十分简单,就是将Pack中某一列的所有值进行N等分, 如果这列的区间长度m小于1024,则N等于m,否则N等于1024。然后将每个值映射到这N个区间,每个区间用1个bit表示。如下图

对于如下的date列:因为区间长度(20170110 - 20170101 = 9)小于1024,所以每个值对应的bit就是和该列最小值的差值,所以生成的RSIndex如下,value等于1表示存储,等于0表示不存在。
所以当我们查询: SELECT column FROM A WHERE date = '20170104' 时, 我们知道 20170104 的value是0,所以确定20170104不在该pack,可以直接跳过。
由于Pack内的数据是根据维度有序的,每个Pack总共有65536行记录,所有有很大概率1个Pack的维度列的基数是小于1024的。所以RSIndex的索引文件很小,而且索引效率较高。
2、Inverted Index
IndexR对于需要倒排索引的列会建立倒排索引,用于Pack之间的精准过滤。 倒排索引的构建过程如下:
首先Pack内部会使用红黑树对value进行字典编码,然后将字典保存下来。
在生成离线 Segment的时候,每一列会建立倒排索引。
倒排索引会保留每个value到packID的映射。
查询时会根据value找到对应的packID。
3、PackExtIndex
PackExtIndex是Pack的扩展索引,包括equal, in, greater, between, like 5种,主要用于查询时的对于Pack内部数据的快速过滤。PackExtIndex的实现方式有两种,一种是基于字典的,一种是基于bit的简单索引。
4、有了Inverted Index为什么还需要RSIndex
一个很明显的问题,既然倒排索引已经可以很精准的对Pack进行过滤,为啥还多此一举再加个粗糙集索引呢? 因为倒排索引是可选项,而且存储成本较高。
IndexR 常见问题
1、数据实时摄入如何实现
实现思路和Druid基本类似,实时节点直接从Kafka拉取数据,生成RT Segment。
2、IndexR如何支持Hive查询
实现了IndexRInputFormat 和 IndexROutputFormat。
3、IndexR 如何支持Spark查询
实现了IndexRFileFormat,该类实现了接口org.apache.spark.sql.execution.datasources.FileFormat。
4、IndexR 如何整合Drill
IndexR主要负责存储层,作为Drill的1个存储插件,还会对具体的查询过程进行优化,比如常见的条件下推,limit下推。

5、IndexR 的存储性能
作者声称VLT模式的Segment的Scan速度比Parquet快2倍,而且仅需要 75%的存储。Basic模式的Segment使用了Infobright的压缩算法,可以实现极高的压缩比。
6、IndexR 如何实现Schema的在线更新
当addColumn,deleteColumn,alterColumn时,生成新的SegmentSchema,然后通过MR job生成新的Segment,当Job commit时,删除旧的Segment,并将新Segment从tmp目录move到标准目录,最后通知该Segment已更新。
7、IndexR 堆外内存的实现
利用sun.misc.Unsafe直接操作堆外内存。
像C语言一样直接用指针从内存get值,用指针直接set值。
读取文件时直接读写到DirectByteBuffer。
用到DirectByteBuffer的类一定及时释放。
IndexR 亮点
丰富的索引。
丰富的谓词下推。
只有一种节点,外部依赖较少。
同时支持OLAP和明细查询。
支持Schema在线更新。
使用堆外内存避免GC。
压缩算法使用C++实现。
IndexR 不足
数据类型仅支持int, long, float, double, string。
聚合函数仅支持sum, max, min, first, last。
Drillbit和DN混部,可能会影响HDFS的稳定性。
强依赖Drill,必须先部署Drill。
IndexR 是最快的数据库吗?
显然不是!
没有预计算的系统肯定不会是最快的OLAP数据库,对于需要大量Scan,大量计算,大量聚合的SQL, 不经过预计算则不可能实现秒级查询。IndexR的作者显然也知道这个问题,所以提出了父子表的概念,也就是对于一些查询经常用到的高频维度组合,可以把这些高频的维度组合提前计算出来,作为一张子表,这就是预计算的思想,和Kylin能够保证Cube和HBase的透明性相比,IndexR必须要求应用层实现表的路由,并且查询时需要明确的指定不同表的名称。
其实实际业务的查询一般也是符合二八定律的,我们只需要将高频的20%的维度组合预计算出来,就可以满足80%查询的性能要求。 Kylin一直在维度组合优化上努力,而360也在Druid中引入了类似Kylin中cubooid的概念。
所以我们可以得出,要想打造出一个高并发,足够稳定,秒级响应的OLAP系统,预计算肯定是必要的,但关键是我们需要在预计算的度上进行自动化,智能化的把控。